このエントリは、SoftLayer Advent Calendar 2015の12日目のエントリーです。
SoftLayerの特徴のひとつである「ベアメタル」サーバー。今日はこのベアメタルについて、SoftLayerでどこまで行っているのか、最新情報をまとめてご紹介します。
SoftLayerで利用できるベアメタル・サーバー
オーダー時は、ソケット数が1,2,4の3種類から選択することになります。
ご存知のとおり、IAサーバーのラインナップとなっています。現時点の最新のCPUは、E5-2690v3ですね。
CPUのラインナップが最も充実しているのが、2ソケットのベアメタルです。次いで1ソケット、4ソケットとなります。
このところ、データセンターではE5-2600v3(Haswell)のラインナップが充実してきました。つまり、少し前のCPU(SandyBridgeやIvyBridge)を選択できるデータセンターが減ってきています。コア数やクロック周波数で昔のCPUが必要な場合は、オーダーに先立ってTicketで在庫を確認しておくとよいでしょう。
特に、4ソケットのベアメタルはCPUの世代交代が今まさに実施されているため、必要なCPUが選択できるかを前もって確認しておくことをお勧めします。
SoftLayerのベアメタルのデフォルト設定
OS以上の設定は仮想サーバーと同じです。
ベアメタルならではの設定としては以下の二つが代表格ですね。
Hyper Threading(HT)
Turbo Boost(TB)
HTは、CPUの物理的な1コア上に2つのスレッドを動かして、あたかも2コアあるかのように処理するIntel入ってるですね。
TBは、利用されていないCPUコアの処理性能を使って、利用されているCPUコアのクロック周波数を上げるというテクノロジーです。
それぞれ、デフォルトでは、HT=ON、TB=OFF となっています。
コア数を多く必要とするアプリケーションであれば、HTはデフォルトのONでよいでしょう。コア数依存のライセンスソフトを利用していたり、CPUの処理性能が必要なエンジニアリングなどでは、HTをOFFにするのを忘れないようにしましょう。
HTのON/OFF切り替えは、Ticketで依頼するのが最も簡単です。以下の例文を参考に依頼すれば、すぐに適用されます。
-
HyperThreadingの切り替え依頼Ticketサンプル
タイトル: Please Turn ON/OFF the HyperThreading of Server XXX
本文: Please Turn ON/OFF the HyperThreading of Server XXX. I am ready to reboot the system anytime. -
依頼時の注意事項
Server xxxの箇所に対象のベアメタルを指定してください。またこの変更はBIOSの操作を伴うためシステムが再起動されます。パスワードを変更している場合はTicketのパスワード欄に記載するか、ベアメタルのPasswordsタブ内に記載しておき、「Use Password on File」にチェックしておきましょう。
SoftLayerでDeep Learningといえば
SoftLayerでは、NVIDIA Tesla K80が最大2枚まで挿せるベアメタルが標準です。このベアメタルとGPUでDeep Learningするツールとして、NVIDIA提供の「DIGITS」をご存知ですか?
サンプルで、航空写真の画像解析を動かしてみました。
SoftLayerでは、Ticket経由で最大4枚のGPUまで挿せるベアメタルを利用できます。
Deep Learningでその差を少し見て見ましょう。同じモデルデータを使って同じ条件で同じ世代分の学習をさせてみて、どの程度の時間の短縮が図れたか、という観点です。
2枚利用した「aerial」は、10時間38分、4枚利用した「JG Test」では、6時間4分です。2倍のGPUを利用して、約4割ほど学習時間を短縮することが出来ています。
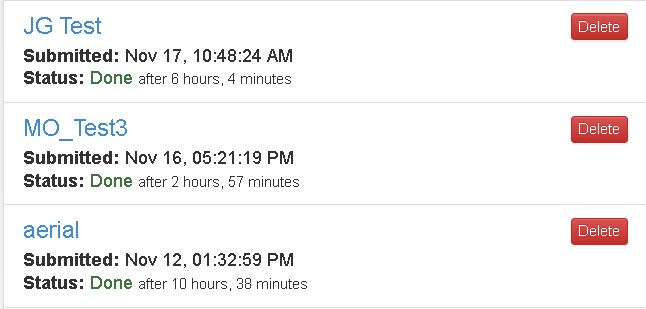
$$図1.学習結果一覧:表示されている時間は学習にかかった時間$$
学習の条件が同じなので、分析の精度はどちらの場合も同じです。しかし、多くのGPUを利用すれば、同じ時間でより多くの学習をすることができます。つまり、Deep Learningの精度を上げられるのです。仮想GPUが多いパブリッククラウドにおいて、物理的なK80 GPUが4枚も利用できるなんて、SoftLayerだけですね。
ちなみに、web上にあるレインボーブリッジの航空写真を判定してみました。
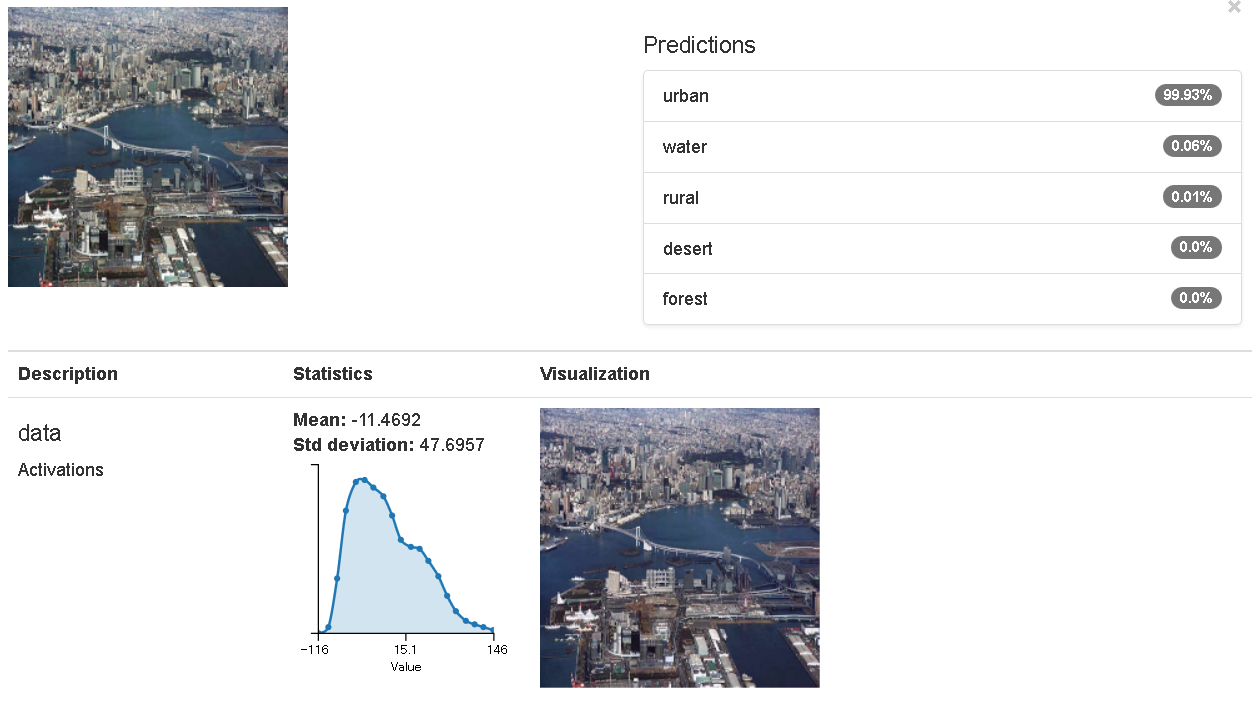
$$図2.分類結果例$$
urban(市街地の写真である率、99.93%)だと、ちゃんと判断してくれていますね。ホッ。
ベアメタルを使った並列計算とかCAEとか
SoftLayerでは、現在、Infinibandが利用できるのはヒューストンのデータセンターのみです。その為、高速かつ低レイテンシのInter-connect環境が必要な多くのシステムでは、ベアメタルのUplink Port Speedで「10 Gbps Redundant Public & Private Network Uplinks」を選択しましょう。
こちら、Bonding Mode=4、つまり、動的リンクアグリゲーションが利用できるのです。オンプレミスだとスイッチの設定とか大変ですが、SoftLayerではそういった面倒な設定はすべてSoftLayerがやってくれます。
10GbpsのNICを2つ使って冗長化構成が組めるのですが、これをInter-connectの代わりに使うのです。20Gbpsではなく、あくまでも、2x10Gbpsなのでご注意を。10Gbpsの物理的な帯域にボトルネックが来るのを少しだけ緩和できます。
ちなみに、Bonding Modeの変更は出来ません。といっても、Bonding Mode=4は並列計算の用途としては最適ですので、特に設定変更を交渉する必要はありません。
CAE の代表的なアプリで動かしてみた
オンプレミスの環境で、Infinibandを使わず、わざわざBondingでCAEを使う、なんてことをしているユーザーは一人もいないはず。
ならやってみるか、ということで代表的なアプリと公開データを使って性能評価してみました。流体については、ANSYS Flentとか、SCRYUとかStreamとかもやってますが、ここでは代表的な上記の三つをご紹介します。結論から言うと、以下の通りでした。勿論、モデルの規模やパラメータによって結果は異なりますので、あくまでもご参考までに。
- 構造解析(MSC Nastran):性能バッチリ。価格的にも使いやすい。
- 衝突解析(LS-Dyna):200並列くらいまでなら使い物になりそう。
- 流体解析(STAR-CCM+):300並列くらいまでなら使い物になりそう。
これらのソフトウェアの多くは、クラウド対応のライセンスを提供元や販売代理店から購入することが出来ます。ほとんどが月課金型ですので、SoftLayerのベアメタルの月課金型と相性がよいですね。
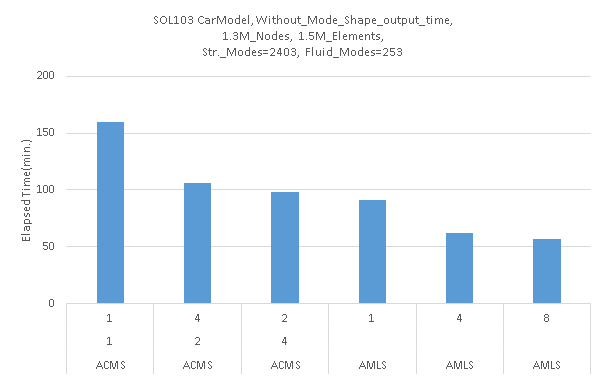
$$図3.MSC\ Nastranの例(MSC Software社提供データ使用)$$
並列数を上げるとその分の処理時間も短縮されているのがわかります。1台のベアメタルの中での処理なので当然といえば当然です。
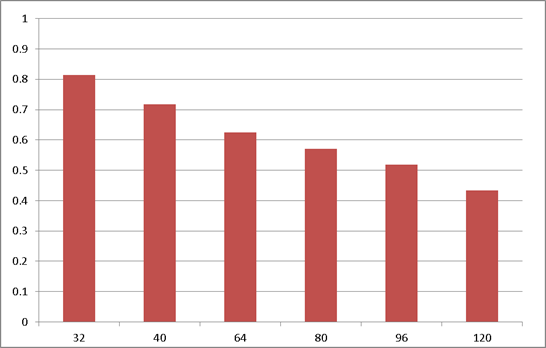
$$図4.LS-Dynaの例(TOP CRUNCHデータ使用)$$
TOP CRUNCHで公開されている3Carsの例です。並列効率は理論性能どおりではありませんが、並列数を上げるとリニアに処理時間が短縮されている傾向が読み取れます。240並列まで実施したかったのですが、予算の都合上、断念せざるを得ませんでした。
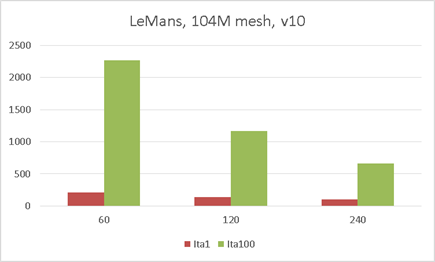
$$図4.STAR-MMC+の例(CDアダプコ社提供データ使用)$$
イタレーション1と100までの経過時間(秒)をグラフにしています。1億を超えるメッシュ数ですが理論性能どおりの結果となっていることがわかります。360並列までできなかったのは・・・はい、そうです。予算の制限でした。悔やまれます。。。
まとめ
SoftLayerのベアメタルは、物理サーバーではあるものの、Bondingの箇所で触れたとおり、クラウドならではのわずらわしさは、SoftLayer側でやってくれます。
さらに、ベアメタルは「物理サーバー」です。Dedicated Hostではないので「Hypervisor」はないのです。だからこそ、Hyper TreadingやTurbo BoostといったCPUそのものの機能も自由に制御できるんですね。
HPC環境をSoftLayerに構築したい!という場合は、以下のガイドもぜひご参照ください。
HPC on SoftLayer構築ガイド