いろいろあって、文字起こしAPIをとっかえひっかえして試してます。
whisperとか、Google CloudのSpeech to textとか、いろいろあるんですが、ちょうど良さげなキャンペーンがありましたので、AmiVoiceを使ってみることにしました。
AmiVoiceって何だ
音声認識エンジンです。
汎用のモデルのほか、医療、介護、保険などに特化したモデルがあるようです。
個人的には、SDKがあってオフラインで利用可能なのがすごく気になります。
目標
今回はAmiVoiceを使用して、マーダーミステリーの動画ログの文字起こしをしてみましょう。
(とはいえ、この記事にログを載せているわけでもありませんし、また、マーダーミステリーのシナリオのネタバレはありませんので、ご安心ください。)
TRPGのボイスセッションのログおこしにも良いかも、と思ったのですが、AmiVoiceの無料時間が月60分までなので、お金を節約しようと思うとマーダーミステリー向きですね。
マーダーミステリーも(シナリオに寄りますが)なんだかんだ長尺になりがちではありますが、議論時間のみ、最終議論のみとすればハイライトとして使えそうです。
超過した場合は1分1.5円、1時間90円ほどなので、下手なことをしない限りは破産せずにはすみそうです。
(今回はお試しキャンペーン中なので、クーポンで月600分まで使えます。)
AmiVoiceの導入
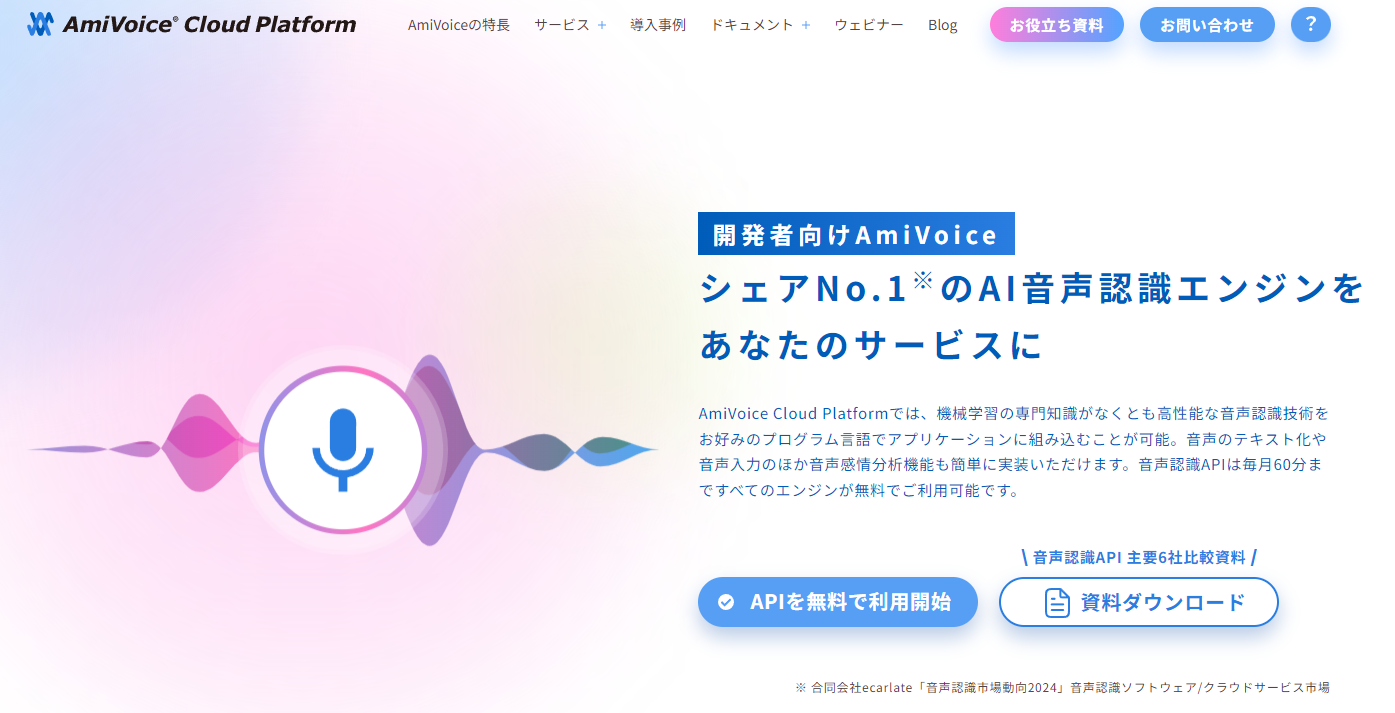
公式サイトからユーザー情報を登録して、利用を開始します。
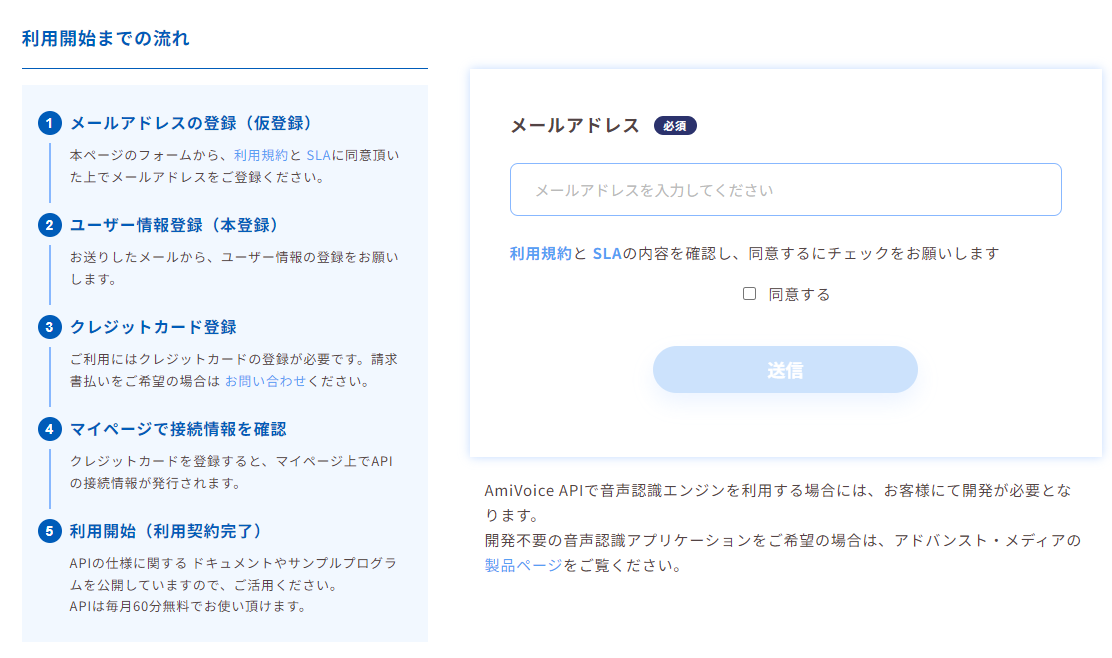
使用にはクレジットカードの登録が必要なタイプのAPIです。
なお、クレジットカードの支払いについてはGMOペイメントです。

ダッシュボードがシンプルで、かなり好きです。
日本語でわかりやすいサイト、それだけで、嬉しい。
あとは、退会手続きがメニュー欄の分かりやすいところにあるのはユーザーフレンドリーで好感が持てます。
いいと思うんだよな……文字を小さくするより……。
早速使ってみる
ドキュメントを見てみましょう。
三つのユースケースが紹介されています。
- 同期 HTTP インタフェース (短い音声ファイル)
- 非同期 HTTP インタフェース (長時間の音声ファイル)
- WebSocket インタフェース (ストリーミング)
今回は手元にある動画ファイルの音声をAPIに送り、結果を得るということをしたいので、非同期HTTPインタフェースがよさそうです。
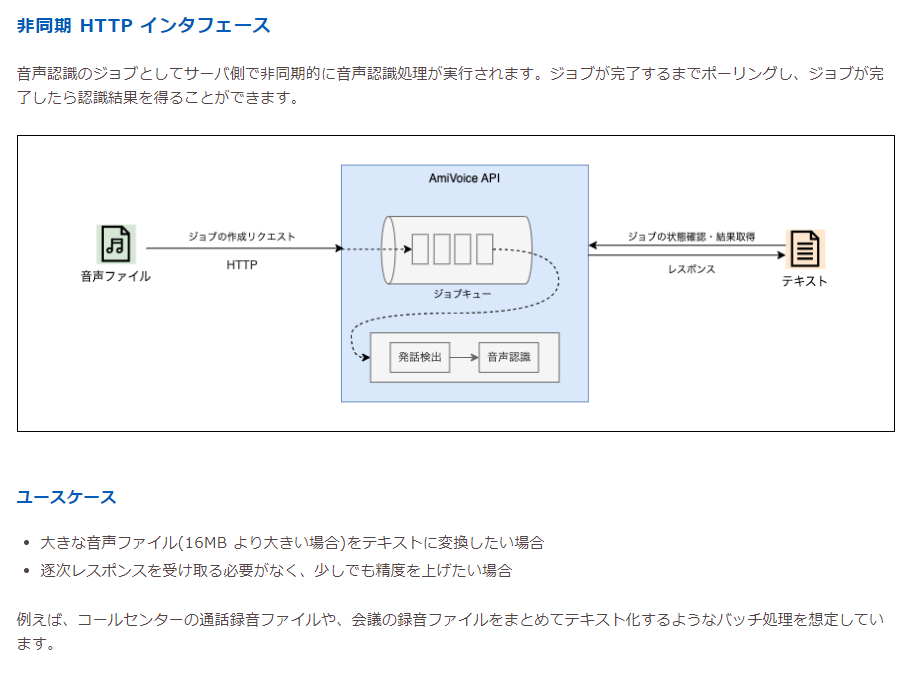
チュートリアルの「長い音声ファイルの書き起こし」を参考にして、コードを実装していくことにしましょう。
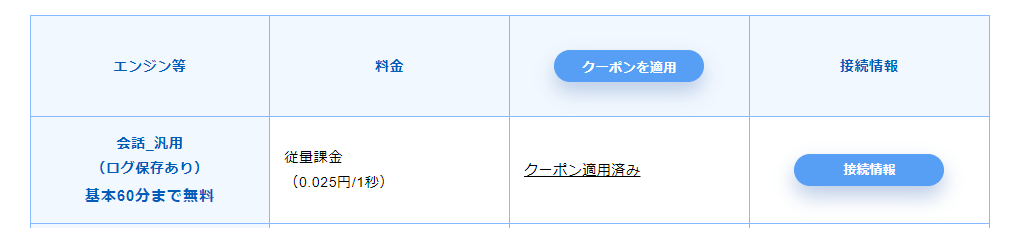
エンジンは素直に会話_汎用(ログ保存あり)でいきましょうか。
Window標準の「サウンドレコーダー」で、マイクに向かって10秒ほど喋ってみました。
私はじゃっかんコンソール黒い画面アレルギーがあるのでC#で呼び出すことにしました。
わざわざWindows Form アプリケーションです。
作っておいてなんだが、コンソールからの方がかっこつくかもしれん……。
MainFormの中身はこんな感じです。
using System;
using System.IO;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Threading.Tasks;
using System.Windows.Forms;
using Newtonsoft.Json.Linq;
namespace AmiTest
{
public partial class MainForm : Form
{
public MainForm()
{
InitializeComponent();
}
private readonly HttpClient client = new HttpClient();
private string appKey = "API_KEY"; // AmiVoiceのAPP_KEYを設定
private async Task<string> SendTranscriptionRequest(string audioFilePath)
{
var content = new MultipartFormDataContent
{
{ new StringContent("-a-general"), "d" },
{ new StringContent(appKey), "u" },
{ new ByteArrayContent(File.ReadAllBytes(audioFilePath)), "a", Path.GetFileName(audioFilePath) }
};
HttpResponseMessage response = await client.PostAsync("https://acp-api-async.amivoice.com/v1/recognitions", content);
response.EnsureSuccessStatusCode();
string responseBody = await response.Content.ReadAsStringAsync();
JObject jsonResponse = JObject.Parse(responseBody);
return jsonResponse["sessionid"]?.ToString();
}
private async Task<string> PollForTranscriptionResult(string sessionId)
{
string url = $"https://acp-api-async.amivoice.com/v1/recognitions/{sessionId}";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", appKey);
while (true)
{
HttpResponseMessage statusResponse = await client.GetAsync(url);
string statusResponseBody = await statusResponse.Content.ReadAsStringAsync();
JObject statusJson = JObject.Parse(statusResponseBody);
string status = statusJson["status"]?.ToString();
if (status == "completed")
{
return statusResponseBody; // JSON形式での結果をそのまま返します
}
else if (status == "failed")
{
throw new InvalidOperationException("Transcription failed.");
}
await Task.Delay(5000); // 5秒ごとにステータスをチェック
}
}
private async void buttonTranscribe_Click(object sender, EventArgs e)
{
OpenFileDialog openFileDialog = new OpenFileDialog
{
Filter = "WAV Files (*.wav)|*.wav|All files (*.*)|*.*",
Title = "Select an audio file"
};
if (openFileDialog.ShowDialog() == DialogResult.OK)
{
string audioFilePath = openFileDialog.FileName;
try
{
// 音声ファイルをAPIに送信して書き起こしをリクエスト
var sessionId = await SendTranscriptionRequest(audioFilePath);
if (sessionId == null)
{
MessageBox.Show("Failed to start transcription job.", "Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
return;
}
// 結果の取得
var result = await PollForTranscriptionResult(sessionId);
MessageBox.Show(result, "変換が完了しました。", MessageBoxButtons.OK, MessageBoxIcon.Information);
textBox1.Text = result;
}
catch (Exception ex)
{
MessageBox.Show("Error: " + ex.Message, "Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
}
}
}
wavファイルを選んで、「あれ……俺、あいつを怒らせたかな?」というくらい待つと結果が出力されます。
(*速度を求めない長い音声の変換用処理なので、こんなものだと思います。)
コーヒーを、あーいや、すみません、見栄を張りました。カルピスを飲んでいると、返事が返ってきました。
中身はこんな感じです。
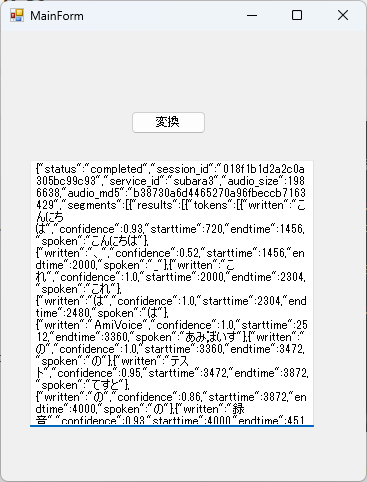
大まかな区切りで確からしさと評価値があり、最後にすべて連結されたテキストが入っています。
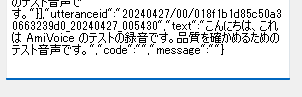
パーフェクトです。
実際に文字起こしをしてみた
とはいえ、これはかなり意識的に音読してみた音声ファイルですから、実用性があるかというとまた別のお話です。
マーダーミステリーをプレイしたときの実際のログを変換してみることにしました。
Shotcut(フリーの動画編集ソフト)で動画から音声を抜き出しました。
……。
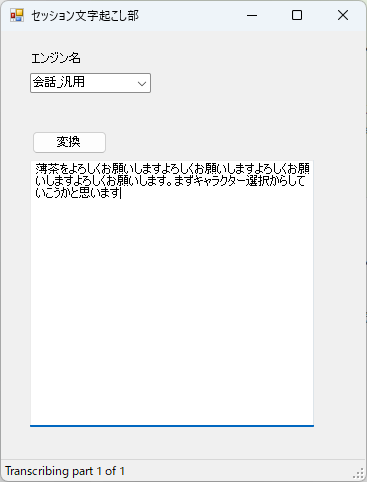
いいですね。
実装があんまりだったので、ちょっと改善して、text部分(変換後結果)のみ抜き出すようにしてみました。
(追記)
上のつくりはあまりよくなくて、今はなんとなく小分けにして送るよりもいっぺんに3時間くらいで送る方がよさそうだと思っています。
結果
3時間超えの長尺のマダミスを文字起こししてもらうことにしました。
長いファイルを変換するために、5分ごとに音声ファイルを分割して、順次文字起こしをしてもらうようにします。
エンジンを選択できるようにして、進捗を表示するようにしました。
およそ3時間30分かかりました。
6万字近くありますね。
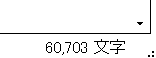
STT結果はかなり良かった(=手で1から起こすよりも早そうなくらいは使えそう)です。
漢字の変換は文脈がつかめないのか難しいところがあるようですが(例:勘で選ぶ→間で選ぶ、となっていたり)8割~9割は起こせてますし、会話の流れもつかんでいそうでした。
あと、認識できない部分が少ないです。
試しに、Google Document+音声文字起こしという方法でやってみたんですが、なんとなく声が大きい話者ひとりにフォーカスしてしまうのか「よろしくお願いします!」に続くほかのプレイヤーの「よろしくお願いします」というような声はとれていませんでした。AmiVoiceだと、ちゃんと、人数分のよろしくお願いしますが入っていました。
私がやった感触では、小さい声の抑揚にもかなり強いように思えます。
この用途(TRPG/マダミスのセッションの文字起こし)についてはじゅうぶん実用レベルはあるんじゃないかと思います。
Google CloudのSpeech to textも、まあ、こっちも月60分無料ではあるんですけれども、やっぱりほかの選択肢は持っておきたい……。
AmiVoiceもなかなか面白そうです。
ほかは、オープンソースがゆえに自前で構築できれば無料のwhisperのkotoba-whisperが気になります。
ストリーミングでの速度も気になるところなので、時間があれば、リアルタイムでいろいろやってみたいなと思います。