この記事は NTTコミュニケーションズ Advent Calendar 2018 の4日目です。
はじめに
何している人
社会人5年目。アメリカでDevOpsのロールを担当しています。
今回紹介したいこと
日本でも多くの企業がDevOpsという役割の重要性を認識してポジションが設けられ始めています。しかし,DevOpsが実際にどんな仕事なのか。何を考えて,どのようなスキルが必要で,どのようなアウトプットにコミットメントしているのかはまだまだ世の中に出て来ていないという印象です。そこで今回は,ある自分のアウトプットに対して,どんな考え方をしたか,どのようなアウトプットを出したかを振り返りの意味も込めてまとめようと思います。
考え方
DevOpsの本質は組織やチームの間のサイロによる弊害を減らすことだと解釈しています。その中で最もポピュラーな例がDevとOpsを繋ぐCI/CD等の試験やデプロイメントの自動化であると。よって基本は,「プロダクト開発において,それぞれ専門化された役割(Dev, QA, Ops..etc)を開発工程でつないだ際に生じてしまう互いの領域に踏み込み合う手間を緩和してあげるにはどうするか」という考えになります。一番良いなと思った説明はGoogleの SRE vs. DevOps でした。Youtubeで字幕も付けられるのでおすすめします!
ケーススタディ
QAチーム 「任意のタイミングでコンポーネントをステージング環境へ昇格させたい。」
Devチーム「CIでFeature Branchが動作することは保証するけど,Slackで一言あると良いかもね。」
自分 「レジストリ間のコンテナ昇格を任意のタイミングでしたいってことね。」
問題は何か(What)を定義する
この手の話を受けた時に感じたのは,すべての工程において自動化が基本ではあるが,トリガーするのは人間が実施するケースが残るという点です。つまり解決したい問題(What)をより汎用的な形で定義すると「簡単なインタフェースで特定のタスクをトリガーしたい」となります。
解決策(How)を考える
何を定義する必要があるか整理すると必要な要素を「インタフェース」,「ゲートウェイ」,「ワークロード」の3つに分類できます。これら3つは互いに疎結合であるべきであり,プロジェクトの都合や最適化の途中で変更されうるものと想定しなければなりません。そして,各役割の要件を満たすコンポーネントを候補から選定します。これは組織やプロジェクトで利用しているコンポーネントの再利用やビジネス上の制約条件を考慮した上で選定します。
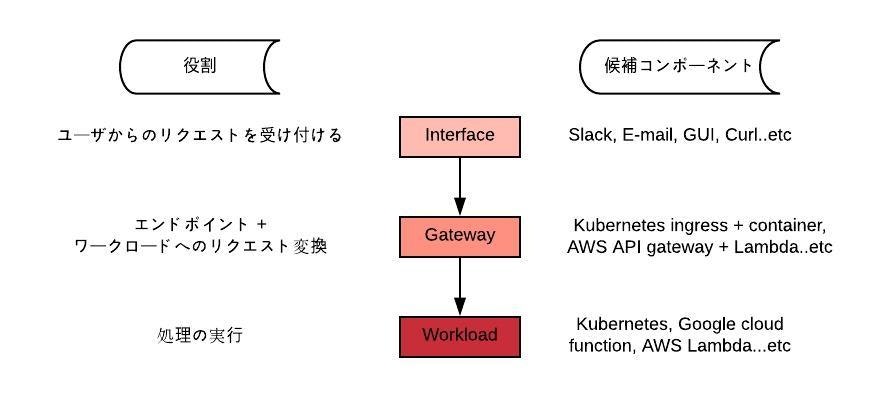
そして今回選ばれたのがこちらの布陣
インタフェース: Slack
ゲートウェイ: Kubernetes Ingress
ワークロード: Kubernetes Job Container
アウトプットとしてはChatopsの実装に近いですが,各要素は疎結合でリプレイス可能に設計しているためインタフェースは何を使っても良いです。KubernetesはDevで利用しているクラスタ(GKE)で遊んでいるリソースを有効に利用したかった点と,One shot container(Job)をワークロードとして試してみたいという考えがあったためです。世の中にあるコンテナ資源を再利用できることやFaaSにおけるタイムアウト制約からの開放,クレデンシャルを外に出さなくて良い点に着目しました。
解決策を実装する
Slack
今回のユースケースの場合,コマンド入力をトリガーにしたかったので「Slash Commands」を採用。チャンネル上からスラッシュで始まるコマンドとREST API Callを対応付けられる機能。ここに実装の要素はありません。強いて言えばコマンドとAPIエンドポイントの設定を自動化したい。Terraform等で定義できると幸せやぁ。
Kubernetes Ingress + Container
Ingress
Ingress(GKEなのでGLBCを利用)はSlackから叩かれるAPIエンドポイントを提供するために必要です。Ingressの説明を始めると長くなるので割愛しますが,一言ならこれはリバースプロキシに相当します。パブリックIPを持たせて,URLの階層とバックエンドをマッピングし,HTTPSを終端します。また,エンドポイントにドメインを使用するのでドメインをGoogle DNSへゾーン委譲してAレコードを設定します。下記がサンプルのIngress.yamlとなります。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.allow-http: "false"
kubernetes.io/ingress.global-static-ip-name: example-public-ip
name: api-gateway
namespace: m2-faas
spec:
backend:
serviceName: faas-backend-flask
servicePort: 5000
tls:
- secretName: wild-card-example-tls
kubernetes.io/ingress.global-static-ip-nameは必須ではありませんが,public ipを固定するために必要です。固定したい場合は予めTerraformでpublic ipを作成しておきます。
##
## Reserved Public IP Address
##
resource "google_compute_global_address" "example-public-ip" {
name = "example-public-ip"
}
SSL証明書については,もちろんみんな大好きLet's Encryptで行きます。Kubernetesから証明書を発行する方法はたくさんあるようですが,ドメインのゾーン委譲もしてあるし今回はCert-managerのDNS Domain認証を利用しました。日本語の記事ではQiitaのこちらの記事が素敵でした。上記のyamlにある通り,cert-managerが生成したsecretsをそのままIngressに食わせられます。Let's Encrypt自体から知りたい!という人はこちらもみんな大好きnetlify(アメリカの方は発音良すぎてネリファイに聞こえる)のKeiko Odaさんが書かれた記事が絵も入っていてとても素敵です。素晴らしいセンスをしてると思います。ぜひお会いしたいです。(笑)
Container
Slackから叩かれるAPIの受け手を用意します。アイディアとして参考にしたのは コチラの方です。 元々サーバレス向けの記事ですが,達成したいことはほぼ同じでした。Flaskでの実装ですが要点は
- Kubernetesのserviceが,コンテナが生きていると判断するためのHealth check用APIを設けること
- Tokenによるアクセスバリデーションをかけること
- Slash Commandsの3秒タイムアウト問題に対応するため,3秒を超える可能性のある処理はThreadでAsyncにすること
※ ContainerがImmutableでなくなるので処理は短く,シンプルなものに限定する。複雑なワークフローを処理する時はJenkins等のPipelineツールをキックした方が良い。
import os
import json
import requests
import concurrent.futures
from flask import abort, Flask, jsonify, request
from kubernetes_manager import KubernetesManager
app = Flask(__name__)
executor = concurrent.futures.ThreadPoolExecutor(max_workers=5)
def is_request_valid_slack(request):
is_token_valid = request.form['token'] == os.environ['SLACK_VERIFICATION_TOKEN']
is_team_id_valid = request.form['team_id'] == os.environ['SLACK_TEAM_ID']
return is_token_valid and is_team_id_valid
@app.route('/', methods=['GET'])
def health_check():
return jsonify({"status": True})
@app.route('/promote-container', methods=['POST'])
def promote_container():
if not is_request_valid_slack(request): abort(400)
k8s_client = KubernetesManager()
raw_res = json.dumps(k8s_client.container_promotion("sampleapp"))
json_res = json.loads(raw_res)
job_name = json_res['metadata']['name']
executor.submit(promote_container_watch, job_name, request.form['response_url'])
attachments = [{'color': 'good',
'text': 'Job: {}, Status: Accepted'.format(job_name)}]
return jsonify(
attachments=attachments,
response_type='in_channel',)
def promote_container_watch(job_name, response_url):
k8s_read_client = KubernetesManager()
status = k8s_read_client.read_namespaced_job(job_name)
if status == 'Complete':
status_color = 'good'
else:
status_color = 'danger'
attachments = [{'color': status_color,
'text': 'Job: {0}, Status: {1}'.format(job_name, status)}]
data = {'attachments': attachments,
'response_type': 'in_channel'}
requests.post(response_url, json=data)
KubernetesManagerについてはpython clientを使いCreate Job, Watch Job Statusを実施します。ちょっと長いの割愛しますが, 説明したいJob作成の部分だけ抜粋して
- [先駆者の方教えて下さい...]リクエストのボディをドキュメントに沿って真面目に書いた。想像以上に面倒だった。utilもあるしyamlからロードしてくる勢が優勢なのでしょうか?
- Jobは同一NameだとName重複で二度目の作成が失敗するので,タイムスタンプを入れていること
- 今回の目玉であるワークロードのコンテナです。今回は google/cloud-sdk:alpine を利用してcloudbuild.yamlをマウントし,それをキックして実施したい処理を行っています。もちろんGoogleのClientを用いて処理を書いてもよいのですが,AWS,Azureとマルチクラウドになった時に出来るだけコードを書かない方法はないかと思い試してみました。
def container_promotion(self, component):
date = time.time()
timestamp = datetime.datetime.fromtimestamp(date).strftime(TS_FORMAT)
metadata = client.V1ObjectMeta(
name="{}-container-promotion".format(timestamp),
labels={"jobgroup": "registry"}
)
containers_env = [
client.V1EnvVar(
name="COMPONENT",
value=component
)
]
container_volume_mounts = [
client.V1VolumeMount(
mount_path="/var/credentials",
name="gcloud-account",
read_only=True
),
client.V1VolumeMount(
mount_path="/var/scripts",
name="init-script",
read_only=True
),
client.V1VolumeMount(
mount_path="/opt",
name="cloudbuild",
read_only=True
),
]
pod_containers = [
client.V1Container(
command=["/var/scripts/init.sh"],
env=containers_env,
image="google/cloud-sdk:alpine",
name="container-promotion",
volume_mounts=container_volume_mounts
)
]
init_script_configmap_volume_source = client.V1ConfigMapVolumeSource(
name="init",
default_mode=0o755
)
cloudbuid_configmap_volume_source = client.V1ConfigMapVolumeSource(
name="cloudbuild",
)
gcloud_account_secret_volume_source = client.V1SecretVolumeSource(
secret_name="gcloud-account",
)
pod_volumes = [
client.V1Volume(
name="init-script",
config_map=init_script_configmap_volume_source
),
client.V1Volume(
name="cloudbuild",
config_map=cloudbuid_configmap_volume_source
),
client.V1Volume(
name="gcloud-account",
secret=gcloud_account_secret_volume_source
)
]
pod_spec = client.V1PodSpec(
containers=pod_containers,
restart_policy="Never",
volumes=pod_volumes
)
template = client.V1PodTemplateSpec(
metadata=metadata,
spec=pod_spec
)
spec = client.V1JobSpec(
active_deadline_seconds=120,
backoff_limit=3,
template=template,
ttl_seconds_after_finished=None)
body = client.V1Job(
api_version="batch/v1",
metadata=metadata,
spec=spec)
return self.create_namespaced_job(body)
実際には複数コンテナを集約するServiceも必要ですが,特に特別なことはしていないので説明は割愛します。
Kubernetes Job Container
コンテナプロモーションを実施するcloudbuild.yaml (TAG名は都合で消しちゃってます) をinit scriptからキックします。
steps:
- name: 'gcr.io/cloud-builders/docker'
args: ['pull', 'gcr.io/${_DEV_PROJECT}/${_COMPONENT}']
- name: 'gcr.io/cloud-builders/docker'
args: ['tag', 'gcr.io/${_DEV_PROJECT}/${_COMPONENT}', 'gcr.io/${_STG_PROJECT}/${_COMPONENT}']
images: ['gcr.io/${_STG_PROJECT}/${_COMPONENT}']
# !/bin/bash
: "${COMPONENT:=sampleapp}"
: "${DEV_PROJECT:=dev-project}"
: "${STG_PROJECT:=stg-project}"
: "${key_file:=/var/credentials/key.json}"
gcloud auth activate-service-account --key-file="${key_file}"
gcloud config set project "${STG_PROJECT}"
gcloud info
gcloud builds submit /opt \
--config /opt/cloudbuild.yaml \
--substitutions \
_COMPONENT="${COMPONENT}",_DEV_PROJECT="${DEV_PROJECT}",_STG_PROJECT="${STG_PROJECT}"
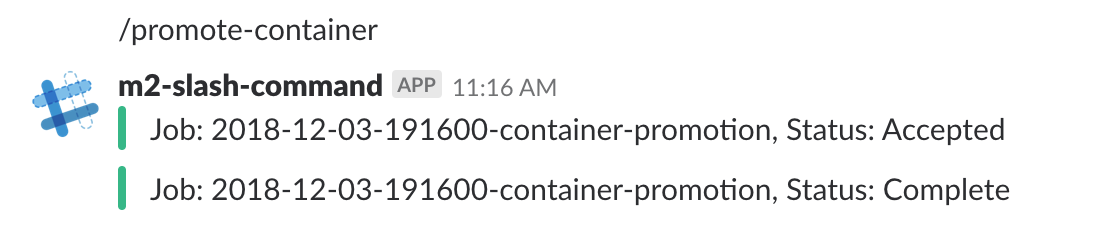
動作イメージ
Gifじゃなくてごめんなさい・・・
おわりに
DevOpsにどんなスキルが問われたのか
Githubでスター60Kのエンジニアロードマップがありますが(Qiitaでは@poly_softさんが記事として紹介していました),これに沿って振り返りをしてみると
https://github.com/kamranahmedse/developer-roadmap#-devops-roadmap
-
Programming Language
Python (Api gateway及びkubernetesのリソース操作に利用) -
Understand OS concept
Containerizeの設計とそのデバッグ (プロセス管理の理解が必要)
KubernetesクラスタにおけるOS及びインスタンス選定
I/O managementを考慮したストレージ設計 -
Managing servers (How to use OS)
Bash scripting, compile source (コンパイルはなかったのでコンテナのビルド相当)
nmap, ping, dig, traceroute, mtr
text manipuration系 -
Network & Security
DNS, HTTP/2, SSL/TLS, IP based filtering (REST API Endpointの準備に必要) -
What is and how to setup xxx (integration skills)
Reverse Proxy (kubernetes ingressで同等の能力が必要)
Loadbalancer (APIのEndpointに必要. GCLB自体の理解も含む)
Firewall (APIのEndpointに必要. Cloud armorの理解も含む) -
Infrastructure as a code
Terraform (AWS, GCP及びkubernetesのリソース管理) -
CI/CD tools
Jenkins, Circle CI, Travis CI, Spinnaker (直接登場しないがこれらの知識とそのインテグレーションが必要) -
How to monitor software and infrastructure
GCPのStackdriverで代用 -
Cloud Providers
Google cloud platform(GCP), Amazon web services(AWS) (マルチリージョン構成を用いた冗長設計)
これらに加えて
Container, Docker, Kubernetes, Let's encrypt (cert-managerによるCERT管理含む) についても理解が必要です。
と,大体このロードマップに示された通りのスキルが必要になりました。
技術には"理解の深さ"という観点もあるので一概には言えないですが,実際の業務と必要になったスキルセットを比較した時に一致していることを知るだけで勉強の方向性が明確になります。
そしてこれは感想ですが,インフラのスキルとして「How to use public cloud」の要素が日々大きくなっています。いちエンジニアとして,本来最も大切であるインフラの泥臭くて成長出来る仕事が減ってしまうのかなと少し怖い気持ちになりました。
まとめ
世の中にはDevOpsとは何たるかについて示されたものが数多く存在しますが,私の結論は「専門ポジションの人間がその仕事に専念できる状態を作る仕事」であると思います。デベロッパーは開発だけ,QAは試験だけを考えられる状態が一番理想なのです。(ハイアリングもし易いしね) 可能な限り避けるべきなのは,開発者や運用者にDevOpsという役割を追加することです。恐らくスキルセットだけを見れば出来ないことはないですが(これが怖いところ),これでは本業である専門ポジションの仕事に専念できない上,その役割の人間を雇おうとすると途端に単価の高いエンジニア(上記のロードマップスキルに加えて専門スキルが求められる)が必要になります。本来解決したい問題を解決できていない上,チームビルディングの観点でもエンジニアの変更が効きづらくなるのは大きな打撃です。これからDevOpsという考え方や役割が広く浸透し,多くの開発現場で重宝される職種として認知されると幸いです。
最後になりますが,Nグループのエンジニアのみなさん(入社を検討している学生さんも含む)には,このようなプロダクション開発を行うポジションがあることを知っていただけると嬉しいです。5年働いてみて,社内で募集されているポジションがもう少し見えるともっと良いな(組織を強くするという意味で)と思ったので,自分のできる範囲で微力ながら発信してみました。おわり。