Hands-On Machine Learning with Scikit-Learn and TensorFlowを読んでいます.
読んだところをまとめ.
前段は特に重要なことは書いていないので飛ばします.
(9.1) Installation
Tensorflowのインストール方法は巷にいろいろな記事がありますので,それらを参考にしてください.一旦ここではmacで
pip install -- upgrade pip
pip install tensorflow
という風にインストールされたとして話を進めていきます.
(9.2) Creating Your First Graph and Running It in a Session
次のコードでFigure 9-1のグラフが作れます.
import tensorflow as tf
x = tf.Variable(3, name="x")
y = tf.Variable(4, name="y")
f = x * x * y + y + 2
注意すべき点は,このコードは実態はグラフを作っただけで,計算しているように見えてなにも計算していないことです.変数(x,y)は初期化すらされていません.このグラフを使って計算するには,Tensorflowのsessionを開けて変数を初期化し,fを評価しなければいけません.
TensorflowのsessionはCPUやGPUなどのデバイスに変数を乗せるオペレーションなどを全部面倒みてくれます.次のコードでは,先ほどの変数(x,y)とfに対して,sessionを作り,変数を初期化し,fを評価し,クローズするという一連の流れを行います.
sess = tf.Session()
sess.run(x.initializer)
sess.run(y.initializer)
result = sess.run(f)
print(result)
sess.close()
いちいちsess.run()をしなければならないのは面倒なので,以下のように書くことで先ほどのコードと同じことができます.
with tf.Session() as sess:
x.initializer.run()
y.initializer.run()
result = f.eval()
上のコードではwithブロック内ではデフォルトのsessionが適用され,
-
x.initializer.run()はtf.get_default_session(). run( x.initializer)と同一 -
f.eval()はtf.get_default_session(). run( f)と同一
と解釈されます. これでコードがみやすくなるうえに,withブロックの終わりで自動的にsessionが終了します.
また,各変数に対してそれぞれinitializerを走らせるのもの面倒なので,代わりにglobal_variables_initializer()を使うことができます.これもコードを実行してすぐに初期化するのではないことに注意してください.この関数では実行時に全てのノードを作ってくれます.
init = tf.global_variables_initializer()
# prepare an init mode
with tf.Session() as sess:
init.run() # actually initialize all the variables
result = f.eval()
またjupyterやPythonシェル内ではInteractiveSessionを作る方が便利だったりすることがあります.先ほどのコードのような普通のsessionとの違いはInteractiveSessionは作られたときに自動的にデフォルトのsessionになることで,したがってwithブロックを書く必要はありません.
sess = tf.InteractiveSession()
init.run()
result = f.eval()
sess.close()
TensorFlowの典型的なプログラムは2つの部分に分けることができます.
- a computation graphを作るフェーズ (構築フェーズ:the construction phase)
- そのグラフの計算を走らせるフェーズ (実行フェーズ:the execution phase)
以下では事例を元にこの手順を試してみましょう.
(9.3) Managing Graphs
ノードを作ると自動的にデフォルトのグラフに追加されます.例えば次のコードでグラフにノードを追加したとします.
x1 = tf.Variable( 1)
x1. graph is tf.get_default_graph()
だいたいのケースでは問題ないんですが,たまにいくつかの独立したグラフを使っているときに支障をきたします.
別のグラフとして上記を使いたい場合は新しいグラフを作ってwithブロック内で一時的にデフォルトグラフとして使うことができます.
graph = tf.Graph()
with graph.as_default():
x2 = tf.Variable( 2)
このとき,次のような結果が返ってきます.
>>> x2. graph is graph
True
>>> x2. graph is tf.get_default_graph()
False
(9.4) Lifecycle of Node Value
ノードを評価するとき,TensorFlowは別のノードに依存しているノードを自動的に探してきて,一番大元にあたるノードから評価していきます.例えば次のコードを考えます.
w = tf.constant(3)
x = w + 2
y = x + 5
z = x * 3
with tf.Session() as sess:
print( y.eval()) # 10
print( z.eval()) # 15
最初の4行で簡単なグラフを定義しています.
sessionが始まると,y.eval()でyの評価を,z.eval()でzの評価を始めます.
-
yの評価ではTensorFlowがyがxに依存している,xがwに依存しているということを自動的に検出してきて,w,x,yという順に評価していき,yの値を返します. -
zの評価でも同様にw,x,zという順に評価していきますが,ここで注意しなければいけないのは,yを評価するさいに使ったwとxの値は再利用しないということです.つまり上のコードではwとxは2回づつ評価されます.
どうなっているかというと,いくつかのグラフの評価を走らせる場合,あるグラフから別のグラフの評価に移る際に全てのノードの値を消去してしまいます(queues and readers also maintain some state, as we will see in Chapter 12).
一方,変数はinitializerが走った後,sessionが閉じられるまで消えずに存在し続けるため,変数の値はあるグラフから別のグラフの評価の間で保持されます.wとxの値を再評価しないでyとzを効率的に評価するには,次のコードのように1つのグラフを走らせる間にyとzを評価すればよいです.
with tf.Session() as sess:
y_val, z_val = sess.run([ y, z])
print( y_val) # 10
print( z_val) # 15
(9.5) Linear Regression with TensorFlow
TensorFlowのoperationsはopsと省略します.
opsはインプット何個でもアウトプット何個でも大丈夫です.たとえば,
- 和と積は2つのインプットに対して1つのアウトプットを出力します.
- 定数と変数はインプットをとりません,こうしたopsをsource opsといいます.
これらのインプットとアウトプットはtensorと呼ばれる多次元配列です.
Numpyと同じでtensorも型(type)と形(shape)を持ちますが,実はPython APIのtensorはNumpy ndarrayで表現されています.
これまでの例ではtensorはスカラー値を保持してましたが,どんな形の配列でも計算できます.
たとえば次のコードは2次元配列を使って(Chapter2で使った)the California housing データセットで線形回帰を行います.
手順としては
- データセットを変数に代入します
- すべての変数(フィーチャ)にbias input($x_0 = 1$)を加えます(NumPyを使っているのでこれはコードのところで実行)
-
Xとyという2つのノードを作成し,これらを使ってthetaを定義します. - sessionを作成し,
thetaを評価します.
という流れで計算をしています.
補足:
行列関数:transpose(), matmul(), matrix_inverse() の意味は名前からわかると思いますが,これらはTensorflowが提供している関数です.この関数も使われた直後に実行されるのではなく,グラフにノードを作るだけで,グラフが実行される中でこれらの関数も実行されます.また,thetaの定義は正規方程式の解 $\theta=X^T\cdot X)^{-1}\cdot X^T\cdot y$です.(Chapter 4を参照).
import numpy as np
from sklearn.datasets import fetch_california_housing
# to make this notebook's output stable across runs
def reset_graph(seed=42):
tf.reset_default_graph()
tf.set_random_seed(seed)
np.random.seed(seed)
reset_graph()
housing = fetch_california_housing()
m, n = housing.data.shape
housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]
X = tf.constant(housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
XT = tf.transpose(X)
theta = tf.matmul(tf.matmul(tf.matrix_inverse(tf.matmul(XT, X)), XT), y)
with tf.Session() as sess:
theta_value = theta.eval()
print(theta_value)
Numpyを使って正規方程式の解を計算する代わりに上のコードを使うメリットは,Tensorflowはちゃんと設定しておけば,勝手にGPUなどを使ってくれるところです(Chapter 12を参照).
(9.6) Implementing Gradient Descent
ここでは正規方程式の解を使うのではなくて,Tensorflowを使ってBatch Gradient Descent (Chapter 4参照)をやってみましょう!
はじめに(9.6.1で) gradientを手動で計算してやる方法と,次に(9.6.2で)Tensorflowのautodiffを使ってgradientを自動で計算し,最後に(9.6.3で)TensorFlowのout-of-the-box optimizerを使ってgradient decentりましょう!
(9.6.1) Manually Computing the Gradients
gradient decentするには,事前にフィーチャベクトルをスケーリングしとかないといけません.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_housing_data = scaler.fit_transform(housing.data)
scaled_housing_data_plus_bias = np.c_[np.ones((m, 1)), scaled_housing_data]
print(scaled_housing_data_plus_bias.mean(axis=0))
print(scaled_housing_data_plus_bias.mean(axis=1))
print(scaled_housing_data_plus_bias.mean())
print(scaled_housing_data_plus_bias.shape)
次のコードで本チャンのgradient decentをします,内容はだいたい読めばわかるでしょう.いくつか補足をしておきます:
- random_uniform()は乱数のtensorをグラフのノードに作る関数です. Numpyのrand()みたいに形(shape)と値のレンジを指定する必要があります.
- assign()は変数に新たな値を代入する関数です.下の例ではBatch Gradient Decentの$\theta^{(\text{next step})}=\theta-\eta\nabla_\theta\text{MSE}(\theta)$を実装しています.
- mainループは訓練を何回も繰り返し,100回ごとに回ごとに,その時のmseを返します.毎回mseが小さくなることを確認してください.
reset_graph()
n_epochs = 1000
learning_rate = 0.01
X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
gradients = 2/m * tf.matmul(tf.transpose(X), error)
training_op = tf.assign(theta, theta - learning_rate * gradients)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
if e
poch % 100 == 0:
print("Epoch", epoch, "MSE =", mse.eval())
sess.run(training_op)
best_theta = theta.eval()
(9.6.2) Using autodiff
前節のコードはそれはそれでうまくいくんですが,コスト関数(MSEのこと)のgradientが数学的にわかってないと使えません.
線形回帰なら簡単ですが,たとえばDeep Neural Networkとかでgradientを計算するのは至難の業です.
自動微分を使って偏微分を計算することもできますが,結果出来上がるコードは必ずしも効率的なものではありません.
TensorFlowのautodiffを使えば自動的かつ効率的にgradientを計算してくれます.
上のコードのgradients = ...の行の右辺をtf.gradient(mse, [theta])[0]と書き換えればOKです.
reset_graph()
n_epochs = 1000
learning_rate = 0.01
X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
# ↓ここを書き換えました
gradients = tf.gradients(mse, [theta])[0]
# ↑ここを書き換えました
training_op = tf.assign(theta, theta - learning_rate * gradients)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
if epoch % 100 == 0:
print("Epoch", epoch, "MSE =", mse.eval())
sess.run(training_op)
best_theta = theta.eval()
print("Best theta:")
print(best_theta)
gradients()関数はops(mse)と変数のリスト(theta)を引数に取り,第一引数のopsのgradientを第二変数の各変数に対応して計算し,結果のopsのリスト(変数1つに対して1ops)を作ります.今回のコードではthetaに関するMSEのgradientを計算してくれます.
gradientの計算には主に4つのアプローチがあって,Table9-2にまとめていますが,TensorFlowはreverse-mode autodiffを使っていて,インプットが多くアウトプットが少ない場合は効率的で正確な手法なので,バッチリです.Neural Networkのときも同じような状況なので,バッチリです.
(9.6.3) Using an Optimizer
TensorflowはGradient Decent Optimizerを含むout of the boxのoptimizersをいくつか提供しているので,それを使うこともできます.
そのときはgradients = ...とraining_op = ...を入れ替えて,次のコードのようにすればOKです.
reset_graph()
n_epochs = 1000
learning_rate = 0.01
X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
# ↓ここを書き換えました
optimizer = tf.train.GradientDescentOptimizer( learning_rate = learning_rate)
training_op = optimizer.minimize( mse)
# ↑ここを書き換えました
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
if epoch % 100 == 0:
print("Epoch", epoch, "MSE =", mse.eval())
sess.run(training_op)
best_theta = theta.eval()
print("Best theta:")
print(best_theta)
別のoptimizerを使いたいときはoptimizer = ...の一行を書き換えればOKです.
たとえば,Gradient Decent Optimizerより早く収束するMomentum Optimizerを使うには次のようにします(詳しくはChapter11を参照).
reset_graph()
n_epochs = 1000
learning_rate = 0.01
X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
# ↓ここを書き換えました
optimizer = tf.train.MomentumOptimizer( learning_rate = learning_rate, momentum = 0.9)
# ↑ここを書き換えました
training_op = optimizer.minimize( mse)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
if epoch % 100 == 0:
print("Epoch", epoch, "MSE =", mse.eval())
sess.run(training_op)
best_theta = theta.eval()
print("Best theta:")
print(best_theta)
(9.7) Feeding Data to the Training Algorithm
前節のコードをMini-batch Gradient Decentにしましょう!必要なことはxとyを毎回のイテレーションで更新することですが,プレースホルダノード(placeholder nodes)を使うことで,訓練中に訓練データをTensorflowに渡すことができます.
プレースホルダノードのポイントは以下の感じです.
- placeholder()で使えます.
- アウトプットのtensorの型を指定します.
- 実行時の返り値を指定しないとエラーが出力されます.
- オプション引数でアウトプットの形(shape)を指定することができます.
- 次元(dimension)に
Noneを指定すると,どんなサイズでも扱えます.
たとえば,次のコードは以下の手順で計算します.
- プレースホルダ
AとノードB = A + 5を作ります. -
B.evalでBを評価するとき,Aをfeed_dictを通してeval()メソッドに渡すことで,```A``の値を指定します. -
Aを渡すとときには,Aは$2$次元であること,$3$カラムあること(3で指定),行数はいくつでもよいこと(Noneで指定)に注意してください.
A = tf.placeholder( tf.float32, shape =( None, 3))
B = A + 5
with tf.Session() as sess:
B_val_1 = B.eval( feed_dict ={ A: [[ 1, 2, 3]]})
B_val_2 = B.eval( feed_dict ={ A: [[ 4, 5, 6], [7, 8, 9]]})
print( B_val_1)
print( B_val_2)
Mini-batch Gradient Decentを実装するには次の手順を踏みます.
- 構築フェーズの`
``xとy```をプレースホルダノードに変え,batchサイズとbatch数を決めます. - 実行フェーズでmini-batchを毎回代入し,
feed_dictパラメータでXとyを作ります.
# 1.のコード
X = tf.placeholder(tf.float32, shape=(None, n+1), name="X")
y = tf.placeholder(tf.float32, shape=(None, 1), name="y")
batch_size = 100
n_batches =int(np.ceil(m / batch_size))
# そのほかもろもろの準備
n_epochs = 100
learning_rate = 0.01
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse)
init = tf.global_variables_initializer()
# 2.のコード
def fetch_batch(epoch, batch_index, batch_size):
np.random.seed(epoch * n_batches + batch_index) # not shown in the book
indices = np.random.randint(m, size=batch_size) # not shown
X_batch = scaled_housing_data_plus_bias[indices] # not shown
y_batch = housing.target.reshape(-1, 1)[indices] # not shown
return X_batch, y_batch
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
for batch_index in range(n_batches):
X_batch, y_batch = fetch_batch(epoch, batch_index, batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
best_theta = theta.eval()
print(best_theta)
(9.8) Saving and Restoring Models
モデルの訓練が終わったらパラメータを保存したいし,実行中のクラッシュに備えて訓練中にチェックポイントを保存しときたいですよね.
Tensorflowでは,構築フェーズの終わりにSaverノードを作り,実行フェーズでsave()メソッドを保存したい時に実行すれば保存できます.
保存する内容はモデルとセッション,チェックポイントファイルのパスです.
次のコードはGradient Decent Optimizerの例でチェックポイントを保存する例です.(テキストと違い,tfcheckpointフォルダを実行フォルダの下に作り,そこに保存しています.)
reset_graph()
n_epochs = 1000
learning_rate = 0.01
X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse)
init = tf.global_variables_initializer()
# ↓構築フェーズの最後にsaver作成
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
if epoch % 100 == 0:
print("Epoch", epoch, "MSE =", mse.eval())
# ↓毎100回ごとにチェックポイント保存
save_path = saver.save(sess, "./tfcheckpoint/my_model.ckpt")
sess.run(training_op)
best_theta = theta.eval()
# ↓最後にチェックポイント保存
save_path = saver.save(sess, "./tfcheckpoint/my_model_final.ckpt")
保存したチェックポイントを読み込むのも簡単です.
構築フェーズの最後にSaverを作るのは先ほどと同じですが,実行フェーズの最初にinitで変数を初期化する代わりに,Saverオブジェクトのrestore()メソッドを呼びます.
with tf.Session() as sess:
saver.restore(sess, "./tfcheckpoint/my_model_final.ckpt")
best_theta_restored = theta.eval()
best_theta_restored
デフォルトではSaverは全ての変数を,宣言したときの名前で保存します.保存する変数とその名前を自分で選びたときは,saver = tf.train.Saver({"weights": theta})のように指定すればOKです.
また,デフォルトのsave()メソッドでは,.meta拡張子がついたファイルにグラフの構造を保存します.このグラフの構造はtf.train.import_meta_graph()メソッドで呼び出すことができます.このメソッドは呼び出したグラフをデフォルトグラフに追加し,グラフの状態を使えるようにSaverインスタンスを返します.たとえば,先ほどの例のグラフは次のコードで呼び出せます.
saver = tf.train.import_meta_graph("./tfcheckpoint/my_model_final.ckpt.meta")
with tf.Session() as sess:
saver.restore(sess, "./tfcheckpoint/my_model_final.ckpt")
(9.9) Visualizing the Graph and Training Curves Using TensorBoard
これまでのコードでは訓練の進捗をprint()関数に頼っていましたが,TensorBoardを使えば,訓練に関する統計値のinteractiveなvisualizationをブラウザ上に表示できます.また,グラフの定義も表示でき,グラフ上のエラーやボトルネックを探すなどのことができます.
TesorBoardを使えるようにするには次の4つのステップでこれまでのコードを修正する必要があります.
1.グラフの定義と訓練時の統計値をログ保存用のディレクトリに保存するためのコードを追加します.このとき注意しなければいけないのが,TensorBoardは実行するごとに統計値をマージしてしまい,visualizationがぐちゃぐちゃになってしまうので,各実行回ごとに別のログディレクトリを作る必要があります.一番簡単な方法は次のコードのようにログディレクトリ名にtimestampを入れることです.
from datetime import datetime
now = datetime.utcnow(). strftime("% Y% m% d% H% M% S")
root_logdir = "./tf_logs"
logdir = "{}/ run-{}/". format( root_logdir, now)
2.構築フェーズの最後に次のコードを追加して,ログディレクトリに統計値を保存するようにします.
mse_summary = tf.summary.scalar('MSE', mse)
file_writer = tf.summary.FileWriter( logdir, tf.get_default_graph())
1行目でMSEを計算してsummaryと呼ばれるTensorBoard用のバイナリログ文字列を作っています.2行目でsummaryをログディレクトリ内のログファイルに書き込むFileWriterを作っています.FileWriterの第一引数はログディレクトリのパス,第二引数はvisualizeしたいグラフを指定します.FileWriterを作るときにログディレクトリが作られていない場合は,FileWriterが作ってくれ,(ログディレクトリがあるときでもないときでも)events fileと呼ばれるグラフの定義が記録されたバイナリログファイルを置いてくれます.
3.実行フェーズで,訓練中に上記のmse_summaryを計算するコードを追加します.これには上で定義したfile_writerを使って,event fileに書き込むことでできます.
4.プログラムの最後にFileWriterを閉じます.
以上の修正を加えたコードが次のものです.
reset_graph()
from datetime import datetime
# 1.ログディレクトリの用意
now = datetime.utcnow().strftime("%Y%m%d%H%M%S")
root_logdir = "./tf_logs"
logdir = "{}/run-{}/".format(root_logdir, now)
n_epochs = 1000
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=(None, n + 1), name="X")
y = tf.placeholder(tf.float32, shape=(None, 1), name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse)
init = tf.global_variables_initializer()
# 2.FileWriterの用意
mse_summary = tf.summary.scalar('MSE', mse)
file_writer = tf.summary.FileWriter(logdir, tf.get_default_graph())
n_epochs = 10
batch_size = 100
n_batches = int(np.ceil(m / batch_size))
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
for batch_index in range(n_batches):
X_batch, y_batch = fetch_batch(epoch, batch_index, batch_size)
if batch_index % 10 == 0:
summary_str = mse_summary.eval(feed_dict={X: X_batch, y: y_batch})
step = epoch * n_batches + batch_index
# 3.統計値の記録
file_writer.add_summary(summary_str, step)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
best_theta = theta.eval()
# 4. FileWriterの終了
file_writer.close()
# 結果の表示
print(best_theta)
コードの修正ができたらプログラムを実行しましょう.ログディレクトリができてログファイルがその中にできます.この中にはグラフの定義とMSEの値が格納されています.
確認するために,シェルを立ち上げ,working directoryへ移動し,
ls -l tf_logs/run*
というコマンドを実行してください.
-rw-r--r-- 1 'username' staff 18620 Sep 6 11:11 events.out.tfevents.1517126950.'userPCname'.local
という結果が帰ってくると思います.(2回目なら別のログフォルダが参照すべきフォルダです)
これでTensoBoardを立ち上げる準備ができたことが確認できました!このログファイルを使ってTensorBoardを立ち上げましょう!
いろいろ面倒な話は省略して先ほどworking directoryへ移動したシェルを使って 次のコマンドを実行しましょう.
Tensorboard --logdir tf_logs
実行後に次のメッセージが流れてきたらOKです(バージョンはなんでもok)
TensorBoard 0.4.0rc3 at http://'userPCname'.local:6006 (Press CTRL+C to quit)
ブラウザのurlにlocalhost:6006と入力して移動してください.
次のようなページに移動したらOKです.
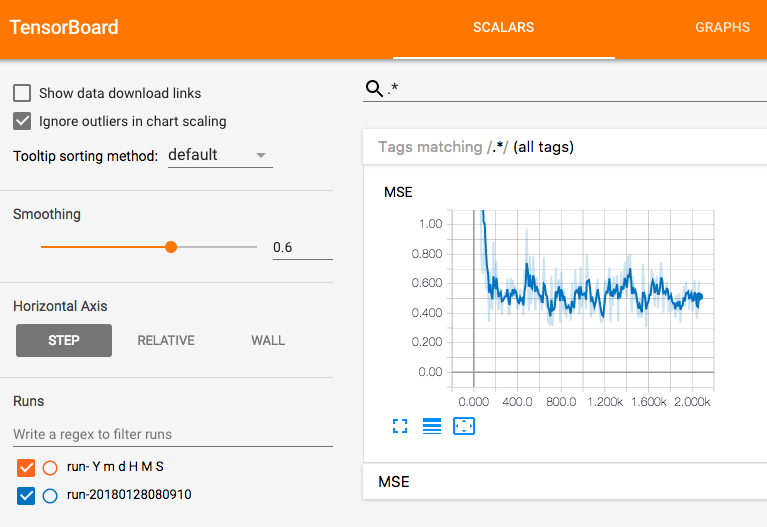
それから上のGRAPHSタブを押したら次のようなページに移ることを確認してください.
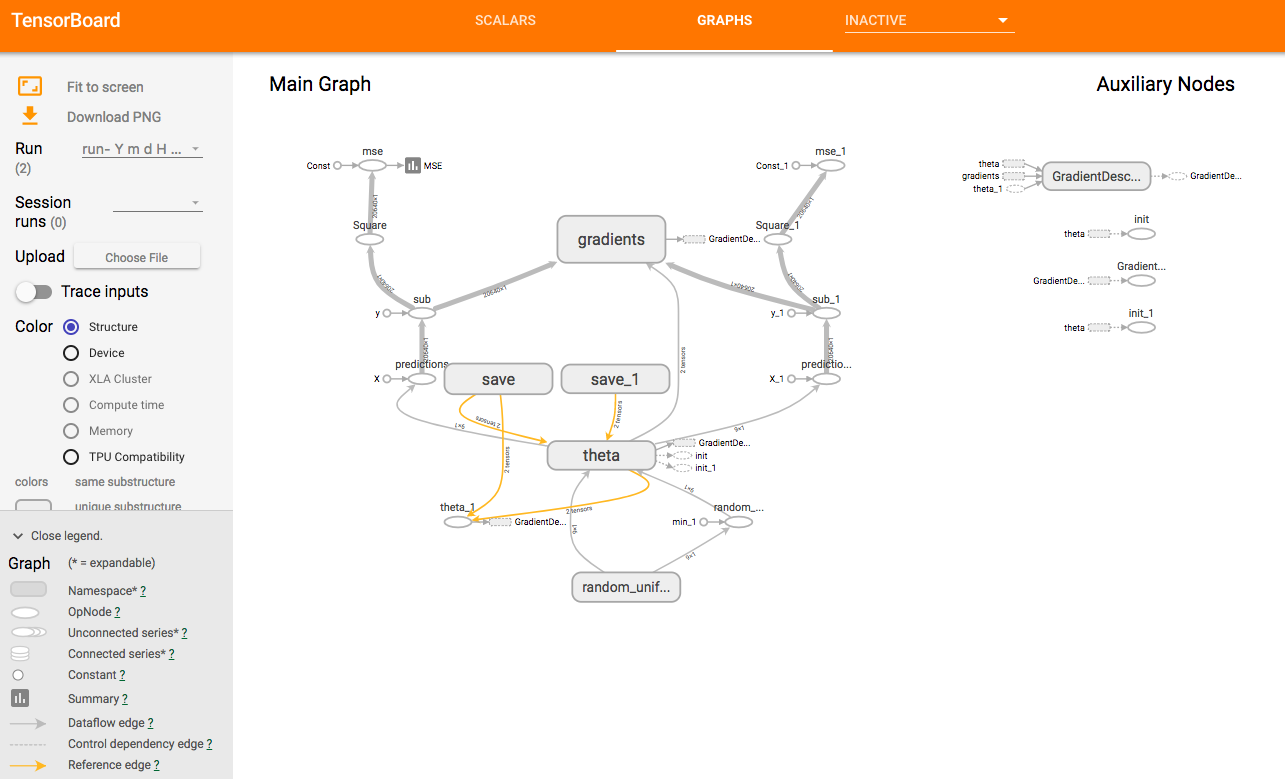
- 左の
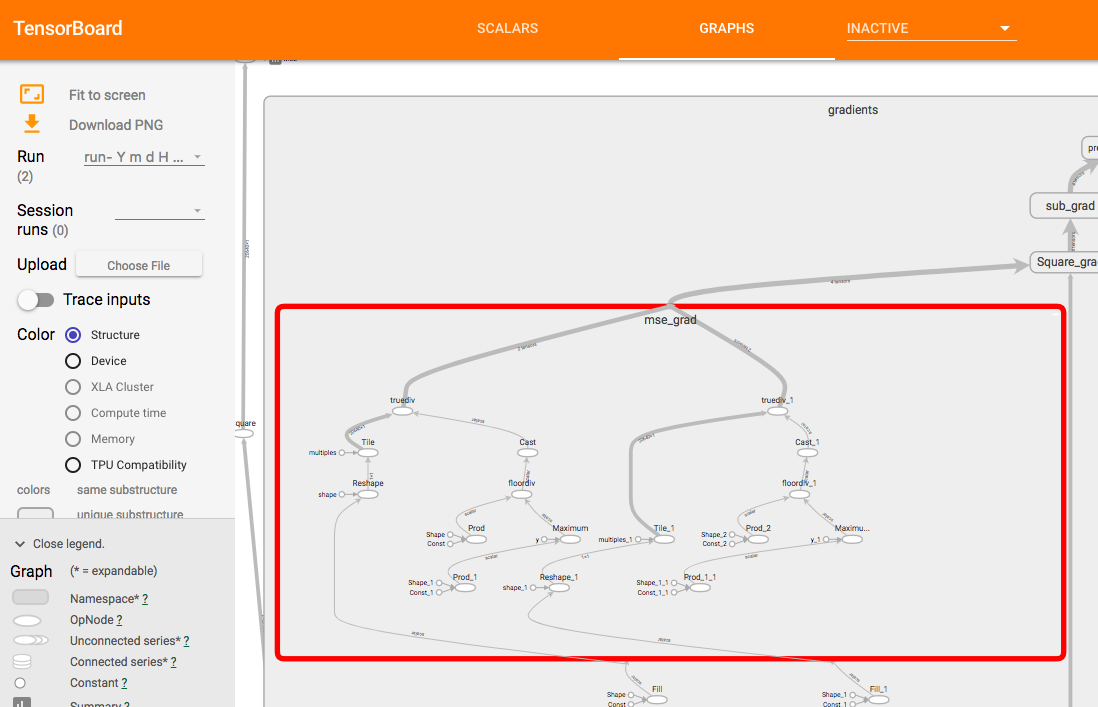
Main Graphのうち,他と結合している数が多いノードは右のAuxiliary Nodesの詳しく表示されます . - いくつかのノードはデフォルトでまとめてあります.たとえば
gradientsノード,ダブルクリックすると開くことができます.さらにその中のmse_gradも下の感じで開くことができます.