1. はじめに
前回の記事では、AWS GlueとAthenaを使ってS3のデータを日付で検索する方法を解説しました。
今回は、作成したテーブルをベースに、AthenaからIceBergのテーブルを作成してみます。
サンプルデータも前回の記事で紹介してますので参考にしてください。
2. IceBergテーブルの作成
今回検証するためのIceBergのテーブルを作成していきます。
IceBergはパーティションによって、チューニングできるため、それの検証用に3パターン作成しました。
2.1 更新日時でパーティションを作成
CREATE TABLE datalake.sales_iceberg_date (
id bigint,
timestamp string,
product_name string,
price bigint,
quantity bigint,
update_date string)
PARTITIONED BY (`update_date`)
LOCATION 's3://handson-kmg-0207/sales_iceberg_date'
TBLPROPERTIES (
'table_type'='iceberg',
'format'='PARQUET',
'write_compression'='ZSTD'
);
2.2 製品名でパーティションを作成
CREATE TABLE datalake.sales_iceberg_product (
id bigint,
timestamp string,
product_name string,
price bigint,
quantity bigint,
update_date string)
PARTITIONED BY (`product_name`)
LOCATION 's3://handson-kmg-0207/sales_iceberg_product'
TBLPROPERTIES (
'table_type'='iceberg',
'format'='PARQUET',
'write_compression'='ZSTD'
);
2.3 製品名でと更新日時でパーティションを作成
CREATE TABLE datalake.sales_iceberg_product_date (
id bigint,
timestamp string,
product_name string,
price bigint,
quantity bigint,
update_date string)
PARTITIONED BY ('product_name', 'update_date')
LOCATION 's3://handson-kmg-0207/sales_iceberg_product_date'
TBLPROPERTIES (
'table_type'='iceberg',
'format'='PARQUET',
'write_compression'='ZSTD'
);
2.4 データを登録
INSERT INTO datalake.sales_iceberg_date
SELECT
id,
timestamp,
product_name,
price,
quantity,
update_date
FROM sales;
INSERT INTO datalake.sales_iceberg_product
SELECT
id,
timestamp,
product_name,
price,
quantity,
update_date
FROM sales;
INSERT INTO datalake.sales_iceberg_product_date
SELECT
id,
timestamp,
product_name,
price,
quantity,
update_date
FROM sales;
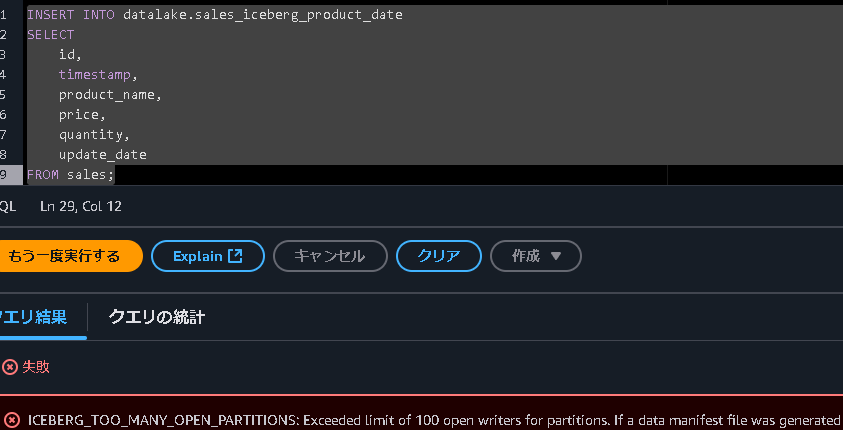
2.5 ここで問題発生!!
次のエラーが出てきました。
AthenaからIceBergテーブルにインサートする際、パーティション数が100を超えると次のようなエラーが発生します。
ICEBERG_TOO_MANY_OPEN_PARTITIONS: Exceeded limit of 100 open writers for partitions.
GlueからIceBergテーブルにインサートすればいいそうなのですが、中々上手くいかないので後日追記します。。。
3. S3テーブルとIceBergとでパフォーマンス検証
3.1 全データに対する単純な distinct 検索
実験1: 商品名の一覧取得
select distinct product_name from sales;
select distinct product_name from sales_iceberg_date;
select distinct product_name from sales_iceberg_product;
S3テーブル
- キュー内の時間: 99 ms
- 実行時間: 58.907 sec
- スキャンしたデータ: 92.28 KB
sales_iceberg_date
- キュー内の時間: 112 ms
- 実行時間: 1.022 sec
- スキャンしたデータ: 12.34 KB
sales_iceberg_product
- キュー内の時間: 139 ms
- 実行時間: 1.165 sec
- スキャンしたデータ: -
3.2 パーティション絞り込みあり
実験2: 期間指定での商品名一覧取得
select distinct product_name from sales where update_date < '2024/02/01/00';
select distinct product_name from sales_iceberg_date where update_date < '2024/02/01/00';
select distinct product_name from sales_iceberg_product where update_date < '2024/02/01/00';
S3テーブル
- キュー内の時間: 102 ms
- 実行時間: 1.448 sec
- スキャンしたデータ: 92.28 KB
sales_iceberg_date
- キュー内の時間: 79 ms
- 実行時間: 1.155 sec
- スキャンしたデータ: 12.34 KB
sales_iceberg_product
- キュー内の時間: 63 ms
- 実行時間: 2.029 sec
- スキャンしたデータ: 9.25 KB
3.3 パーティション絞り込みと条件検索
実験3: 特定商品の期間指定データ取得
select product_name,timestamp,price from sales where product_name = 'ProductD' and update_date < '2024/02/01/00';
select product_name,timestamp,price from sales_iceberg_date where product_name = 'ProductD' and update_date < '2024/02/01/00';
select product_name,timestamp,price from sales_iceberg_product where product_name = 'ProductD' and update_date < '2024/02/01/00';
S3テーブル
- キュー内の時間: 116 ms
- 実行時間: 2.025 sec
- スキャンしたデータ: 92.28 KB
sales_iceberg_date
- キュー内の時間: 70 ms
- 実行時間: 1.239 sec
- スキャンしたデータ: 54.30 KB
sales_iceberg_product
- キュー内の時間: 107 ms
- 実行時間: 2.388 sec
- スキャンしたデータ: 5.90 KB
3.4 条件検索のみ(パーティション絞り込みなし)
実験4: 特定商品の全期間データ取得
select product_name,timestamp,price from sales where product_name = 'ProductD';
select product_name,timestamp,price from sales_iceberg_date where product_name = 'ProductD';
select product_name,timestamp,price from sales_iceberg_product where product_name = 'ProductD';
S3テーブル
- キュー内の時間: 70 ms
- 実行時間: 56.571 sec
- スキャンしたデータ: 92.28 KB
sales_iceberg_date
- キュー内の時間: 68 ms
- 実行時間: 3.082 sec
- スキャンしたデータ: 54.30 KB
sales_iceberg_product
- キュー内の時間: 127 ms
- 実行時間: 2.948 sec
- スキャンしたデータ: 4.27 KB
4. 検証結果の考察
4.1 全体的な傾向
-
実行時間の改善
- IceBergテーブルは、ほとんどのケースでS3テーブルより高速に動作
- 特に全データスキャンが必要な場合(実験1)で顕著な改善(58秒 → 1秒程度)
- これはIceBergの効率的なデータ構造とメタデータ管理によるもの
-
スキャンデータ量の削減
- IceBergテーブルは常にスキャンデータ量が少ない
- S3テーブル(92.28 KB)に対し、IceBergは4-54 KB程度まで削減
- データ量の削減がパフォーマンス向上に直結
4.2 パーティション戦略の影響
日付パーティション(sales_iceberg_date)の特徴
- 時系列データの検索に強い
- 日付範囲での絞り込み(実験2)で良好なパフォーマンス
- 汎用的な使用に適している
製品名パーティション(sales_iceberg_product)の特徴
- 製品別の検索(実験4)で優れたパフォーマンス
- スキャンデータ量が最も少ない(4.27 KB)
- 特定製品の分析に適している