創作物への生成AIの利用については様々な議論がなされており、扱いには注意が必要です。
ティラノスクリプトでGPT-3.5のAPIと連携し、自由入力でキャラクターに応答してもらえるようにしてみました。
しくみ
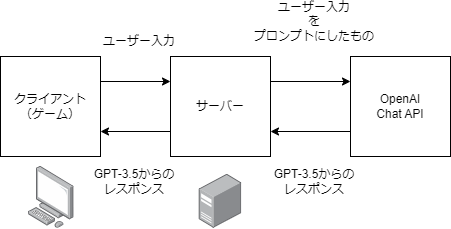
ティラノスクリプトではJavaScriptが使えますので、GPTのAPIも叩けます。
(GPT-3.5は、俗にいうChatGPT……と、だいたいおんなじ!)
JavaScriptを使って、ゲームからサーバーにリクエストを送り、サーバー側で整えて、GPT-3.5のAPIを叩いて、お返事を出力しています。
なお、サーバーを挟まずに直でクライアントからGPT-3.5のAPIを叩きに行ってもいいんですが、OpenAIのキーをゲーム側においとくわけにもいかないのと、うまくいったらデータベースを持たせてやりたかったりとか、用があるので泣く泣くサーバーを立てました。
公開しない、ないしOpenAIのキーを各自で用意してもらう場合はサーバーはなくても大丈夫だと思います。
サーバーを立てるの、自宅の水道を出しっぱなしにするくらいおっかねぇ~~~……。
実装
クライアント側(前後とスクリプト部分)
#青年
今日は、ティラノスクリプトに、
JavaScriptでGPT3.5のAPIを組み込んでみました。
自由にしゃべってみましょう。[p]
#青年
というわけで、何か御用ですか?[p]
*input
[cm]
[edit name="tf.test" top=100 left=100 width="200"]
[button x=400 y=100 target="*ok" graphic="arrow_next.png"]
[s]
*ok
[commit]
[cm]
[jump target="*next"]
[s]
*next
[iscript]
var API_URL = "http://【IP・ポート】/get_response/";
// XMLHttpRequest オブジェクトの生成 (毎回新しく生成)
var xhr = new XMLHttpRequest();
// リクエストの設定
xhr.open("POST", API_URL, true);
xhr.setRequestHeader("Content-Type", "application/json;charset=UTF-8");
// イベントハンドラの設定
xhr.onreadystatechange = function() {
// レスポンスが完了した場合
if (xhr.readyState == 4) {
if (xhr.status == 200) {
var responseData = JSON.parse(xhr.responseText);
tf.response = responseData.response;
console.log(responseData);
// 非同期処理完了後のターゲットを実行
tyrano.plugin.kag.ftag.startTag("jump", {target: "*after_api"});
} else {
tf.response = "失敗しちゃったみたい。";
console.error("Error:", xhr.statusText);
// エラー時のターゲットも設定可能
tyrano.plugin.kag.ftag.startTag("jump", {target: "*error"});
}
}
};
// データの送信(これがプロンプトだよ!)
var data = JSON.stringify({
system_input: "ユーザーを「わが師」と呼びます。返答は50字以内です。名前はケレス。一人称は僕。慇懃で丁寧です。手に持っているのは名刺です。好きなものは我が師。例「これは技術デモです。我が師」",
user_input: tf.test
});
xhr.send(data);
[endscript]
[s] ; この部分でスクリプトを止める
*after_api
[emb exp="tf.response"]
; 「次へ」ボタンを表示して、クリックされたら *input へジャンプ
[button graphic="arrow_next.png" x="100" y="150" target="*input"]
; ここで処理は停止し、ボタンがクリックされるのを待つ
[s]
「純粋なJavaScriptでやってたときと比べたら、なんか応答を待ってくれない~」、
とぼやいてたらChatGPTさんがいい感じに待機する処理を書いてくれました。
意外とティラノスクリプトに堪能です。
(tyrano.plugin.kag.ftag.startTagってなんだ……!?)
[p]タグでは止まってくれないので、ボタン操作にしたりしていて、
なんていうか、まあ、このあたりが「とりあえず」の部分ですね。
ひとのおうちで動くんだろうか……?
サーバー側
こっちはPythonで、GCPの格安インスタンスにのっけたFastAPIを稼働させています。
(とっても雑です)
from fastapi.middleware.cors import CORSMiddleware
from fastapi import FastAPI
from pydantic import BaseModel
import os
import openai
import time
from datetime import datetime
app = FastAPI()
【※ここでCORSとか設定したりするといいみたい……※】
# モデルクラスの定義(入力データの形式を指定)
class InputText(BaseModel):
system_input: str
user_input: str
# ChatGPTにテキストを送って受け取る処理
def get_gptText(system_input, user_input, max_retries=0, model_name="gpt-3.5-turbo"):
openai.api_key = os.getenv("OPENAI_API_KEY") # 環境変数
retries = 0
while retries <= max_retries:
try:
# テキストを生成するためのAPIリクエストを作成する
start_time = time.time()
start_time_str = datetime.fromtimestamp(start_time).strftime('%Y-%m-%d %H:%M:%S')
max_tokens_value = 60
# GPT-3.5 Turbo model
response = openai.ChatCompletion.create(
model=model_name,
messages=[
{"role": "system", "content": system_input},
{"role": "user", "content": user_input},
],
)
end_time = time.time()
end_time_str = datetime.fromtimestamp(end_time).strftime('%Y-%m-%d %H:%M:%S')
response_time = end_time - start_time
return response.choices[0]['message']['content'], start_time_str, end_time_str, response_time
except Exception as e:
print(f"Error: {e}")
retries += 1
print(f"Retrying... {retries}/{max_retries}")
time.sleep(20)
if retries > max_retries:
print("Max retries exceeded. Exiting...")
return None
@app.post("/get_response/")
async def get_response(text: InputText):
response, start_time, end_time, response_time = get_gptText(text.system_input, text.user_input)
if not response:
raise HTTPException(status_code=500, detail="Failed to get response from GPT")
return {
"response": response,
"response_time": response_time
}
@app.get("/")
def read_root():
return {"Hello": "World"}
コードは上記のようなものですが、そのまえにGCPでいろいろインストールしたり、コマンドラインで順番にビンタする必要があります。
とくにブラウザで動かしたいわけじゃなく、おうちでお話するbotが欲しいだけだったら直でAPIをどつくのもありです。
コスト
これをやると、サーバー費+OpenAIのChatのAPIのぶんコストがかかります。
サーバー
とりあえずGCPの無料枠で動かしてみました。
数円かかっていました。
GPT-3.5のAPI使用料金
応答を作成するのに使うお金です。
GPT-3.5 Turboの4K contextは
1000トークンあたり、入力$0.0015、出力$0.002です。
ドル払いなので、円高/円安の影響を受けます。
参考:https://openai.com/pricing
トークンは文字数ってわけじゃなくて、tokenizerで数えることができますが、日本語だと、まあ、だいたい文字数(以下くらい)です。
トークナイザー:https://platform.openai.com/tokenizer
日本語は英語よりも損で、プロンプト(命令文)は英語だけど、回答は日本語でね、なーんてやったりすることもあるようです。
でも、まじめな用途ならともかくも、「俺/オレ」「僕/ぼく/ボク」とかのニュアンスは捨てがたいものがあるよね。
正規表現や置換でやる方法もあるようです。
このトークンってやつには、ユーザーの入力+命令文も含まれるので、
ざっくり入力200、出力100くらい使うとして、
今日(2023/8/18)のレートだと、0.073 円くらい。
10回やりとりしたら0.7円、100回やりとりしたら7円くらいになります。
1人でおしゃべりしてる分には何ら問題ないのですが、これが100人とかになってくると、ねっ!
回数もね、1日にひとり10回とか、合計して1日1000回とか、何かしらは制限をかけたいところですね。
それか、キーを自前で用意してもらわないとちょっともたないですね。