1. はじめに
このガイドでは、AWS GlueとAthenaを使ってS3のデータを日付で検索する方法を解説します。
サンプルデータも添えてますので、お手元の環境でお試しください。
構成は次のようにS3のCSVファイルをGlueDataCatalogとAthenaで検索する形になります。
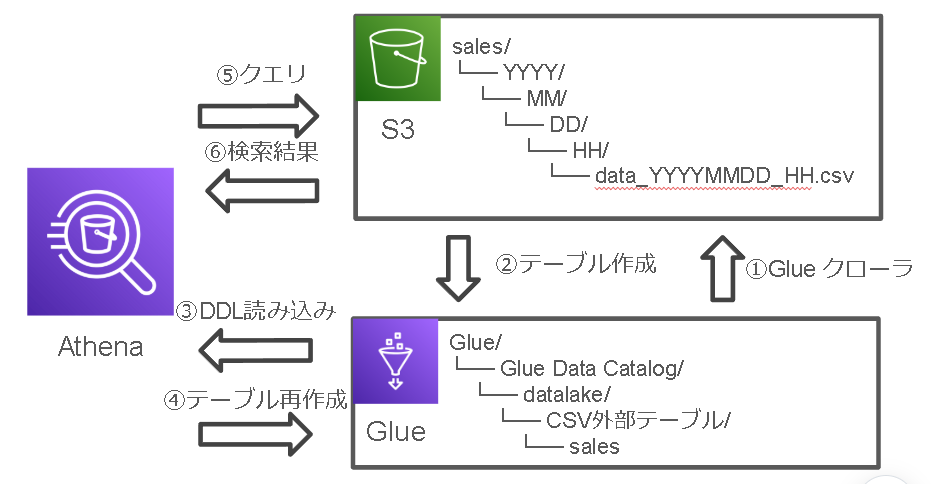
2. 環境準備
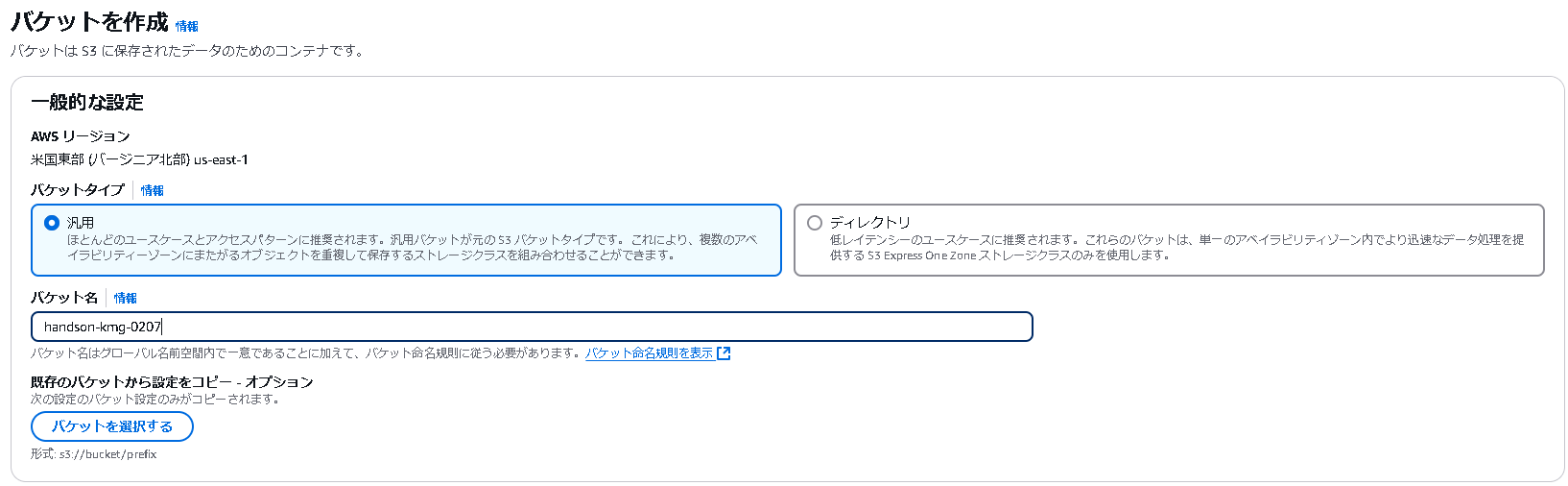
2.1 S3バケットの作成
まず、テストデータを格納するためのS3バケットを作成します。
- バケット名:
handson-kmg-0207 - リージョン:
ap-northeast-1(東京)
2.2 テストデータの生成
テストデータを生成するPythonスクリプトを作成します。データは以下の構造で生成されます:
sales/
└── YYYY/
└── MM/
└── DD/
└── HH/
└── data_YYYYMMDD_HH.csv
テストデータ生成スクリプト(upload-data.py)
import pandas as pd
import random
from datetime import datetime, timedelta
import os
def generate_test_data():
# Windows用のパス設定
base_dir = r"C:\Users\tamago\Documents\Python Scripts\glue_athena"
data_type = "sales"
base_path = os.path.join(base_dir, "data", data_type)
# テストデータの期間設定
start_date = datetime(2024, 1, 1)
end_date = datetime(2024, 2, 7)
current_date = start_date
# 商品リスト(サンプル)
products = ["ProductA", "ProductB", "ProductC", "ProductD", "ProductE"]
# S3バケット名
bucket_name = "handson-kmg-0207"
# アップロードコマンドを保存するリスト
upload_commands = []
while current_date <= end_date:
# 1時間ごとのデータを生成
for hour in range(24):
# Windowsパス形式でディレクトリを作成
path = current_date.strftime(f'%Y/%m/%d/{hour:02d}')
full_path = os.path.join(base_path, current_date.strftime(f'%Y'),
current_date.strftime('%m'),
current_date.strftime('%d'),
f"{hour:02d}")
# ディレクトリ作成
os.makedirs(full_path, exist_ok=True)
# その時間のデータ件数(ランダム:10-30件)
n_records = random.randint(10, 30)
# データ生成
data = {
'id': range(n_records),
'timestamp': [current_date.replace(hour=hour) + timedelta(minutes=random.randint(0, 59))
for _ in range(n_records)],
'product_name': [random.choice(products) for _ in range(n_records)],
'price': [random.randint(100, 5000) for _ in range(n_records)],
'quantity': [random.randint(1, 10) for _ in range(n_records)]
}
df = pd.DataFrame(data)
# ファイル名
filename = f"data_{current_date.strftime('%Y%m%d')}_{hour:02d}.csv"
file_path = os.path.join(full_path, filename)
# CSVとして保存
df.to_csv(file_path, index=False)
# S3アップロードコマンド生成部分を修正
s3_path = f"s3://{bucket_name}/{data_type}/{path}/{filename}"
local_path = file_path.replace('\\', '/')
# ダブルクォートでパスを囲む
upload_commands.append(f'aws s3 cp "{local_path}" "{s3_path}"')
current_date += timedelta(days=1)
# アップロードコマンドをファイルに保存
upload_script_path = os.path.join(base_dir, 'upload_commands.ps1')
with open(upload_script_path, 'w') as f:
for cmd in upload_commands:
f.write(f"{cmd}\n")
print("データ生成完了!")
print(f"生成されたデータ: {base_path}")
print(f"アップロードスクリプト: {upload_script_path}")
print("PowerShellでupload_commands.ps1を実行してS3にアップロードできます")
if __name__ == "__main__":
generate_test_data()
データの内容
生成されるCSVファイルには以下のカラムが含まれます:
| カラム名 | 説明 | データ例 |
|---|---|---|
| id | レコードID | 1, 2, 3, ... |
| timestamp | タイムスタンプ | 2024-01-01 10:15:00 |
| product_name | 商品名 | ProductA, ProductB, ProductC, ... |
| price | 価格 | 100〜5000のランダム値 |
| quantity | 数量 | 1〜10のランダム値 |
サンプルデータ
id,timestamp,product_name,price,quantity
1,2024-01-01 10:15:00,ProductA,1200,3
2,2024-01-01 10:25:30,ProductC,4500,2
3,2024-01-01 10:45:15,ProductB,800,5
2.3 データのアップロード手順
Pythonスクリプトの実行
python upload-data.py
データアップロード
.\upload_commands.ps1
こんな感じで格納された成功です
3. テーブル設計とデータ取得の進め方
これからの作業は以下の流れで進めていきます:
- AWS Glueでクローラーを作成し、S3のデータからテーブルを自動生成します
- 生成されたテーブルのDDLをAthenaで確認します
- 日付での検索が効率的に行えるよう、DDLを修正して新しいテーブルを作成します
ここで、一見、最初からAthenaでテーブルを作成すれば良いように思えますが、その場合、全ての列名と型を手動で定義する必要があり、かなりの手間がかかってしまいます。
そこで、まずはGlueクローラーを使ってスキーマを自動検出させ、その結果をベースにテーブルを作り直すアプローチを取ります。
クローラーが生成したテーブルは、日付での検索に最適化されていない可能性が高いものの、列名や型の定義は自動で行ってくれるため、それをベースにDDLを修正することで、効率的にテーブルを作成できます。
3.1 Glueクローラーの作成と実行
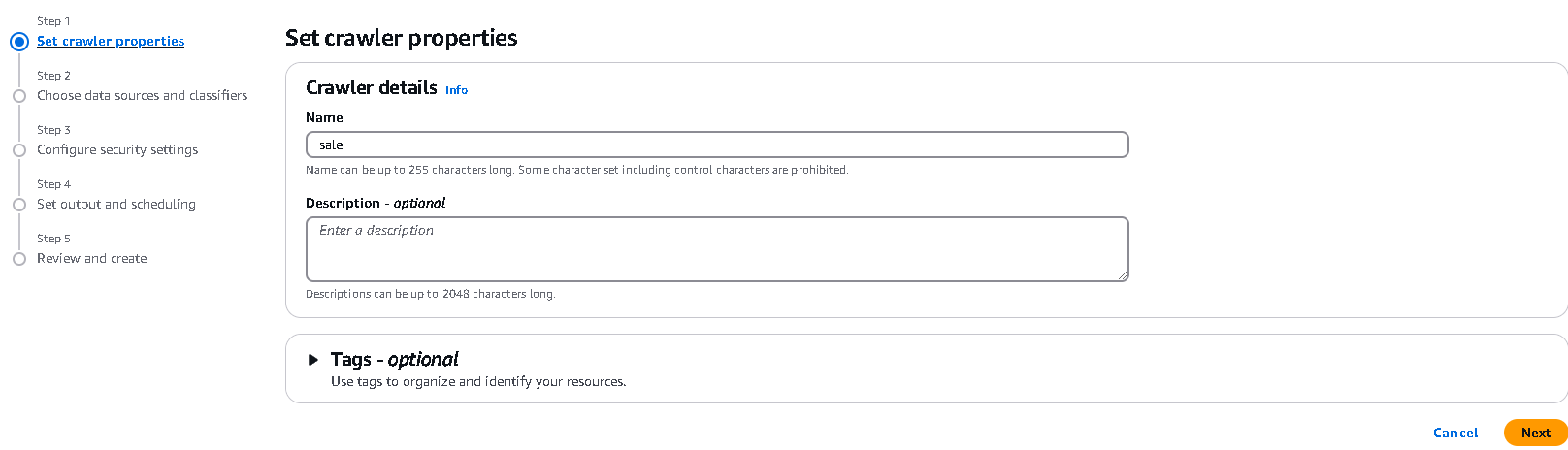
クローラーの作成
saleという名前でクローラーを作成します。
データソースの追加
Add a data sourceを選択します。
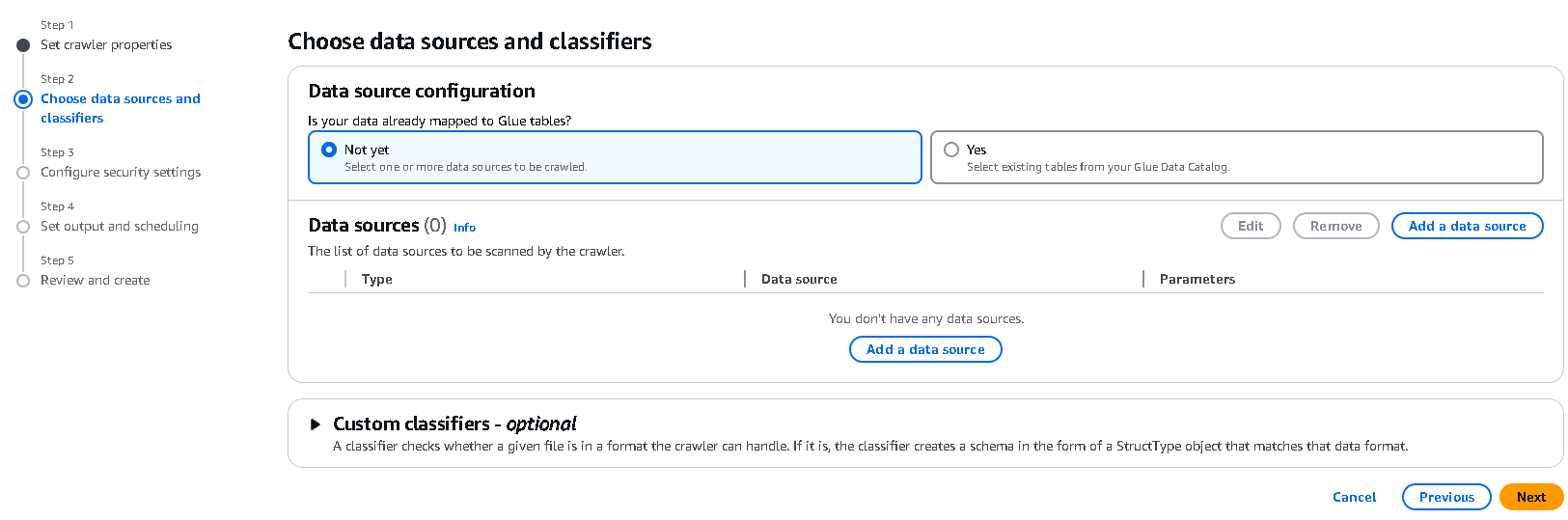
S3パスの設定
先ほど作成したsaleのS3パスを選択します。
注意
もし、特定のVPC上で実行していた場合は、Network connectionを設定する必要があります。既にGlue JobでRDSなど接続を追加していたらここで追加してください。
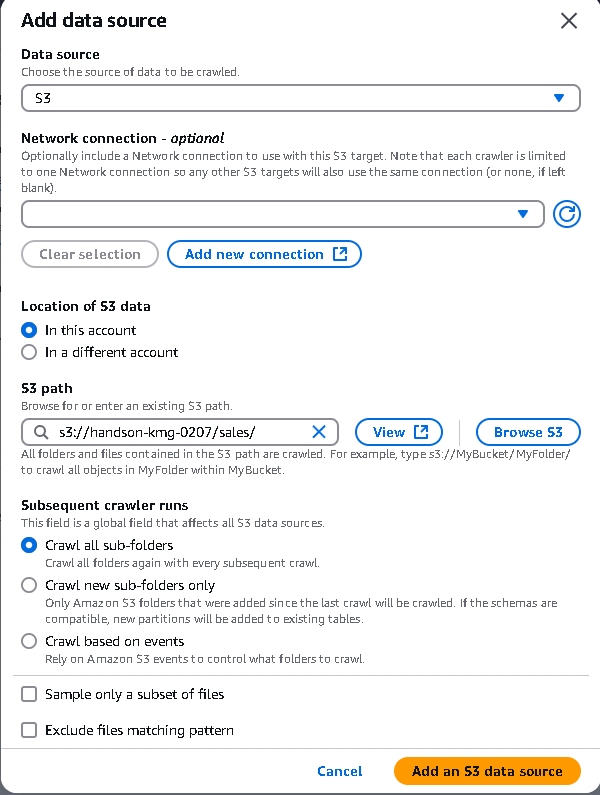
IAMロールの作成
必要な権限を持つIAMロールを作成します。
データベースの作成
datalakeという名前でデータベースを作成します。
クローラーの実行
作成したクローラーのRun crawlerを実行します。
数分で実行が完了します。
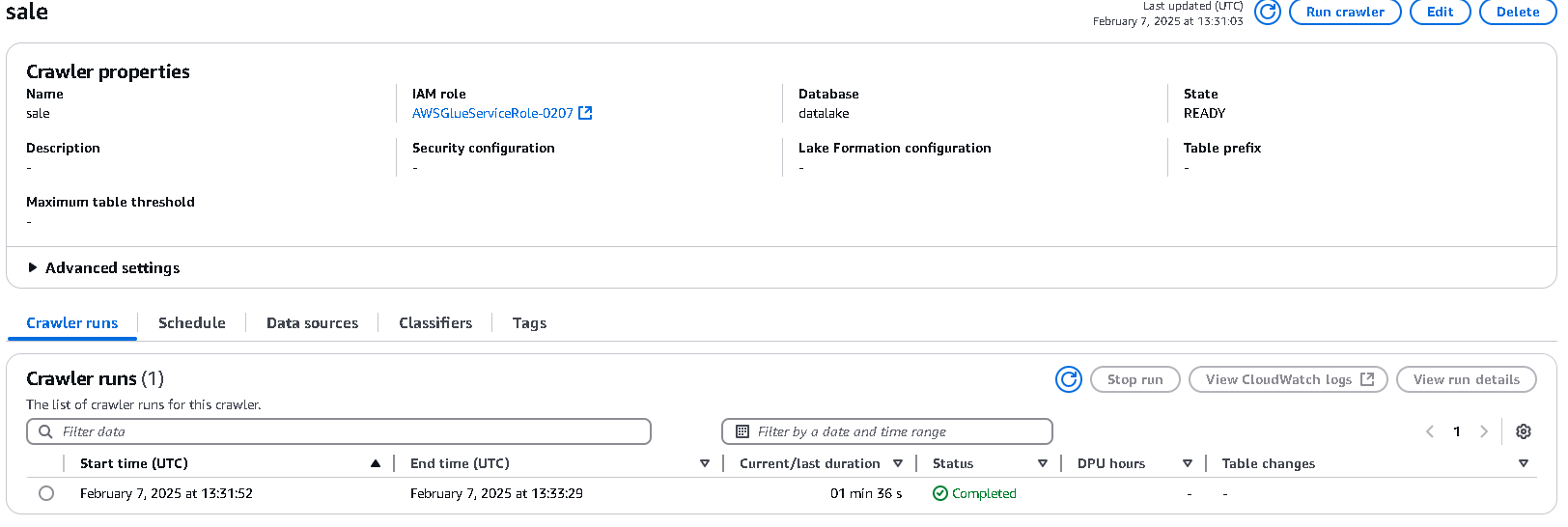
4. Athenaでのテーブル確認と修正
まずは、Glueクローラーによって自動生成されたテーブルの内容を確認していきます。
AthenaのQuery editorを開き、以下の手順で確認作業を進めます。
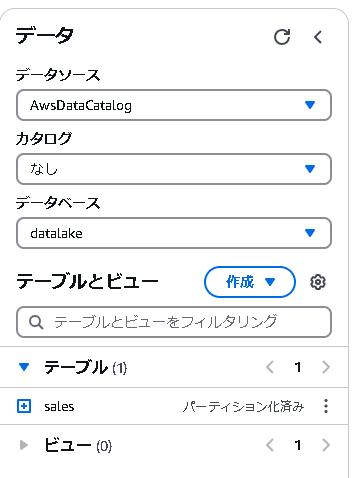
4.1 データベースの確認
先ほど作成したdatalakeを選択すると、salesというテーブルが作成されていることが確認できます。
4.2 動作確認
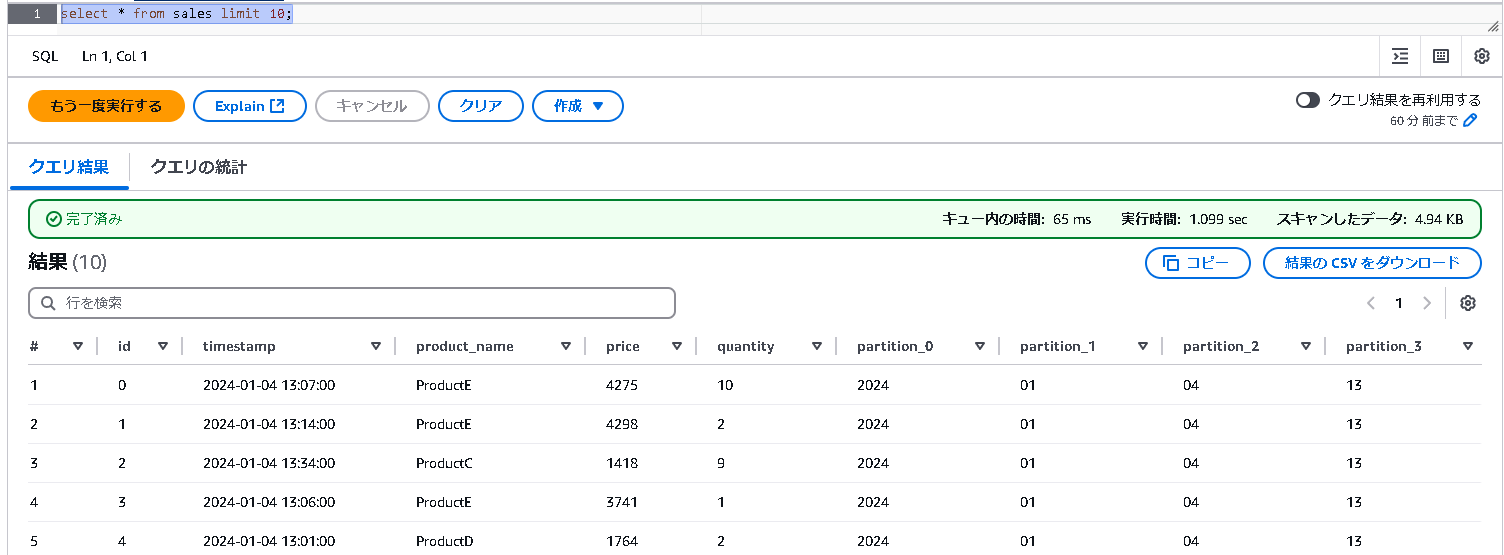
まずは簡単なSELECT文で動作確認をしてみましょう。
SELECT * FROM sales LIMIT 10;
以下のように結果が表示されれば成功です。
4.3 テーブル定義の確認
クローラーによって自動生成されたDDL(Data Definition Language)を確認します。
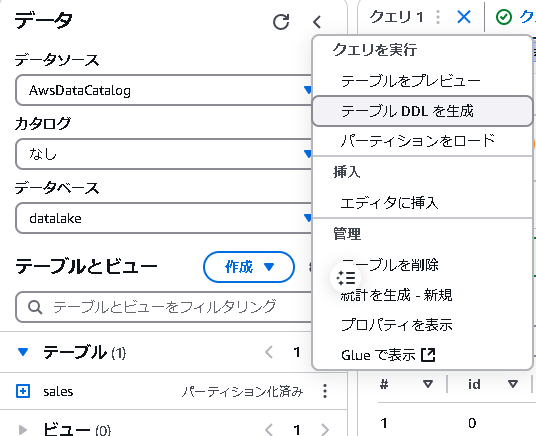
生成されたDDLは以下の通りです:
CREATE EXTERNAL TABLE `sales`(
`id` bigint,
`timestamp` string,
`product_name` string,
`price` bigint,
`quantity` bigint)
PARTITIONED BY (
`partition_0` string,
`partition_1` string,
`partition_2` string,
`partition_3` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://handson-kmg-0207/sales/'
TBLPROPERTIES (
'CrawlerSchemaDeserializerVersion'='1.0',
'CrawlerSchemaSerializerVersion'='1.0',
'UPDATED_BY_CRAWLER'='sale',
'areColumnsQuoted'='false',
'averageRecordSize'='37',
'classification'='csv',
'columnsOrdered'='true',
'compressionType'='none',
'delimiter'=',',
'objectCount'='111',
'partition_filtering.enabled'='true',
'recordCount'='2461',
'sizeKey'='94491',
'skip.header.line.count'='1',
'typeOfData'='file')
4.4 修正が必要な点
DDLを確認すると、以下の部分に問題があることがわかります:
PARTITIONED BY (
`partition_0` string,
`partition_1` string,
`partition_2` string,
`partition_3` string)
クローラーは、ディレクトリ構造(YYYY/mm/dd/HH)を単なる文字列のパーティションとして認識してしまっています。
日付での検索を効率的に行うためには、この部分を適切なパーティション構造に修正する必要があります。
ただし、3章で説明した通り、クローラーは基本的なスキーマ定義を自動で行ってくれている点が便利です:
CREATE EXTERNAL TABLE `sales`(
`id` bigint,
`timestamp` string,
`product_name` string,
`price` bigint,
`quantity` bigint)
特に複数のテーブルを作成する場合、このようなスキーマの自動検出機能は非常に有用です(意見が分かれるところではありますが😅)。
4.5 DDLの修正
この方のQiitaの記事を参考にしました:
https://qiita.com/a_b_/items/2d2822988f161de37d04
修正点はPARTITIONED BYとTBLPROPERTIESを修正するところだけです。
このやり方にすることで、update_date列に対して日付っぽくBETWEENで検索できるようになります。
Hiveにすると列が分かれたり結構苦労したのと、パフォーマンスが出ななかったのでこのやり方に落ち着いています。
今回だとrangeは大きく設定しておけば大丈夫です。
まだ実行は待ってくださいね!
DROP TABLE sales;
CREATE EXTERNAL TABLE `sales`(
`id` bigint,
`timestamp` string,
`product_name` string,
`price` bigint,
`quantity` bigint)
PARTITIONED BY (
`update_date` string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://handson-kmg-0207/sales/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.update_date.type' = 'date',
'projection.update_date.range' = '2024/01/01/00,2030/01/01/00',
'projection.update_date.format' = 'yyyy/MM/dd/HH',
'projection.update_date.interval' = '1',
'projection.update_date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://handson-kmg-0207/sales/${update_date}/'
)
4.6 クローラで作成したテーブルの再作成
先にさっきのテーブルを削除します:
DROP TABLE sales;
次にさっき修正したDDLを実行してください。
新しくupdate_date列が入ったテーブルができていると思います。
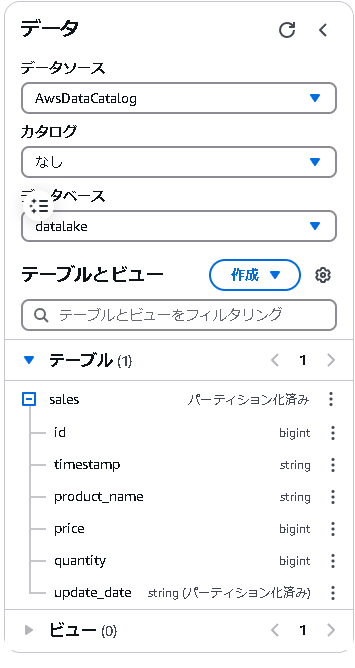
4.7 パーティション列を使ったクエリ例
新しく作成したテーブルで、update_date列を使った検索が可能になりました。
いくつかの実用的なクエリ例を見ていきましょう。
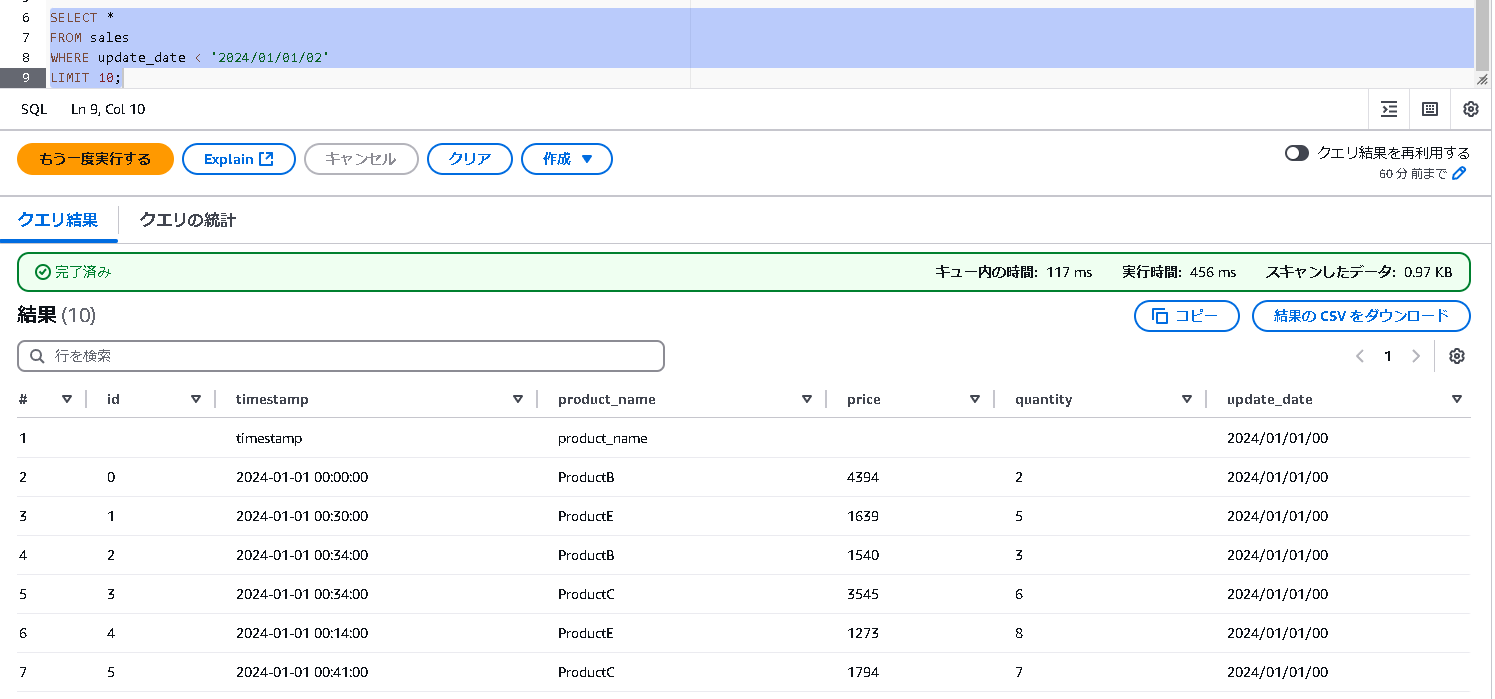
時間での範囲指定
-- 特定の時刻より前のデータを取得
SELECT *
FROM sales
WHERE update_date < '2024/01/01/02'
LIMIT 10;
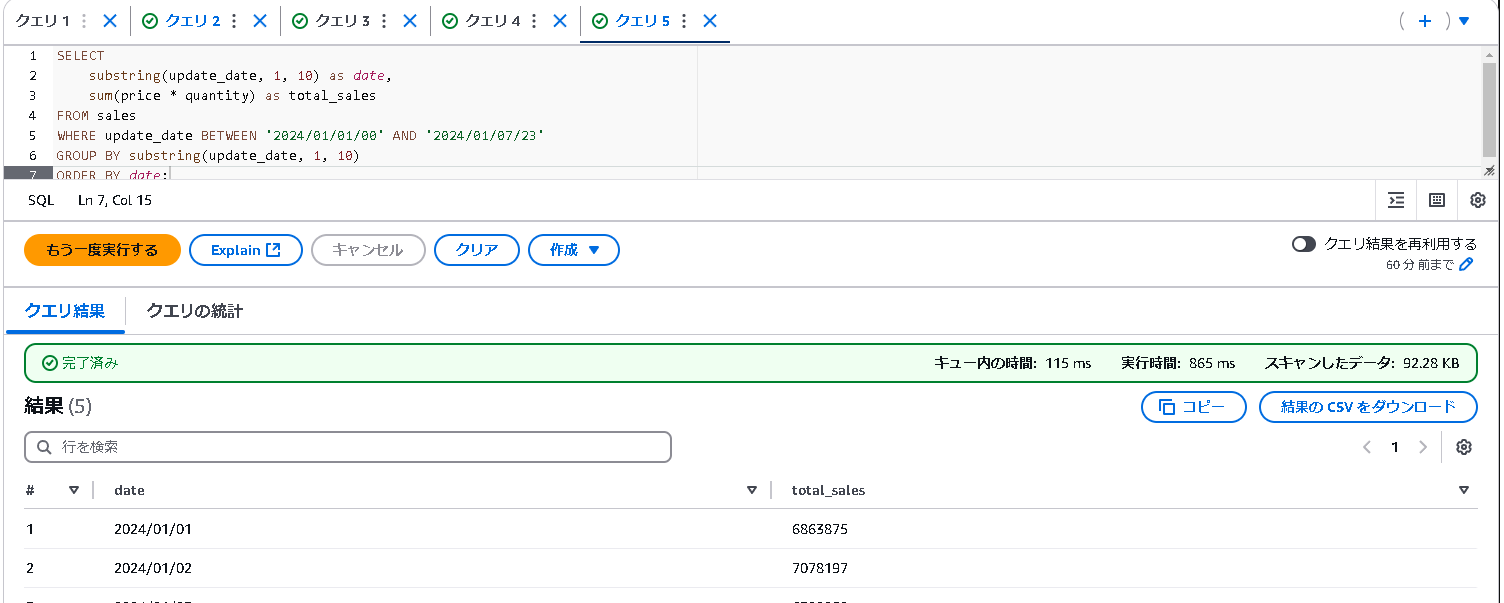
日付範囲での検索
-- 2024年1月1日から1月7日までの間の売上集計
SELECT
substring(update_date, 1, 10) as date,
sum(price * quantity) as total_sales
FROM sales
WHERE update_date BETWEEN '2024/01/01/00' AND '2024/01/07/23'
GROUP BY substring(update_date, 1, 10)
ORDER BY date;
Note
パーティション列が時間単位の場合、intervalとinterval.unitの設定が必要です。
これにより、Athenaが時間単位での範囲検索を正しく処理できるようになります。
5. まとめ
本記事では、AWS GlueとAthenaを使ってS3のデータを日付で効率的に検索する方法を紹介しました。
ポイントは以下の通りです:
-
Glueクローラーの活用
- スキーマの自動検出により、カラム定義の手間を省略
- 複数テーブルの一括定義に特に有効
-
パーティション設計の工夫
- クローラーが生成したパーティション定義をカスタマイズ
- 時間単位の検索に対応するための適切なTBLPROPERTIESの設定
-
効率的な検索の実現
- 日付/時間での範囲検索が可能
- パーティションを活用した高速な検索の実現
本手順を応用することで、大量のログデータや時系列データを効率的に分析することができます。