はじめに
Geminiを用いたLLMアプリからの出力をラベルなしで評価したいと思っていたのですが、パッと見た感じ公式リファレンスに実装方法がのっていなかったので評価までの流れをここに記しておきます。
下記を参考にしました!
いざ実装
LLMアプリ内部ではGeminiを使用し、評価にはデフォルトのGPT4Tを使用しています。
まずは、APIkeyの設定です
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ["LANGCHAIN_API_KEY"] = "YOUR_API_KEY"
os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY" # 評価にはOpenAIのLLMを用いる
次に、LLMアプリに渡す質問をLangSmithにアップロードします。ラベルなし評価のため正解は必要ないです。
また、質問は「そうめんとひやむぎの違いを教えてください」「カッペリーニとフェデリーニの違いを教えてください」「うどんときしめんの違いを教えてください」の3つです。原材料に大きな違いがないものの、太さが違うという共通点があります。
from langsmith import Client
client = Client()
# Define dataset: these are your test cases
dataset_name = "YOUR_DATASET_NAME"
dataset = client.create_dataset(dataset_name)
client.create_examples(
inputs=[
{"question": "そうめんとひやむぎの違いを教えてください"},
{"question": "カッペリーニとフェデリーニの違いを教えてください"},
{"question": "うどんときしめんの違いを教えてください"},
],
dataset_id=dataset.id,
)
今回はLLMアプリ内部で Gemini 1.5 Flash もしくは Gemini 1.5 Pro を使います。
import vertexai
from vertexai.generative_models import GenerativeModel
def gemini_flash(question: str) -> str:
vertexai.init(project="YOUR_PROJECT_ID" , location="YOUR_LOCATION")
multimodal_model = GenerativeModel("gemini-1.5-flash")
response = multimodal_model.generate_content(question)
return response.text
def gemini_pro(question: str) -> str:
vertexai.init(project="YOUR_PROJECT_ID" , location="YOUR_LOCATION")
multimodal_model = GenerativeModel("gemini-1.5-pro")
response = multimodal_model.generate_content(question)
return response.text
次の項目で使用するために、evaluate (evaluate.py)に渡すためには下記のようにwrapする必要があります。しないとTypeErrorではじかれます。
def langsmith_app(inputs):
output = gemini_flash(inputs["question"])
return {"output": output}
どのように評価するかを定義します。今回はタイトルの通りCriteria(no labeled)を使います。
評価の内容は upload_examples.py で与える質問に対するLLMアプリからの出力を、「麺の太さの違いを実際の数字を用いて示しているか」という基準からLLMに判定してもらうことにします。
from langsmith import Client
from langsmith.evaluation import LangChainStringEvaluator, evaluate
criteria_evaluator = LangChainStringEvaluator(
"criteria",
config={
"criteria": {
"麺の太さ": "麺の太さの違いを実際の数字を用いて示していますか?",
}
}
)
最後に評価の実行です!langsmith_app (wrapper.py) 内のgemini_flashをgemini_proに変更すれば、Gemini 1.5 Proの出力を評価できます。
from langsmith.evaluation import evaluate
experiment_results = evaluate(
langsmith_app, # Your AI system
data=dataset_name, # The data to predict and grade over
evaluators=[criteria_evaluator], # The evaluators to score the results
experiment_prefix="gemini-1.5-flashの出力評価テスト", # A prefix for your experiment names to easily identify them
)
※YOUR_HOGE_HOGEは自身の設定を入力してください
評価結果
Gemini 1.5 Flashの結果
下図のまるで囲ったところが麺の太さの評価結果になっていてY/Nで表されます。FlashはN(3)となっているのですべての質問結果で麺の太さの違いを実際の数字を用いて示していないといえそうです。

下図は実際の出力です!
ラベルなしなのでReference Outputはなしとなっています。OutputがLLMアプリからの出力ですが、麺の太さを実際の数値を用いて示していないのがわかります。(他の2つも同じ)
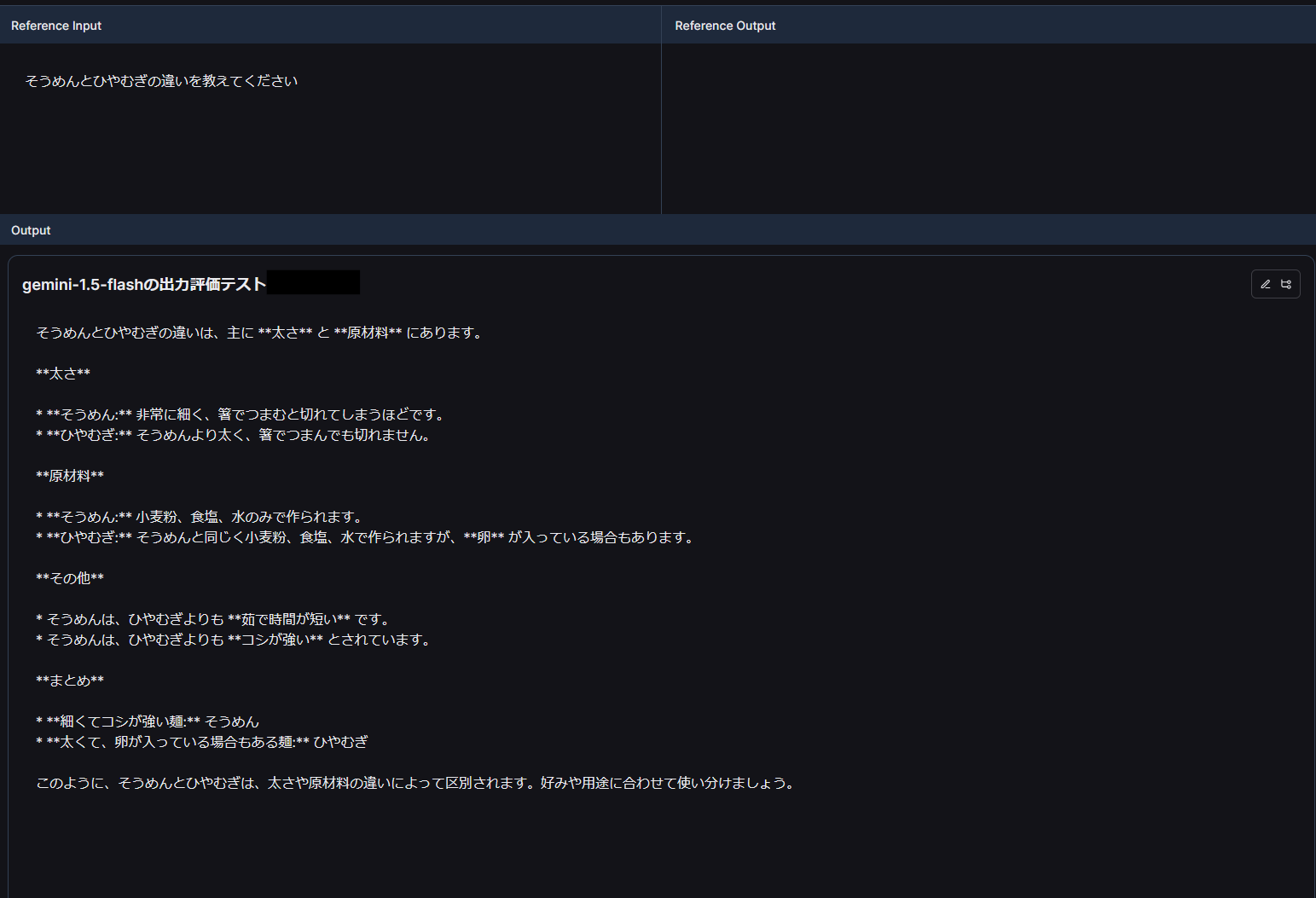
Gemini 1.5 Proの結果
Proは Y(2)N(1) となっているようです。実際の結果を見てみましょう。

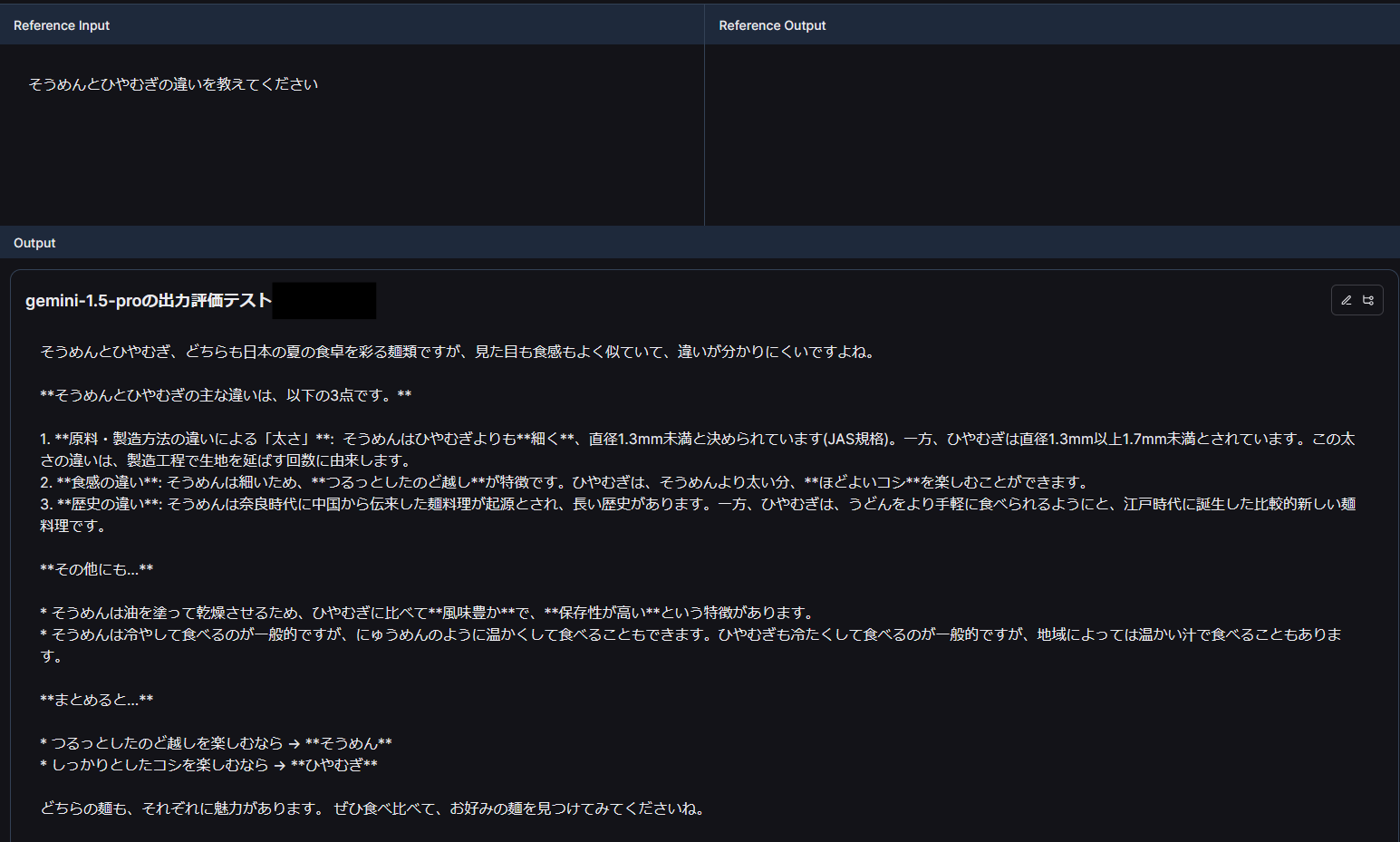
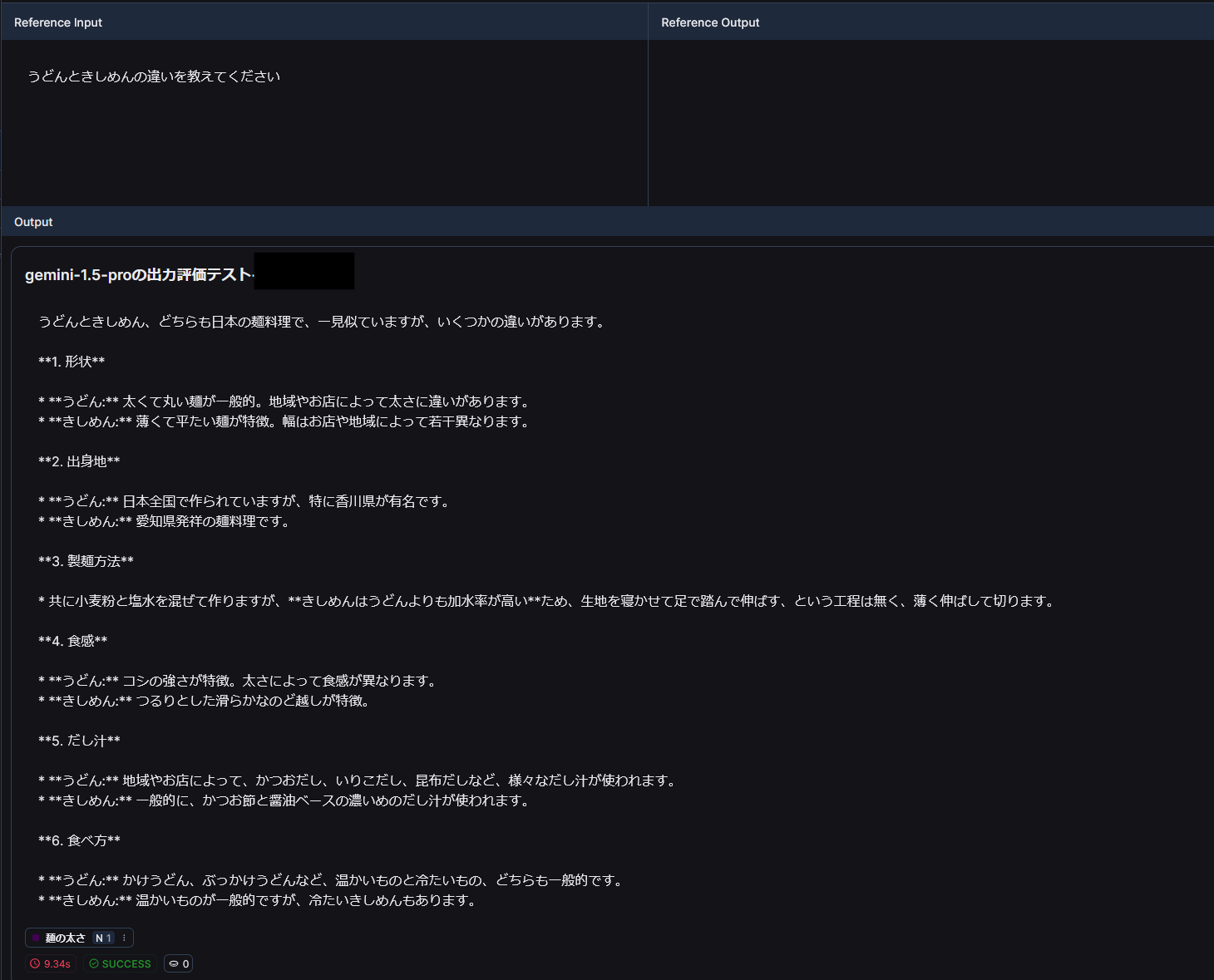
下図はそれぞれYとNの結果です。確かにYのほうの結果は数値を使っていてNは使ってなさそうです。
Yの結果
Nの結果
感想
アプリである以上ユーザーからの直接的な評価はとても重要だと思いますが、今回のLLMを用いた評価は思っているよりも人間からの評価に近いという感触を得ることができました。
ただ、実際の出力はより複雑で、どのように評価するかという基準作りは困難で一定の技術が必要になるという感触も得ることができました!