はじめに
Self-Supervised Learning(自己教師あり学習)では学習時にはラベルを使わないため、普通の教師あり学習におけるAccuracy(正解率)のようなものは直接取得できないようだ。kNN法を使って進捗をモニターするということがSimSiamの論文に書いてあったので、GPUまたはTPUを使って比較的高速に分類する方法を実装した。
動作確認を兼ねて、すでに学習済みのCNNモデルに適用し、CIFAR10の正解率で各モデルを比較してみた。
Nearest-Neighbor Classifier
一文にすると「特徴空間中でテストデータに最も近いデータのクラスを、そのテストデータのクラスとする」ということで大体あっているはずだが、ここで「最も近い」というのをどう定義するかで実装が分かれる。
「近さ」はユークリッド距離を使うのが一般的なようだが、本記事ではコサイン距離でも評価できるように実装した。
最も近いデータ上位k個から決める場合はkNN法と言われて、k=5が普通のようだ。本記事では、「学習の進捗がわかれば良い」ということにして、簡易的にk=1として実装している。
実装
TensorFlow 2.5.0のtf.kerasで実装した。
class NearestNeighborsClassifier(tf.keras.Model):
def __init__(self, num_classes, features, labels, encoder=None, metric='euclidean'):
super().__init__()
self.distance_metric = metric
self.encoder=encoder
self.num_classes = num_classes
self.label_tensor = tf.convert_to_tensor(labels)
if metric=='euclidean':
self.feature_tensor = tf.convert_to_tensor(features)
self.feature_tensor = tf.expand_dims(self.feature_tensor, axis=0)
elif metric=='cosine':
self.feature_tensor , _ = tf.linalg.normalize(tf.convert_to_tensor(features), axis=1)
else:
raise ValueError('Unknown metric')
def build(self, input_shape):
super().build(input_shape)
def call(self,x):
if self.encoder:
x = self.encoder(x)
if self.distance_metric=='euclidean':
x = tf.expand_dims(x, axis=1)
dist = tf.norm(self.feature_tensor-x, ord='euclidean', axis=2,)
indices = tf.math.argmin(dist, axis=1)
elif self.distance_metric=='cosine':
x , norm= tf.linalg.normalize(x, axis=1)
dist = tf.linalg.matmul(x, self.feature_tensor, transpose_b=True)
indices = tf.math.argmax(dist, axis=1)
labels = tf.gather(self.label_tensor, indices)
x = tf.one_hot(labels, self.num_classes)
return x
def compute_output_shape(self, input_shape):
return (input_shape[0], self.num_classes)
クラス分けのための特徴空間に変換済みのデータとラベルを最初に指定する。その後テストデータを順次入力していくとOneHotで最も近かったデータのラベルが取得できる。
Modelとして定義してevaluateを使って分類するので、GPUやTPUが使えるということになっている。
特徴空間への変換はpredictを使用して事前に変換するが、テストデータの方はencoderを指定すればModel内でも変換できるように実装した。
以下、CIFAR10を分類する場合の例。
def evaluate_nnc(features, labels, features_test, labels_test, metric, verbose=0):
nnc = NearestNeighborsClassifier(10,
features,
labels,
encoder = None,
metric=metric)
loss = tf.keras.losses.SparseCategoricalCrossentropy()
acc = tf.keras.metrics.SparseCategoricalAccuracy(name='acc')
nnc.compile(loss=loss, metrics=[acc])
ds_test_feature = tf.data.Dataset.from_tensor_slices(features_test)
ds_test_label = tf.data.Dataset.from_tensor_slices(labels_test)
ds_nnc = tf.data.Dataset.zip((ds_test_feature,ds_test_label)).batch(16)
return nnc.evaluate(ds_nnc,verbose=verbose)
TRAIN_DATA, VALIDATION_DATA = tf.keras.datasets.cifar10.load_data()
ds_train = tf.data.Dataset.from_tensor_slices(TRAIN_DATA[0]).batch(batch_size).prefetch(tf.data.AUTOTUNE)
ds_test = tf.data.Dataset.from_tensor_slices(VALIDATION_DATA[0]).batch(batch_size).prefetch(tf.data.AUTOTUNE)
encoder = build_model(modelname)
features_train = encoder.predict(ds_train,verbose=verbose)
features_test = encoder.predict(ds_test,verbose=verbose)
result = evaluate_nnc(features_train, TRAIN_DATA[1], features_test, VALIDATION_DATA[1], metric,verbose)
build_modelで事前に学習済みのモデルを生成する。この際にはモデルの最後の層にある全結合の層は省き、直前の層の出力を特徴量とする。CNNの場合はここは大抵GlobalAveragePoolingの出力になっている。
実験
上述のようにCIFAR10を分類して実験する。Google ColabのGPUで実施した。
TensorFlowで提供されているモデルを対象としたが、一部大規模モデルは特徴量のデータがGPUのメモリに収まりきらないようなので対象から除外した。
「ImageNet1Kで学習したモデルを使って追加学習なしに直接CIFAR10を分類したもの」と考えてよいだろう。
metricとして、ユークリッド距離とコサイン距離ともに実施した。
以下、結果。
| モデル名 | パラメータ数 | 特徴次元数 | 正解率(ユークリッド) | 正解率(コサイン) |
|---|---|---|---|---|
| VGG16 | 14.7M | 512 | 0.744 | 0.766 |
| VGG19 | 20.0M | 512 | 0.763 | 0.787 |
| ResNet50 | 23.5M | 2048 | 0.845 | 0.851 |
| ResNet152 | 58.3M | 2048 | 0.884 | 0.888 |
| ResNet50V2 | 23.5M | 2048 | 0.814 | 0.827 |
| ResNet152V2 | 58.3M | 2048 | 0.823 | 0.845 |
| DenseNet121 | 7.0M | 1024 | 0.827 | 0.846 |
| DenseNet201 | 18.3M | 1920 | 0.847 | 0.868 |
| EfficientNetB0 | 4.0M | 1280 | 0.802 | 0.813 |
| EfficientNetB4 | 17.6M | 1792 | 0.857 | 0.858 |
| Xception | 20.8M | 2048 | 0.838 | 0.839 |
| InceptionV3 | 21.8M | 2048 | 0.825 | 0.823 |
| InceptionResNetV2 | 54.3M | 1536 | 0.875 | 0.881 |
| NASNetMobile | 4.2M | 1056 | 0.801 | 0.810 |
| MobileNet | 3.2M | 1024 | 0.818 | 0.830 |
| MobileNetV2 | 2.2M | 1280 | 0.788 | 0.788 |
| MobileNetV3Large | 4.2M | 1280 | 0.853 | 0.864 |
| MobileNetV3Small | 1.5M | 1024 | 0.824 | 0.831 |
以下所見。
- ほとんどのモデルで、コサイン距離で判定した方がユークリッド距離よりも結果が良かった。
- 最高はResNet152(V1)で、最低はVGG16。
- ResNetではV1の方がV2よりも結果がよかった。ImageNetの分類ではV2の方がいいはずで、転移学習でCIFAR10を学習させてもこのような差はでないようなので、metricの相性が悪かったのかもしれない。元の重みを学習させる際の条件(学習率やデータ拡張の方法)もV1とV2では違うはずなので、その辺の影響もあるかもしれない。
- EfficientNet系があまり良くなかった。実際に転移学習などで使用すると好成績なので、これだけでCNNの性能を判断してはいけないようだ。
- MobileNetV3Largeがパラメータ数の割には好成績だった。EfficientNetB0とさほど違いのない構成のはずなので、なぜこのような差が出るのかは謎。
tSNEで視覚化
分類結果が気になったいくつかのモデルに関して、tSNEを使って2次元に落とし込んで視覚的に確認してみる。
図で隣接するクラスは類似度が高いクラスと解釈できて、重なり合っている場合はうまく判断できない可能性が高くなる。
openTSNEを使い、metricはcosineを選択した。
ResNet152
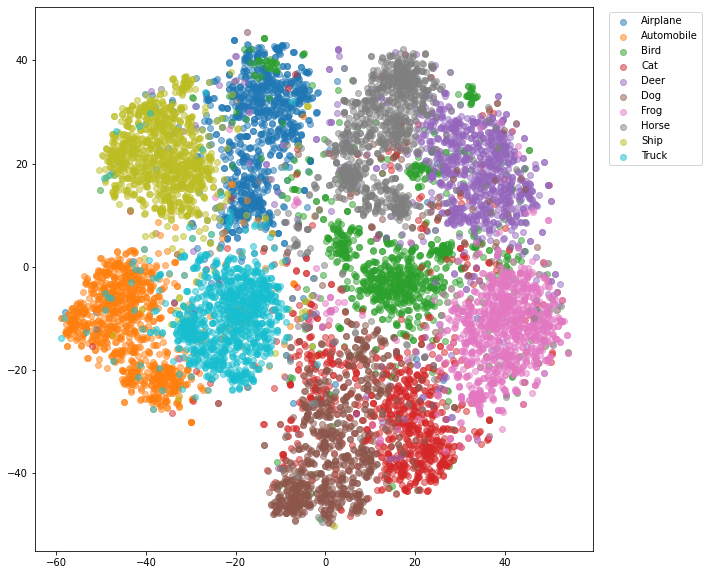
分類性能が最高だったResNet152だが、tSNEのプロットでも比較的綺麗に分類されていることがわかる。
強いて言えば、若干CatとDogの分離が悪く、Birdに関してはまとまり方が他よりも弱いように見える。
VGG16

最も分類性能が悪かったVGGは、tSNEで可視化しても問題があることがわかる。クラス間の境界が曖昧で、特にBirdに関してはほぼ分離できていないように見える。
EfficientNetB0
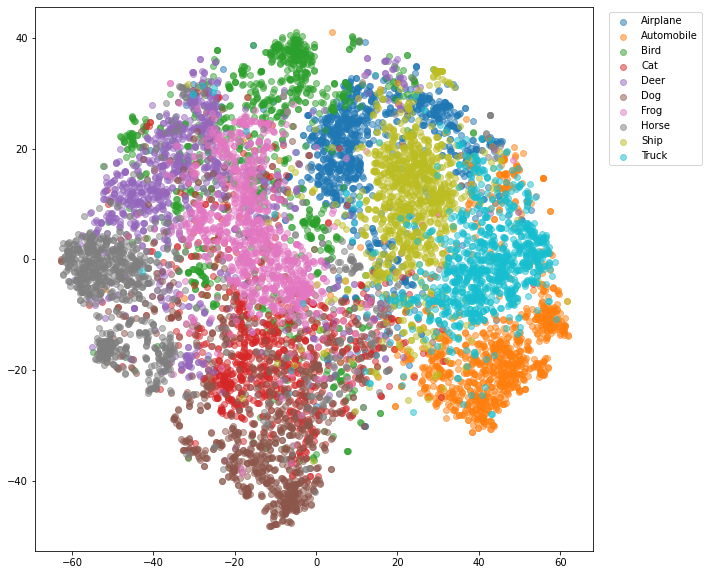
NN法で意外と良くなかったEfficientNetB0は、tSNEで見てもさほど良くないように見える。VGG16よりはマシだが、Birdは苦労している様子。
MobileNetV3Large

Airplaneが2つのクラスタに分かれてしまっているのが残念だが、全体的に見てEfficientNetB0よりは良さそうに見える。(実際に最後に全結合層を追加したモデルで分類すると性能は大差ないが)
まとめ
CNNモデルでの特徴量を使ってNN法でCifar10を分類してみた。
コサイン距離の方がユークリッド距離よりも性能が良い。
NN法の分類性能とtSNEでの視覚的な印象は、概ね一致しているように見える。
各モデルの差が数値的に明らかにはなったが、全結合層を組み込んだモデルの性能とは乖離が見られるものも結構あるので、これだけでモデルの表現力の比較指標としてしまうことはできないようだ。
また、モデル学習時のOptimizerの設定やデータ拡張の手法にも左右されるはずなので、あくまで今回の結果は「TensorFlowで提供される学習済みモデルでの結果」ということは注意したい。
実験用のgoogle Colabノートブックはこちら。