はじめに
本記事では、強化学習の研究でスタンダードになっているAtari2600のゲーム攻略について、筆者が行った実験の内容を記す。
Google Colabで動作するコードを公開する他、多くのゲームについて実際に学習させたAIがプレイしている動画を閲覧できるようにしてある。この手の記事は結構あるのだが、ここまで対象となるゲーム数の多い記事はあまりないのではないかと思う。
実装について
PPOを自前で実装して学習を行った。自作すると間違った実装になるリスクが大きいが、これは筆者が自分で仕組みを理解するための選択なので、この辺のリスクを避けたい場合はStable Baselines等を使った方が良いだろう。実験の結果、論文と同等の性能が出ているようなので、今回の実装に大きな問題は無いと思う。
PPOの解説はすでにネット上に複数あるので、ここでは行わない。こちらの記事が最も信頼できそうで、実装する際にも参考にした。
TensorFlow(Keras)で実装してあるが、機械学習のフレームワーク依存になる箇所はできるだけ局所化させて書いたつもり。
論文との違い
論文とはハイパーパラメータには若干の違いがある。
ハイパーパラメータの違い一覧
| Hyperparameter | 論文 | 本記事 |
|---|---|---|
| Horizon(T) | 128 | 128 |
| Adam stepsize | 0.0025 × α | 0.0025 × β |
| Num epochs | 3 | 4 |
| Minibatch size | 32×8 | 128×8 |
| Discount | 0.99 | 0.95/0.99/0.995/0.999 |
| GAE parameter | 0.95 | 0.95 |
| Number of actors | 8 | 8 |
| Clipping parameter | 0.1 × α | 0.1 |
| VF coef. | 1.0 | 0.5 |
| Entropy coef. | 0.01 | 0.01 |
Adamの学習率は論文では線形で0に減らすが、本実験では指数関数的に0.1倍に減衰。
ネットワークの重みには、別論文に従ってOrthogonalで初期化してある。
そのほか、バッチ単位でAdvantageの値を正規化している。これは、また別の論文の由来のもののはずで、本来は平均を引いて標準偏差で割るようだが、本記事の実装では標準偏差だけ使っている。筆者が誤って実装してしまったことを実験が進んだ後で気づいたのだが、特に悪影響はなかった(場合によってはこの方が良かった)ようなので、これで押し通した。
実験結果
学習に使った総Frame数は論文と同じ40Mにしてある。強化学習の論文でのFrame数は色々解釈があるようなのだが、ここでは最終的にAtariのEnviromentが実行するFrame数を表す。Actionを4つ連続させて1つのObservationデータにしているので、学習に投入するFrameとしては10Mになる。これはGoogle ColabのGPU使用で6〜7時間程度かかる(ゲームによって若干違いがある)。ちなみにDQN系の論文だと200M(50x4M)が主流の模様。
PPOはA2Cの系統で、ゲームを並列実行させられるのも特徴なのだが、GoogleColabではCPUコアは2つしかないので、本記事では並列処理はさせていない。並列処理できるように改造すればコア数が多いPC上で実行した方が早く終わる可能性がある。
以下、論文でのスコアと実験結果の表。(randomとhumanはNature版のDQN論文から引用)
| Game | random | human | PPO(論文) | PPO(実験) |
|---|---|---|---|---|
| Alien | 227.8 | 6875 | 1860.3 | 3093.0 |
| Amidar | 5.8 | 1676 | 674.6 | 909.1 |
| Assault | 222.4 | 1496 | 4971.9 | 4862.1 |
| Asterix | 210 | 8503 | 4532.5 | 6540.0 |
| Asteroids | 719.1 | 13157 | 2097.5 | 133181.0 |
| Atlantis | 12850 | 29028 | 2311815.0 | 2944420.0 |
| Bank Heist | 14.2 | 734.4 | 1280.6 | 1244.0 |
| Battlezone | 2460 | 37800 | 17366.7 | 28100.0 |
| Beam Rider | 363.9 | 5775 | 1590.0 | 4088.0 |
| Bowling | 23.1 | 154.8 | 40.1 | 115.6 |
| Boxing | 0.1 | 4.3 | 94.6 | 89.0 |
| Breakout | 1.7 | 31.8 | 274.8 | 480.0 |
| Centipede | 2091 | 11963 | 4386.4 | 22450.6 |
| Chopper Command | 811 | 9882 | 3516.3 | 13270.0 |
| Crazy Climber | 10781 | 35411 | 110202.0 | 118980.0 |
| Demon Attack | 152.1 | 3401 | 11378.4 | 9248.0 |
| Double Dunk | -18.6 | -15.5 | -14.9 | 15.2 |
| Enduro | 0 | 309.6 | 758.3 | 1122.0 |
| Fishing Derby | -91.7 | 5.5 | 17.8 | 30.0 |
| Freeway | 0 | 29.6 | 32.5 | 32.9 |
| Frostbite | 65.2 | 4335 | 314.2 | 2838.0 |
| Gopher | 257.6 | 2321 | 2932.9 | 59920.0 |
| Gravitar | 173 | 2672 | 737.2 | 955.0 |
| Ice Hockey | -11.2 | 0.9 | -4.2 | -4.7 |
| James Bond 007 | 29 | 406.7 | 560.7 | 5150.0 |
| Kangaroo | 52 | 3035 | 9928.7 | 14140.0 |
| Krull | 1598 | 2395 | 7942.3 | 9274.0 |
| Kung-Fu Master | 258.5 | 22736 | 23310.3 | 42350.0 |
| Montezuma’s Revenge | 0 | 4367 | 42.0 | - |
| Ms. Pac-Man | 307.3 | 15693 | 2096.5 | 3936.0 |
| Name This Game | 2292 | 4076 | 6254.9 | 6633.0 |
| Pitfall | - | - | -32.9 | - |
| Pong | -20.7 | 9.3 | 20.7 | 20.7 |
| Private Eye | 24.9 | 69571 | 69.5 | - |
| Q*bert | 163.9 | 13455 | 14293.6 | 12460.0 |
| River Raid | 1339 | 13513 | 8393.6 | 8218.0 |
| Road Runner | 11.5 | 7845 | 25076.0 | 50070.0 |
| Robotank | 2.2 | 11.9 | 5.5 | 20.6 |
| Seaquest | 68.4 | 20182 | 1204.5 | 2700.0 |
| Space Invaders | 148 | 1652 | 942.5 | 1059.0 |
| Stargunner | 664 | 10250 | 32689.0 | 28530.0 |
| Tennis | -23.8 | -8.9 | -14.8 | 14.2 |
| Time Pilot | 3568 | 5925 | 4342.0 | 4370.0 |
| Tutankham | 11.4 | 167.6 | 254.4 | - |
| Up’n Down | 533.4 | 9082 | 95445.0 | 104567.0 |
| Venture | 0 | 1188 | 0.0 | - |
| Video Pinball | 16257 | 17298 | 37389.0 | 19073.9 |
| Wizard of Wor | 563.5 | 4757 | 4185.3 | 11670.0 |
| Zaxxon | 32.5 | 9173 | 5008.7 | 9960.0 |
論文では、各3回学習を実施して、それぞれの終了時点での100エピソードの平均の平均が結果となっている模様。一方、本記事の実験では、学習中の100エピソード平均で最も高い時点の重みで10回実行した平均スコア。
右端の数字が今回の実験の結果で、humanのスコアを上回ったものを太字にしている。一部ゲームは結果がないが、これは筆者が最初から諦めて実験を実施していないため。
ゲームごとにチューニングしてあり、元論文に掲載されているスコアを大きく上回っている場合があるが、その辺を考察するのが本記事の主な趣旨となる。
ゲーム名のリンクから筆者が学習させたAIによるプレイ動画へジャンプできる。こちらは上記のスコア集計とは別に、3回実施して最高得点のものを動画化している。Asteroids/Atlantis/Enduro/Gopherについては、ゲームオーバーまで動画にすると長すぎるので途中でカットしている。
論文には学習曲線が掲載されていて、これを見ると各ゲームの難易度がなんとなくわかる。ただ、これだけでは「あるゲームで学習が止まっている理由はなぜなのか」などということがわからないのだが、実際にやって見るとわかってきたりする。
論文から引用した学習曲線
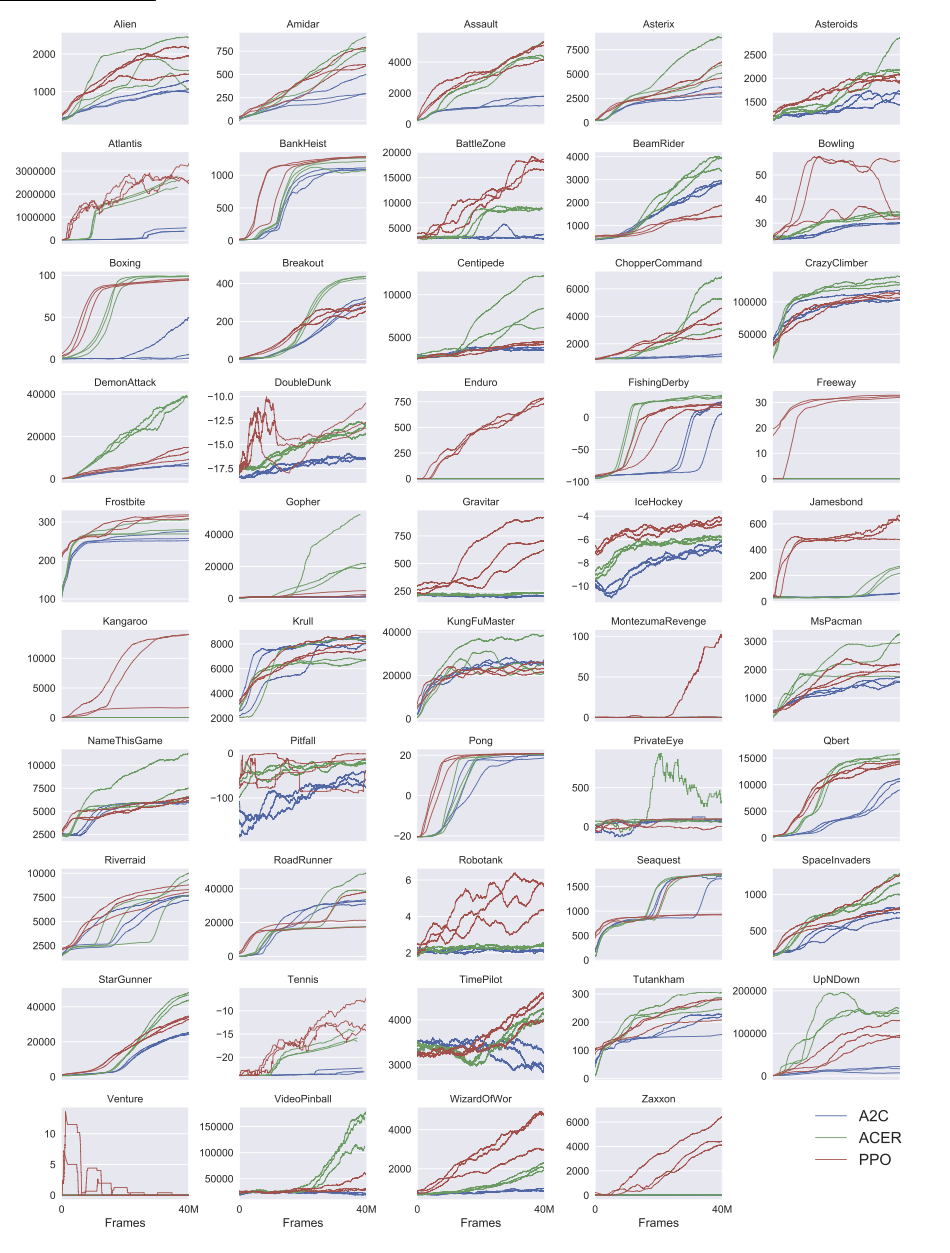
各種チューニングの内容について
普通の論文ではアルゴリズムの汎用性を示すため、基本的に全てのゲームで統一の設定を使って実験されている。筆者は「AIがどの程度ゲームをプレイできるか」に興味があったので、ゲームごとに各種アシストをして高得点を狙っている。以下どのような調整をしたのか記す。
報酬の調整(スケーリング&クリッピング)
初期の強化学習の論文では、「報酬を±1.0でクリッピングする」というのが定番だったが、高得点を狙うためにはこの処理は避けた方が良いゲームが複数存在する。実際、最近のアルゴリズムではクリッピングせずに報酬を適応的にスケーリングするのが基本となっているようだ。
今回の実装では手動で係数を設定してスケーリングしている。
-
スケーリング
- Ms. Pac-Manのように「モンスターを食べると高得点」的な設計は割と多いのだが、これを単純にクリップしてしまうと高得点をとる動機が減る。本記事の実装では報酬に0.001や0.01を掛けて、高得点を狙いやすくしてあるものが多い。
-
クリッピング
-
Bowlingはその名の通りボウリングのゲームで、(スペアやストライクを除いて)2投して倒したピンの数が報酬として得られるが、これを一律に±1.0でクリップすると、AIとしてはピンを多く倒す動機がなく、学習させても低得点で終わる。本記事の実装ではこのゲームについてはクリップ自体を実質無くしている。
-
クリッピングの特殊な例として、Fishing Derbyでは「0から+1にクリッピングする」という処置をしている。このゲームはCPUとの対戦形式の釣りゲームで、自分が釣ると正の報酬、CPUが釣ると負の報酬が入る。しかしゲーム的にはCPU側が魚を釣ることを防ぐ手段は存在しないため、AIの学習にとっては負の報酬に意味がないと考えられるので、負の報酬はなくして自分が魚を釣ることに集中させている。
-
Actionの制限
Atariのゲームで可能なActionは、8方向+入力なしの合計9の移動系に、Fire入力の有無を掛けて、最大で9x2=18になる。ゲームごとに可能なActionは違ってくるが、手動でActionを制限すると学習しやすくなる場合が多いようだ。
主に、下のような方針で制限してある。
-
Fire+方向のActionを取り除く
- 一部のゲームを除きFire+方向のActionは特別な意味を持たないので、単純にこれを選択できないようにすると、総Action数を一気に半分にできたりする。本記事の実装では多くのゲームで「Fire+方向」のActionは積極的に取り除いてある。
-
斜め移動のActionを取り除く
- 4方向しか移動できないゲームに関わらず斜め移動が可能なゲームなどもある。これらを除くと探索するActionが減らせるので学習が速まる場合が多いようだ。
-
上下左右のActionを取り除く(斜め移動だけにする)
- Zaxxonは8方向移動可能なシューティングゲームだが、これは斜め移動だけ制限にした方が成績がよかった。
- 斜めだけで他の移動Actionの代わりが務まる場合は、斜めだけに制限した方が移動効率が良くなるためと思われる。
-
回数制限のあるActionを取り除く
割引率の調整
報酬に対する割引率(Discount)は論文では0.99で固定だったが、ゲームによってはこの値を変えると学習が進みやすくなる。
-
割引率を小さくする
- 報酬の機会が多い場合は、割引率は小さめにすると良い場合がある。
- Breakout/Enduro /Road Runnerは割引率を0.95と小さくしてある。
-
割引率を大きくする
- 報酬の機会が少ない(Actionから報酬までに時間がかかる)場合は、割引率は大きめにすると良い場合がある。
- Amidar/Wizard of Wor/Robotank 等では0.995と大きくしてある。
- Bowlingは0.999と最も大きくしてある。これは、報酬が入るのが2回玉を投げた後でActionと報酬に時間差が大きく、ゲーム内にプレーヤーを妨害する要素も無いため、という理由で説明できると思う。
特定の方向に誘導する
ある種のゲームでは、「特定の方向に進むことがゲームを進めることの前提となっているが、報酬からは直ちにそれがわからない」ということがある。例えば、こちらのスーパーマリオのGym環境では「x軸の距離」によって本来のゲームにはない報酬が与えられているが、これは明らかにステージクリアしやすいように誘導している。
今回攻略対象のAtariのゲームでは単純にゲーム内の得点しか報酬がなく、この手のゲーム設計だと難易度が高いのだが、少し工夫すると誘導できる場合がある。
-
Action自体に報酬を与える
- 誘導したい方向のActionが選択された場合に報酬を与えると、その方向にうまく誘導できる場合がある。
- Enduro/Road Runner/Kangaroo/Kung-Fu Master/Up’n Downでこの手法を使用。
- Kung-Fu MasterやKangarooでは、実は誘導すべき方向は進行状況に応じて変わるのだが、今回の実装では結局そこまで辿り着けないので、最初に誘導したい方向で固定してある。
-
Actionを取り除く
- Actionの制限は特定の方向に誘導したい場合にも使える。Freewayは攻略対象のゲームの中で最も簡単な部類だと思われるが、意外にAIにとっては難しく論文ではPPO以外では全く学習できていない(筆者の実験ではPPOでも運が悪いと失敗した)。このゲームでは、自機を前後に操作して道路を渡り切れば入る報酬しかないのだが、そうなると学習が進むためには偶然にそこまで辿りつくことが必要で、それ自体が確率的に低い。これを「後退を無効にして前進しかできないようにする」というように制限して前方に誘導すると、学習が一気に簡単になる。前述したように「前進に報酬与える」方法でも誘導できる。
- 当該Actionを削除するとゲームの進行に悪影響を与える場合にはこの方法は使えない。
報酬がないことにペナルティを与える
「正の報酬よりも負の報酬が入りやすい」かつ「時間制限がない」というゲームの場合、AIとしては「何もしない」という選択を選びやすくなる。このようなことを防ぐために、一部のゲームでは以下のような処理を入れてある。
- 報酬が入らない時間が長い場合に負の報酬を入れる
- 報酬が入らない時間が長い場合にゲームオーバーにしてしまう
Breakoutについては、ブロックが減ると同じ軌道でループしてしまうことがあり、(何もしないのではなく)ボールを打ち返し続けてしまうことが逆に問題になるので、同様にこの処置を入れて早めに打ち切るようにしている。
報酬が入った時点でエピソード終了とする
ライフ(自機)を失うと内部的にエピソード終了としてしまう処理は以前から行われている。これは大抵のゲームでは、自機を失うと一連の動作として継続性がなくなるため、ということが理由と思われるが、対戦スポーツ系のゲームではライフ自体が存在しないので使えない。対戦型のゲームでは、どちらかに得点が入ると継続性はなくなるので、正でも負でも報酬が入ったらエピソード終了(Doneフラグを立てる)という処理を入れてみた。
これは、Pong/Tennis/Double Dunk/Ice Hockeyで使用。
その他、気づき等
リプレイを見て楽しいゲーム
大抵の場合、AIがプレイしてる動画は純粋に見るだけではそんなに面白いものでもないのだが、一部ゲームではスーパープレイが連発される。
Enduroは、アクセルを踏むこと自体に報酬を与えていることもあり、人間には不可能に思えるようなハイスピードでのゲームプレイが見られる。
Freewayはゲームとしてはシンプルすぎて面白くなさそうなのだが、AIのプレイはかなりスリリングで見所があると思う。
TennisやDouble Dunkも人間ではできそうもないプレイが見られるが、ハメ技に近い感じがしてあまり面白くない。
得点稼ぎだけしてステージが進まないゲーム
点数稼ぎだけしてステージクリアを放棄する場合が結構あり、単純にスコアだけ比較して「人間を超えた」というのはどうなのかと思わせる。
ステージクリアの概念があるゲームでは、何面までクリアしたかでも評価すべきなのだろう。
Kangarooは初代ドンキーコングのように最上階に登ってステージクリアになるのだが、そこへ導く報酬は希薄なので、最下階で時間切れまでひたすら得点稼ぎを行う。
Seaquestは潜水艦で所定の数のダイバーを救ってから海面に浮上するとステージクリアになるのだが、ダイバーを救った時点ではなんの報酬も得られないので、AIとしてはダイバー救出の動機が短期的には存在しない。一方サメや敵潜水艦を倒すと得られる報酬が多いので、海面付近で得点稼ぎの方法だけ学習する。
Kung Fu Master(日本ではスパルタンX)では体力ゲージがあり、体力が0になった時点でライフを失うのだが、この体力減少が負の報酬として入ってこないので、攻撃を避ける行動を学習しにくい設計になっている。その結果、ステージボスにたどり着く頃には体力が削られていてどうしてもボスに勝てない、という状況になる。ステージボスの位置まで前進した後に戦わずに後退していくという情けないプレイなのだが、それでもスコア的には人間より良い点が取れる。
Bank Heistは一番ひどい例で、開始直後に左右移動を繰り返しているだけで、humanのスコアを上回る。
Krullは、点数自体は人間を超えているがステージクリアする気配が全くない。これは筆者もステージクリアの条件がよくわからない(難解な?)ゲームなので仕方ない気がする。
ドットイートタイプのゲームは難しい
これはパックマンに代表されるタイプのゲームで、所定のオブジェクトを全て取ることがステージクリアの条件になるタイプのゲームは、1面もクリアできないものが多かった。ステージ序盤は報酬が入りやすい反面、必然的にオブジェクトが残り少なくなる終盤になってからの学習効率が悪くなることによると思われる。
今回の攻略対象としては、Ms. Pac-Man、Alien、Amidarあたりがドットイートタイプゲームとして分類できるだろう。
Up’n Downは、広義でドットイートタイプに入るはずだが、ステージクリア目前の状況で得点稼ぎを延々と行い、スコア自体は良いものの最初のステージで終わる。
BreakOutは普通はドットイートタイプとされないと思われるが、ゲームが進むつれて確実に報酬の機会が減るという特徴は同じで、全ブロック消去できるまで学習させるのは意外と難しい。
うまく学習できなかったゲーム
Video Pinballはランダムプレイと大差ない結果しか出なかった。これは「Actionと関係なく大量に報酬が入る場面が多い」ことが原因と思われる。
Ice Hockeyは対戦型のスポーツゲームでは唯一平均スコアがマイナスで、リプレイもランダムで操作しているのと大差ないように見える。
シューティングゲームは割と学習の成果が確実に現れることが多かったが、Time Pilotは1面クリアがやっとなので不満が残る。他方向スクロールシューティングは特性的に学習が難しいのかもしれない。
今回は攻略を諦めたゲーム
Pit Fall!、Venture、Montezma's Revenge、Tutankham、Private Eyeについては、難しすぎてまともな学習ができないので対象外としている。簡単に言えば、「初期位置からゲーム内の報酬が入りづらく、人為的な誘導も難しい」というのが原因だろう。
最近のアルゴリズムでは、Intrinsic Reward(内部報酬)を設けることで解決しようとするのが主流のようで、Random Network Distillation(RND)が代表的な手法と思われる。これは見たことのない画面に遷移したら高い報酬が得られるような仕組みを入れて、探索を誘導している。今回いまいちだった他のゲームでも、これを導入したらもっと良い結果が得られたかもしれない。
ゲーム側の不具合
筆者が気づいたゲーム側の不具合を記しておく。
- Road Runnerの画面出力がずれていて、スコア部分が画面に表示されない。
- Bowlingの最終フレームでストライクやスペアをとると報酬が入らない場合がある。
- Up'n Downで本来あるはずの左右のActionが定義されていないので、道の交差箇所で進路変更できない。
まとめ
強化学習(PPO)で各種Atariのゲームの攻略を試みた。
ゲームごとにパラメータ調整等のアシストすることによって、一部ゲームでは論文掲載スコアを大きく上回るスコアを出せた。
ただし、得点稼ぎだけしてステージクリアできないゲームや、Montezma's Revenge等のどうにもならないゲームが複数あった。これらのゲームは内部報酬が有効らしいので、この仕組みを入れて今回うまくいかなかったゲームに再挑戦する予定。