はじめに
Udemyの【世界で5万人が受講】実践 Python データサイエンスを参考にpythonで使ってデータ分析をしてみました。今回使うデータはStatsmodelsというライブラリに入っているサンプルデータで、1974年に行われた既婚女性に対しての不倫の有無を聞いた調査の論文になります。
今回の目的は
サンプルデータを使い機械学習で不倫の有無を予測するモデルを作って、どの属性が結果に影響を与えているかを予測します。
このデータを選んだ事に他意はなく、自己申告による虚偽が含まれる可能性が多いにある点を加味するとデータの信憑性に関しては考えず、あくまでサンプルデータとして扱います。
環境:
Pyhton3
scikit-learnバージョン 0.21.2(Udemyの講座とscikit-learnのバージョンが違います)
jupyter notebook+Anaconda
説明しない事:
環境構築
Python、Pandas、Numpy、matplotlibの基本文法(それ以外はコメントで説明します)
数学的な背景の説明
説明する事:
ロジスティック回帰
説明変数と目的変数
データの準備と可視化
データの前処理
scikit-learnを使ったモデル構築
まとめ
ロジスティック回帰とは
ロジスティック回帰とは目的変数(取得したいデータの事)が0~1の値に収束する回帰分析です。具体的にはシグモイド関数を使う事で値を収束させる事が出来ます。その特性を使用して確率予測に使用したり2値分類に使用したりするようです。今回は不倫の有無を1と0の2値分類にするのでロジスティック回帰を使用しました。
データの準備と可視化
# 必要なライブラリインポート
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import math
# seabornはグラフをきれいに描画できるライブラリ。人気らしい。
# set_styleでスタイル変更。今回はwhitegridを選択して背景が白のグリット有りを選択
# 面倒なら.set()だけでもおしゃれになる
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
# scikit-learnの必要なモジュールインポート
# cross_validationは古いバージョンでしか使えないので
# 2.0からはmodel_selection使う
from sklearn.linear_model import LogisticRegressin
from sklearn.model_selection import train_test_split
# モデルの評価の時に使うモジュール
from sklearn import metrics
# statsmodelsのサンプルデータを使う為のインポート
# Anaconda以外ならインストール必要かもです
import statsmodels.api as sm
準備が出来たので、データの概要を見ていきます。
# PandasのDataFrameにサンプルデータを読み込みます
df = sm.datasets.fair.load_pandas().data
# まずはデータの概要を見てみます
df.info()
# 出力
# RangeIndex: 6366 entries, 0 to 6365
# Data columns (total 9 columns):
# rate_marriage 6366 non-null float64
# age 6366 non-null float64
# yrs_married 6366 non-null float64
# children 6366 non-null float64
# religious 6366 non-null float64
# educ 6366 non-null float64
# occupation 6366 non-null float64
# occupation_husb 6366 non-null float64
# affairs 6366 non-null float64
# dtypes: float64(9)
# memory usage: 447.7 KB
# 次に最初の5行を見てみます
df.head()
| rate_ marriage |
age | yrs_married | children | religious | educ | occupation | occupation_husb | affairs |
|---|---|---|---|---|---|---|---|---|
| 3 | 32 | 9.0 | 3 | 3 | 17 | 2 | 5 | 0.1111 |
| 3 | 27 | 13.0 | 3 | 1 | 14 | 3 | 4 | 3.2308 |
| 4 | 22 | 2.5 | 0 | 1 | 16 | 3 | 5 | 1.4000 |
| 4 | 37 | 16.5 | 4 | 3 | 16 | 5 | 5 | 0.7273 |
| 5 | 27 | 9.0 | 1 | 1 | 14 | 3 | 4 | 4.6667 |
行数が6366、列数は目的変数のaffairsと説明変数の合計9で構成されていて、Nullは存在しない事がわかります。列名について補足すると
・rate_marriage:結婚生活の自己評価
・educ:学歴
・children:子供の数
・religious:信仰心
・occupation:職業
・occupation_husb:夫の職業
となりますが、詳しくはstatsmodelsのWEBサイトで確認ができます。
目的変数とは予測したい変数の事を指します。今回であれば不倫の有無の変数である「affairs」がそれになります。説明変数とは、目的変数を予測するために使用する変数の事です。今回はaffairs以外の全ての変数です。
今回は不倫の有無を調べるので変数を2値にする必要がありますが、目的変数のaffairsが連続した実数値になっています。これは質問内容がaffairsをした場合の時間になっている為です。そこで0以外の数字を1に変換する関数を通して、その結果を格納するために新しくHad_Affairの列を追加します。
# affairsが0以外ならHad_affairs。
def affair_check(x):
if x != 0:
return 1
else:
return 0
# applyの引数は指定列に関数を適用する。
df['Had_Affair'] = df['affairs'].apply(affair_check)
# 最初の5行を出力
df.head()
| rate_marriage | age | yrs_married | children | religious | educ | occupation | occupation_ husb |
affairs | Had_Affair |
|---|---|---|---|---|---|---|---|---|---|
| 3 | 32 | 9.0 | 3 | 3 | 17 | 2 | 5 | 0.1111 | 1 |
| 3 | 27 | 13.0 | 3 | 1 | 14 | 3 | 4 | 3.2308 | 1 |
| 4 | 22 | 2.5 | 0 | 1 | 16 | 3 | 5 | 1.4000 | 1 |
| 4 | 37 | 16.5 | 4 | 3 | 16 | 5 | 5 | 0.7273 | 1 |
| 5 | 27 | 9.0 | 1 | 1 | 14 | 3 | 4 | 4.6667 | 1 |
追加できました。それではデータの可視化をしてどの説明変数が影響を与えているか、簡単にあたりをつけて行きましょう。Had_Affairでグループ分けして各列の平均を求めます。
df.groupby('Had_Affair').mean()
| Had_Affair | rate_marriage | age | yrs_married | children | religious | educ | occupation | occupation_husb | affairs |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 4.330 | 28.39 | 7.989 | 1.239 | 2.505 | 14.32 | 3.405 | 3.834 | 0.000 |
| 1 | 3.647 | 30.54 | 11.152 | 1.729 | 2.262 | 13.97 | 3.464 | 3.885 | 2.187 |
2行目である「Had_Affair」が1の行は結婚生活が長く、結婚生活の自己評価が低い事がわかります。
では結婚生活の長さとの関係性を、seaborn(おしゃれなmatplotlibみたいなものです)を使ったヒストグラムでデータを可視化します。
# seabornのcountplotメソッドを使ってデータを集計して可視化、引数はX軸、対象のDF、列名をHad_Affairで2値分類、色指定
sns.countplot('yrs_married',data=df.sort_values('yrs_married'),hue='Had_Affair',palette='coolwarm')
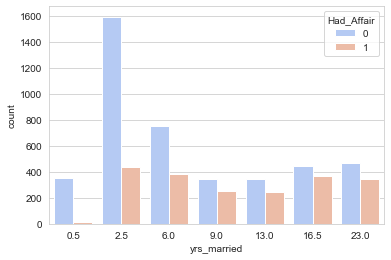
結婚生活と不倫の有無は関係がありそうです。次に結婚生活の長さと不倫をする割合を可視化してみます。
# barplotのy軸は平均を出力する。Had_Affairが1と0の値の為、平均を求めて1である割合を求めている。
sns.barplot(data=df, x='yrs_married', y='Had_Affair')
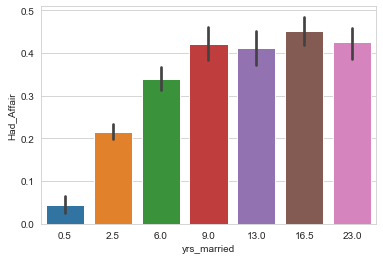
結婚生活が9年を超えると不倫をする割合が4割を超えてきます。他のデータも事前に見ておく事である程度の予測ができそうですが、この辺で次に進みます。
データの前処理
可視化が終わったのでデータの前処理を行います。具体的には機械学習のモデルにFitさせる為に説明変数と目的変数を分けたり、データの値を揃えたり、欠損値に対処したりします。
それではデータの値を揃えていきます。
職業を示す「occupation」と「occupation_husb」のデータ列は、カテゴリ分けをする為に便宜上数字を割り振っているだけなので、数字の大小に意味がありません。職業に貴賎なしです。
そこで、職業のカテゴリカルデータを職業別に新しい列を作成します。レコードが該当するのであれば1そうでなければ0の2値に分ける事でデータを揃えています。面倒な作業ですがPandasのダミー変数生成関数を使えば一瞬です。
そうすると、職業列が不要になるので削除、目的変数をYに代入し説明変数をXに代入、目的変数の元データであるaffairsも削除しておきます。
出力する場合は一つの表ですが、列が多くなりすぎてQiitaだと見辛いので2つに分けています。
# pandasのダミー変数を生成する関数を使う。scikit-learnにもあるらしい。
occ_dummies = pd.get_dummies(df['occupation'])
hus_occ_dummies = pd.get_dummies(df['occupation_husb'])
# カテゴリ名を命名。本当は元データの列名使うほうが見やすいけど、面倒でしたので諦めました。
occ_dummies.columns = ['occ1','occ2','occ3','occ4','occ5','occ6']
hus_occ_dummies.columns = ['hocc1','hocc2','hocc3','hocc4','hocc5','hocc6']
# 不要になったoccupationの列と、目的変数「Had_Affair」を削除します。ついでにaffairsも。
# axisは0で行、1で列を指定する。
# dropメソッドは引数にinplace=Trueを入れなければ元のDataFrameからは削除されない。
X = df.drop(['occupation','occupation_husb','Had_Affair','affairs'],axis=1)
# ダミー変数をまとめて、説明変数XのDataFrameに結合します。
dummies = pd.concat([occ_dummies,hus_occ_dummies],axis=1)
X = pd.concat([X,dummies],axis=1)
# Yに目的変数を代入します
Y = df.Had_Affair
# 出力
X.head()
| rate_marriage | age | yrs_married | children | religious | educ |
|---|---|---|---|---|---|
| 3 | 32 | 9.0 | 3 | 3 | 17 |
| 3 | 27 | 13.0 | 3 | 1 | 14 |
| 4 | 22 | 2.5 | 0 | 1 | 16 |
| 4 | 37 | 16.5 | 4 | 3 | 16 |
| 5 | 27 | 9.0 | 1 | 1 | 14 |
| occ1 | occ2 | occ3 | occ4 | occ5 | occ6 | hocc1 | hocc2 | hocc3 | hocc4 | hocc5 | hocc6 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
独立する変数に強い相関関係があったりすると、解析が不可能になる場合があるらしいです。それを多重共線性と呼ぶのですが、詳しい内容はググっても理解できなかったので、来月ぐらいに統計学勉強するついでに調べます。
とりあえず今回のデータで相関性が高いのはダミー変数を使った職業列なので一つずつ削除する事で対処できるようです。
# とりあえずこれで対処できるぽい
X = X.drop('occ1',axis=1)
X = X.drop('hocc1',axis=1)
目的変数であるYがSeriesになっているので、モデルにfitさせる為一次配列であるarrayに変更します。これでデータの前処理は終わりです。
type(Y)
Y = np.ravel(Y)
scikit-learnを使ったモデル構築
scikit-learnを使ってロジスティック回帰モデルを構築します。
# LogisticRegressionクラスのインスタンスを作ります。
log_model = LogisticRegression()
# データを使って、モデルを作ります。
log_model.fit(X,Y)
# モデルの精度を確認してみましょう。
log_model.score(X,Y)
# 出力
# 0.7260446120012567
このモデルの精度は約73%です。モデルを鍛えたり、パラメーターはデフォルトなのでこれくらいが妥当なのでしょうか。
それでは回帰係数を表示して「予測にはどの変数が寄与しているか?」を探っていきましょう。
# 変数名とその係数を格納するDataFrameを作ります。
# coef_は回帰係数を表示します。
coeff_df = DataFrame([X.columns, log_model.coef_[0]]).T
coeff_df
| 0 | 1 |
|---|---|
| rate_marriage | -0.72992 |
| age | -0.05343 |
| yrs_married | 0.10210 |
| children | 0.01495 |
| religious | -0.37498 |
| educ | 0.02590 |
| occ2 | 0.27846 |
| occ3 | 0.58384 |
| occ4 | 0.35833 |
| occ5 | 0.99972 |
| occ6 | 0.31673 |
| hocc2 | 0.48310 |
| hocc3 | 0.65189 |
| hocc4 | 0.42345 |
| hocc5 | 0.44224 |
| hocc6 | 0.39460 |
説明変数に対してモデルを作ったときの回帰係数が見れました。
回帰係数が正の値であれば、その変数の値が高い程不倫の可能性は増します。負であればその逆です。
この表からは結婚生活の自己評価と、宗教観が高ければ不倫の可能性は下がり、結婚した後の年数が上がれば不倫の可能性は上がるようです。職業別でも表示しているのですが、多重共線性の対策の時に1の値を削除しているので、参考程度という事で見ておくほうが良さそうです(因みに、かなり高い値であるocc5の職業はmanagerialなので直感的に納得しやすい値かもしれません)
まとめ
より精度を上げたければ、正規化やパラメーターの試行錯誤を行えば良いと思います。
しかし、データの信憑性を考えるとモデルに使用した回帰係数を見る事で、属性による結果へ関係性を分析する方がより学びになると思いました。
余談
DataFrameで出力した表をQiitaに投稿するのが凄く大変で5時間ぐらいかかりました。
最初はmatplotlibのtableに変換して画像として出力しようとしましたが、インデックスの文字が小さくなってしまい修正方法がわからず断念。
次にDataFrameをMarkdownに変換するpytablewriterというライブラリを使おうとしたのですが、Anacondaで配布されているライブラリではないので、仕方なくPIPでインストールしたのが終わりの始まり。
「cannot import name」のエラーがインポートしたライブラリ内で発生しているので調べると。
Anaconda環境にPIPインストールをするとライブラリが衝突して、面倒な事になる可能性がある。
あら!びっくりだわ!
よく考えれば、依存関係にあるライブラリのバージョンはAnacondaもPIPも違う可能性があるので、問題は起きそうですね。今まで気にせずやっていたのでConda Listで確認すると無数のPypiが存在しているので見なかった事にしています。
他の言語、例えばNPMとyarnとかは問題は起きないのか気になって、友達のエンジニアに聞いたら「ライブラリの保存先は一緒ですよ!」とありがたい回答を頂いたので真相は闇の中。
という事なので対策は別のAnaconda環境を作るか、PIPインストールしかしない別の環境を作るかなのですが、後者を選択し、一からPIPでライブラリをインストールするのですが、StatsmodelsをPIPでインストールする場合もエラー起きて(Anacondaだと楽)、なんやかんやしてたら無事解決。
サクッとMarkdownで表を作成している投稿者の方尊敬します。何か方法あったら教えて欲しいです。