0.はじめに
第4回の記事でデータのまとめ方には縦長と横長があることを述べました。この記事ではR上で縦長と横長を相互に変換する方法を紹介します。
ぱっと見て理解しやすいのは横長のデータなので、取得した実験データをエクセル等で打ち込む際も横長でまとめていることが多いかもしれません。その一方、Rで扱いやすいのは縦長のデータなので変換する必要があります。この変換を手作業でするのは大変なので、Rでやっていきましょう。(ご指摘いただいた@StrawBerryMoonさん、ありがとうございました。)
ちなみに、私は実験データはエクセルに入力する段階で縦長にしています。
0-1. この記事の到達目標
- 横長データを縦長データに変換できる
- その逆の変換もできる
0-2. 初めて登場する関数
data.frame(ベクトル)- ベクトルからデータフレームを作ります。
pivot_longer()- 横長データを縦長データに変換します。
as.data.frame()- 引数のデータ型をデータフレームにします。
pivot_wider()- 縦長データを横長データに変換します。
1. 練習データの準備
今回の練習データとして第4回で扱ったトウモロコシの横長のデータを使ってみましょう。
Excelで以下のようにデータを打ち込みます。
トウモロコシ_横長.csvという名前で保存し、read.table()で変数df.wideに読み込ませています。

> df.wide<-read.table("トウモロコシ_横長.csv",header = TRUE,sep=",")
> df.wide
ID Fertilizer Control
1 1 180 165
2 2 178 171
3 3 192 173
4 4 182 168
5 5 185 169
もし、Excelからのデータの打ち込みはめんどくさいけど、縦長と横長の変換を手を動かしてやってみたい方はdata.frame()関数を使って、R上でデータフレームを作成してもよいと思います。
ID列、Fertilizer列、Control列をそれぞれベクトルとして作成し、data.frame()で列同士を横にくっつけてデータフレームにしています。
> ID<-c(1:5)
> Fertilizer<-c(180,178,192,182,185)
> Control<-c(165,171,173,168,169)
> df.wide<-data.frame(ID,Fertilizer,Control)
> df.wide
ID Fertilizer Control
1 1 180 165
2 2 178 171
3 3 192 173
4 4 182 168
5 5 185 169
2. tidyverseパッケージのインストールと読み込み
縦長データと横長データの変換を行うために、tidyverseパッケージ内の関数を用います。まずはこのパッケージをインストールしましょう。
インストールが終わったらlibrary()で読み込んでおきます。
> install.packages("tidyverse")
> library("tidyverse")
3. pivot_longer()で横長データを縦長データに
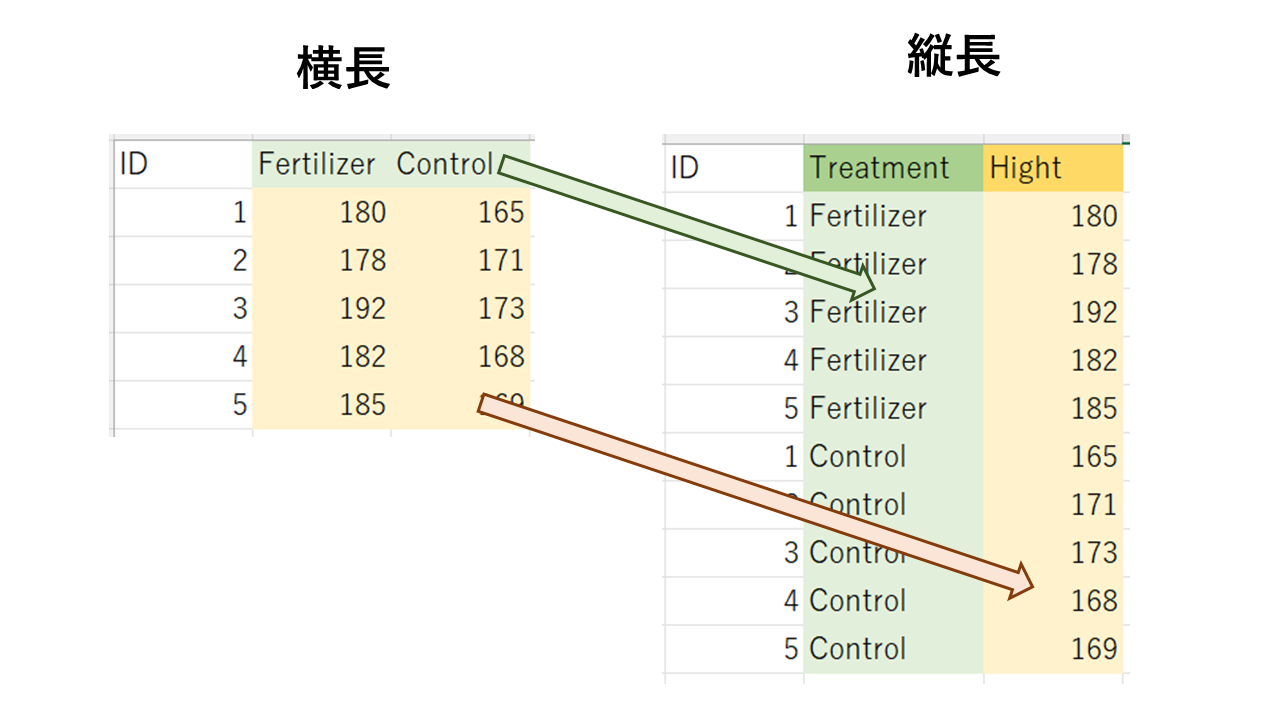
横長データを縦長データに変換する、ことを具体的な例を用いて言い換えると、
横長データにおけるFertilizerとControlという要因を新たにTreatmentという列に格納し、数値データは新たにHightという列に格納する、ということです。
このことを念頭においてコードについて説明します。
横長データ(wide)を縦長データ(long)にするためにはpivot_longer()関数を使います。この関数では指定すべき引数が4つあるので少々ややこしいです。
第1引数に横長データなデータフレーム(元データ)を指定します。
第2引数に元データで変換の対象となる列を指定します。先の例では緑の網掛けと黄色の網掛けの両方を含んでいる列を指定します。
第3引数に変換先データでの要因列名を指定します。緑の網掛けが格納される列の列名、つまりTreatmentが該当します。
第4引数に変換先データでの数値列名を指定します。黄色の網掛けが格納される列の列名、つまりHightが該当します。
以上を踏まえたコードは以下の感じになります。
実行してみましょう
> df.long<-pivot_longer(df.wide,
+ cols = c(Fertilizer,Control),
+ names_to = "Treatment",
+ values_to = "Hight")
> df.long
# A tibble: 10 x 3
ID Treatment Hight
<int> <chr> <dbl>
1 1 Fertilizer 180
2 1 Control 165
3 2 Fertilizer 178
4 2 Control 171
5 3 Fertilizer 192
6 3 Control 173
7 4 Fertilizer 182
8 4 Control 168
9 5 Fertilizer 185
10 5 Control 169
でてきた縦長データについて詳しく見てみましょう。
まず、今まで扱ってきたデータフレームとなんだか様子が異なるのに気づきますでしょうか?
class()でデータ型を調べますと、tbl_dfと表示されます。これはデータフレームをより使いやすくしたもので、基本的な使い方はデータフレームであるためあまり気にしなくて大丈夫です。
どうしても普通のデータフレーム型のほうがいいという人はas.data.frame()関数でデータ型を変換してもよいでしょう。
> #データ型を確認
> class(df.long)
[1] "tbl_df" "tbl" "data.frame"
> #データフレームに変換する
> df.long<-as.data.frame(df.long)
> #データ型を確認
> class(df.long)
[1] "data.frame"
4. pivot_wider()で縦長データを横長データに
次は、先ほどの逆の操作、縦長データを横長データに変換しましょう。
やっていることとしては、まさに先ほどの操作の逆、です。
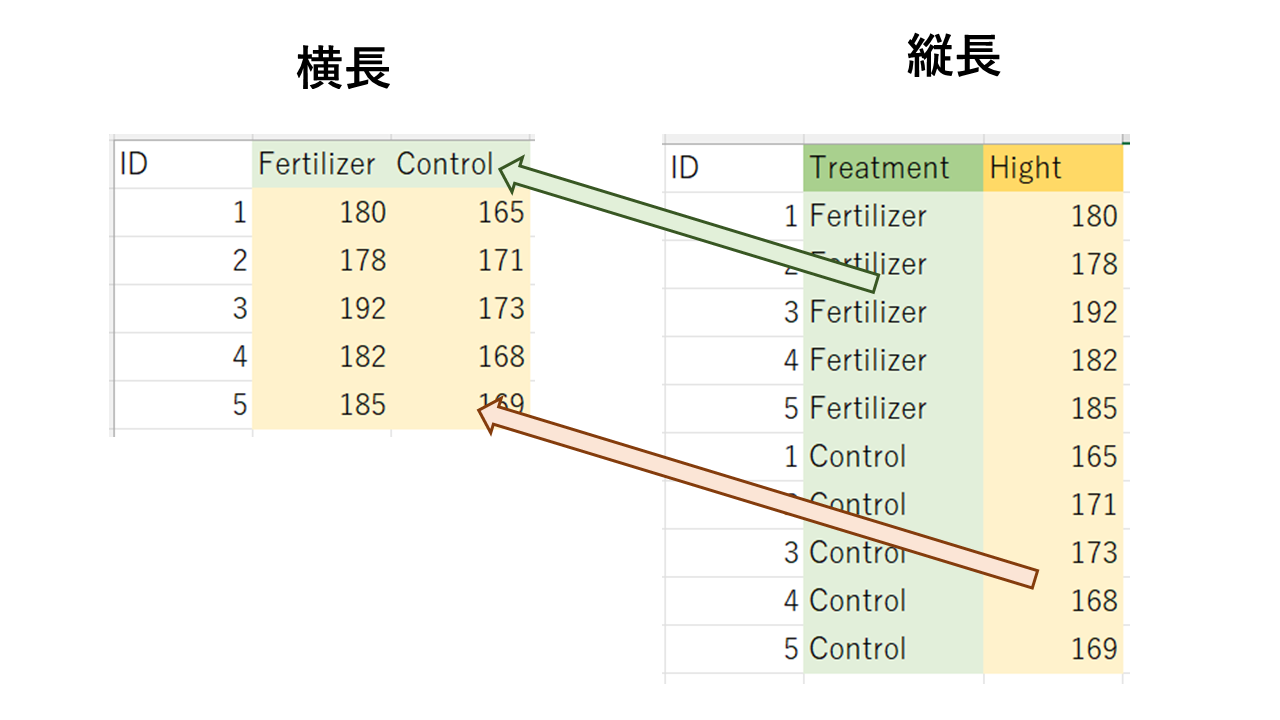
くどいかもしれませんが念のため具体的な例を用いて言い換えると、
縦長データにおけるTreatment列の要素を
FertilizerとControlという要因として列名に格納し、Hight列に入っている数値データを要因ごとにそれぞれ格納する、ということです。
縦長データ(long)を横長データ(wide)にするためにはpivot_wider()関数を使います。この関数において引数は3つあります。
第1引数に縦長データなデータフレーム(元データ)を指定します。
第2引数に縦長データの要因列名を指定します。Treatmentが該当します。
第3引数に縦長データの数値列名を指定します。Hightが該当します。
以上を踏まえたコードは以下の感じになります。
実行してみましょう
> df.wide2<-pivot_wider(df.long,
+ names_from = "Treatment",
+ values_from = "hight")
> df.wide2
# A tibble: 5 x 3
ID Fertilizer Control
<int> <dbl> <dbl>
1 1 180 165
2 2 178 171
3 3 192 173
4 4 182 168
5 5 185 169
いかがでしょうか、変換うまくいったでしょうか。
5. 次回