- はじめに
- 私は幼い頃に二匹犬飼ったことがありました、CATとDOGはかなり仲良く私達の生活の中に存在感があります、今回の画像認識アプリ製作のテーマはCATとDOGの識別を選びました。
- 実行環境
- 画像収集
- 実行
- HTMLの作成
- 結果と考察
- WEB上で画像認識
- まとめ
- 1.実行環境
- 2.画像取集・画像認識 画像を用意ためにDowndload後 500枚ずつ画像をCATとDOGのフォルダを分けて、GoogleDrive上に保存されています。
- 3.モデルを実行
- 画像のサイズ調整 最初画像 # 50*50サイズに圧縮しましたが、特徴がアップするために # 200*200サイズで実行しました。 epoch=1正確率52%まで上がっていますが、もう少しあがりたいので再度コードを調整したり、 epoch=10 正確率56%ですがもう少し上がりたいので epoch=4 正確率78%まで上がりました、2分くらいで実行が完了しました。
- 4.HTMLの作成
- 5.結果と考察
- 6.WEB上で画像認識
- 実際のアプリ製作アプリケーション https://flask-render-seikabutu1.onrender.com
- 7.まとめ 今回のAIアプリ開発受講コードを通って、Pythonを使用しているライブラリの機能を単純から複雑まで基本的な知識を学びました、かなりメリットがあります、現在業務に応用できるまで、再度復習したいと思います。Pythonの柔軟性を徹底的に応用したいと思います。。
目次
・Visual Studio Code
・Google Colaboratory

・Driveから画像を読み込み出来るように下記のコード。

・ 画像認識、拡張子がすべてjpgであることを確認、ぼんやり画像を削除しました。

必要なライブラリ (numpy,matplotlib) などをimportして
versionはそれぞれ:
・numpy==1.23.5
・opencv-python==4.8.0.76
・matplotlib==3.7.1
・tensorflow==2.14.0
下記のコードを実行しました。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
path_cat500= "/content/drive/MyDrive/Aidemy/Seikabutu/Cat500"
path_dog500= "/content/drive/MyDrive/Aidemy/Seikabutu/Dog500"
# Catのイメージ画像の配列
img_cat = []
# Dogのイメージ画像の配列
img_dog = []
# Catのイメージ画像を読み込み
for i in range(len(path_cat500)):
# 画像を読み込み(i番目の)
img = cv2.imread('/content/drive/MyDrive/Aidemy/Seikabutu/Cat500/' + str(i) + '.jpg')
# 青、緑、赤のチャンネルを取得(それぞれの値)
b,g,r = cv2.split(img)
# OpenCVが使用するBGRの順序から、画像表示ライブラリやスクリーンが想定する標準的なRGBの順序に変換
img = cv2.merge([r,g,b])
# 200*200サイズに圧縮
img = cv2.resize(img, (200,200)) #(50,50)
# 配列に格納
img_cat.append(img)
# Dogのイメージ画像を読み込む(処理内容はCat側と同じ、フォルダが違うだけ)
for i in range(len(path_dog500)):
img = cv2.imread('/content/drive/MyDrive/Aidemy/Seikabutu/Dog500/' +str(i) + '.jpg')
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (200,200)) # (50,50)
img_dog.append(img)
# CatDogの配列を1つに結合
X = np.array(img_cat + img_dog)
# ラベル(回答)の設定、0:Cat、1:Dog
y = np.array([0]*len(img_cat) + [1]*len(img_dog))
#Xとy(データとラベル)をランダムに並び替える(データとラベルの紐づきは崩さずに)
rand_index= np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
#データの分割(8割をトレーニングデータとして使う)
X_train = X[:int(len(X)*0.8)] # トレーニングデータ
y_train = y[:int(len(y)*0.8)] # トレーニングデータのラベル
X_test = X[int(len(X)*0.8):] # テストデータ
y_test = y[int(len(y)*0.8):] # テストデータのラベル
# 出力をSoftmax関数にするため、必要な処理です
# クラス0(Cat) -> [1, 0]
# クラス1(Dog) -> [0, 1]
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデルにvggを使います
# 200x200ピクセルのカラー画像(RGBの3チャンネル)の入力テンソルを用意
input_tensor = Input(shape=(200, 200, 3)) #(50,50)
# 用意した入力テンソルをVGGに読み込ませる
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、2クラス分類する層を定義します
# その際中間層を下のようにいくつか入れると精度が上がります
# 新しいトップモデルを作成するためのSequentialモデル(層を直列に積み重ねるモデル)を開始
top_model = Sequential()
# VGG16の出力を1次元のベクトルに平坦化(入力が、200*200*3(画像X軸×画像Y軸×RGBの色)と3次元であるため、1次元に圧縮する)
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
# 256個のユニットを持つ全結合層(Dense層)を追加し、活性化関数としてReLUを使用 (ここのユニット数と活性化関数はハイパーパラメータ)
top_model.add(Dense(256, activation='relu'))
# 過学習を防ぐため、50%の確率でランダムにユニットの出力を0にする
top_model.add(Dropout(0.5))
# 最後の層であるDense層を追加し、2クラス分類のためのsoftmax活性化関数を適用
top_model.add(Dense(2, activation='softmax'))
# vggと、top_modelを連結します (VGG16の入力層と新しく定義したトップモデルを結合
model = Model(vgg16.inputs, top_model(vgg16.output))
# vggの層の重みを変更不能にします(VGGは19層)
for layer in model.layers[:19]:
layer.trainable = False
# コンパイルします
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy']) # どの性能を指標とするか accuracy:正確度
# 学習を行います batch_size:一度に処理するデータの数、epochs:訓練データをすべて使って学習する回数
model.fit(X_train, y_train, batch_size=100, epochs=5, validation_data=(X_test, y_test))
#############################################
def pred_PetImages(img):
# 引数から受け取った画像を200*200にリサイズ
img = cv2.resize(img, (200, 200))
# モデルが予想した結果のうち、大きいほうを取得 [0.6, 0.4]
pred = np.argmax(model.predict(np.array([img])))
if pred == 0:
return 'cat'
else:
return 'dog'
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# pred_PetImages関数にPetImagesを渡してPetを予測します
for i in range(5):
# pred_PetImages関数に写真を渡してPetを予測します
img = cv2.imread('/content/drive/MyDrive/Aidemy/Seikabutu/Dog500/' + str(i) + '.jpg')
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
plt.imshow(img)
plt.show()
print(pred_PetImages(img))

<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>PetImage Recognition</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<img class="header_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<a class="header-logo" href="#">PetImage Recognition</a>
</header>
<div class="main">
<h2> AIが送信されたペットの画像を識別します</h2>
<p>画像を送信してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
<img class="footer_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<small>© 2019 Aidemy, inc.</small>
</footer>
</body>
</html>
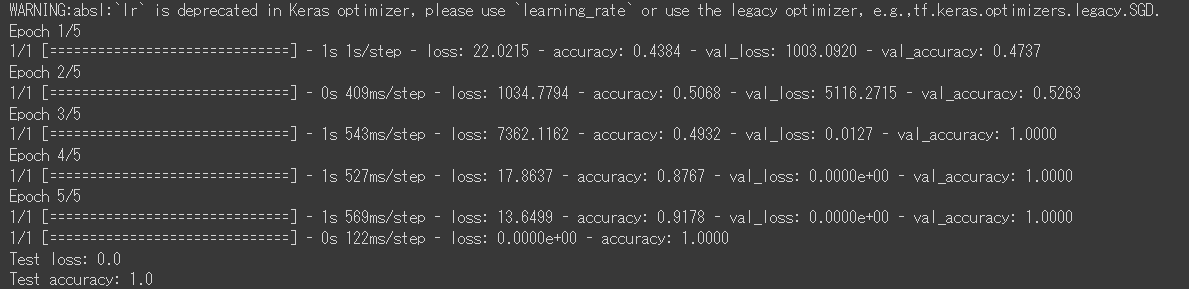
epcho 調整と共に正確率上がったり、下がったり、面白かったです。原因は上げすぎ時に過学習が発生したと思います。
これらはepoch=5 の結果です、びっくりほど結果ですよね、正確率100%です
。
VSCODE上でWebAPP製作、imgの関数 grayscale = True,上手く画像を認識できなかった、再度関数 grayscale = Falseに変わって、画像を認識、識別できました。
1枚写真をドラッグドロップしてみたら、「これはdogです」を識別されました。
