はじめに
この記事は、@minorun365さんの「GraphRAGをAWS上で動かしてみる」を参考に、実際にポケモンWikiの内容でGraphRAGを試してみた実験記録です。
注意
筆者はポケモンについて詳しくないです。
本記事は技術検証目的であり、商用利用を意図するものではありません。
- 本記事は技術検証目的の実験記録です
- ポケモンWikiのコンテンツは [出典元URL] より引用
- ポケモンは株式会社ポケモンの登録商標です
できること
- NeptuneのグラフDBにデータ登録
- プログラムから自然言語でグラフDBを検索
環境準備
みのるんさんの記事を参考に、「Neptune Databaseを作成」の章まで実施してください。
クラスター作成まで完了したらIAMロールを修正します。
SageMakerのIAMロールを修正
ノートブックの名前を選択

アクション->SageMakaerで詳細を表示する
アクセス許可と暗号化->IAMロールARNを選択

許可ポリシーにAmazonBedrockFullAccessを追加

実装
1. データの準備
元データを準備
今回はポケモンwikiからピカチュウのページをPDFで保存します。
ページの左側の「印刷用バージョン」からPDF化できます。
ピカチュウのページ
ノートブックにアップロード
ノートブックを起動したら、直下にDataフォルダを作成

先ほど保存したPDFどドラックアンドドロップ!

2. サンプルプログラムの実行
みのるんさんの記事をベースに少しいじっています。
ノーブックを作成
必要なパッケージのインストール
%pip install -U boto3 llama-index-llms-bedrock llama-index-graph-stores-neptune llama-index-embeddings-bedrock llama-index-readers-file
インポート
from llama_index.llms.bedrock import Bedrock
from llama_index.embeddings.bedrock import BedrockEmbedding
from llama_index.core import StorageContext, SimpleDirectoryReader, KnowledgeGraphIndex, Settings
from llama_index.graph_stores.neptune import NeptuneDatabaseGraphStore
from IPython.display import Markdown, display
回答生成用LLMと、埋め込み用モデルを設定
llm = Bedrock(
model="anthropic.claude-3-sonnet-20240229-v1:0",
region="us-east-1" # Neptuneと同じリージョンを指定
)
embed_model = BedrockEmbedding(model="amazon.titan-embed-text-v2:0")
Settings.llm = llm
Settings.embed_model = embed_model
Settings.chunk_size = 512
ドキュメントとグラフDBを設定
documents = SimpleDirectoryReader("./Data").load_data()
graph_store = NeptuneDatabaseGraphStore(
host="<書き込みエンドポイント名>",
port=8182
)
重要! グラフDBへ登録
次のようにシンプルな実装も可能な様なのですが、リクエスト制限に引っかかってしまったので、複雑な実装を行います。

Retrying llama_index.llms.bedrock.utils.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised ThrottlingException: An error occurred (ThrottlingException) when calling the InvokeModel operation: Too many requests, please wait before trying again. You have sent too many requests. Wait before trying again..
(sonnet v2が。。。)試行錯誤したグラフDBへの登録処理
import time
import logging
from typing import List
from llama_index.core.schema import Document
from llama_index.core import KnowledgeGraphIndex
from llama_index.core import StorageContext
# storage_contextの初期化
storage_context = StorageContext.from_defaults(graph_store=graph_store)
# ログ設定
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def process_documents_in_batches(
documents: List[Document],
storage_context,
batch_size: int = 2, # より小さいバッチサイズ
sleep_time: int = 10, # より長い待機時間
max_retries: int = 5 # リトライ回数を増加
) -> KnowledgeGraphIndex:
"""
ドキュメントを非常に慎重にバッチ処理する
"""
final_index = None
processed_count = 0
try:
total_batches = len(documents) // batch_size + (1 if len(documents) % batch_size else 0)
for i in range(0, len(documents), batch_size):
batch = documents[i:i+batch_size]
current_batch = i//batch_size + 1
logger.info(f"Starting batch {current_batch}/{total_batches}")
logger.info(f"Documents in current batch: {len(batch)}")
success = False
retry_count = 0
while not success and retry_count < max_retries:
try:
if final_index is None:
logger.info("Creating new index...")
final_index = KnowledgeGraphIndex.from_documents(
batch,
storage_context=storage_context,
max_triplets_per_chunk=2
)
else:
logger.info("Adding to existing index...")
final_index.insert_nodes(batch)
success = True
processed_count += len(batch)
logger.info(f"Successfully processed batch. Total documents processed: {processed_count}")
except Exception as e:
retry_count += 1
logger.warning(f"Error on attempt {retry_count}: {str(e)}")
if retry_count < max_retries:
wait_time = sleep_time * retry_count # 指数的バックオフ
logger.info(f"Waiting {wait_time} seconds before retry...")
time.sleep(wait_time)
else:
logger.error(f"Failed to process batch after {max_retries} attempts")
raise
# バッチ間の待機時間
logger.info(f"Waiting {sleep_time} seconds before next batch...")
time.sleep(sleep_time)
except Exception as e:
logger.error(f"Fatal error: {str(e)}")
logger.info(f"Processed {processed_count} documents before error")
raise
logger.info("Processing completed successfully!")
return final_index
# 使用例
try:
index = process_documents_in_batches(
documents,
storage_context=storage_context,
batch_size=2, # 非常に小さいバッチサイズ
sleep_time=10, # 十分な待機時間
max_retries=5 # 多めのリトライ回数
)
except Exception as e:
logger.error(f"Failed to process documents: {str(e)}")
データ登録準備完了!
succesfullyとなればサクセスです!

検証
まずはピカチュウについて聞いてみる
おおお〜それっぽい!
しかし、ピカチュウについては一般常識として、モデルに含まれている可能性も。。。
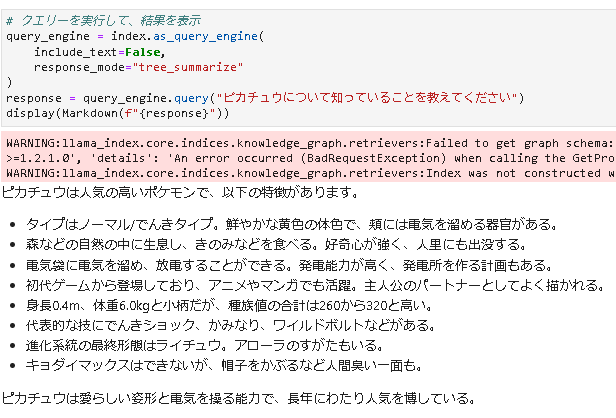
帽子をかぶるが謎ですが、ちゃんと元データに情報ありました。
ただ、「人間臭い一面」について記載がないので、この子(AI)の解釈みたいですね笑

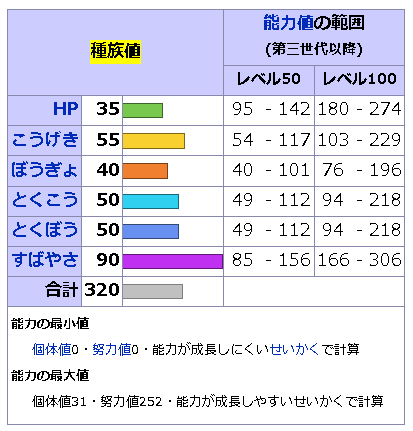
種族値を聞いてみる
さっき種族値という謎ワードがあったので聞いてみる
260または320・・・

元データを確認
第一世代は260、第6世代は320となっているので正解です。

世代を指定して種族値を聞いてみる
正解です!

データを可視化
それっぽい結果が返ってきたので、グラフDBの中身を可視化してみます。
ノートブック->アクション->Graph Explorerを選択
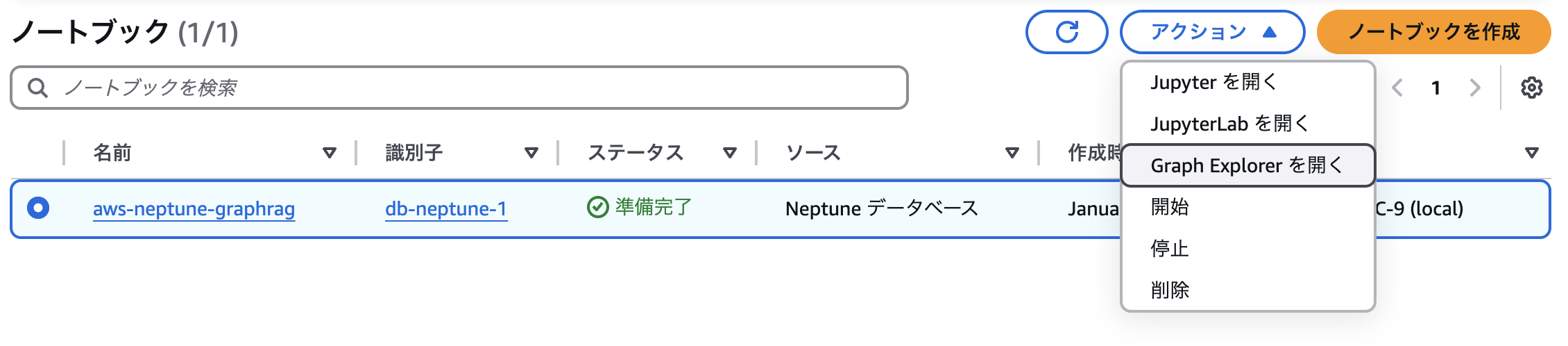
Entityを選択

可視化したい項目をSend to Explorer
ピカチュウとライチュウを選択
選択終わったら、Open Graph Explorerを選択
可視化!
ノードをダブルクリックしてみます。
左側がピカチュウ、右側がライチュウになっていて、「進化する」で紐づいています。
うまくいけてそうですね。

まとめ
AWS上でGraphRAGを試してみました。
今回はピカチュウだけだったので、それっぽい結果になったと思います。
他のポケモンなど、複数の情報を同時に食わせた時にどのようなグラフDBが生成されて、どれ位の精度になるか試してみようと思います。