前置き
みなさん、Slack使ってますか?
Slackのメッセージ履歴が残ってなくて困ったことはないでしょうか?
私はありますw
今回は、Slackの履歴をS3に格納して、Athenaでクエリできるようにする方法を紹介しようと思います。
コーディングとかもしてるので、もっと簡単にできる方法があったら是非教えてください!
手順
Slackアプリの作成
本手順はワークスペースごとに必要です。
1.https://api.slack.com/apps/にアクセスし、Create New Appをクリックします。
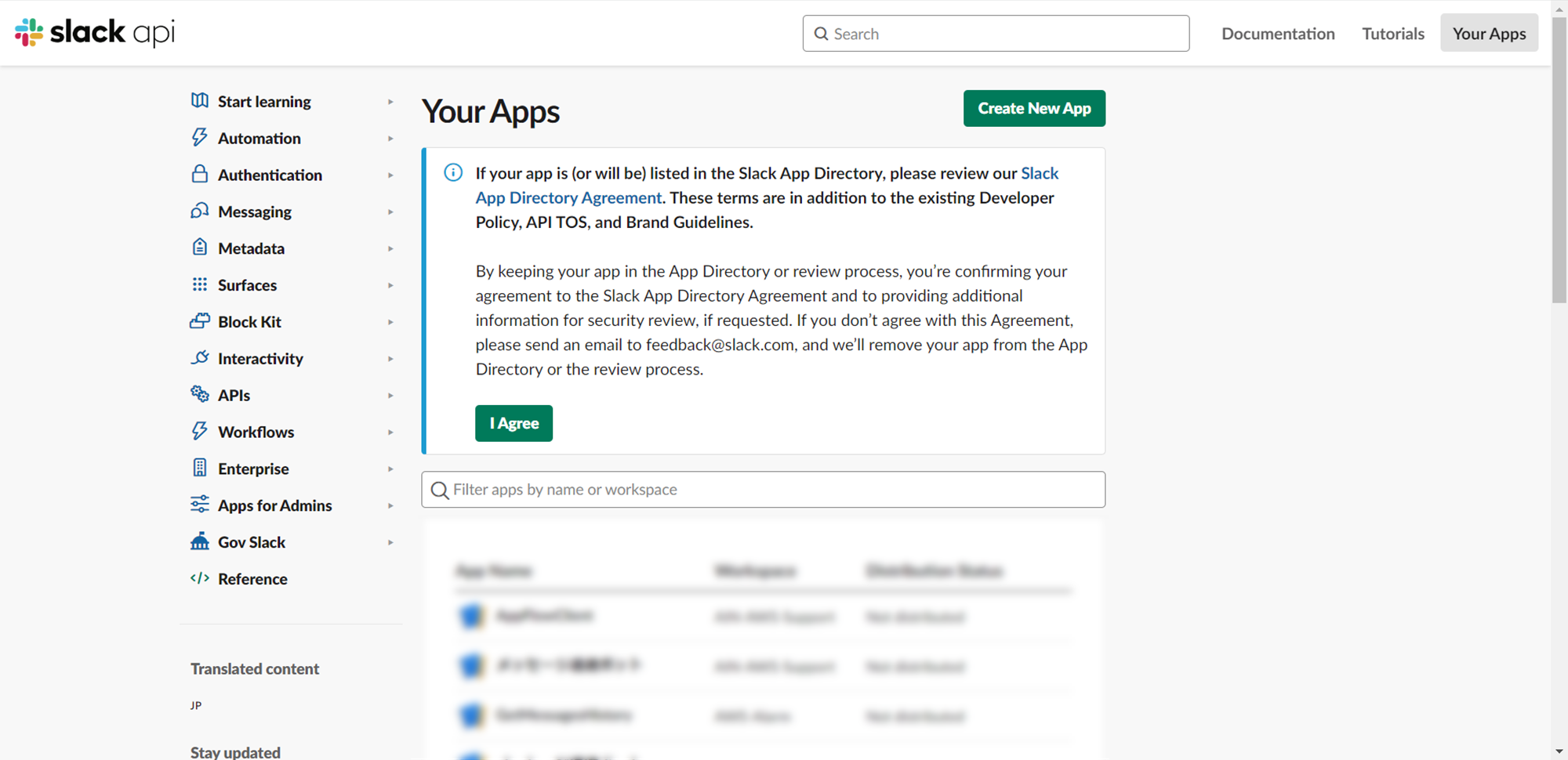
2.From scratchを選択します。
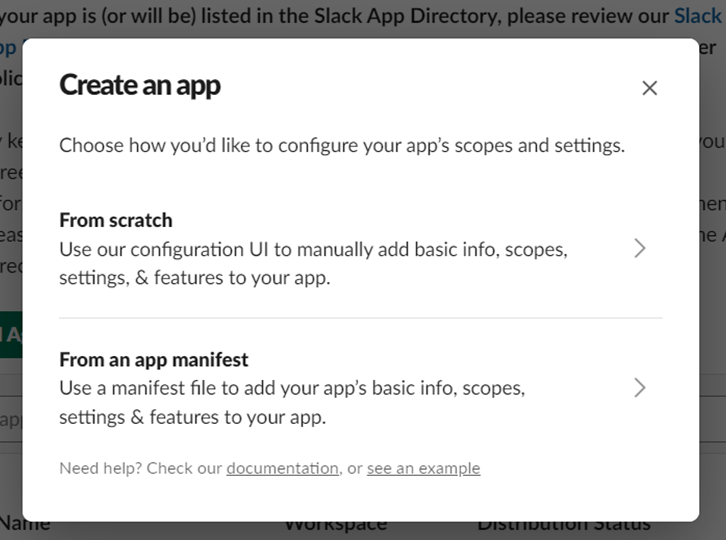
3.Sign into a different workspaceをクリックします。
4.Slackにサインインします。

5.メールに届いた認証コードを入力します。

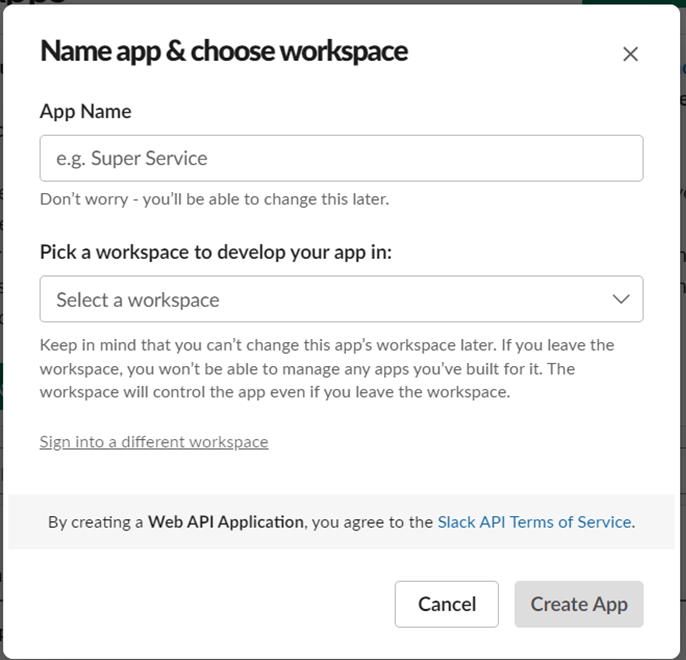
6.アプリを作成するワークスペースを選択します。
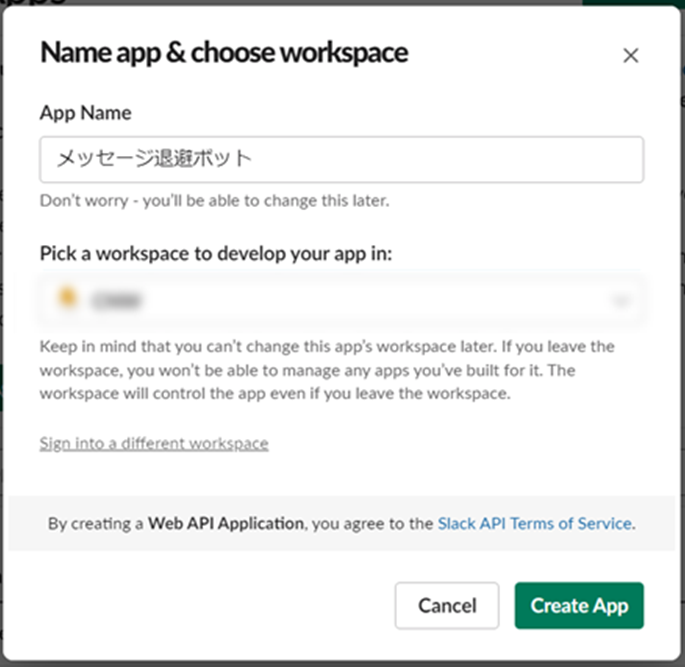
7.App NameとPick a workspace to develop your app in:を指定し、Create Appをクリックします。
Scopeの設定を行い、トークンを取得する
アプリの権限を設定し、トークンを取得します。
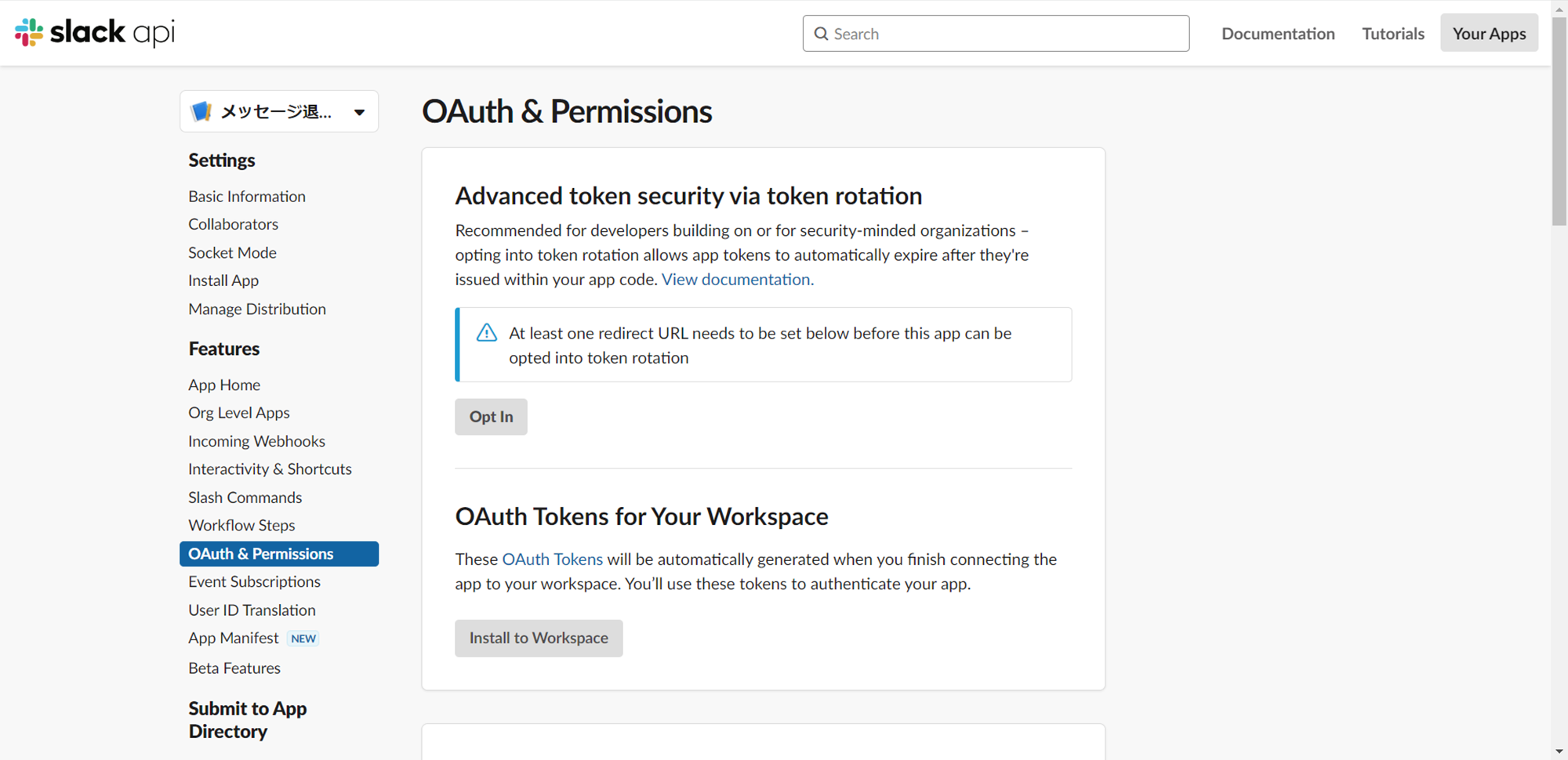
1.画面左のメニューからOAuth & Permissionsを開きます。
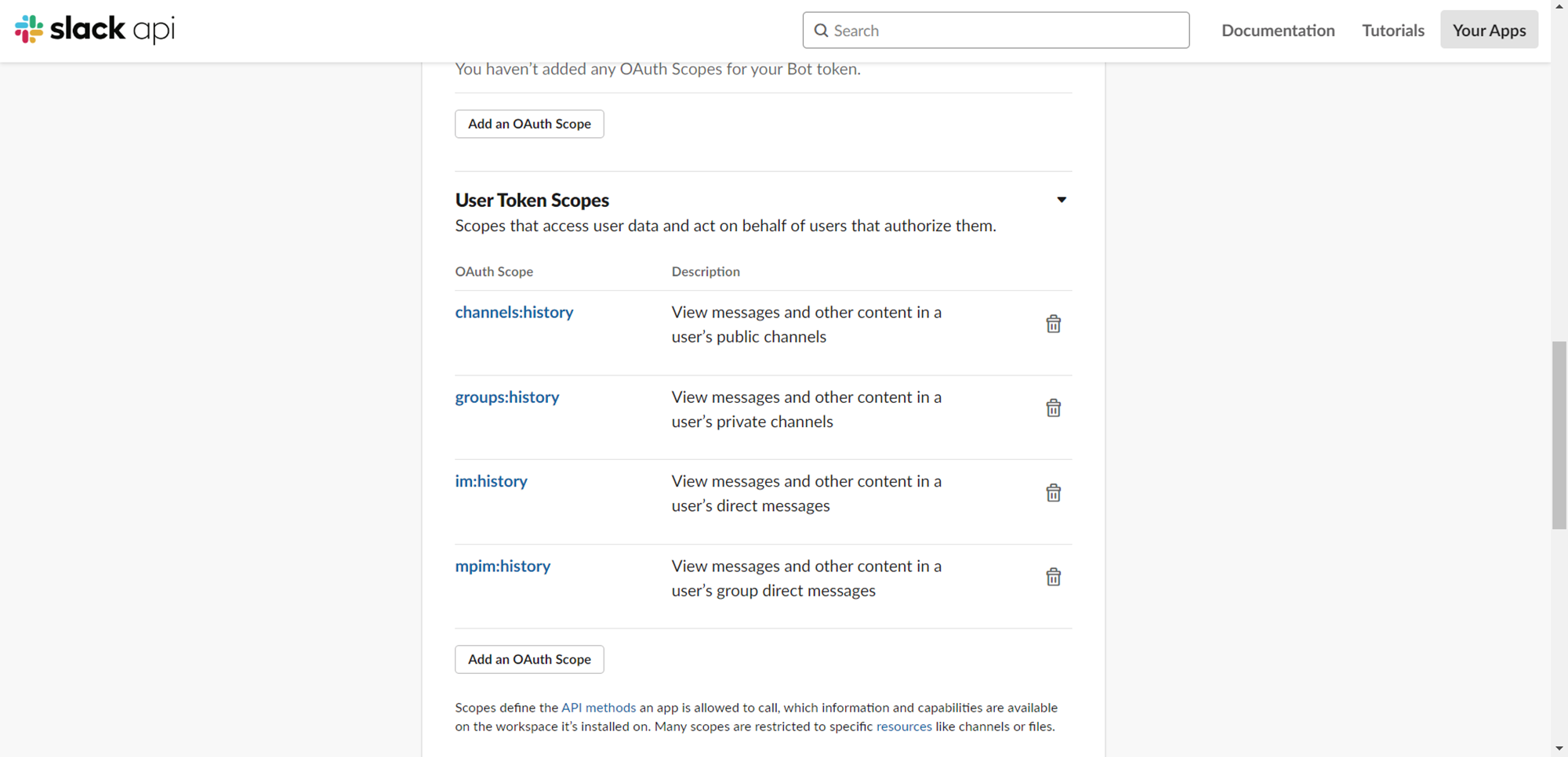
2.ScopesセクションのUser Token Scopesに下記の権限を追加します。
- channels:history
- groups:history
- im:history
- mpim:history
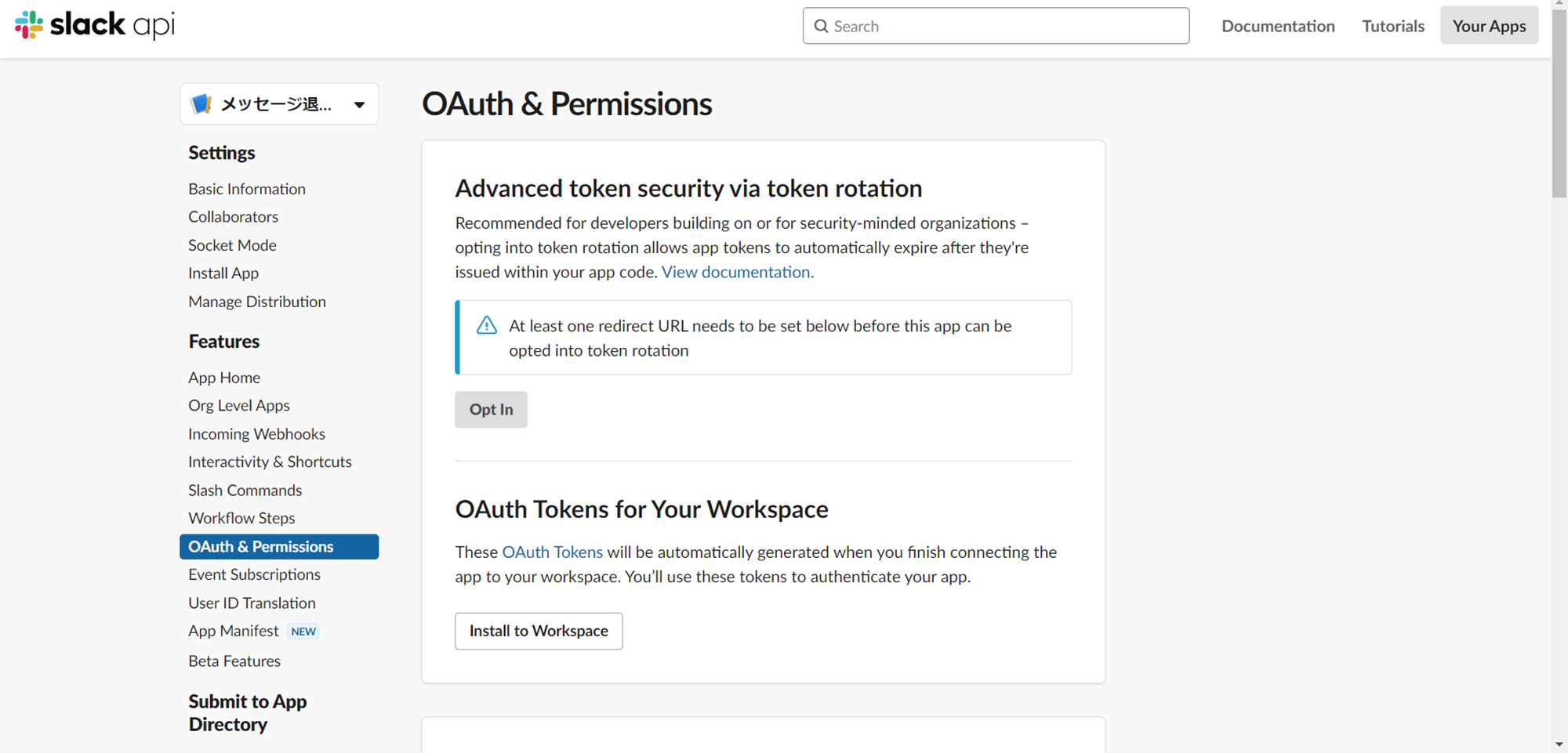
3.OAuth Tokens for Your WorkspaceのInstall to Workspaceをクリックします。
4.Allowをクリックします。
5.User OAuth Tokenの値をメモしておきます。
AWSリソースの作成
AWSのリソースを作成します。
面倒な人は、こちらを使って展開してもOKです。
概要
- 毎日前日のメッセージを取得して、parquetにエクスポートし、S3バケットにアップロードする
構成図
- 以下簡単な構成図(シンプル)
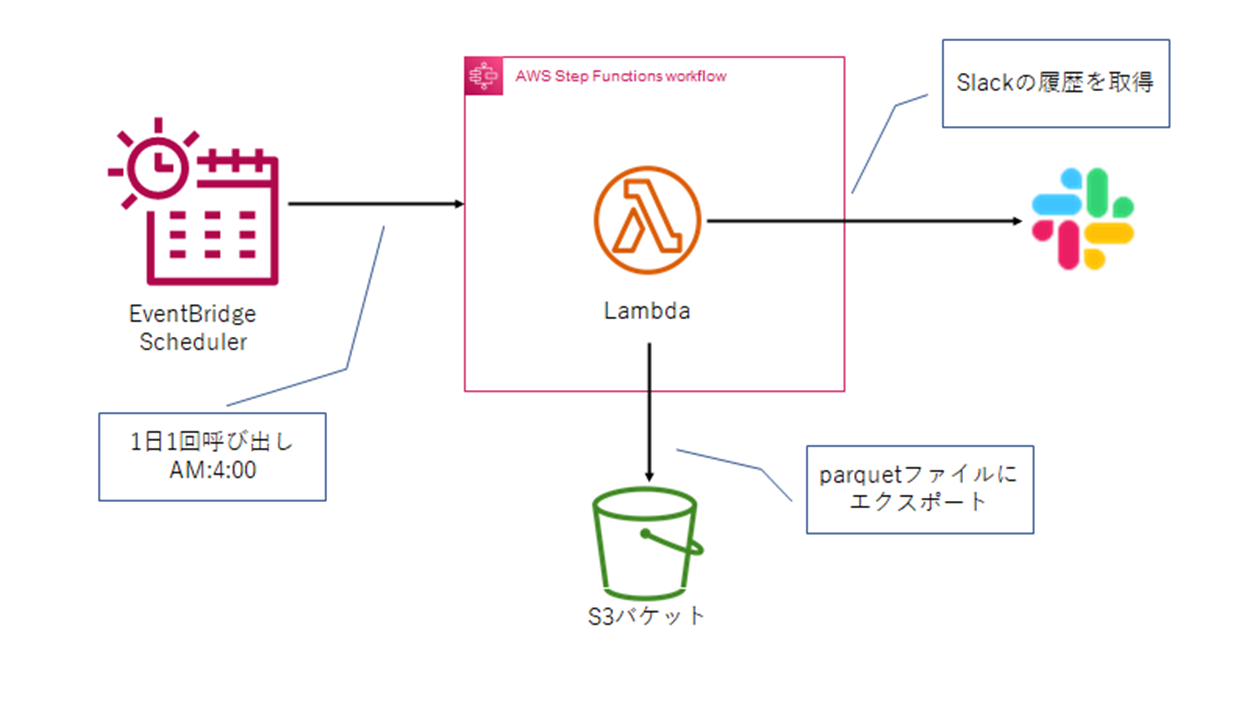
Step Functions
-
概要
- 複数のチャネルを対象にするため、StepFunctionsからLambdaを繰り返し呼び出す
- ワークフロー図は下図の通り
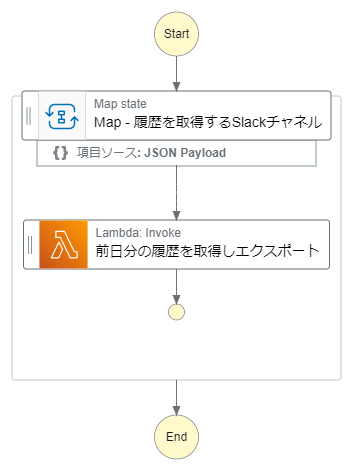
-
定義
- 定義は下記の通りです。(★部分を修正)
ステートマシン定義
{ "Comment": "A description of my state machine", "StartAt": "Map - 履歴を取得するSlackチャネル", "States": { "Map - 履歴を取得するSlackチャネル": { "Type": "Map", "ItemProcessor": { "ProcessorConfig": { "Mode": "INLINE" }, "StartAt": "前日分の履歴を取得しエクスポート", "States": { "前日分の履歴を取得しエクスポート": { "Type": "Task", "Resource": "arn:aws:states:::aws-sdk:lambda:invoke", "OutputPath": "$.Payload", "Parameters": { "FunctionName": "★<Lambda関数名>", "Payload.$": "$" }, "Retry": [ { "ErrorEquals": [ "Lambda.ServiceException", "Lambda.AWSLambdaException", "Lambda.SdkClientException", "Lambda.TooManyRequestsException" ], "IntervalSeconds": 2, "MaxAttempts": 6, "BackoffRate": 2 } ], "End": true } } }, "End": true, "ItemsPath": "$.channels" } } }
Lambda
-
概要
- 処理概要
- Slackの対象のチャネルから、指定された期間の履歴を取得
- 必要な情報を抽出し、parquetファイルにエクスポート
- 指定のS3バケットにparquetファイルを格納
- ランタイム
- python 3.10
- 処理概要
-
外部モジュール
- slackclient
- pandas
-
環境変数
- S3_NAME: 作成したS3バケット名
-
タイムアウト
- 適宜設定してください
-
コード本文
- コードは下記の通り
関数コード
import os import slack import json import logging from time import sleep import datetime import pandas as pd import boto3 # 定数 region = "ap-northeast-1" s3_name = os.environ['S3_NAME'] # Logger定義 logger = logging.getLogger() logger.setLevel(logging.INFO) def unix_to_datetime(unix): """ UNIX時間 => datetime """ try: return datetime.datetime.fromtimestamp(unix, datetime.timezone(datetime.timedelta(hours=9))) except Exception as e: logger.error(e) def unix_to_datetime_messages(messages): formatted_messages = [] for message in messages: formatted_message = {} message['ts'] = unix_to_datetime(float(message['ts'])) formatted_message = message formatted_messages.append(formatted_message) return formatted_messages class slack_channel(): def __init__(self, token, channel, oldest, latest): self.token = token self.channel = channel self.oldest = oldest self.latest = latest def export_result(self): print('=======================エクスポート処理開始=========================') print("{} - {}".format( self.oldest.strftime('%Y/%m/%d %H:%M:%S'), self.latest.strftime('%Y/%m/%d %H:%M:%S') )) print('Slack履歴取得(上限1000件)') history = self.get_history(1000) print('完了') print('unix時間を変換') history = unix_to_datetime_messages(history) print('完了') print('データフレーム化') df = pd.DataFrame(history) print('完了') try: ## parquetファイルの保存先ディレクトリを作成 / ファイルを定義 base_dir = '/tmp' if len(str(self.oldest.month)) == 1: month = '0' + str(self.oldest.month) else: month = str(self.oldest.month) if len(str(self.oldest.date)) == 1: date = '0' + str(self.oldest.day) else: date = str(self.oldest.day) target_dir_path = '{year}/{month}/{date}/{channel_id}'.format( year = str(self.oldest.year), month = month, date = date, channel_id = self.channel ) print('ローカルディレクトリ作成: {}'.format(os.path.join(base_dir, target_dir_path))) os.makedirs(os.path.join(base_dir, target_dir_path), exist_ok=True) print('完了') local_target_file_path = os.path.join( base_dir, target_dir_path, 'slack_history.parquet' ) s3_target_file_path = os.path.join( target_dir_path, 'slack_history.parquet' ) print('parquet出力') print(local_target_file_path) df.to_parquet(local_target_file_path, index = False) print('完了') s3_client = boto3.client('s3', region_name=region) print('S3にアップロード') s3_client.upload_file(local_target_file_path, s3_name, s3_target_file_path) print('完了') print('=======================エクスポート処理終了=========================') except Exception as e: logger.error(e) def get_history(self, limit): result = [] client = slack.WebClient(token=self.token) response = client.conversations_history( channel=self.channel, limit=limit, oldest = str(self.oldest.timestamp()), latest = str(self.latest.timestamp()) ) if not response['ok']: print('okキーがTrueではありません') logger.info('処理を中止します') return messages = response['messages'] for message in messages: tmp_dict = {} try: if 'thread_ts' not in message: tmp_dict['type'] = message['type'] tmp_dict['user'] = message['user'] tmp_dict['ts'] = message['ts'] tmp_dict['text'] = message['text'] tmp_dict['thread_id'] = None if 'attachments' in message: message_list = [] for attachment in message['attachments']: if 'blocks' in attachment: for block in attachment['blocks']: if 'text' in block: message_list.append(block['text']['text']) elif 'fields' in block: for field in block['fields']: message_list.append(field['text']) elif 'elements' in block: for element in block['elements']: message_list.append(element['text']) else: logger.info('キーのリスト:{}'.format(str(block.keys()))) tmp_dict['attachments'] = '\n\n'.join(message_list) if tmp_dict['text'] == "": print("テキストがないため、アタッチメントに置き換えます") tmp_dict['text'] = tmp_dict['attachments'] result.append(tmp_dict) else: thread_messages = self.get_thread_messages(message['thread_ts']) result.extend(thread_messages) except Exception as e: logger.error(e) return result def get_thread_messages(self, thread_ts): result = [] client = slack.WebClient(token=self.token) response = client.conversations_replies( channel=self.channel, ts = thread_ts, oldest = str(self.oldest.timestamp()), latest = str(self.latest.timestamp()) ) if not response['ok']: print('okキーがTrueではありません') logger.info('処理を中止します') return messages = response['messages'] for message in messages: tmp_dict = {} try: tmp_dict['type'] = message['type'] tmp_dict['user'] = message['user'] tmp_dict['ts'] = message['ts'] tmp_dict['text'] = message['text'] tmp_dict['thread_id'] = thread_ts if 'attachments' in message: message_list = [] for attachment in message['attachments']: if 'blocks' in attachment: for block in attachment['blocks']: if 'text' in block: message_list.append(block['text']['text']) elif 'fields' in block: for field in block['fields']: message_list.append(field['text']) elif 'elements' in block: for element in block['elements']: message_list.append(element['text']) else: logger.info('キーのリスト:{}'.format(str(block.keys()))) tmp_dict['attachments'] = '\n\n'.join(message_list) if tmp_dict['text'] == "": print("テキストがないため、アタッチメントに置き換えます") tmp_dict['text'] = tmp_dict['attachments'] result.append(tmp_dict) except Exception as e: logger.error(e) return result def lambda_handler(event, context): ## 現在の時間を取得 dt_now_jst_aware = datetime.datetime.now( datetime.timezone(datetime.timedelta(hours=9)) ) dt_yesterday_jst_aware = dt_now_jst_aware - datetime.timedelta(days=1) oldest = dt_yesterday_jst_aware.replace(hour=0, minute=0, second=0) latest = dt_yesterday_jst_aware.replace(hour=23, minute=59, second=59) channel = slack_channel(event['token'], event['channel'], oldest, latest) channel.export_result() return 'Success'
S3
- ディレクトリ構成(こんな感じに格納される)
root/ └ yyyy/ └ mm/ └ dd/ └ channel_id/ └ slack_history.parquet
EventBridge
- スケジュール
- 毎日4:00実行(何時でもわりといいですが、日付変わるところは避けてください)
- ターゲット
- 作成したStepFunctionsを指定します
EventBridgeのインプット編集
1.Amazon EventBridge Schedulerを開きます。
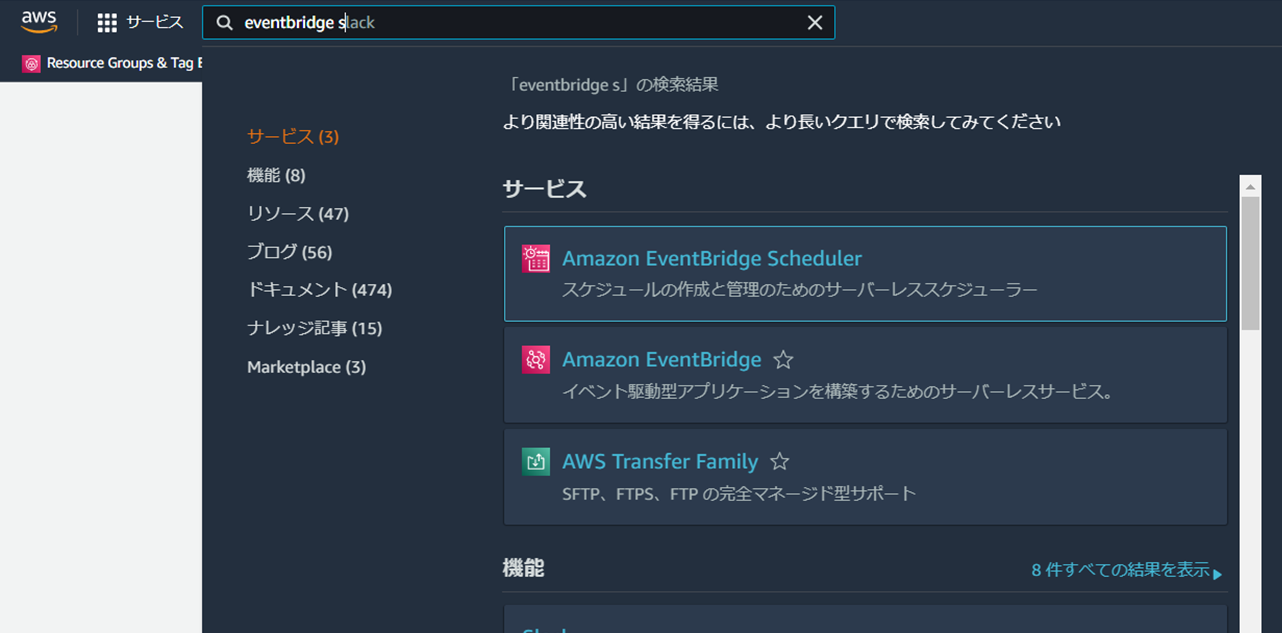
2.作成したスケジューラを開きます。
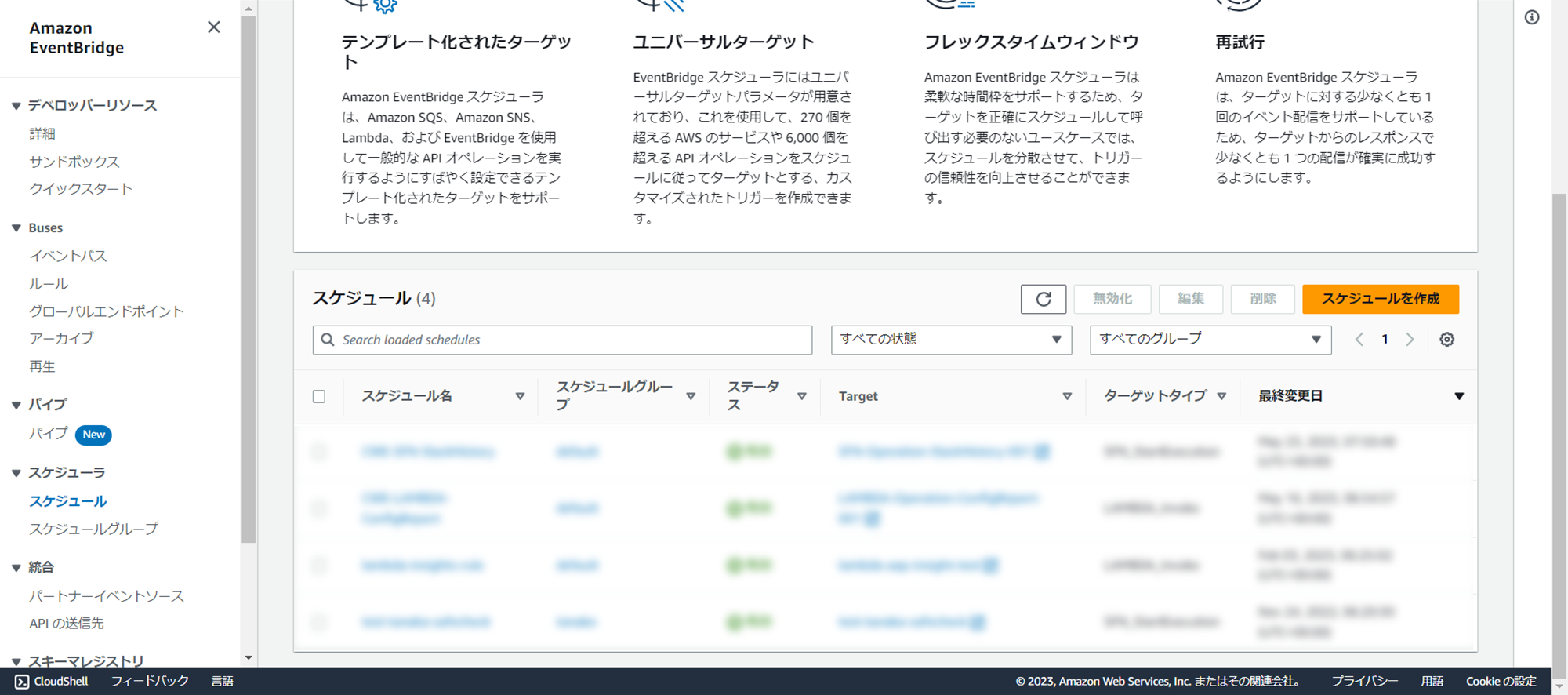
3.編集をクリックします。
4.ターゲットの選択をクリックします。
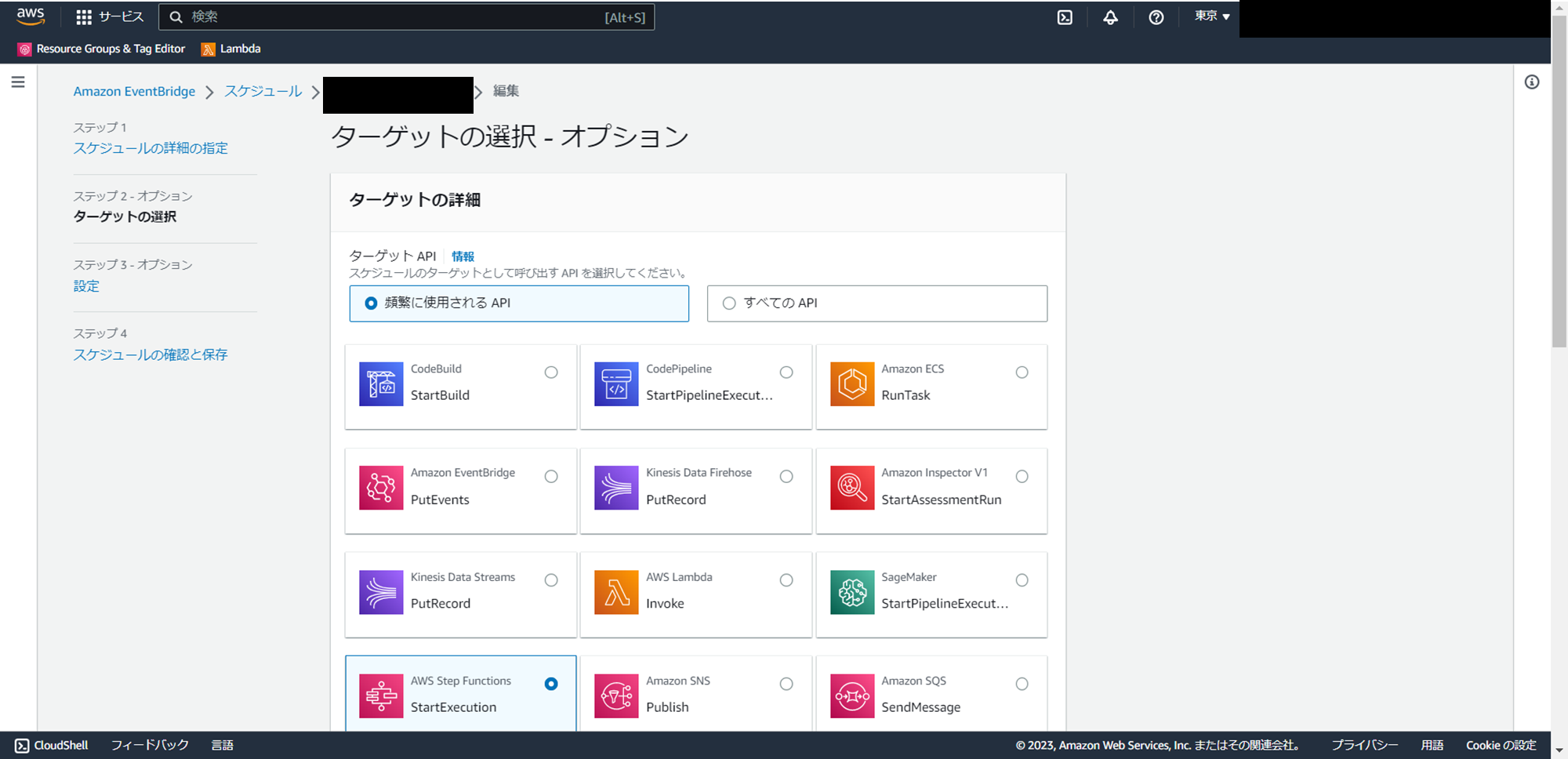
5.下記参考にInputを編集し、Skip to スケジュールの確認と保存をクリックします。
- インプット
- 下記はサンプル、取得したトークンとチャネルIDをリストにして渡します
- チャネルIDの取得方法はこちらを参照してください。
{ "channels" : [ { "token": "xoxp-xxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "channel": "C0XXXXXXXXX" }, { "token": "xoxp-yyyyyyyyyyyyyyyyyyyyyyyyyyyyy", "channel": "C0YYYYYYYYY" } ] }
6.スケジュールの保存をクリックします。
格納したファイルのクエリ方法
テーブルの作成
1.Athenaを開きます。
2.クエリエディタを開き、使用するワークグループとデータベースが正しいことを確認します。
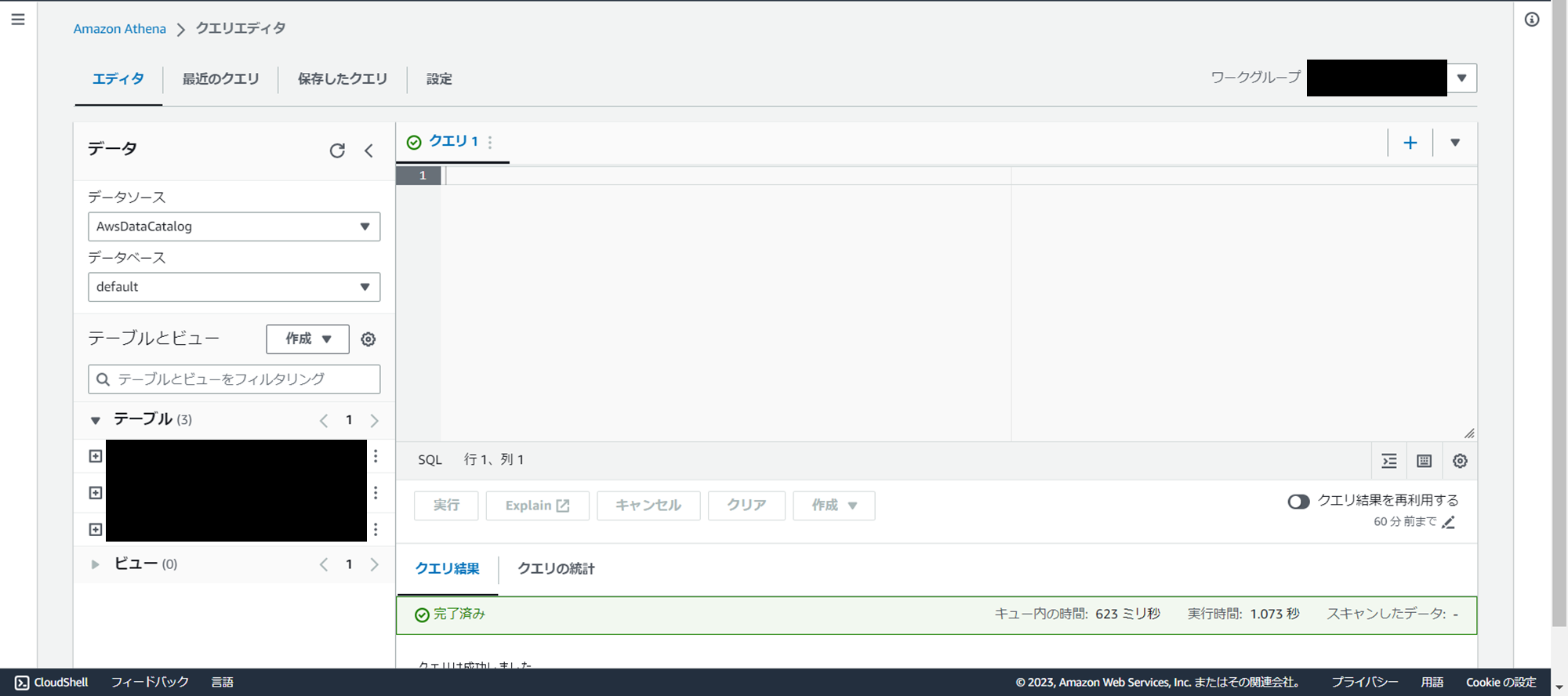
3.下記を参考にクエリを実行し、テーブルを作成します。
★がついている箇所は変更してください。
- テーブル名(他のテーブルと被らない名前にする必要があります)
- 取得するチャネルID
- 取得期間("2023/05/01-NOW"とした場合は、2023/05/01から本日までが対象)
CREATE TABLE文
CREATE EXTERNAL TABLE IF NOT EXISTS ★slack_history (
type string,
user string,
ts timestamp,
text varchar(10000),
thread_id string,
attachments varchar(10000)
)
PARTITIONED BY(`channel` string, `date` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1'
)
LOCATION 's3://★バケット名/'
TBLPROPERTIES (
'skip.header.line.count'='1',
'serialization.encoding'='SJIS',
"projection.enabled" = "true",
"projection.channel.type" = "enum",
"projection.channel.values" = ★"CXXXXXXX",
"projection.date.type" = "date",
"projection.date.range" = ★"NOW-1DAYS,NOW",
"projection.date.format" = "yyyy/MM/dd",
"storage.location.template" = "s3://★バケット名/${date}/${channel}"
)
サンプルクエリ
特定の文字を含むメッセージの取得(この例はタグという文字を含むものを抽出)
SELECT * FROM "default"."slack_history"
WHERE text LIKE '%タグ%';
特定のユーザーからのメッセージを取得
SELECT * FROM "default"."slack_history"
WHERE user = 'U0XXXXXXX';
Appendix
CloudFormationテンプレート
- Lambdaのコードは含んでいないので、こちらのzipファイルをアップロードして更新してください。
テンプレート
AWSTemplateFormatVersion: '2010-09-09'
Description: Slack History
Parameters:
StateMachineName:
Default: SlackHistoryMachine
Description: StepFunctions StateMachine Name
Type: String
FunctionName:
Default: SlackHistoryFunction
Description: Lambda Function Name
Type: String
BucketName:
Default: s3-slack-history-xxxxxxx
Description: bucket name
Type: String
SchedulerName:
Default: SlackHistoryScheduler
Description: Scheduler Name
Type: String
Resources:
S3Bucket:
Type: AWS::S3::Bucket
DeletionPolicy: Retain
Properties:
BucketName: !Ref BucketName
StateMachine:
Type: AWS::StepFunctions::StateMachine
Properties:
StateMachineName: !Ref StateMachineName
Definition:
Comment: A description of my state machine
StartAt: Map - 履歴を取得するSlackチャネル
States:
Map - 履歴を取得するSlackチャネル:
Type: Map
ItemProcessor:
ProcessorConfig:
Mode: INLINE
StartAt: 前日分の履歴を取得しエクスポート
States:
前日分の履歴を取得しエクスポート:
Type: Task
Resource: arn:aws:states:::aws-sdk:lambda:invoke
OutputPath: $.Payload
Parameters:
FunctionName: !Ref FunctionName
Payload.$: $
Retry:
- ErrorEquals:
- Lambda.ServiceException
- Lambda.AWSLambdaException
- Lambda.SdkClientException
- Lambda.TooManyRequestsException
IntervalSeconds: 2
MaxAttempts: 6
BackoffRate: 2
End: true
End: true
ItemsPath: $.channels
RoleArn: !GetAtt StateMachineRole.Arn
StateMachineRole:
Type: "AWS::IAM::Role"
Properties:
RoleName: !Sub ${StateMachineName}Role
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: "Allow"
Principal:
Service:
- "states.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaRole
LambdaFunction:
Type: AWS::Lambda::Function
Properties:
FunctionName: !Ref FunctionName
Runtime: python3.10
Role: !GetAtt LambdaFunctionRole.Arn
Handler: lambda_function.lambda_handler
Code:
ZipFile: |
return pass
Description: Slack History Function
Environment:
Variables:
S3_NAME: !Ref BucketName
Layers:
- arn:aws:lambda:ap-northeast-1:336392948345:layer:AWSSDKPandas-Python310:2
Timeout: 600
LambdaFunctionRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub ${FunctionName}Role
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: "Allow"
Principal:
Service:
- "lambda.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
LambdaFunctionPolicy:
Type: AWS::IAM::Policy
Properties:
PolicyName: !Sub ${FunctionName}Policy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:PutObject
Resource: !Sub ${S3Bucket.Arn}/*
Roles:
- !Ref LambdaFunctionRole
Scheduler:
Type: AWS::Scheduler::Schedule
Properties:
FlexibleTimeWindow:
MaximumWindowInMinutes: 900
Mode: FLEXIBLE
Name: !Ref SchedulerName
ScheduleExpression: cron(0 4 * * ? *)
ScheduleExpressionTimezone: Asia/Tokyo
State: ENABLED
Target:
Arn: !GetAtt StateMachine.Arn
RoleArn: !GetAtt SchedulerRole.Arn
SchedulerRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub ${SchedulerName}Role
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: "Allow"
Principal:
Service:
- "scheduler.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
SchedulerPolicy:
Type: AWS::IAM::Policy
Properties:
PolicyName: !Sub ${SchedulerName}Policy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- states:StartExecution
Resource: !GetAtt StateMachine.Arn
Roles:
- !Ref SchedulerRole
チャネルIDの取得方法
1.Slackの対象チャネルを開き、画面上部のチャネル名をクリックします。
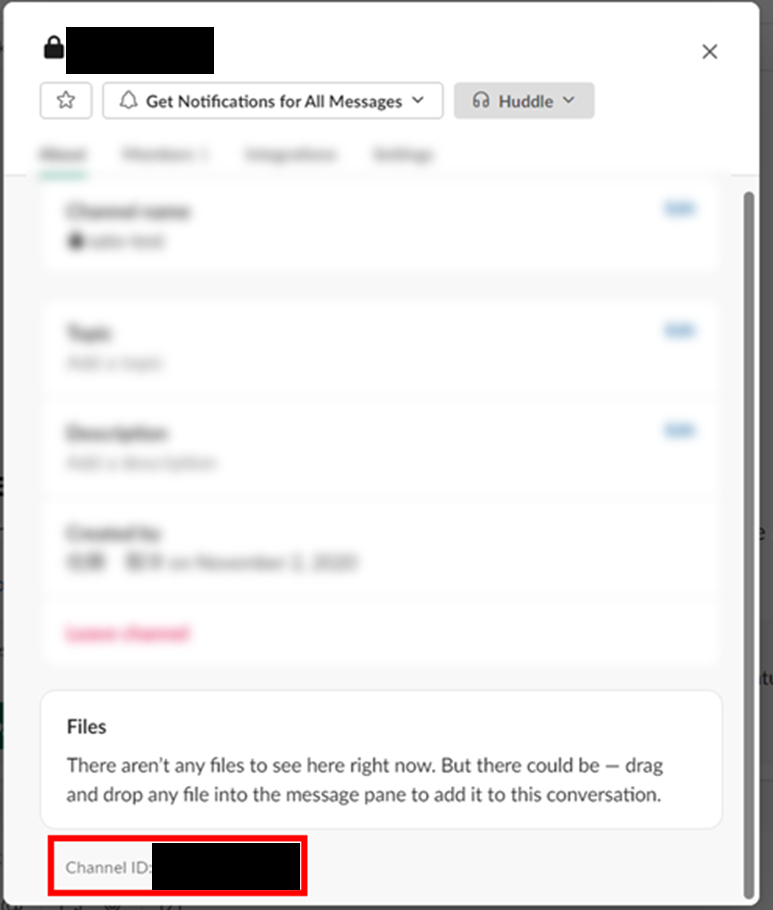
2.チャネルIDを取得できます。
あとがき
メッセージの形式によってはそのまま取得ができないので、無理やり結合したりしてます。
ちょいちょい履歴残ってない!って場面に遭遇することがあると思うので、よかったら使ってみてください~
それでは!