何を解決するか
少量のデータに対して、機械学習を用いた特徴量重要度の議論をする際には、交差検証などでのデータ分割において、偏ったサンプリングとなり、乱数ごとに特徴量重要度(ランキング)に違いが見られます。(後述)
データサイエンスを使用する現場では多量のデータが確保できることは意外と少ないのではと考えています。
なので、本問題に対策を行わなければ、誤った意思決定を行なってしまうかもしれません。
本記事では、比較的簡単な方法で問題を解決する方法を紹介します。
おおよそ数十〜数百レコードのデータで必要になってくる想定です。
対策
様々な策が提案されているとは思いますが、今回はこちらの記事の簡単にできる解決策を試します。
この方法は、複数の乱数で交差検証CVを行い、それぞれのモデルで特徴量重要度を計算して分布を作り、平均的な重要度とランキングを得るものです。
上記の記事内ではアンサンブルモデルも「アルゴリズム選択でのばらつきを抑える方法」として紹介されています。
一方、少量のデータにアンサンブルモデル(ブースティング系含め)を使用すると過学習を起こしやすいため、今回は使用しません。(めんどくさいわけではない)
CV回数×繰り返し回数の数だけモデルを作るので、機械学習や重要度計算のアルゴリズムは軽量なものがよいと思います。
試してみる
データセットにはdiabetes-datasetを使用します。
また計算速度が速い以下の構成で検証を行います。
線形回帰:Ridge回帰
重要度計算:Permutation Importance
使用ライブラリとバージョン等
- python>=3.13
- "pandas>=3.0.0"
- "scikit-learn>=1.8.0"
- "seaborn>=0.13.2"
コードが汚いのは許してください。
インポート
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.linear_model import Ridge
from sklearn.inspection import permutation_importance
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import RepeatedKFold
データ準備
sklearnのdiabetesデータセットを読み込み、使えるようにします。
diabetes_data: dict = load_diabetes()
data: pd.DataFrame = pd.DataFrame(
data=diabetes_data.data,
columns=diabetes_data.feature_names
)
data["target"] = diabetes_data.target
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
print(X.shape)
# (442, 10)
レコード数442と、今回のターゲットである少量データです。
交差検証の繰り返しでモデルと特徴量重要度を計算する
RepeatedKFold()というクラスを使うと、CVを繰り返し行えます。
# 交差検証の設定(5*3で15のモデルを作る)
N_SPLITS = 5
N_REPEATS = 3
RANDOM_STATE = 42
rkf = RepeatedKFold(n_splits=N_SPLITS, n_repeats=N_REPEATS, random_state=RANDOM_STATE)
# 結果格納用DataFrameの初期化
importances = pd.DataFrame({"Feature": X.columns})
metrics = pd.DataFrame({"Metric": ["mse", "r2"]})
# 交差検証ループ
for split_num, (train_index, test_index) in enumerate(rkf.split(X, y)):
# データ分割
X_train = data.iloc[train_index, :-1]
X_test = data.iloc[test_index, :-1]
y_train = data.iloc[train_index, -1]
y_test = data.iloc[test_index, -1]
# モデル学習
model = Ridge(alpha=1.0)
model.fit(X, y)
# 評価指標の計算と結合
split_metrics = evaluate(model, X_test, y_test)
y_pred = model.predict(X)
split_metrics = pd.DataFrame(data={
"Metric": ["mse", "r2"],
f"SplitNumber{split_num}": [
mean_squared_error(y, y_pred),
r2_score(y, y_pred)
],
}
)
metrics = pd.merge(metrics, split_metrics, how="inner", on="Metric")
# 特徴量重要度の計算と結合
split_importance = permutation_importance(
model,
X_test,
y_test,
n_repeats=30,
random_state=42,
scoring="r2",
)
importances = pd.DataFrame({
"Feature": columns,
f"SplitNumber{split_num}": perm_importance.importances_mean,
})
importances = pd.merge(importances, split_importance, how="inner", on="Feature")
# メトリクスを縦持ちに変換
metrics_long = pd.melt(
metrics,
id_vars="Metric",
var_name="SplitNumber",
value_name="Value"
)
# 平均評価指標の表示
print(metrics_long[["Metric", "Value"]].groupby("Metric").mean())
# > mse 3423.986102
# > r2 0.415761
R2が0.415761なので低いですが、データ量もないのでこんなもんかもしれません。
ハイパーパラメータの調整もしていないので...
結果の可視化
seabornを使って、各特徴量の重要度分布を箱ひげ図で描画します。
_df = pd.melt(importances, id_vars="Feature", var_name="SplitNumber", value_name="Importance")
feature_order = _df.groupby("Feature")["Importance"].mean().sort_values(ascending=False).index
plt.figure(figsize=(10, 6))
sns.boxplot(
data=_df,
x="Feature",
y="Importance",
order=feature_order,
)
sns.swarmplot(
data=_df,
x="Feature",
y="Importance",
order=feature_order,
color="darkblue",
alpha=0.6,
size=5,
edgecolor="white",
linewidth=0.5
)
plt.xlabel("Feature")
plt.ylabel("Importance")
plt.grid(True, axis="y", alpha=0.3)
plt.tight_layout()
plt.show()
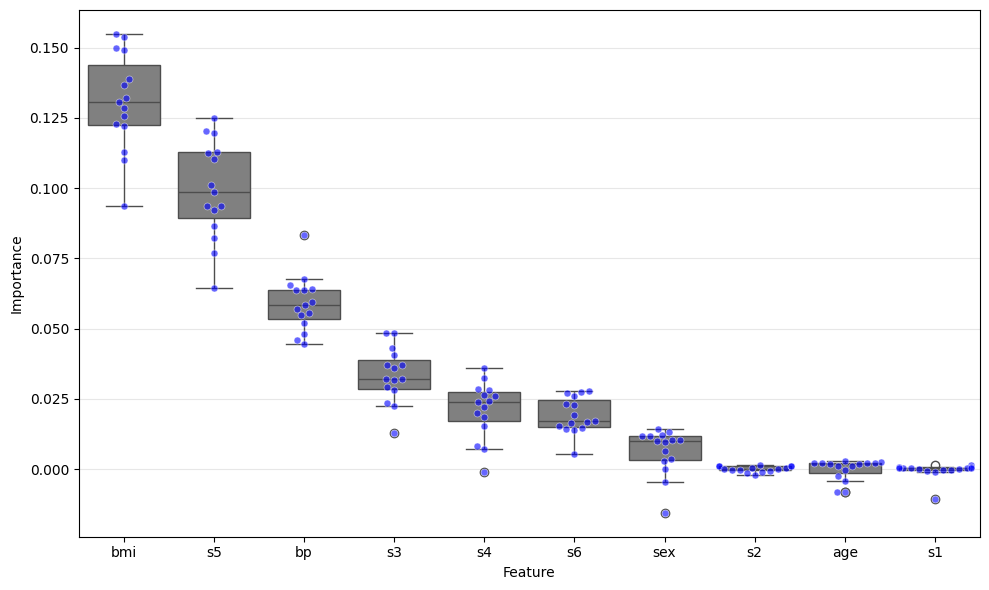
横軸に特徴量、縦軸に重要度をとった箱ひげ図です。
青い点は1モデルでの重要度の値をプロットしています。
bmiの分布が最も高い重要度を示しており、重なるようにs5の重要度が少し下に分布しています。
一方で、s2からs1はほぼ0に分布しています。
このグラフから、各モデル(データ分割方法)で特徴量重要度にばらつきがあり、分布の重なりも見られます。
また、データ分割ごとの特徴量重要度ランキングも見てみます。
rank_columns = importances.iloc[:, 1:].columns
rank_df = pd.DataFrame({'Feature': importances['Feature']})
for col in rank_columns:
# 降順でランク付け(値が大きいほど順位が高い=1位)
rank_df[col] = importances[col].rank(ascending=False, method='min').astype(int)
plt.figure(figsize=(12, 8))
# 各カテゴリごとに折れ線を描画
for i, category in enumerate(rank_df['Feature']):
ranks = rank_df.iloc[i, 1:].values # 順位データ
plt.plot(
rank_columns,
ranks,
marker='o',
markersize=8,
linewidth=2,
label=category
)
plt.gca().invert_yaxis() # Y軸を反転(1位が上になるように)
plt.xlabel('SplitNumber', fontsize=12)
plt.ylabel('Ranking', fontsize=12)
plt.legend(loc='best', fontsize=10)
plt.grid(True, which='both', alpha=0.3)
plt.xticks(rotation=45, ha='right')
plt.yticks(ticks=[i for i in range(1, len(importances.Feature)+1)])
plt.tight_layout()
plt.show()
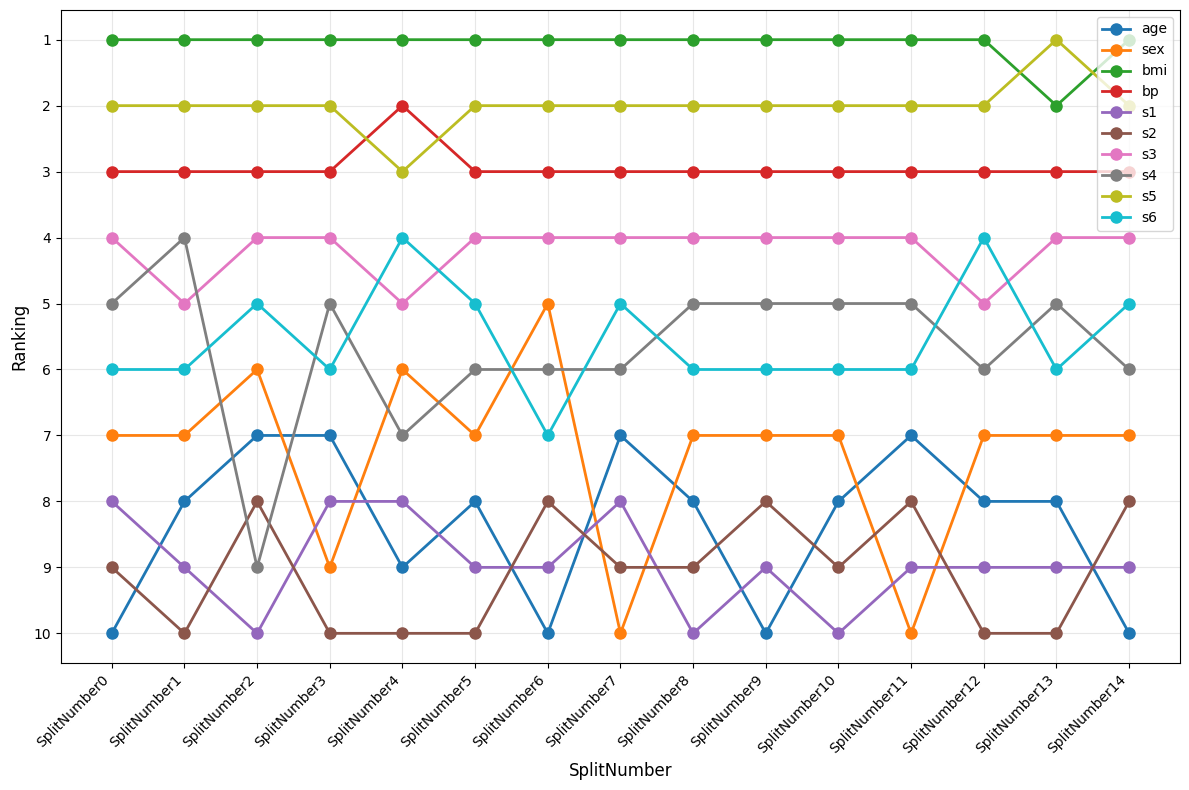
横軸にデータ分割番号、縦軸に各特徴量のランキングを示します。
1位のbmiと2位のs5は、15回のうち一度入れ替わりが起きていることがわかります。
また、2位と3位も1度入れ替わっています。
4位以降は群雄割拠で、データ分割によって異なるランキング結果となりました。
今回は公開データのため比較的綺麗なランキングですが、現場の実データだとより多くの入れ替わりがありそうです。
結論
少量のデータで特徴量重要度を取り扱う際には、データ分割によって結果が変わることがわかりました。
一方で、データ分割を複数の乱数で行い、それぞれモデルを作り重要度を評価することで、分布を描画でき、平均的な重要度とランキングを算出できます。
今回のように比較的簡単な方法でロバスト性を獲得した解釈が可能になります。
隠れたバイアスを取り除いて現場の意思決定をデータドリブンにしたいですね。