前書き
Amazon S3 Vectorsがプレビューリリースされました。
ベクターの保存とクエリをネイティブにサポートする初のクラウドオブジェクトストレージらしいです!
今まで高額なOpenSearchやAurora(高額?)は個人利用には手が出しづらかったけど、ついにナレッジベースの民主化が来たのか。早速試してみたいと思います。
料金
Amazon S3 Vectors の料金はAmazon S3 pricingページで確認できます。
ざっくりした料金例(1 か月あたり)
| 規模 | ベクター数 | ストレージ | PUT | クエリ回数 | クエリ料金 | 合計 |
|---|---|---|---|---|---|---|
| 小規模 | 1,000 万 | $3.54 | $1.97 | 100 万 | $5.87 | $11.38 |
| 大規模 | 4 億 | $141.22 | $78.46 | 1,000 万 | $997.62 | $1,217.29 |
公式ドキュメントでも、規模が大きくなるほど従来のベクターストレージと比べて最大90%のコスト削減が可能だと言っているので、OpenSearchやAuroraと比べれば確かにかなり安そうです。
マネコンから試す
実際に作ってみます。
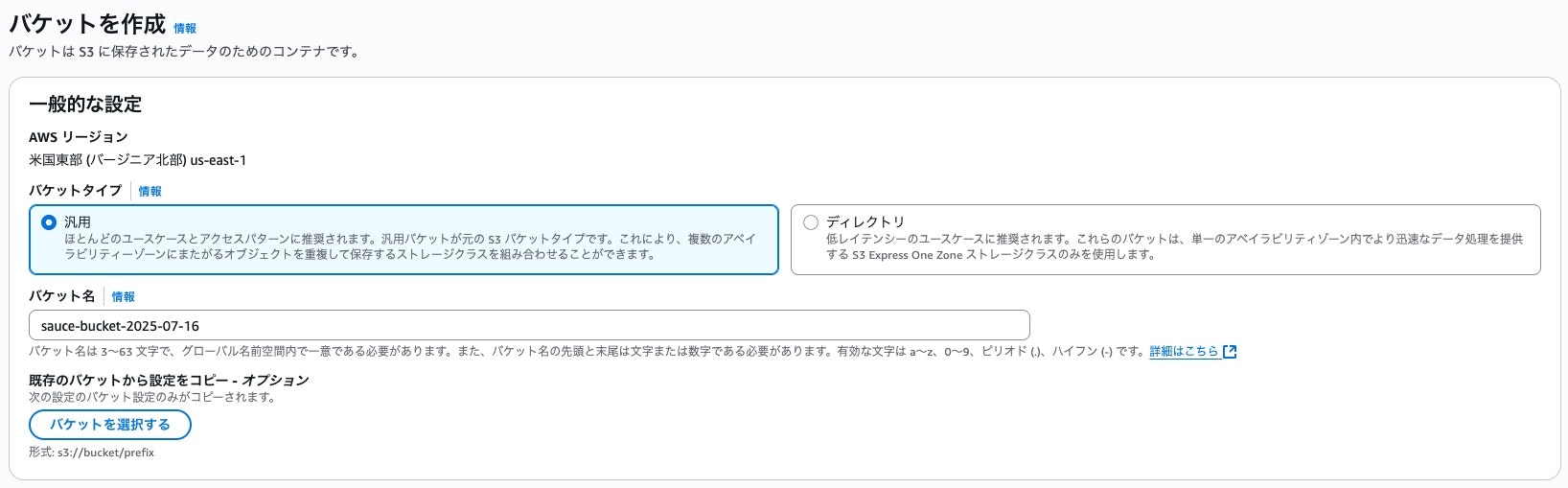
ナレッジ保存用のS3をまず作ります。名前をわかりやすくして、その他の設定はデフォルトのままで。
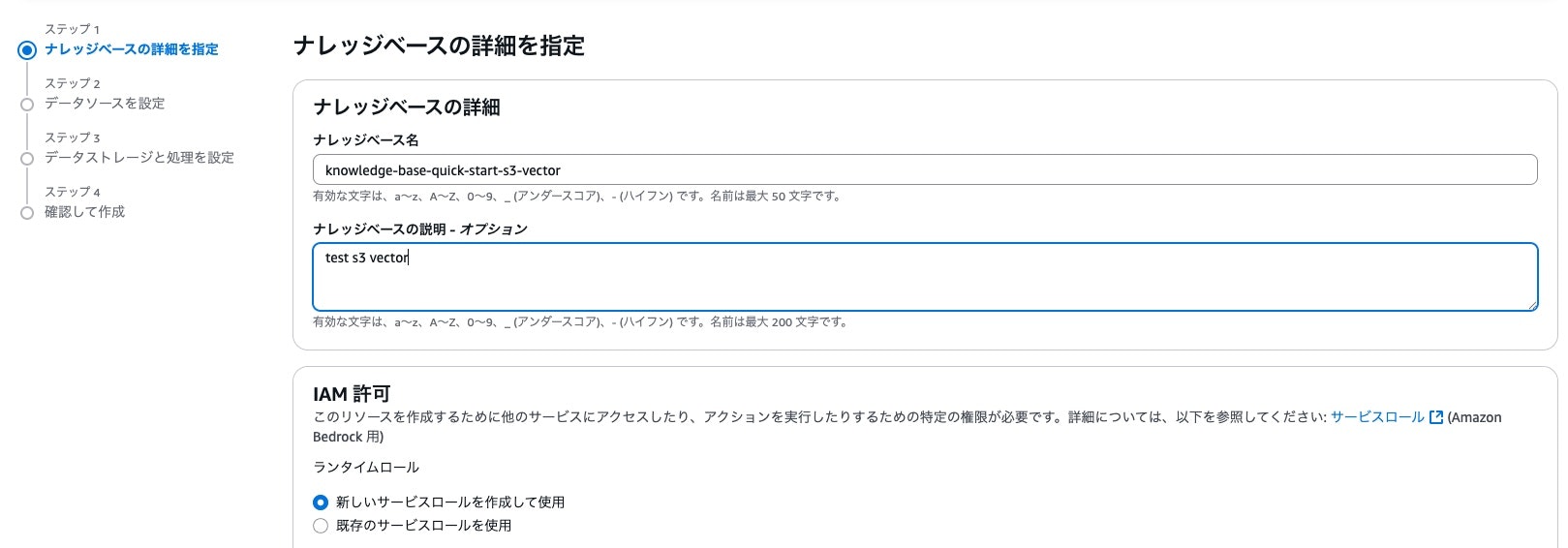
次はナレッジベースを作っていきます。名前と説明をわかりやすくして、データソースをAmazon S3を選んで、先ほどのS3を指定してあげましょう。

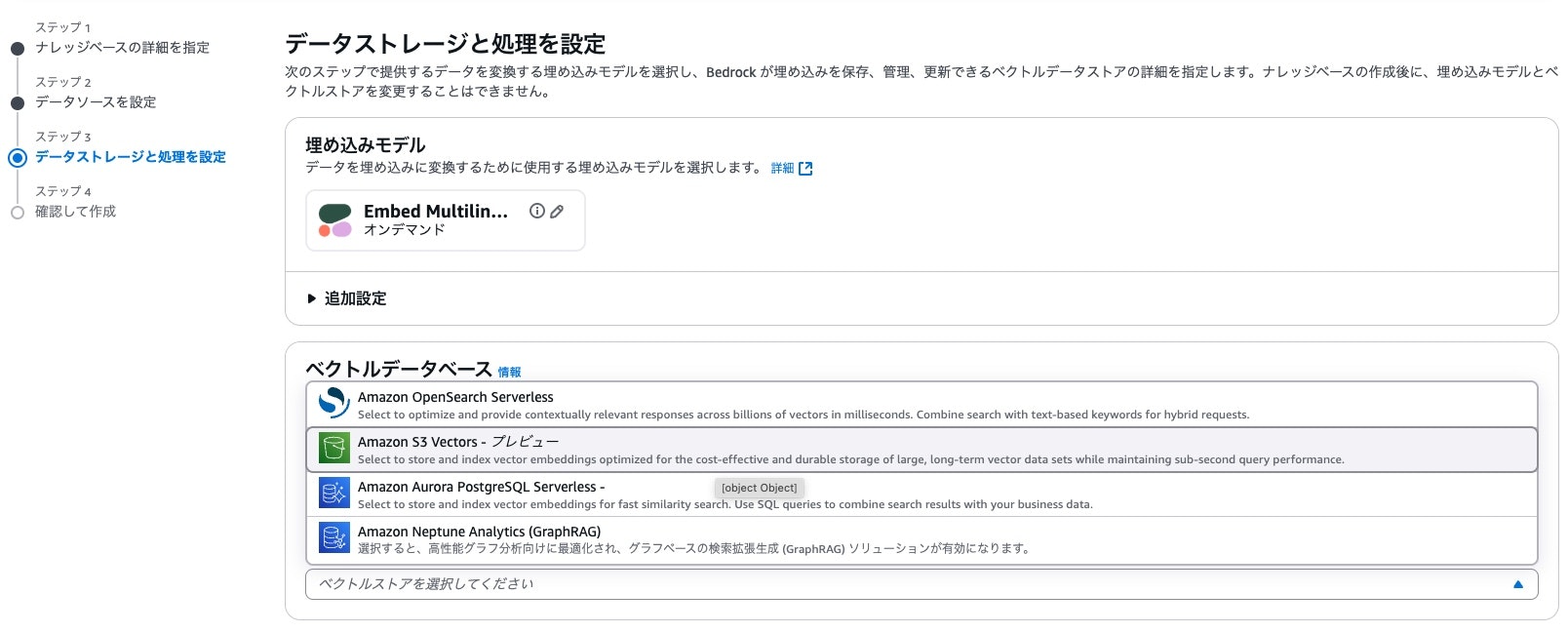
埋め込みモデルはいつものEmbed Multilingualv3を選択して、ベクトルデータベースからAmazon S3 Vectorsを選びます。
解析戦略とチャンキング戦略はデフォルトのままで、ナレッジベースを作成します。
できたナレッジベースの同期もやっておきましょう。

これでナレッジベースが作れました。S3から確認すると、ベクターバケットから新規のバケットが確認できます。

次はAIエージェントを作っていきます。
特に変わった設定はありません。わかりやすい名前にして、モデルをClaude 3.7 Sonnetにして、エージェント向けの指示もそれっぽいもので大丈夫です。設定完了したら、一旦保存しましょう。
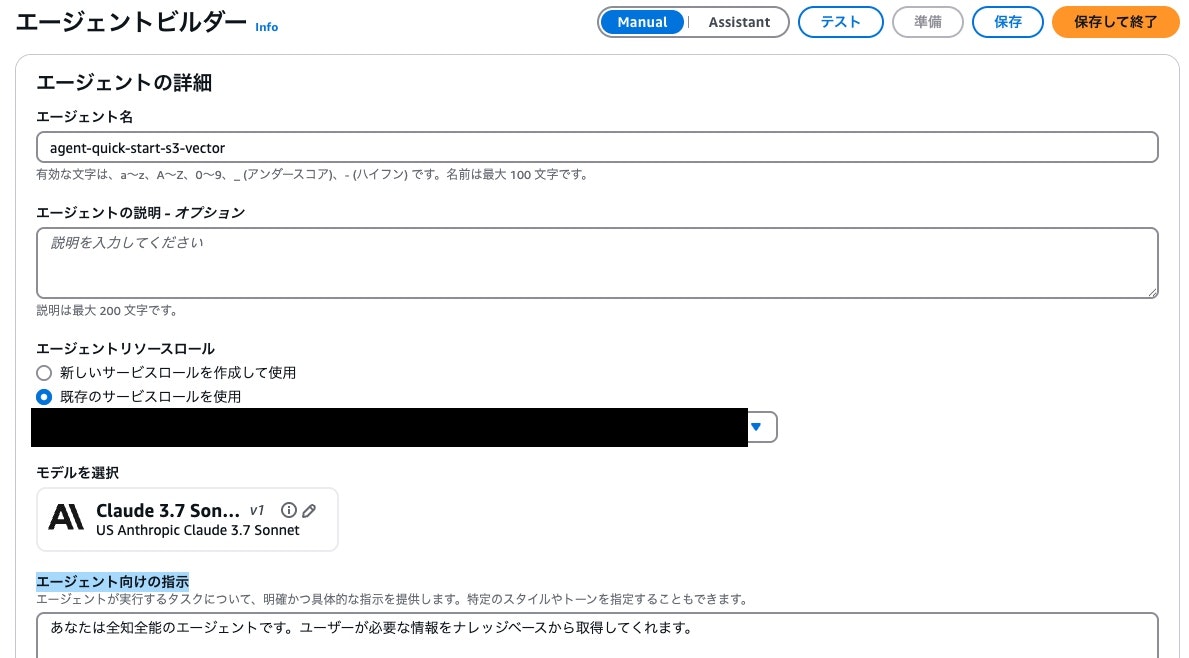
その後、先ほど作ったナレッジベースを接続してあげましょう。
追加完了したら、エージェントのプレイグラウンドでテストしてみます。
回答自体は悪くないです。
精度評価
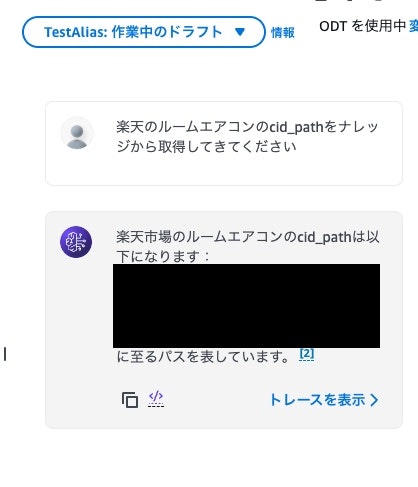
Amazon Bedrockのエージェントのプレイグラウンドで試した感じ、
精度は良さげな気がしますが、さすがにそれだけでは判断できませんので、Amazon BedrockのEvaluations(評価)機能を使ってみます。
マネコンからだと、こちらです。モデルの評価もできますが、今回はRAGを選んでCreateします。
名前は任意にしましょう。modelはClaude3.7 Sonnetにしましょう。
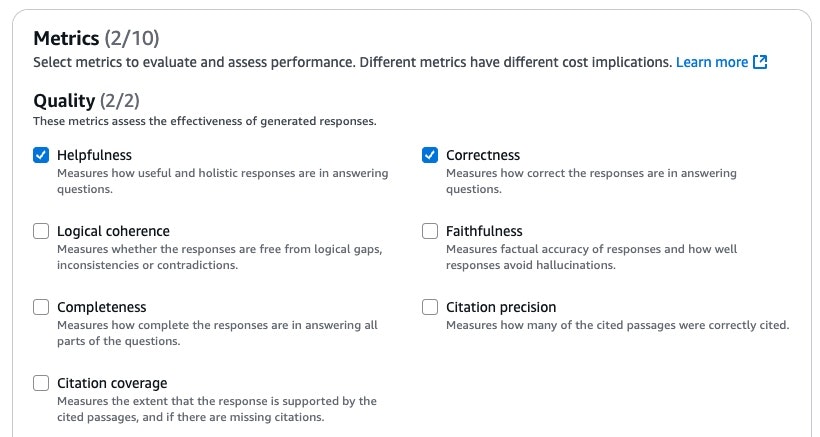
Inference sourceからBedrock Knowledge Baseを選んで、先ほどできたナレッジベースを選びましょう。Evaluation typeは検索と応答生成にして、回答生成モデルもClaude3.7 Sonnetにします。
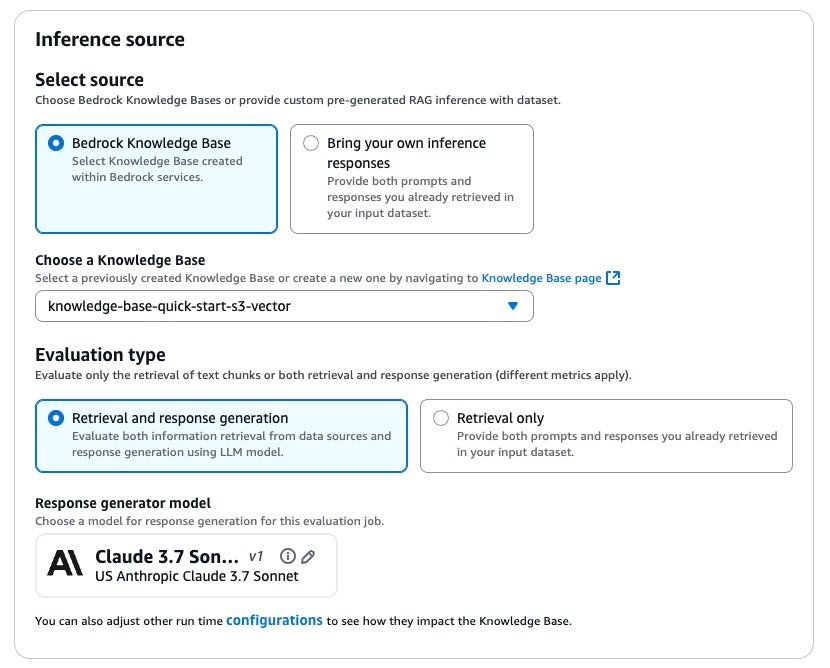
評価メトリクスはたくさんありますが、今回はあくまで精度の評価のため、Quality(品質)から、Helpfulness(有用性)とCorrectness(正確さ)を選びます。
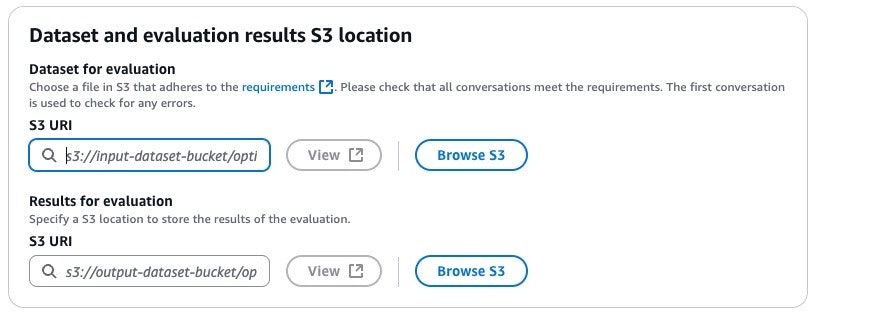
次はデータセットのS3を指定してあげる必要があります。事前に作っておく必要があります。
評価用のデータがjsonlの形式である必要があります、
決まったフォーマットで作る必要があります。
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"カグカグです、多分"}]}],"prompt":{"content":[{"text":"KAGのマスコットキャラはなんですか?"}]}}]}
今回は実際に普段評価に利用されているデータなので、お見せすることができません。
S3に評価データと評価レポート出力するためのフォルダを作っておきます。
その後、このバケットのアクセス許可のCross-Origin Resource Sharing (CORS)に下記の設定を追記します。
[
{
"AllowedHeaders": [
"*"
],
"AllowedMethods": [
"GET",
"PUT",
"POST",
"DELETE"
],
"AllowedOrigins": [
"*"
],
"ExposeHeaders": [
"Access-Control-Allow-Origin"
]
}
]
できたら、評価データとレポートの出力フォルダを指定します。
IAMは一旦新規で作って、その後Createして終わりです。
しばらくしたら元の画面に戻されて、statusがIn progressのレポートが作られました。

体感時間30分後、レポートができました。

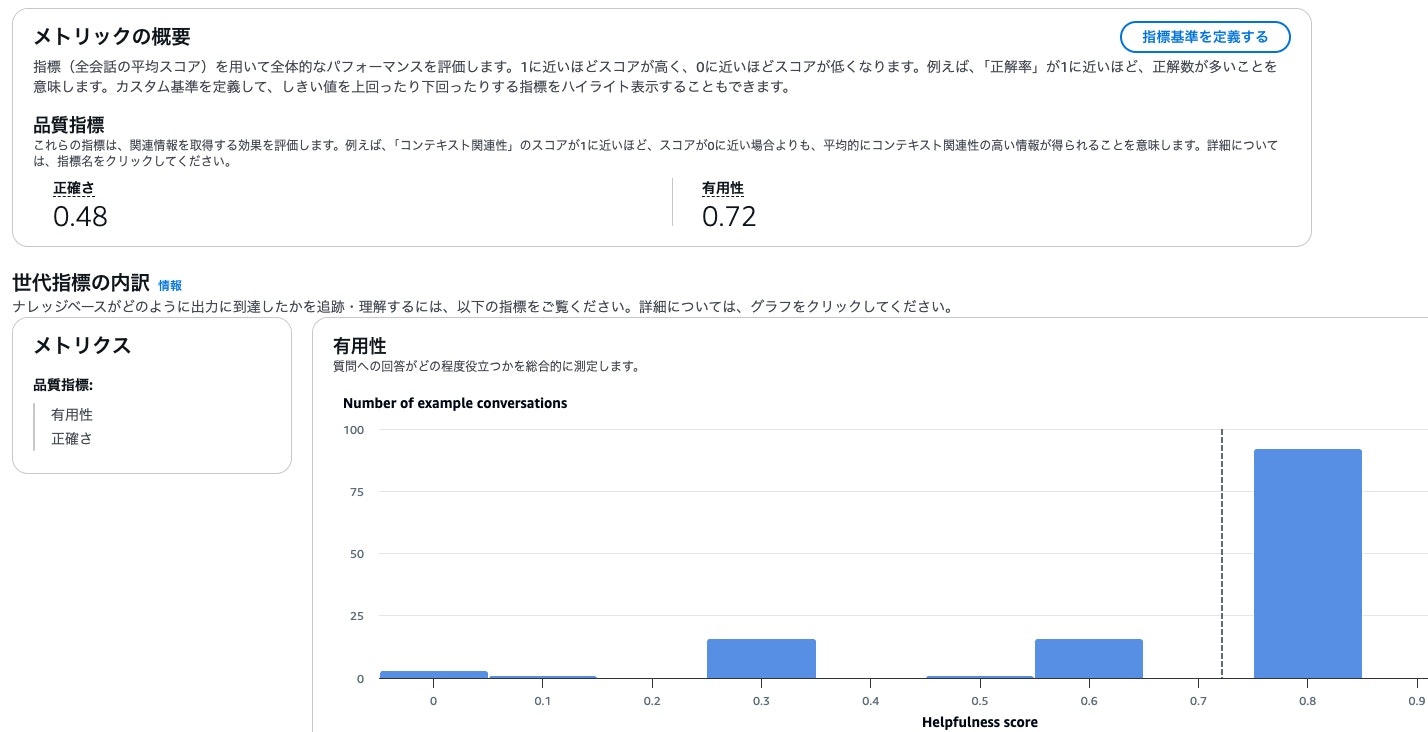
レポートの結果がこちらです。
正確さが低めなのはデータセット設定の問題です。有用性が0.72はOpenSearch利用したナレッジベースと近い数値をたたき出しているので、結構いいのではと感じています。
結論
S3 Vectors、結構いけるんじゃないかと思います。安さは正義ですね!
まだプレビューだから、すぐにCDKなどでIaCできないかもしれないですが、これからナレッジベースを作る際に、もしハイブリッド検索が必要なければ、個人的にはかなり上位候補に来ます。
正式リリースが楽しみです。