(2018年3月13日追記)
.labファイルと.TextGridファイルのフォーマットについて補足を追加しました。
(2018年7月18日追記)
segment_julius.plがjuliusを読み込めなかった場合の対処法を紹介したページのリンクを追加しました。
はじめに
Praatでは、音声波形に対し「この区間は○○の音を出している」という目印(アノテーション)を付けることができます。
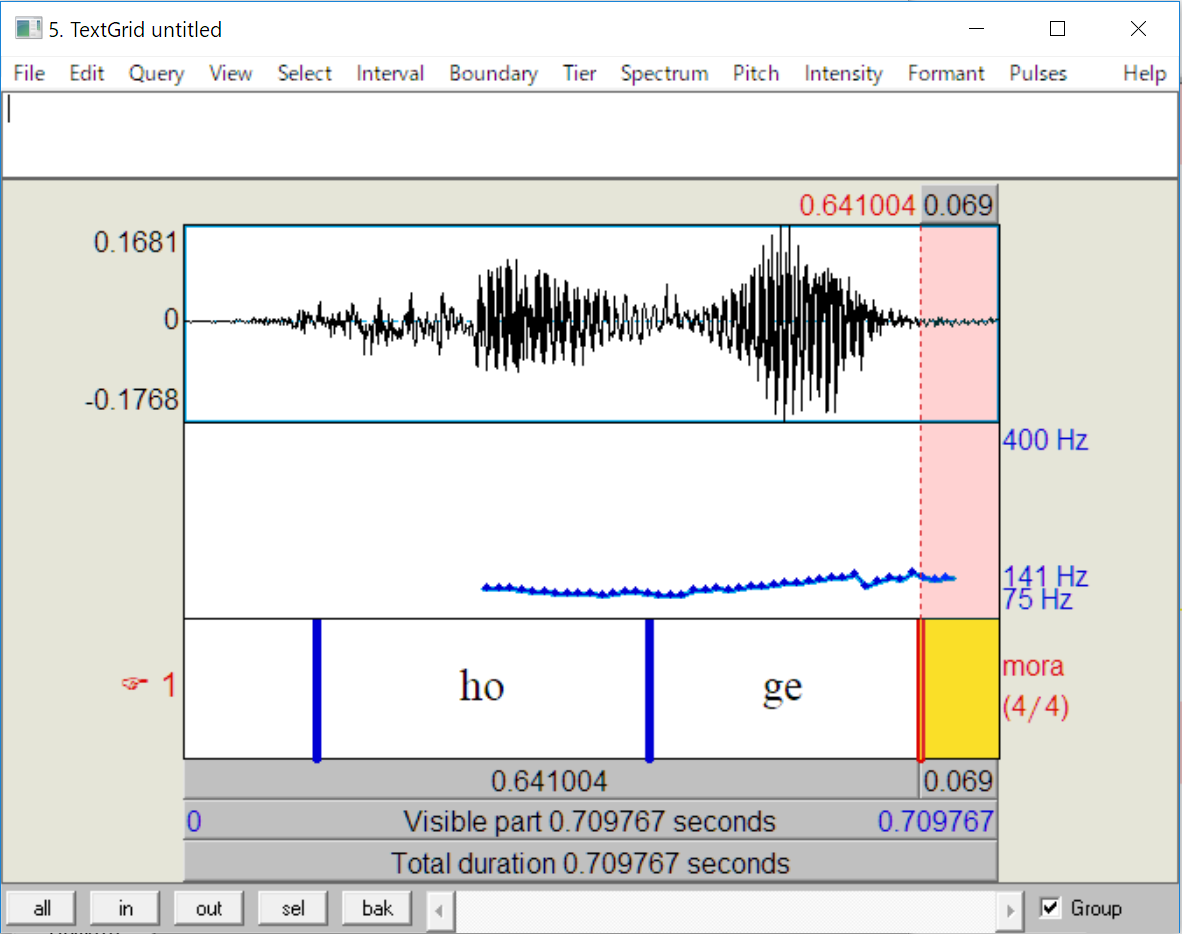
しかし、音声がたくさんある場合、アノテーションを全て手で付けるのは非常に時間がかかります。
そこで、「Julius 音素セグメンテーションキット」を用いてアノテーションを自動生成する方法を紹介します。
(注意)
以下で紹介するのは、発話した(喋った)内容が分かっている場合にしか使えません(セリフを読んでもらった等)。
発話内容から分析する必要がある場合は、別の方法をご検討ください。
使用した環境
ubuntu 16.04
1. 準備、インストール
Julius 本体
こちらの記事を参考にインストールしました。
Ubuntu 17.04 で Julius を使う
$ julius --version
でバージョン情報がでたらインストール成功です。
Julius 音素セグメンテーションキット
perlが入っていない場合は先にインストールしておきます。
続いて、セグメンテーションキットをインストールします。
$ git clone https://github.com/julius-speech/segmentation-kit.git
segmentation-kit内のsegment_julius.pl が本体プログラムです。
このまま使ってもいいのですが、直下の/wavディレクトリしか読み込まないので、コマンドライン引数で
対象ディレクトリを指定できるように改造します。
(修正前, 33行目~)
## data directory
$datadir = "./wav";
(修正後)
## data directory
if ($ARGV[0]){
$datadir = $ARGV[0];
} else {
$datadir = "./wav";
}
python (3.6以上)
セグメンテーションキットが出力したアノテーション(.lab)をPraatで使える形式(.TextGrid)に変換するために使います。
2. データの前処理
Julius 音素セグメンテーションキットは、.wavファイルと、その発話内容を記した.txtファイルから音素区間を推定し
結果を.labファイルに出力します。
.wavファイルのサンプリングレート変換
しかし、セグメンテーションキットが扱えるのはサンプリングレート16kHzかつモノラルの.wavファイルだけです。
以下のPraat scriptコード(convertwav_to_16khz.praat)を使うと、ディレクトリ内全ての.wavファイルを16kHzモノラルに変換できます。
4行目directory$ = "dir/to/path"を指定ディレクトリに書き換えて使用してください。
(追記) 18/11/02: ディレクトリをコマンドライン引数(or フォーム入力)で指定できるように修正しました。
TextGridConverter
発話内容を.txtファイルに記載
すべてひらがな、かつ発音通りに表記します。例えば、sample.wavの発話内容が「今日はいい天気だ」であったら
きょーわいいてんきだ
と表記します。長音は、伸ばし棒「ー」を使うと1音節、別々に書くと2音節として処理されます。
また、.txtファイルは全てutf-8で書く必要があります。
$ file -i sample.txt
sample.txt: text/plain; charset=utf-8
3. Julius 音素セグメンテーションキットを用いた音声アノテーション生成
準備のときにコードを書き換えているので、
$ perl segment_julius.pl path/to/dir
でディレクトリpath/to/dir内の各.wavファイルに対しアノテーション(.lab)を生成します。
pythonのos.walkを使用すれば、path/to/dir内が入れ子構造になっていても全.wavファイルのアノテーション生成が行えます。
import os
import subprocess
import sys
args = sys.argv
for dirpath, dirnames, filenames in os.walk(args[1]):
subprocess.call(['perl', 'segment_julius.pl', dirpath])
$ python segment_recursively.py dir/to/path
hoge.wavのアノテーション結果がhoge.labに出力されます。
結果は音素単位で、silB、silEはそれぞれ開始、終了の無音区間を表します。
0.0000000 0.1850000 silB
0.1850000 0.2745000 h
0.2745000 0.3870000 o
0.3870000 0.4455000 g
0.4455000 0.6415000 e
0.6410000 0.7097500 silE
4. 生成データ(.lab)をPraatで使える形式(.TextGrid)に変換
最後に、できた.labファイルをPraatで使える.TextGrid形式に変換します。
File type = "ooTextFile"
Object class = "TextGrid"
xmin = 0
xmax = 0.7097500
tiers? <exists>
size = 1
item []:
item [1]:
class = "IntervalTier"
name = "phoneme"
xmin = 0
xmax = 0.7097500
intervals: size = 6
intervals [1]:
xmin = 0.0000000
xmax = 0.1850000
text = ""
intervals [2]:
xmin = 0.1850000
xmax = 0.2745000
text = "h"
intervals [3]:
xmin = 0.2745000
xmax = 0.3870000
text = "o"
intervals [4]:
xmin = 0.3870000
xmax = 0.4455000
text = "g"
intervals [5]:
xmin = 0.4455000
xmax = 0.6415000
text = "e"
intervals [6]:
xmin = 0.6410000
xmax = 0.7097500
text = ""
TextGridのフォーマットについて詳細は公式ページをご覧ください。
以下のリンクからconvert_label.pyをダウンロードしてください。
TextGridConverter
convert_label.pyを実行します。
$ python convert_label.py path/to/dir
ラベルをつける単位を音節単位(例: [k, o, N, n, i, ch, i, w, a])にするかモーラ単位(例: [ko, N, ni, chi, wa])にするか選択します。
モーラ単位の場合はy、音節単位の場合はnと打ってください。
change segmentation unit to mora? (default:phoneme) y/n:
もしjuliusが読み込めずエラーが出た場合は、
Juliusによる音素アライメント(音素セグメンテーション) on MacOSX(Yosemite)
を参考にしてsegment_julius.plがjuliusを参照するディレクトリを変更してください。
ディレクトリpath/to/dir内の全.labファイルが.TextGridファイルに変換されます。
お疲れ様でした。これでpraatで使用できるアノテーションが得られました。
参考文献
Ubuntu 17.04 で Julius を使う
Python、os.walkでディレクトリ走査 - naritoブログ
公式ページ
Juliusによる音素アライメント(音素セグメンテーション) on MacOSX(Yosemite)