0. はじめに
実験で収集したデータはエクセルに入力するという方が多いと思います。
したがって、エクセルという外部のデータをRに読み込ませるという作業は必須です。
読み込ませたデータはデータフレームのデータ型を持っているので、
前回紹介した、データフレームの扱いが重要になってきますので、必要に応じてご確認ください。
【前回の記事はこちら】
0-1. この記事の到達目標
- ワーキングディレクトリについて理解できる。
- ExcelからRにデータを読み込める
- 縦長なデータと横長なデータの違いを理解できる。
0-2. はじめて登場する関数・記号
getwd()- 現在のワーキングディレクトリを確認します。
setwd()- 引数のパスにワーキングディレクトリを設定します。
read.table()- CSV形式またはテキスト形式のファイルを読み込みます。
\t- タブを表します。
NA- 欠損値を表します。
1. ワーキングディレクトリ
外部からのデータの読み込みや、ファイルの出力などにおいて、ワーキングディレクトリは基本となる概念です。
ワーキングディレクトリをうまく使い分けることで、統計に使うデータセットを整理することができます。
1-1. ワーキングディレクトリとは
エクセルからデータを読み込ませるために、ワーキングディレクトリ(作業フォルダ)の概念を押さえておきましょう。
日常生活でもパソコン上でも、書類やデータがごちゃごちゃだと扱いにくいので、フォルダに分けて整理します。
「ある書類」の場所を見つけるためには「その書類が入ってるフォルダ」の中を探しますよね、これがワーキングディレクトリです。
Rはデータを読み込むために、ワーキングディレクトリに入っているデータファイルを検索します。
パソコンには入っていても、指定したワーキングディレクトリにデータファイルが入っていないとデータの読み込みができません。
1-2. 確認と変更
現在のワーキングディレクトリを確認するためにはgetwd()を使います。
この関数の今までと異なるポイントは、引数は空で何も入れない点です。
出力結果が現在のワーキングディレクトリのパス(パソコン上の住所)を示しています。
結果は人によって異なります。
> getwd()
[1] "C:/Users/Surku/Desktop"
現在のワーキングディレクトリを別のフォルダに変更する方法としてここでは2つのやり方を説明します。
1つめは、コードは使わず手動で変更する方法です。
ウィンドウ上のSesssion>Set Working Directory>Choose Directoryを選択すると画面が現れるのであとはフォルダを指定するだけです。
操作が視覚的にわかりやすい一方で、慣れてくるとカーソルの操作がめんどくさく感じるようになるかもしれません。
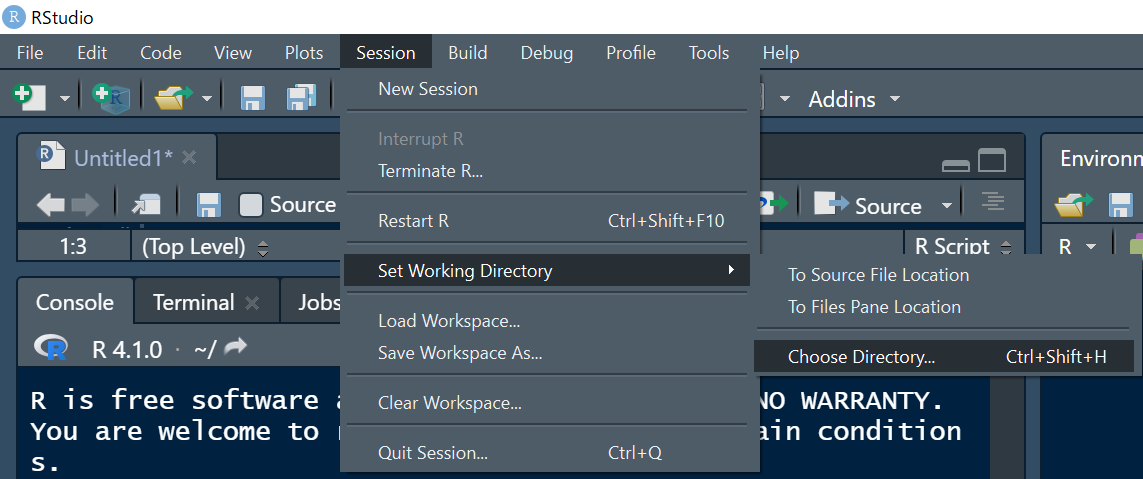
2つめは、setwd()を使う方法です。引数に変更したいフォルダのパスを入れます。
したがって、変更したいフォルダのパスを調べる必要があり、これについてはこちらの記事様がお詳しいので、この手順でパスを取得してみてください。
パスを取得できたら任意の場所に張り付けて、バックスラッシュ\をスラッシュ/に書き換えます。バックスラッシュのままだとエラーになってしまいます。
書き換えたものを、ダブルクォーテーションでくくり、setwd()の引数に指定して実行するとワーキングディレクトリが変更されます。
getwd()でちゃんと変更できたことが確認できます。
この方法は最初がめんどくさいですが、コードを保存できるのが良い点です。
# デスクトップ上の「R」フォルダーにワーキングディレクトリを指定
# バックスラッシュのままだとエラー
> setwd("C:\Users\Surku\Desktop\R")
Error: '\U' used without hex digits in character string starting ""C:\U"
# スラッシュに書き換え
> setwd("C:/Users/takum/Desktop/R")
> getwd()
[1] "C:/Users/takum/Desktop/R"
2.エクセルの準備
エクセルのデータをRに読み込ませるためにはいくつかの手順が必要です。
まずはデータのまとめかたを、一般的な”横長”から”縦長”に変換します。
その後、ファイル形式をExcelブック.xlsxからCSV(コンマ区切り).csvやテキスト(タブ区切り).txtなどに変換し、ワーキングディレクトリに保存します。
順を追ってみていきましょう。
2-1. ”横長”なデータと”縦長”なデータ
データのまとめかたを理解するために、練習データを用意してみました。
トウモロコシを肥料ありと肥料なしで栽培し、背丈を調査した架空の実験です。
処理は肥料あり、なしの1要因2水準、で各区5個体供試した実験系としています。
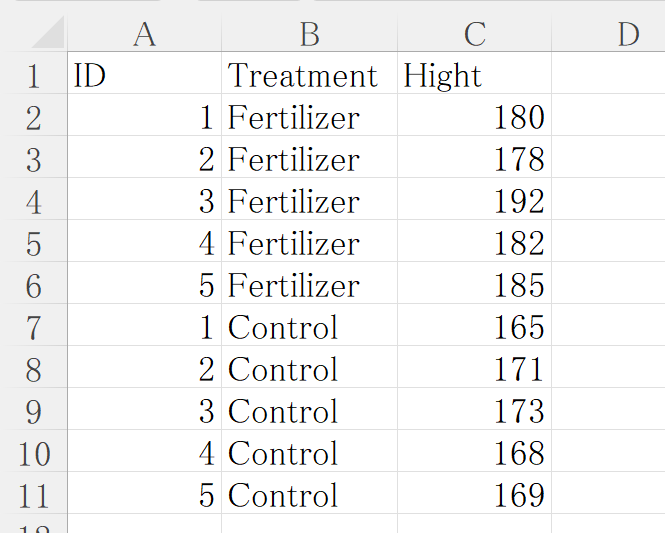
肥料あり(Fertilizer)のデータはB列に、肥料なし(Control)のデータはC列に該当します。
このように要因ごとに横に並べていくデータのまとめかたを横長と呼んでいます。
【横長】

一方、縦長のデータでは要因を縦方向に並べます。
先ほどの横長データとは異なり、以下の縦長データではTreatment列に要因の情報が、Hight列に数値データが格納されています。
【縦長】
Rで扱うデータの形は基本的に縦長のデータです。
なので、私は実験ノート等に記した実験データをExcelに打ち込む際に縦長にまとめています。
もし、すでにExcel上で横長にまとめられたデータをRで統計処理したい場合は、横長のままRに読み込み、R上で縦長に変換しましょう。
以下の記事をよければご覧ください
2-2. CSV形式またはテキスト形式で保存
Excelで作ったファイルは通常、Excelブック.xlsxのファイル形式で保存されます。
しかしこの.xlsxをそのままRに読み込ませるのは厄介なので、CSV.csvやテキスト.txtなどに変換してから読み込ませると簡単です。
トウモロコシのデータがExcel上ですでに縦長になっているとして例を進めますが、横長の場合も同様に実行できます。
Excelの「名前を付けて保存」メニューからCSV(コンマ区切り).csv、あるいはテキスト(タブ区切り).txtで保存します。それぞれ、CSV UTF-8やunicode テキストなどよく似た形式もありますが、間違えないようにしてください。
また、これらの方式で保存すると、Excelブック上のある一つのシートしか保存されず、それ以外のシートは消えてしまうので、困る場合は確実に再度Excelブックで保存するようにしてください。
保存場所は、ワーキングディレクトリにしてください。
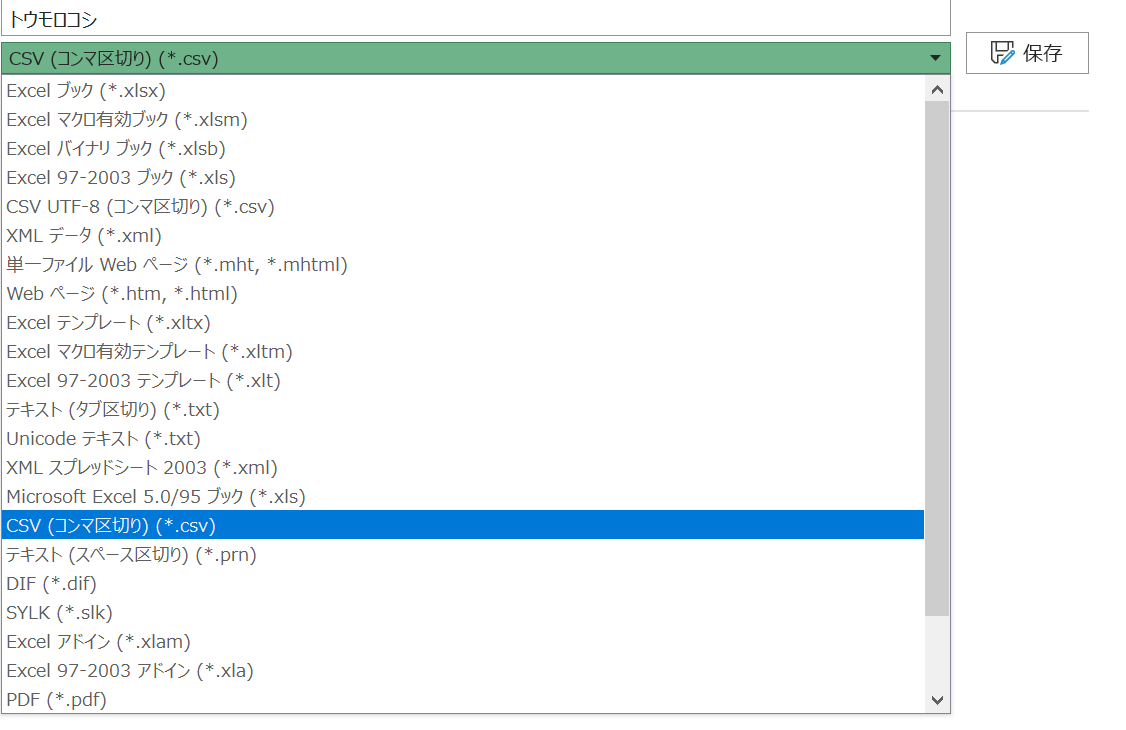
これでExcel側の準備は終了です。
3. Rへの読み込み
では実際に、Rへ読み込みを行っていきましょう。
CSV形式で保存したときと、テキスト形式で保存したときの2パターン紹介します。
3-1. CSV形式ファイルの読み込み
CSV、テキスト形式にかかわらず、読み込みにはread.table()関数を用います。
今まで登場してきた関数に比べ、引数が多いことに注意してください。
第1引数に、ファイルの名前を指定し、" "でくくります。このとき、.csvという拡張子も含めてください。
第2引数header =には基本的にTRUEを指定します。これは、列名があるかどうかを指定するもので、今回のように「ID」「Treatment」など列名があるのでTRUEを指定します。
第3引数header =には","を指定します。これはデータが何で区切られているかを指定するもので、コンマ区切りと言われているようにコンマで区切られているので、コンマを指定しています。
> read.table("トウモロコシ.csv",header = TRUE,sep=",")
ID Treatment Hight
1 1 Fertilizer 180
2 2 Fertilizer 178
3 3 Fertilizer 192
4 4 Fertilizer 182
5 5 Fertilizer 185
6 1 Control 165
7 2 Control 171
8 3 Control 173
9 4 Control 168
10 5 Control 169
読み込みの際に、変数に代入しておきます。
読み込まれたデータセットのデータ型はデータフレームなので、私はよくdfの変数名を使っています。
> df<-read.table("トウモロコシ.csv",header = TRUE,sep=",")
> class(df)
[1] "data.frame"
3-2. テキスト形式ファイルの読み込み
実はCSV形式とほとんど変わりません。
CSVはコンマ,で区切られていますが、今回指定しているテキスト形式ではタブで区切られています。タブを表すには\tを用います。
したがって、先ほどの第3引数の部分を","から"\t"に書き換えるだけでOKです。
> read.table("トウモロコシ.txt",header = TRUE,sep="\t")
ID Treatment Hight
1 1 Fertilizer 180
2 2 Fertilizer 178
3 3 Fertilizer 192
4 4 Fertilizer 182
5 5 Fertilizer 185
6 1 Control 165
7 2 Control 171
8 3 Control 173
9 4 Control 168
10 5 Control 169
CSVを用いるか、テキスト形式を用いるかは正直好みだと思います。使いやすい方で読み込むとよいでしょう。
また、詳しくは次項で扱いますが、なぜか読み込みがうまくいかないということがあります。どうしてもうまくいかないときは、もう一方のやり方で読み込むのも一つの手です。
3-3. 読み込みがうまくいかないとき
私がRを始めて最初につまづいたのがデータの読み込みでした。
読み込み成功のヒントになるかもしれないことをいくつか紹介します。
-
No such file or directory
意外とよく起こるエラーメッセージです。
指定されたファイルが、ワーキングディレクトリ内で見つからない、というエラーです。
ワーキングディレクトリ以外にファイルを保存している、拡張子が.xlsxのままで.csvになっていない 、ファイル名に誤字がある、といった原因が考えられます。 -
データに欠損値が含まれている
実験のエラーや外れ値検定でどうしても欠損値が出てしまい、サンプルサイズが群によってことなる、というケースが起こりえます。そういったデータを読み込もうとするとエラーが出るときがあります。この場合、元のデータにおいて欠損値を空白ではなく、欠損値を意味するNA(not available)を入力したり、read.table()の引数にfill = TRUEを指定したりする解決策が考えられます。 -
データに
"や'が含まれている
データにダブルクォーテーションやシングルクオーテーションが含まれているとエラーが出る場合があります。元データで該当部分を削除するか、引数にquote = ""を指定します。
4.次回