はじめに
Generative AIを使い始めると、よく次のような表現に出会います。たとえば「7B parameters」「128K context」「RoPE」「LoRA fine-tuning」「MoE model」などです。一見ばらばらの用語に見えますが、実際にはLLMを構成する複数の層を指しています。具体的には、tokenizer、Transformerアーキテクチャ、token生成、training/fine-tuning、そして運用です。
この記事は、LLMを学び始めたエンジニア向けの短いハンドブックです。model card、API config、モデルの技術資料を読んだときに、基本的な意味を見失わないことを目的にしています。
この記事で扱うLLMは、自然言語を生成するLarge Language Modelを指します。いくつかの考え方はマルチモーダルモデルにも当てはまりますが、ここでは理解しやすいようにtext modelを中心に説明します。
1. LLMの基本的な処理の流れ
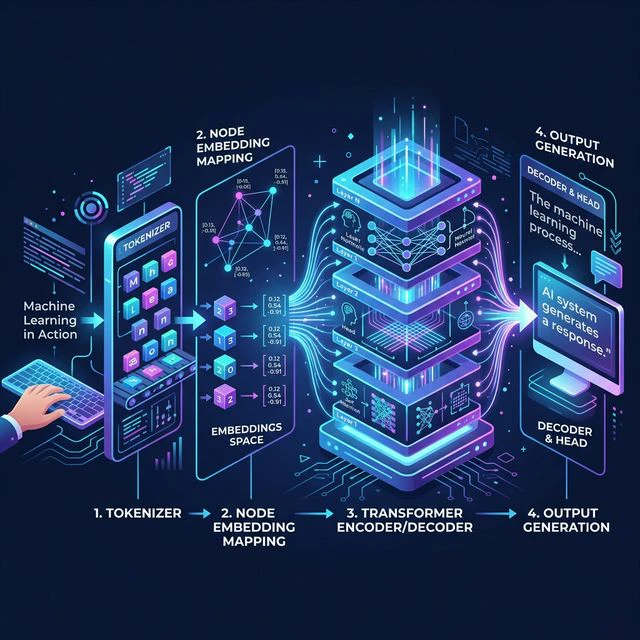
LLMは、人間が理解する意味で文章をそのまま読んでいるわけではありません。LLMが扱うのは、textを細かく分割したtokenの列です。
たとえば「私はLLMを勉強しています」という文は、tokenizerによっていくつかのtokenに分割されます。それぞれのtokenはtoken IDに変換され、さらに数値ベクトルに変換されます。その後、複数のTransformer layerを通り、最終的に次のtokenに対する確率分布が出力されます。
簡単に言うと、LLMは「文章全体を一気に書く」のではありません。次のtokenを予測し、それを何度も繰り返しています。
イメージ例:モデルが「今日は天気がとても...」という文を書いているとします。このとき、次に来る語として「良い」「暑い」「寒い」「悪い」などを候補として考えます。ひとつの語を選んだら、その新しい文全体を使って、さらに次の語を予測します。
2. Tokenizer、token、vocabulary
Tokenizerは、textをtokenに変換するコンポーネントです。小さな処理に見えますが、コスト、速度、言語処理の品質に大きく影響します。
tokenには、次のようなものがあります。
- ひとつの単語
- 単語の一部
- ひとつの文字
- 句読点
- 空白や特殊なpattern

Vocabularyは、モデルが知っているtokenの集合です。たとえばvocabularyが100,000 tokenある場合、tokenizerはtextをそれらに対応するIDへ変換できます。
英語では、よく使われる単語が1 tokenで表されることが多いです。一方、日本語、ベトナム語、または特殊文字を多く含むtextでは、token数が増えやすくなります。そのため、同じ長さに見える文章でも、言語によってtokenコストが変わることがあります。
イメージ例:tokenizerは、料理の前に材料を切る人のようなものです。同じニンジンでも、大きな輪切りにする人もいれば、細かい角切りにする人もいます。モデルは切られた後の材料だけを扱うため、切り方が後続の処理全体に影響します。
Context lengthは文字数や単語数ではなく、token数で数えます。APIが「128K context」と言っている場合、それはそのモデルのtokenizerで数えたinput + outputの合計が最大約128,000 tokenである、という意味です。
3. Embedding:tokenをベクトルに変換する
token IDが得られた後、モデルはそのtokenを数値ベクトルとして表現する必要があります。このベクトルをembeddingと呼びます。
token IDが辞書上の番号だとすれば、embeddingは多次元空間におけるtokenの座標のようなものです。意味が近いtokenは、学習の過程で近いベクトルになりやすくなります。
LLMにおけるembeddingは、単独のtokenの意味だけを保持しているわけではありません。Transformer blockを通るたびに、周囲のcontextに基づいてtokenの表現が更新されます。

イメージ例:それぞれの単語が地図上の店だと考えてみてください。「ご飯」「ラーメン」「うどん」は食べ物エリアの近くにあり、「ペン」「ノート」「本」は学習用品エリアの近くにあります。embeddingは、モデルがtokenをこのような意味の地図上に配置する方法です。
4. Transformer block:現代LLMの中核
多くの現代的なLLMはTransformerアーキテクチャをベースにしています。ひとつのモデルには、多数のTransformer blockが積み重なっています。各blockは、主に次の要素で構成されます。
- attention
- feed-forward network
- residual connection
- layer normalization
embeddingがtokenの初期表現だとすれば、Transformer blockはtoken同士の情報を混ぜ合わせ、よりcontextを反映した表現を作る場所です。
イメージ例:Transformer blockは、チーム内の短いミーティングのようなものです。それぞれの単語が周囲の単語に「自分に関係する情報は何か」を確認し、自分の理解を更新してから次のミーティングに進みます。
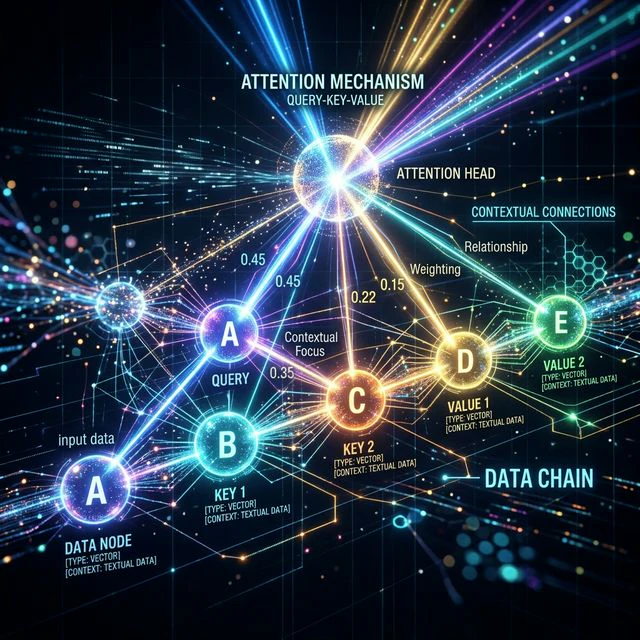
Attention、Q/K/V、multi-head attention
Attentionは、それぞれのtokenがcontext内の他のtokenを見て、どの情報が重要かを判断するための仕組みです。
self-attentionでは、各tokenから3種類のベクトルが作られます。
- Query (Q):このtokenは何を探しているのか
- Key (K):このtokenは他のtokenに対して、どのような情報を持っているのか
- Value (V):注目されたとき、このtokenはどの情報を渡すのか
Attentionは、あるtokenのQueryと他のtokenのKeyの関連度を計算し、その重みに基づいてValueを集約します。
Multi-head attentionとは、モデルが複数の「head」を持つという意味です。それぞれのheadは、文法、参照関係、順序、トピック、技術的なpatternなど、異なる関係を学習できます。
イメージ例:「花子は美咲に上着を渡しました。彼女が寒そうだったからです」という文では、「彼女」が誰を指すのかを判断する必要があります。Attentionは、すべての単語を同じ重みで見るのではなく、関連する単語により強く注目するための仕組みです。
Feed-forward network
Attentionの後、各tokenはfeed-forward networkと呼ばれる小さなネットワークを通ります。Attentionが他のtokenから情報を集める役割だとすれば、feed-forward networkはその情報を処理し、変換する役割を持ちます。
多くのLLMでは、feed-forward部分が非常に多くのパラメータを占めています。そのため、モデル構造を読むときはattentionだけを見ればよいわけではありません。
Residual connectionとLayerNorm
モデルが数十層、数百層と深くなると、学習は不安定になりやすくなります。Residual connectionは、古い情報がlayerを迂回して流れる経路を作り、gradientを安定させます。
LayerNormは、モデル内部のactivationを正規化し、学習を安定させる仕組みです。API利用者が直接調整することはほとんどありませんが、深いモデルを学習可能にするための重要な基盤です。
Positional encodingとRoPE
元のTransformerは、tokenの順序をそのまま理解できません。位置情報がなければ、「私はご飯を食べる」と「ご飯が私を食べる」の違いを扱えません。そのため、モデルには位置を表現する仕組みが必要です。
現代のLLMでよく使われる手法のひとつが**RoPE (Rotary Position Embedding)**です。RoPEは、位置ベクトルを単純にembeddingへ足すのではなく、ベクトル空間内の回転として位置を表現します。これはattentionや長いcontextの処理において特に有効です。
覚えておきたい点は、「context lengthが長い」というのは単に数字を大きくするだけではない、ということです。位置表現、attention、inference最適化と深く関係しています。
5. Logitsと次tokenの確率
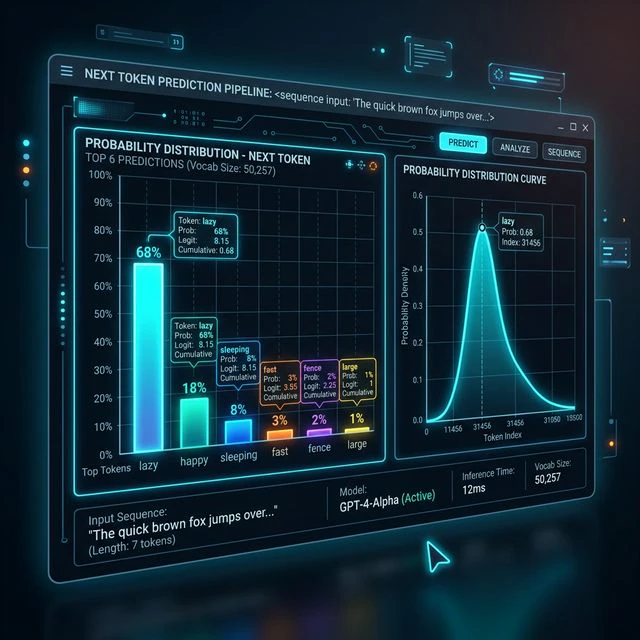
最後の段階で、モデルはlogitsを出力します。logitsの各要素は、vocabulary内のひとつのtokenに対応しています。logitが高いtokenほど、次に選ばれる可能性が高くなります。
その後、システムはsoftmaxやsamplingを使って次のtokenを選びます。常に最も確率が高いtokenを選ぶと、出力は安定しやすくなりますが、硬くなったり繰り返しが増えたりします。一方、samplingを柔軟にすると自然な出力になりやすいですが、予測しにくくなります。
ここでtemperature、top_p、top_kのようなパラメータが意味を持ち始めます。
イメージ例:現在の文が「私はご飯を...」だとすると、モデルは次のtokenを次のように見積もるかもしれません。
| 次のtoken | 例としての確率 |
|---|---|
| "食べる" | 40% |
| "作る" | 20% |
| "炊く" | 15% |
| "買う" | 10% |
| "見る" | 5% |
ここでの数値は、特定のモデルの実際の確率ではありません。あくまでイメージです。モデルは常に複数の候補を持っており、samplingがどの候補を選ぶかを決めます。
6. よく見るアーキテクチャ上のパラメータ
| パラメータ | 意味 | 実務上の影響 | よくある誤解 |
|---|---|---|---|
| Parameter count | モデル内で学習されたweightの数 | 表現力、実行コスト、メモリ使用量に関係する | パラメータが多いほど常に優れている |
| Layers | Transformer blockの数 | 深いモデルほど複雑な表現を学習しやすい | layerが多いほど常に速く、良い |
| Hidden size | 内部ベクトルの次元数 | 表現力と計算コストに影響する | hidden sizeだけ大きければ十分 |
| Attention heads | attention headの数 | context内の複数の関係を学習しやすくする | headが多いほど常に賢い |
| KV heads | key/value headの数。GQA/MQAと関連することが多い | inferenceコストやKV cacheを削減できる | KV headが少ないとモデルが弱い |
| Context length | モデルが処理できる最大token数 | 1 requestで扱えるinput/output量を決める | contextが長ければ、すべての情報を同じ品質で使える |
| Vocabulary size | tokenizer内のtoken数 | tokenization、多言語、code、特殊文字の扱いに影響する | vocabularyが大きいほど常に良い |
| Dense vs MoE | Denseは全体を使い、MoEは一部のexpertを使う | MoEはtokenごとのコストを抑えつつモデル容量を増やせる | MoEの総パラメータ数がそのままtokenごとの実行コストになる |
Parameter count
Parameterとは、trainingの過程でモデルが学習したweightのことです。7B modelは約70億、70B modelは約700億のparameterを持ちます。
parameterが多いほど複雑なpatternを学びやすい傾向はありますが、すべてのuse caseで優れているとは限りません。データ品質、training方法、instruction tuning、alignment、inference setupも重要です。
イメージ例:parameterは、自動コーヒーマシンの内部にある調整つまみの数のようなものです。つまみが多ければ細かく調整できますが、豆が悪かったりレシピが間違っていたりすれば、おいしいコーヒーにはなりません。
Context length
Context lengthは、モデルが一度に処理できる最大token数です。ただし注意が必要です。contextが長いからといって、すべてのtokenを同じ品質で使えるとは限りません。
実際には、モデルがcontextの中央付近の情報を見落としたり、長すぎるinputによってノイズが増えたりすることがあります。RAGでは長いcontextは有利ですが、retrievalやrerankingも依然として重要です。
イメージ例:context lengthは作業机の大きさに似ています。机が大きければ多くの書類を置けます。しかし書類が整理されずに積み上がっているだけなら、必要なページを見つけるのは難しくなります。
Dense modelとMoE
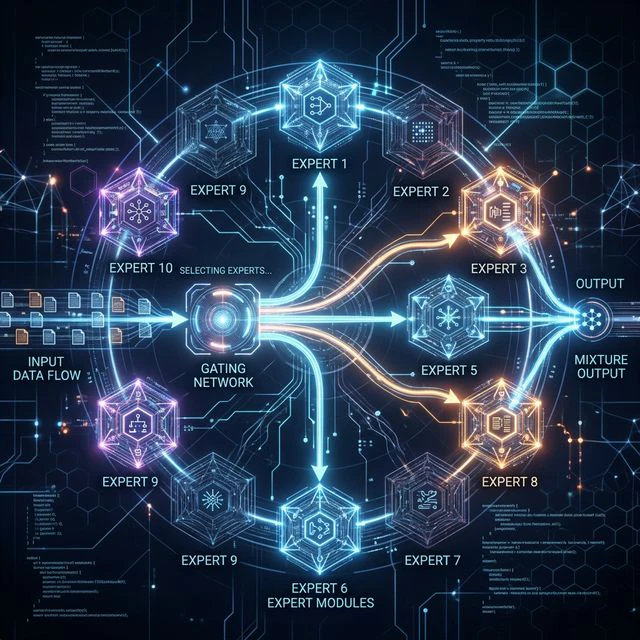
Dense modelは、各tokenに対してほぼすべてのparameterを使います。一方、MoE (Mixture of Experts) は複数のexpertを持ちますが、各tokenはrouterが選んだ一部のexpertだけを通ります。
そのため、MoEは総parameter数が非常に大きくても、tokenごとのinferenceコストは同じ総parameter数のdense modelより低くなることがあります。MoEのmodel cardを読むときは、次の点を分けて見る必要があります。
- total parameters
- active parameters per token
- expertの数
- tokenごとに有効化されるexpertの数
イメージ例:dense modelは、どんな質問にも会社全員が会議に参加するようなものです。MoEは、多くの専門家がいる相談窓口に近く、質問ごとに最も合いそうな数人だけが対応します。
7. 文章生成時のパラメータ
APIを呼び出したり、localでモデルを動かしたりすると、inference用のパラメータをよく見かけます。これらはモデルのweightを変えるものではなく、次のtokenをどう選ぶかを変えるものです。

| パラメータ | 意味 | 使う場面 |
|---|---|---|
temperature |
ランダム性を調整する | 低い値は安定したtask向け、高い値はbrainstorming向け |
top_p |
累積確率がpに達するtoken集合から選ぶ | top_kより柔らかく多様性を制御する |
top_k |
確率が高い上位k個のtokenだけを見る | sampling候補を制限する |
max_tokens |
最大output token数 | コストと出力長を制御する |
stop |
generationを止める文字列 | outputを特定のformatで終わらせたいとき |
frequency_penalty |
何度も出ているtokenを抑制する | 同じ語句の繰り返しを減らす |
presence_penalty |
すでに出たtokenを抑制する | 話題を広げやすくする |
seed |
対応している場合、乱数源を固定する | 再現性を高める。ただし完全保証ではない |
Temperature
temperatureが低いほど、モデルは確率の高いtokenを優先します。分類、JSON抽出、安定した要約などでは、低めのtemperatureがよく使われます。
temperatureを高くすると、outputは多様になりやすくなります。アイデア出しやbrainstormingには向いていますが、要求から外れやすくもなります。
イメージ例:「私はご飯を...」という文で、temperatureが低い場合、最も確率が高い「食べる」をほぼ選び続けます。temperatureが高い場合は、「作る」「炊く」「買う」のような候補にもチャンスが生まれ、出力が多様になります。
Top_pとtop_k
top_kは候補tokenの数を制限します。たとえばtop_k = 50なら、モデルは確率が高い上位50 tokenの中からだけ選びます。
top_pは、累積確率がpに達するまでのtoken集合を候補にします。
多くの現代的なAPIでは、まずtemperatureとtop_pを調整するだけで十分なことが多いです。明確なevaluationがない段階で、多くのパラメータを同時に動かしすぎない方がよいでしょう。
イメージ例:メニューに100品あるとします。top_k = 10は、最も合いそうな10品の中からだけ選ぶという意味です。top_p = 0.9は、妥当そうな候補を確率の高い順に集め、合計が約90%に達したところで、その候補群の中から選ぶイメージです。
Max tokensとstop
max_tokensはoutputの長さを制限します。コストを管理し、モデルが長く答えすぎるのを防ぐために重要です。
stopは、特定のmarkerでgenerationを止めたいときに便利です。複数recordの生成、code block、明確な境界を持つformatを返す場合などに使えます。
8. Trainingとfine-tuning
LLMは、製品で使える状態になるまでに複数の段階を通ります。
Pretraining
Pretrainingは、モデルが大量のtextから学習する段階です。基本的なtaskは、多くの場合「次のtokenを予測すること」です。この段階で、モデルは言語、一般知識、code pattern、データ内の統計的な関係を学びます。
Pretrainingには非常に大きなcomputeが必要です。重要な要素には、次のようなものがあります。
- training token数
- データ品質
- モデルサイズ
- training step数
- compute budget
Scaling lawやChinchillaの研究は、parameterだけを増やしてtoken数やcomputeを無視してはいけないことを示しています。大きなモデルでも、十分なデータでtrainされていなければ、適切にtrainされた小さなモデルより効率が悪くなることがあります。
イメージ例:pretrainingは、人が大量の本、新聞、会話、資料を読んで、言語の仕組みを学ぶ段階に似ています。その人は、まだあなたの具体的な依頼に正しく答える訓練を受けていないかもしれませんが、文章を理解する基礎は身につけています。
Supervised fine-tuningとinstruction tuning
pretraining後のモデルはtextを予測できますが、必ずしもinstructionにうまく従えるとは限りません。**Supervised fine-tuning (SFT)**では、instruction-responseのペアを使い、ユーザーが期待する形式で回答するようにモデルを教えます。
Instruction tuningは、要約、翻訳、分類、code説明、format付き回答など、指示に従う能力を高めることに焦点を当てます。
イメージ例:pretrainingが多くの本を読む段階だとすれば、instruction tuningは試験での答え方を練習する段階です。知識を持っているだけでなく、ユーザーが「要約して」と言ったら短く書く、JSONを求めたら正しいformatで返す、といった振る舞いを学びます。
RLHFとRLAIF
RLHF (Reinforcement Learning from Human Feedback) は、人間のfeedbackを使って、モデルの回答をより有用で安全かつ適切な方向に調整する手法です。RLAIFは似た考え方ですが、プロセスの一部でAI feedbackを使います。
アプリケーション開発者として覚えておきたいのは、alignmentはモデルに「すべての知識を追加する」ものではなく、回答の振る舞いを調整するものだという点です。文体、拒否の仕方、instructionへの従い方、安全性などに影響します。
イメージ例:RLHFは、先生が複数の回答例を見て「この回答は役に立つ」「これは冗長」「これは危険なので答えるべきではない」と評価するようなものです。モデルは、どのような回答が好まれるかを少しずつ学びます。
LoRAとadapter fine-tuning
大きなモデル全体をfine-tuneするには、多くのリソースが必要です。LoRAはparameter-efficient fine-tuningの手法です。すべてのweightを更新する代わりに、一部のlayerに小さな低rank行列を追加し、その部分だけをtrainします。
LoRAの主な利点は次の通りです。
- full fine-tuningよりVRAM使用量が少ない
- adapterが元モデルよりずっと小さい
- domainごとに複数のadapterを持てる
- 特定task向けにモデルを調整しやすい
ただし、LoRAは魔法ではありません。データ品質が悪かったり、output formatが曖昧だったりすると、fine-tuningは失敗することがあります。
イメージ例:full fine-tuningは教科書全体を書き換えるようなものです。LoRAは、重要な数章に薄い補足ノートを貼り付けるようなものです。軽くて速い一方で、土台そのものが間違っている場合に全体を置き換えるものではありません。
9. 実務でモデルを選ぶとき
製品で使うモデルを選ぶときは、leaderboardやparameter数だけを見るべきではありません。まずuse caseから考える必要があります。

Quality、latency、cost
この3つは、しばしばトレードオフになります。
- 大きなモデルは品質が高い傾向があるが、遅く高価になりやすい
- 小さなモデルは速く安価だが、複雑なreasoningでは弱くなりやすい
- 長いcontextは便利だが、tokenコストとlatencyが増える
- 長いoutputは体験を遅くし、コストも増やす
productionでは、「最も強いモデル」よりも、latencyとcostが許容範囲に収まる「十分に良いモデル」が適していることが多いです。
Benchmarkはあくまでシグナル
Benchmarkは相対比較には役立ちますが、社内evaluationの代わりにはなりません。reasoning benchmarkで高得点のモデルが、日本語の請求書抽出、社内ticket分類、特定codebaseのtest生成に強いとは限りません。
実データから小さなevaluation setを作ることをおすすめします。
- 代表的な50-100件のcase
- 明確なexpected output
- 具体的な採点基準
- モデルやpromptを変えたときの再テスト
大きなモデル、小さなモデル、fine-tuneをどう使い分けるか
taskが曖昧で、inputが多様で、深いreasoningが必要な場合、またはprototype段階では、大きなモデルが向いています。taskが狭く、繰り返しが多く、低latencyが必要で、input/outputを制御しやすい場合は、小さなモデルが向いています。
taskが安定しており、formatやdomain説明のためにpromptが長くなりすぎる場合、または一貫した文体が必要で、十分にきれいなtraining dataがある場合は、fine-tuningを検討できます。
単に「資料をモデルに詰め込みたい」だけなら、fine-tuningは適切ではないことが多いです。頻繁に変わる知識には、RAGの方が向いています。
10. model card/configを1分で読むためのチェックリスト
新しいモデルに出会ったら、次の順番で確認すると整理しやすくなります。
- そのモデルは何向けか:chat、code、reasoning、embedding、reranking、multimodalのどれか
- licenseは自分のuse caseで使えるものか
- parameter countはいくつか。DenseかMoEか。MoEならactive parametersはいくつか
- context lengthとoutput上限は何tokenか
- tokenizerは日本語、ベトナム語、code、特殊文字をうまく扱えるか
- benchmarkは自分のuse caseに関係しているか。それとも一般的な点数にすぎないか
- latencyとcostはproductionに合うか
- structured output、tool calling、fine-tuning、LoRAに対応しているか
- 運用上のリスクは何か:hallucination、privacy、prompt injection、schema違反など
まとめ
LLMは、単なる大きなweight fileではありません。複数の層からなるシステムです。
- tokenizerはtextをどのようにtokenへ分割するかを決める
- embeddingはtokenをベクトルに変換する
- Transformer blockはcontextとtoken間の関係を処理する
- logitsとsamplingは次のtokenを決める
- アーキテクチャ上のパラメータは性能、コスト、制限に影響する
- inference parametersはoutputの安定性と多様性に影響する
- training/fine-tuningはモデルが何を学び、どう振る舞うかを決める
- 実際のdeploymentではquality、latency、costのバランスが常に重要になる
最初に覚えておくべきことは、LLMのパラメータを独立した数字として読まないことです。「このパラメータは自分のuse caseにどう影響するのか」と考えると、model cardやAPI configはかなり読みやすくなります。