- 本記事は2021/12/12のアドベントカレンダー原稿を落とした私が後日追加した記事です
以前、仕事の必要に迫られてシステムのNW構成を把握するためにneo4jを使う機会があったため、また使い始めてみようと改めて触りました。
ローカル環境のJupyterLabから同じくローカル起動のneo4j serverにクエリすることで、AWS構成情報のグラフ化を試しました。
はじめに
冒頭からなんですが、但し書きです。
本記事を作成する中で断念したことは次の通りです。
-
aws/graph-notebookのウォークスルーをJupyterLab環境で動かす
- JupyterLabではなくJupyterノートブック前提のnbextensionであり、拡張機能に互換性がなさそうだったため中止しました
- Neo4jのWebコンソール同等の可視化グラフ
- グラフ構造の可視化にあたっては色々と実装上の調整が必要だったため、触りだけ確認しました
- その辺りの操作性だけ先に確認したい人はNeo4j Sandboxがおすすめ
- ローカル環境からAmazon Neptuneにクエリする
- サービス仕様として不可... RDSやAESではパブリックアクセスやData APIが可能なので盲点でした
- Amazon Neptune の制限
Amazon Neptune は、仮想プライベートクラウド (VPC) 専用サービスです。
また、VPC の外部からインスタンスにアクセスすることはできません。
前提
- JupyterLab(ローカル)
- 今回はAWS認証情報なし
- pipenv環境で動かす
- 主に必要なPythonパッケージ
neo4jnetworkxmatplotlib
- Neo4j(ローカル)
- サンプルデータ
- 件数は極小ですが、今回はAWS Configが出力するjsonを使ってます
グラフDBとNeo4jについて
(ネット検索のキーワード精度が落ちる一因ですが、、)ここでいう「グラフ」はデータ構造のことで、Neo4jはDBエンジンやクエリ仕様を意味してます。
「有向グラフ」や「無向グラフ」でキーワード検索すると、関連する結果になるはずです。
自分自身、グラフ理論を語るほど理解していないですがグラフDBのユースケースは明確です。
- 多:多の関係を高速に検索したい
- 可視化ツールと組み合わせて複雑なデータ(大抵は多:多)の視認性を上げたい
概要については、AWSのアーキテクト資料がとても分かりやすかったので参考になります。
グラフDBを用いた開発のポイント
多:多なのにどうやってデータを高速に扱えるのか、
という点はグラフ理論のコア実装に関わる部分で自分はまだ十分に理解できていません...
少なくとも、データロードで作成するエンティティ(ノードやエッジなど)には全てインデックスを作成する仕様になっているようです。
Neo4j
Neo4jはローカルファイルをデータストアとして使うため、可用性を上げたい場合にNeo4j Fabricを導入することになり、データベース構築に頭を使う必要がありそうです。その場合、マルチDB仕様のためfabric構成で台数を増やすごとに性能もスケールアウトするようです。
自分がグラフDBを初めて知った契機はRDFでしたが、グラフDBの強力さを知ったきっかけはパナマ文書の印象が強いです。
パナマ文書のデータセットはNeo4jが無償提供しているため、注意書きを理解した上で使いましょう。
参考:Offshore Leaks Database
なお、今回使うNeo4jはOpenCypherというクエリ仕様ですが、他にはGremlinとRDFが標準的です。
参考:GremlinとOpenCypher
AWSはneo4jからNeptuneへの移行をブログで紹介してます...さすが。
https://aws.amazon.com/jp/blogs/news/migrating-a-neo4j-graph-database-to-amazon-neptune-with-a-fully-automated-utility/
サンプルデータ準備
Neo4jにデータロードするため、AWS Configのjsonを簡単に加工しておきます。
と言っても、必要な項目だけパースしてcsvに変換するだけです。
どのような形にパースすれば良いか、という点が最初の関門ですが、一般的なデータ設計と同様のステップが必要です。
参考:Graph Modeling Guidelines
Neo4jでは、NodeとRelationshipsのデータを分けてロードすることになります。
元データ(json)
今回はIAM RoleとLambda関数のAWS Configデータです。
{
"fileVersion": "1.0",
"configurationItems": [
{
"relatedEvents": [],
"relationships": [
{
"resourceName": "lambda_test",
"resourceType": "AWS::IAM::Role",
"name": "Is associated with "
}
],
"configuration": {
"functionName": "Athena_Cost-Query",
"functionArn": "arn:aws:lambda:ap-northeast-1:123456789012:function:Athena_Cost-Query",
"runtime": "python3.8",
"role": "arn:aws:iam::123456789012:role/lambda_test",
"handler": "lambda_function.lambda_handler",
"codeSize": 831,
"description": "",
"timeout": 210,
"memorySize": 128,
"lastModified": "2020-02-20T13:14:36.105+0000",
"codeSha256": ".....",
"version": "$LATEST",
"tracingConfig": {
"mode": "PassThrough"
},
"revisionId": "42275ada-2c5b-4700-9c3b-e567f527f7e7",
"layers": [],
"state": "Active",
"lastUpdateStatus": "Successful",
"fileSystemConfigs": [],
"packageType": "Zip",
"architectures": [
"x86_64"
]
},
"supplementaryConfiguration": {
"Tags": {}
},
"tags": {},
"configurationItemVersion": "1.3",
"configurationItemCaptureTime": "2021-11-12T21:14:00.811Z",
"configurationStateId": 1636751640811,
"awsAccountId": "123456789012",
"configurationItemStatus": "OK",
"resourceType": "AWS::Lambda::Function",
"resourceId": "Athena_Cost-Query",
"resourceName": "Athena_Cost-Query",
"ARN": "arn:aws:lambda:ap-northeast-1:123456789012:function:Athena_Cost-Query",
"awsRegion": "ap-northeast-1",
"availabilityZone": "Not Applicable",
"configurationStateMd5Hash": ""
},
(以下、取得されたConfig数の配列)
加工済みデータ(csv)
AccountId ResourceRegion Az SubjectName SubjectType Relation ObjectName ObjectType
123456789012 ap-northeast-1 Not Applicable lambda_test AWS::IAM::Role Is associated with Athena_Cost-Query AWS::Lambda::Function
#(以下略).....
データファイルの保存先
neo4jをコマンドラインで起動すると、下記のようなメッセージが標準出力されます。
importディレクトリに準備したデータファイルを保存すればOKです。
$ neo4j start
Directories in use:
home: /usr/local/bin/neo4j
config: /usr/local/bin/neo4j/conf
logs: /usr/local/bin/neo4j/logs
plugins: /usr/local/bin/neo4j/plugins
import: /usr/local/bin/neo4j/import
data: /usr/local/bin/neo4j/data
certificates: /usr/local/bin/neo4j/certificates
run: /usr/local/bin/neo4j/run
Starting Neo4j.
Started neo4j (pid 19749). It is available at http://localhost:7474/
There may be a short delay until the server is ready.
See /usr/local/bin/neo4j/logs/neo4j.log for current status.
neo4jデータロード
個人的見解ですが、データロードが完了すれば山場は超えたようなものです。
参考:How-To: Import CSV Data with Neo4j Desktop
今回はロード方法までプログラミングしていませんが、LOAD CSVステートメントではURL指定が可能なのでS3 Pre-signed URLを発行すれば任意のS3ファイルをNeo4jにロードできるため、実運用では役立つこと間違いなしです。
Neo4jをローカル起動後、Webコンソールにログインして次のクエリを実行します。
*ファイルパスはimportディレクトリからの相対パス
-- AWS Config
-- about IAM Roles attached Lambda function
-- Nodes: IAM Role
LOAD CSV WITH HEADERS FROM "file:///AwsConfig_sample_subject-node.csv" as sbj
CREATE (:IAMRole {iam_role_name: sbj.SubjectName});
-- Nodes: Lambda function
LOAD CSV WITH HEADERS FROM "file:///AwsConfig_sample_object-node.csv" as obj
CREATE (:AWSLambda {lambda_function_name: obj.ObjectName});
-- Relationships: roles associated with functions
LOAD CSV WITH HEADERS FROM "file:///AwsConfig_sample_data.csv" as data
MATCH (roles:IAMRole {iam_role_name: data.SubjectName}), (functions:AWSLambda {lambda_function_name: data.ObjectName})
CREATE (roles)-[:ATTACHMENT {relation_name: data.Relation}]->(functions);
次のクエリでデータ検索結果をグラフで確認できます
MATCH (r:IAMRole)-[]->(f:AWSLambda)
RETURN r, f
グラフデータ(画面キャプチャ)
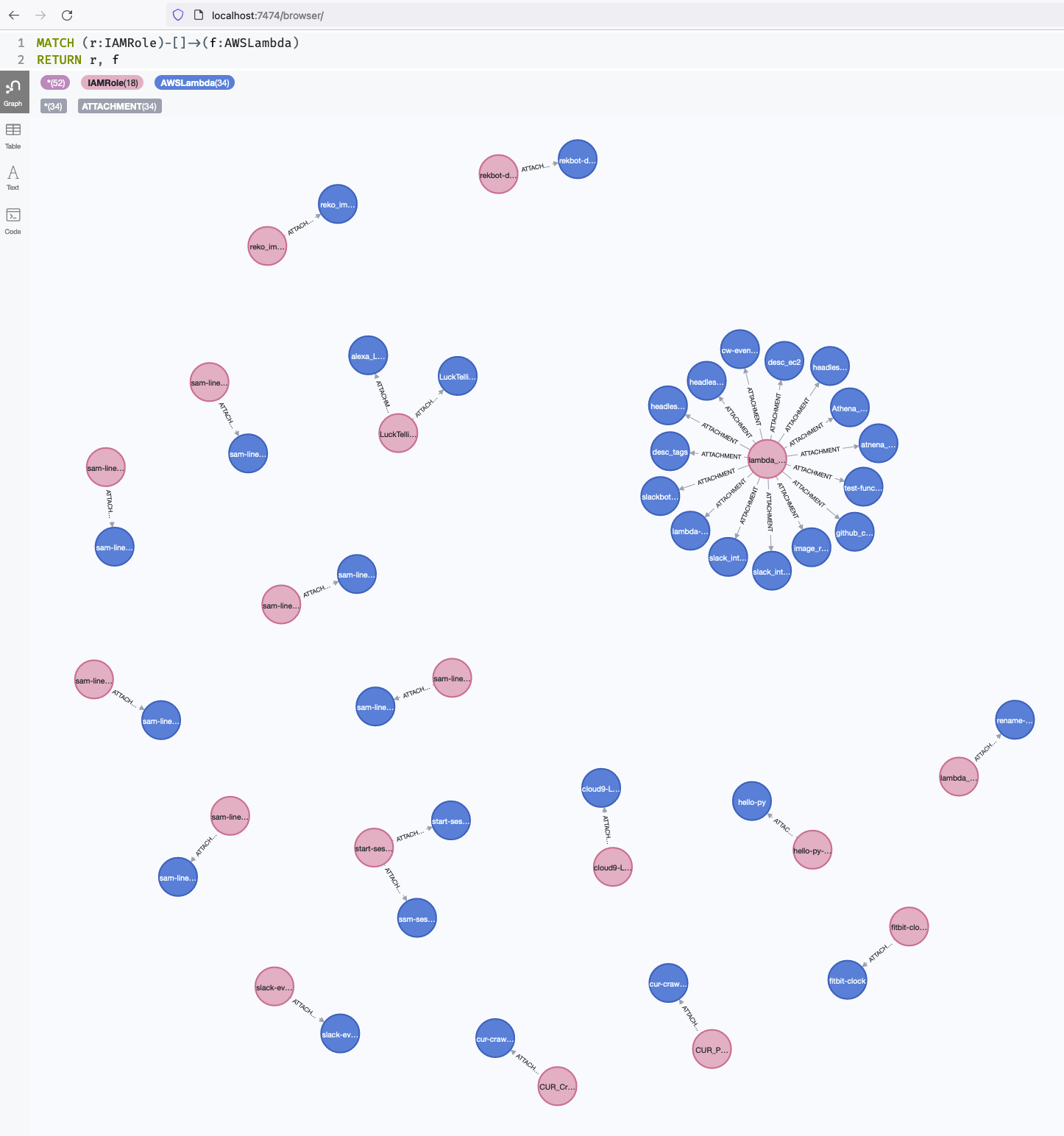
JupyterLabにグラフを描画する
PythonではNetworkXというライブラリがデファクトスタンダードっぽいため、今回もそちらを採用しました。JupyterLabで基本的な動作検証ができれば、Webアプリに組み込む際の目処もつきそうです。
*コードブロックはJyupyterLabのセル単位だと思ってください
from neo4j import GraphDatabase
import networkx as nx
driver = GraphDatabase.driver('bolt://localhost:7687', auth=('neo4j', 'Alskdjfh6'))
#有向グラフのインスタンス
Di = nx.DiGraph()
def create_edge(node_edge):
#networkx仕様により、エッジの両端(ノード)が存在しなければノード・エッジを同時作成する
#引数はtupple
Di.add_edges_from(node_edge)
def get_RoleAttachedLambda(tx):
query = '''MATCH (r:IAMRole)-[]->(f:AWSLambda)
RETURN r.iam_role_name, f.lambda_function_name
'''
node_edge = []
for record in tx.run(query):
edge_data = (record['r.iam_role_name'], record['f.lambda_function_name'])
node_edge.append(edge_data)
create_edge(node_edge)
with driver.session() as session:
session.read_transaction(get_RoleAttachedLambda)
ひとまずグラフ描画できるかお試し
参考:Drawing graphs
#グラフ描画
#networkx自身に描画機能はなく、draw_networkx()の実行にはmatplotlibが必要
nx.draw_networkx(Di)
役立ちそうにないグラフができました...
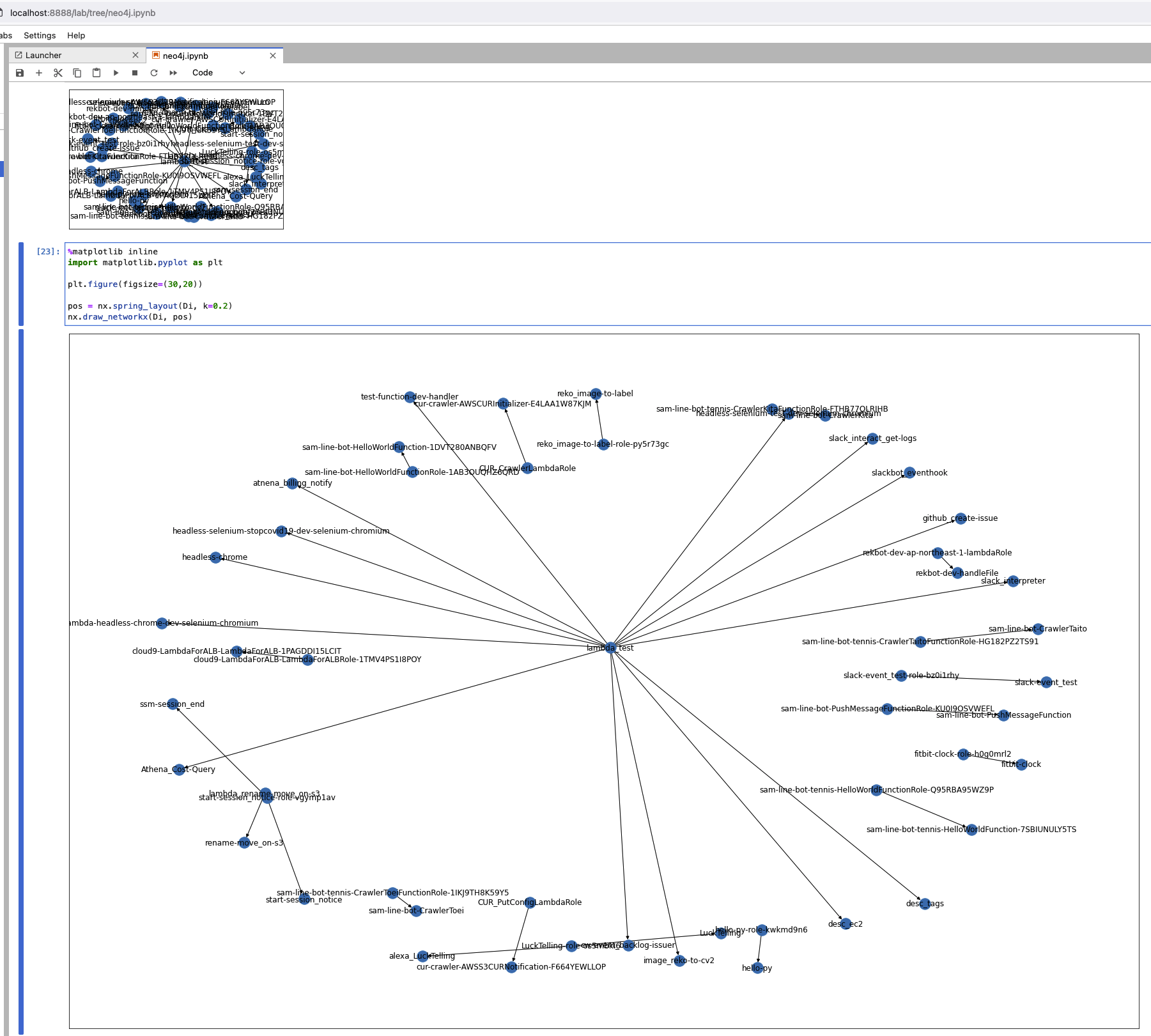
描画エリアとノード間の距離を調整して再実行
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(figsize=(30,20))
pos = nx.spring_layout(Di, k=0.2)
nx.draw_networkx(Di, pos)
少しは役立ちそうなグラフができました![]()
参考記事
The Cypher Style Guide
https://github.com/opencypher/openCypher/blob/master/docs/style-guide.adoc#recommendations
グラフ理論とNetworkX
https://docs.pyq.jp/python/math_opt/graph.html
[Python]NetworkXでQiitaのタグ関係図を描く
https://qiita.com/inoory/items/088f719f2fd9a2ea4ee5
Neo4jについてちょちょいと調べたまとめ
https://the.igreque.info/posts/2014-06-08-neo4j.html