はじめに
手が離せない時に、喋った内容を自動でテキストチャットして欲しいなと思って作った時のメモです。
テキストチャットに対応したオンラインゲーム用に作りました。
動作環境
私が試した環境です。
- OS : Windows10pro 1809
- プログラム言語 : Python 3.7.3
フローの概要
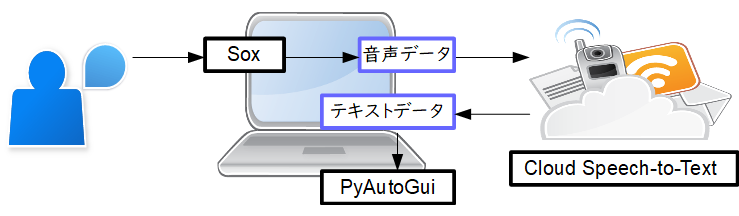
- マイクからの音声を
soxで音声ファイルに出力します。 - 音声データを
Cloud Speech-to-Textへ送信し、テキストに変換します。 - 受け取った文字列を
PyAutoGuiでキーボードを操作して出力します。
録音ファイルの作成
以下のページを参考にさせて頂きました。(1は環境構築の手順、2は音声認識のためのトリガー設定の方法)
以下にコードを記載しています。
import os
import subprocess
# 環境パスの設定
os.environ['AUDIODRIVER'] = \
'waveaudio'
WAVE_OUTPUT_FILENAME = 'data.FLAC'
def rec_wav():
subprocess.run('sox -r 16000 -c 1 -d ' + WAVE_OUTPUT_FILENAME \
+ ' silence 1 00:00:00.5 -55d 1 00:00:02 -45d', \
shell=True) # 録音
print('rec end')
音声を録音するためのトリガーは、一定時間、音量が一定値を超えるとしています。コードの silence 1 00:00:00.5 -55d の部分が対応しています。
録音の終了条件は、一定時間、音量が一定値を下回るとしています。コードの 1 00:00:02 -45d の部分が対応しています。
また、Cloud Speech-to-Text に対応した音声データとするために、モノラルで出力しています。コードの -c 1 の部分が対応しています。
音声からテキストへ変換
以下のページを参考にさせて頂きました。(1はサービスアカウントキー取得までの環境構築の手順、2は実際のプログラムコードの参考、3はオプションなどの理解)
以下にコードを記載しています。
import io
# 環境パスの設定
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = \
'########.json'
def transcribe_file():
from google.cloud import speech
from google.cloud.speech import enums
from google.cloud.speech import types
get_message = ''
client = speech.SpeechClient()
# 音声データのセット
with io.open(WAVE_OUTPUT_FILENAME, 'rb') as audio_file:
content = audio_file.read()
audio = types.RecognitionAudio(content=content)
config = types.RecognitionConfig(
sample_rate_hertz=16000,
language_code='ja-JP')
# サーバへの送受信
response = client.recognize(config, audio)
for result in response.results:
get_message = u'{}'.format(result.alternatives[0].transcript)
return get_message
コードは、ほぼ参考ページ2のままです。
###.json のところには、ダウンロードしたサービスアカウントキーのパスを指定しています。
サンプルレートは、録音時の sox の設定 -r 16000 と同じにしています。
言語は、日本語 ja-JP を指定しています。
テキストチャットとして出力
以下のページを参考にさせて頂きました。
以下にコードを記載しています。
import pyautogui as pgui
from pykakasi import kakasi
# ローマ字変換の設定
kakasi = kakasi()
kakasi.setMode('H', 'a')
kakasi.setMode('K', 'a')
kakasi.setMode('J', 'a')
conv = kakasi.getConverter()
def put_chat(text_chat):
# ローマ字変換
text_chat = conv.do(text_chat)
# チャット出力
pgui.typewrite(text_chat)
pgui.press(keys="space")
pgui.press(keys="enter",presses=2)
テキストチャットを行いたいウィンドウをアクティブにした状態で、実行しています。
Cloud Speech-to-Text で認識されたテキストは、漢字/ひらがな/カタカナ交じりの形となっています。キーボードではローマ字入力としていましたので、認識されたテキストを pykakasi でローマ字(アルファベット文字列)に変換しています。
アルファベットを入力した後、SPACE で変換し、1回目の ENTER で確定、2回目の ENTER でチャット送信を行っています。
プログラムコード全体
以下に全体のコードを記載しています。
import time
import io
import os
import subprocess
import pyautogui as pgui
from pykakasi import kakasi
# -------------------------------
# 設定
# -------------------------------
# 動作
WAITE_TIME_INITIAL = 3 # 起動時の待機時間
# 環境パスの設定
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = \
'########.json'
os.environ['AUDIODRIVER'] = \
'waveaudio'
# 音声ファイルの設定
WAVE_OUTPUT_FILENAME = 'data.FLAC'
# ローマ字変換の設定
kakasi = kakasi()
kakasi.setMode('H', 'a')
kakasi.setMode('K', 'a')
kakasi.setMode('J', 'a')
conv = kakasi.getConverter()
# -------------------------------
# 録音
# -------------------------------
def rec_wav():
subprocess.run('sox -r 16000 -c 1 -d ' + WAVE_OUTPUT_FILENAME \
+ ' silence 1 00:00:00.5 -55d 1 00:00:02 -45d', \
shell=True) # 録音
print('rec end')
# -------------------------------
# 音声認識
# -------------------------------
def transcribe_file():
from google.cloud import speech
from google.cloud.speech import enums
from google.cloud.speech import types
get_message = ''
client = speech.SpeechClient()
# 音声データのセット
with io.open(WAVE_OUTPUT_FILENAME, 'rb') as audio_file:
content = audio_file.read()
audio = types.RecognitionAudio(content=content)
config = types.RecognitionConfig(
sample_rate_hertz=16000,
language_code='ja-JP')
# サーバへの送受信
response = client.recognize(config, audio)
for result in response.results:
get_message = u'{}'.format(result.alternatives[0].transcript)
return get_message
# -------------------------------
# ゲーム画面にチャットを出力
# -------------------------------
def put_chat(text_chat):
# ローマ字変換
text_chat = conv.do(text_chat)
# チャット出力
pgui.typewrite(text_chat)
pgui.press(keys="space")
pgui.press(keys="enter",presses=2)
# -------------------------------
# main
# -------------------------------
if __name__ == '__main__':
time.sleep(WAITE_TIME_INITIAL)
while True:
rec_wav()
get_message = transcribe_file()
if not get_message == '':
put_chat(get_message)
print(get_message)
main 関数内で一連の処理をループさせています。
普段は rec_wav() で音量を監視している状態となり、トリガー条件を満たすと一連の処理を実行し、再び rec_wav() での音量監視の状態に戻ります。
以下に 'requirements.txt` の内容を記載しています。一部必要のないものも入っているかもしれません。
astroid==2.2.5
cachetools==3.1.1
certifi==2019.6.16
chardet==3.0.4
colorama==0.4.1
google-api-core==1.14.2
google-auth==1.6.3
google-cloud-speech==1.2.0
googleapis-common-protos==1.6.0
grpcio==1.22.0
idna==2.8
isort==4.3.21
lazy-object-proxy==1.4.1
mccabe==0.6.1
MouseInfo==0.0.4
Pillow==6.1.0
protobuf==3.9.1
pyasn1==0.4.6
pyasn1-modules==0.2.6
PyAudio==0.2.11
PyAutoGUI==0.9.47
pygame==1.9.6
PyGetWindow==0.0.7
pykakasi==1.0
pylint==2.3.1
PyMsgBox==1.0.7
pyperclip==1.7.0
PyRect==0.1.4
PyScreeze==0.1.22
PyTweening==1.0.3
pytz==2019.2
requests==2.22.0
rsa==4.0
semidbm==0.5.1
six==1.12.0
typed-ast==1.4.0
urllib3==1.25.3
Wave==0.0.2
wrapt==1.11.2
おわりに
ゲーム中に手元が忙しい時もチャットできるようになって、便利になりました。
googleの音声認識の精度は素晴らしく、ちゃんとした日本語がかなりの確率で返ってきます。むしろ録音環境やしゃべり方の側で認識精度を低下させている印象が強いです。使っていたマイクの入力音量がどうも小さく、いいマイクをamazonに注文してしまいました。おそらく、さらに使いやすくなるのではないかと期待しています。
最初はwindows10のデフォルトの音声認識機能を試したのですが、認識精度が悪かったため、google音声認識に切り替えました。
録音のトリガーは、最初はゲームパッドの特定のボタンを押す事にしようと考えていたのですが、ゲームウィンドウをアクティブにした状態から、ボタンの入力をpython側で検知する方法が分からず、音量に切り替えました。(pygameでいけるのかなと思っていたのですが、pygameで作成したウィンドウに対する入力を検知する方法しか分かりませんでした)
録音には PyAudio ライブラリもありましたが、sox の方が初心者向きに思えたので今回は sox を使用しました。 PyAudio であれば、pip だけで管理できるので、環境構築はシンプルに思えたので、そちらも今後確認してみたいと思います。