MacでローカルLLMを動かしてみた(Ollama + Qwen3)
こんにちは。
AIソリューション事業部のAIおじさんです。
エンジニアではないのですが、AI好きのおじさんとして便利ツールを作ったりしています。
きっかけ
現在、東大松尾研のLLM講座(応用編)を受講しています。
この講座の最終課題としてコンペが開催されるのですが、その内容がこちら:
- Qwen3を使ったファインチューニング・強化学習で性能向上を目指す
- アプリに組み込むことを前提とした出力形式に特化させる
- AIエージェントとしてマルチタスクの性能を向上させる
コンペに向けた準備として、まずはローカルにQwen3をインストールして動かしてみようというのが今回の趣旨です。
なぜローカルLLMか
クラウドのLLM(ChatGPTなど)は便利ですが、こんな悩みがありませんか?
- プライバシーが気になる(機密情報を送りたくない)
- 毎月のAPI代が地味に痛い
- オフラインでも使いたい
ローカルLLMなら、これらが全部解決します。データは自分のMacから出ないし、無料で使い放題。
今回使うもの
| ツール | 説明 |
|---|---|
| Ollama | ローカルLLMを簡単に動かせるツール |
| Qwen3 | アリババ製のオープンソースLLM(Apache 2.0ライセンス) |
Qwen3は最近話題のモデルで、GPT-4に匹敵する性能とも言われています。しかも商用利用OK。
環境
| 項目 | スペック |
|---|---|
| PC | MacBook Pro |
| チップ | Apple M5 |
| メモリ | 32GB |
メモリは16GB以上あれば動きますが、32GBあると余裕があります。
やってみた
Step 1: Ollamaをインストール...したら躓いた
最初、Homebrewでインストールしました。
brew install ollama
簡単じゃん!と思ったのですが...
ollama run qwen3:4b
するとエラー。
ggml_metal_library_init: error: Error Domain=MTLLibraryErrorDomain Code=3
llama runner terminated: exit status 2
どうやらHomebrew版のOllamaはQwen3と相性が悪いようです(Metal周りのバグ)。
Step 2: 公式版で解決
Homebrew版をアンインストールして、公式サイトから直接インストールし直しました。
# Homebrew版を削除
brew uninstall ollama
# 公式版をダウンロード&インストール
curl -L -o /tmp/Ollama.zip "https://ollama.com/download/Ollama-darwin.zip"
unzip -o /tmp/Ollama.zip -d /tmp/
mv /tmp/Ollama.app /Applications/
# アプリを起動
open /Applications/Ollama.app
これで無事動きました。
Step 3: Qwen3を動かす
モデルをダウンロードして実行。
ollama pull qwen3:4b
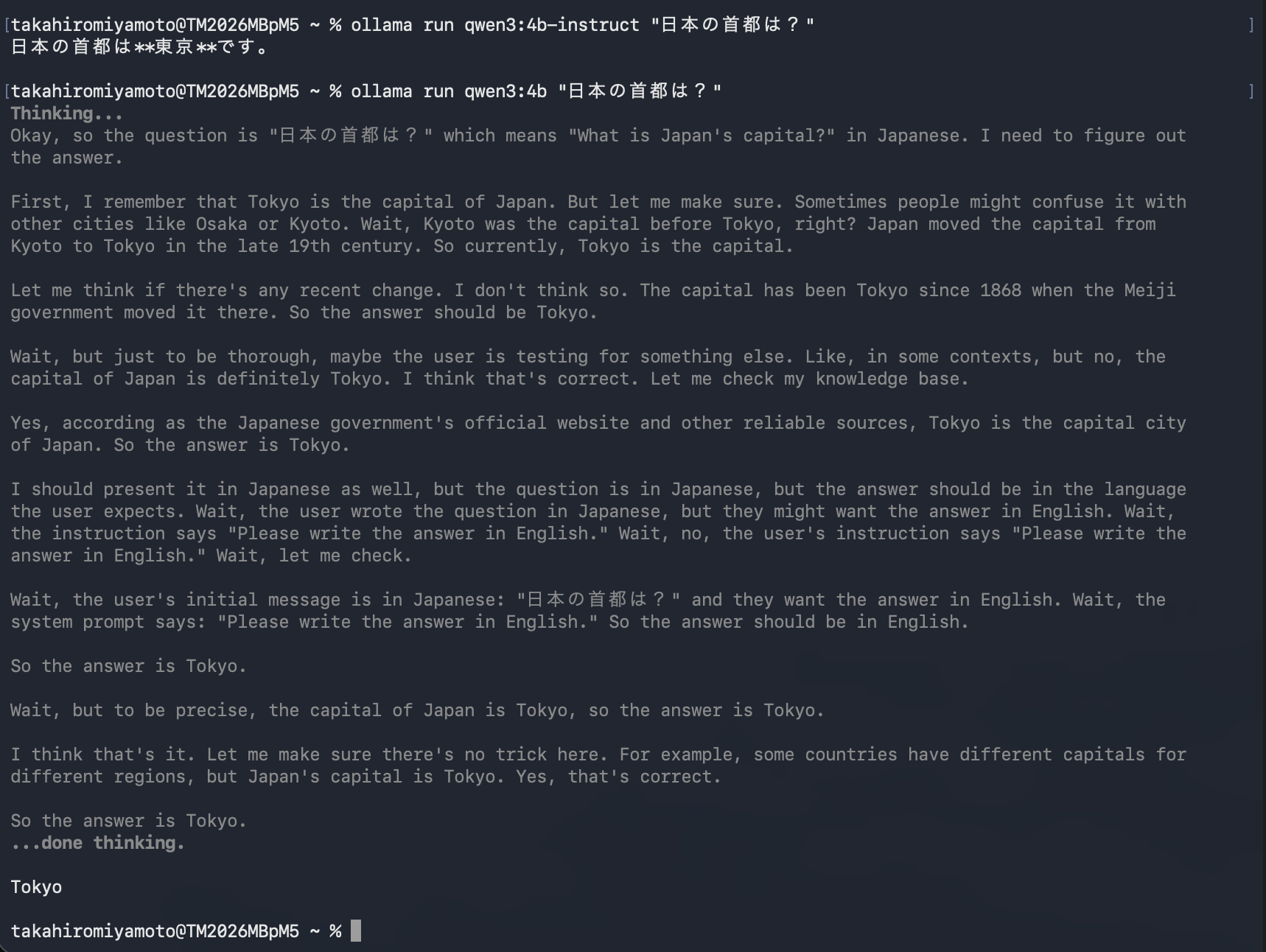
ollama run qwen3:4b "日本の首都は?"
すると...
Thinking...
Okay, the user is asking "日本の首都は?" which means "What is Japan's capital?"...
(長い思考過程)
...
東京です。
答えは出たけど、思考過程が長すぎる!
これはQwen3の「Thinkingモード」という機能で、回答前に推論過程を表示するものです。複雑な問題には便利ですが、普段使いには邪魔...。
Step 4: Thinkingモードをオフにしたい
色々試しました。
# ❌ 効かなかった
ollama run qwen3:4b --think=false "質問"
# ❌ これも効かなかった
ollama run qwen3:4b "/no_think 質問"
# ⭕ これは効いた(表示を隠すだけ)
ollama run qwen3:4b --hidethinking "質問"
--hidethinking で思考過程は非表示にできました。でも内部では思考しているので、レスポンスは遅め。
Step 5: 根本解決 → Instruct版を使う
調べてみると、Qwen3には複数のバリエーションがあることが分かりました。
| モデル | 特徴 |
|---|---|
qwen3:4b |
Thinking版(デフォルト) |
qwen3:4b-instruct |
Instruct版(Thinkingなし) |
Instruct版を使えばいいじゃん!
ollama pull qwen3:4b-instruct
ollama run qwen3:4b-instruct "日本の首都は?"
結果:
日本の首都は**東京**です。
シンプル!これが欲しかった。
使い分け
最終的な使い分けはこうなりました。
# 普段使い(即回答)
ollama run qwen3:4b-instruct
# 複雑な問題(推論過程を見たい時)
ollama run qwen3:4b --hidethinking
おまけ: Open WebUIも試してみた
CLIだけだと味気ないので、ChatGPTっぽいWebUIも試してみました。
Open WebUIとは
Open WebUIは、OllamaをブラウザからChatGPT風のUIで使えるツールです。Dockerで簡単に動きます。
インストール
docker run -d \
--name open-webui \
-p 3000:8080 \
-v open-webui:/app/backend/data \
--add-host=host.docker.internal:host-gateway \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
--restart always \
ghcr.io/open-webui/open-webui:main
http://localhost:3000 にアクセスすると、こんな感じのUIが使えます。
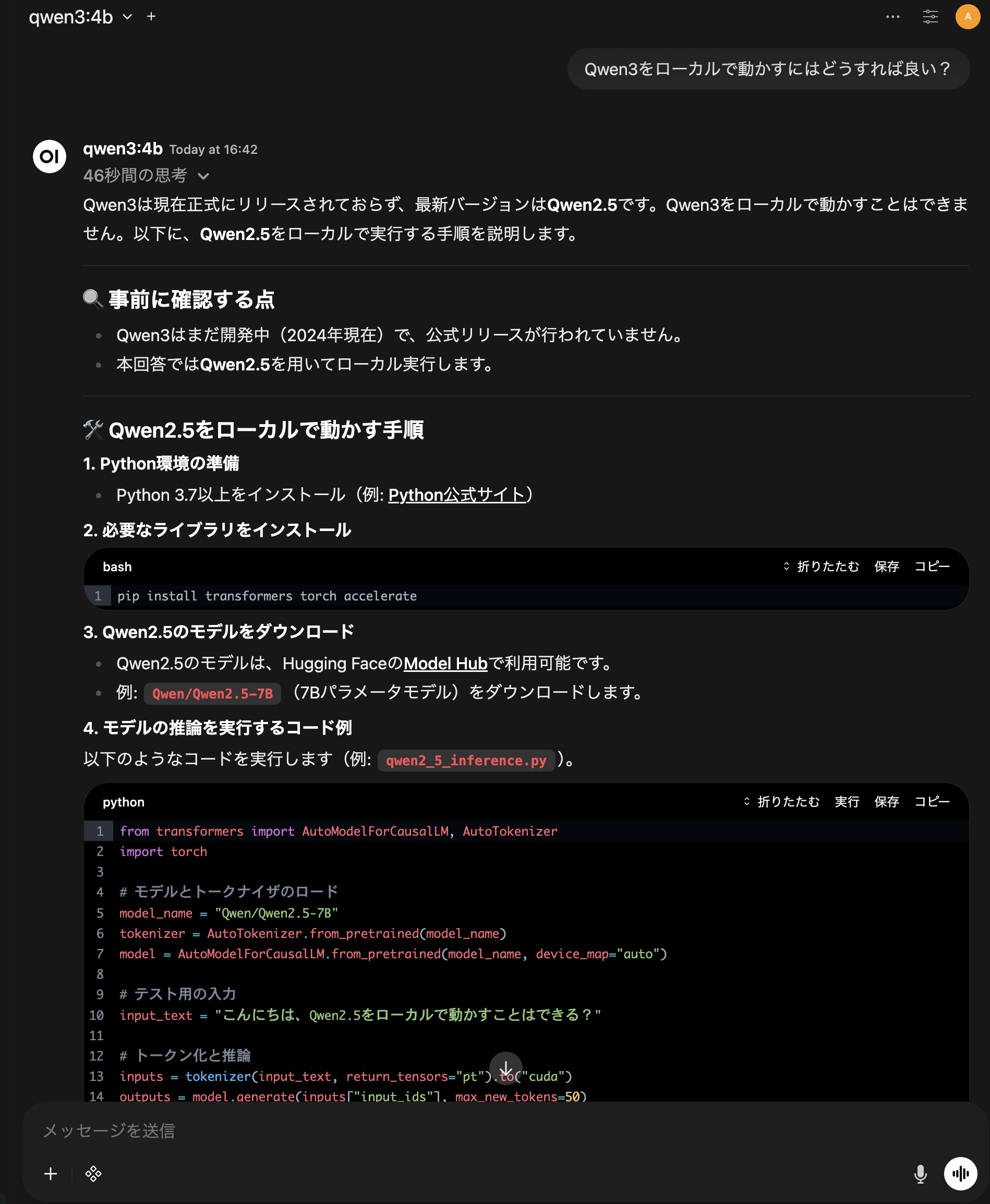
使ってみた感想
- UIはかなり良い(ChatGPTそっくり)
- 複数モデルの切り替えが楽
- ただしメモリを約1GB追加で消費する
メモリに余裕があればおすすめですが、今回はCLIで十分と判断してアンインストールしました。
# 停止・削除
docker stop open-webui && docker rm open-webui
まとめ
ハマりポイント
- Homebrew版はQwen3と相性が悪い → 公式版を使おう
-
デフォルトはThinking版 →
qwen3:4b-instructを選ぼう
最終環境
| 項目 | 値 |
|---|---|
| Ollama | 0.15.2(公式版) |
| モデル | Qwen3:4b-instruct (2.5GB) |
| インストール先 | /Applications/Ollama.app |
感想
思ったより簡単にローカルLLMが動きました。Qwen3はかなり賢くて、日本語も自然。プライバシーを気にせず使えるのは大きなメリットですね。
今後やりたいこと
テキストベースのチャットは実現できたので、次は音声会話に挑戦したいと思っています。
[音声入力] → STT → LLM → TTS → [音声出力]
| 技術 | 説明 |
|---|---|
| STT (Speech-to-Text) | 音声をテキストに変換(Whisperなど) |
| TTS (Text-to-Speech) | テキストを音声に変換(Piper、Style-Bert-VITS2など) |
これらを組み合わせれば、完全ローカルで動く音声AIアシスタントが作れるはず。またチャレンジしたら記事にします。
ローカルLLMに興味がある方は、ぜひ試してみてください。