はじめに
AI活用にあたって重要とされるものの1つにRAGがありますが、これはBigQueryなどのDWHでもできるようになり、身近なものになってきています。
ただ、小規模であれば全然コストはかからないであろうとはいえ、DWHで行うのは少し怖いものがあります。そこで便利なのが、S3 Vectorsです。
これを使うと、ベクトルの保管と検索が激安で行えるようになります。
一方で、S3 Vectors自体の機能は保管と検索に限られるため、検索をかけるベースとするドキュメントに対しては、適切にデータを管理する必要がでてきます。そこで、
- 検索のベースとするドキュメントのデータをデータパイプラインのバッチ処理で管理する
- 検索対象を指定したベクトル検索をリアルタイムで行えるようにする
という仕組みを考えてみました。コードも公開しているので、よろしければ参考にしてください。
全体構成
全体構成は以下の通りです。
- S3 Vectorsとのデータのやり取りはAPI Gateway + Lambdaの構成とする
- エンドポイントとしてIndex List、Vectors List / Upsert / Delete / Searchを用意する
- Searchの際には、EmbeddingのAPIで検索文言のベクトル化を行い、検索結果はS3に保存する
- データ管理は以下のように行う
- ソースシステムからのデータの取得をTROCCOで行う
- 対応していればそのコネクタで、非対応のAPIはカスタムコネクタで連携する
- ベクトル化はDWHの関数で実行する
- IDと更新日時ベースで差分更新とする
- TROCCOの転送先カスタムコネクタでS3 VectorsにデータをUpsertする
- ソースシステムからのデータの取得をTROCCOで行う
- 検索UIの1つとしてGoogle Apps Scriptで画面を用意する
以下の事例ではQiitaのTROCCOに関連する記事をS3 Vectorsに取り込んでおり、検索をすると以下のように検索結果が表示されます。

今回は簡易な検証のためUIでの検索としていますが、もちろんAIエージェントから検索させて、情報を返してあげることもできるでしょう。
それでは、ここから簡単に紹介をしていきます。
そもそもベクトル検索とは
ベクトル検索は、
- 検索のベースとするデータを事前にベクトルとして変換しておく
- 検索対象をベクトル化する
- 両者の類似度を算出する
- 類似度をもとに上位N件を抽出する
といった流れを取ります。
これは冒頭で紹介した「BigQueryでRAGを構築してみた」の記事をなぞっていただくとよくわかるのですが、いずれにせよ(今回の設定では)記事のテキストをベクトル=768次元のfloatの配列に変換します。
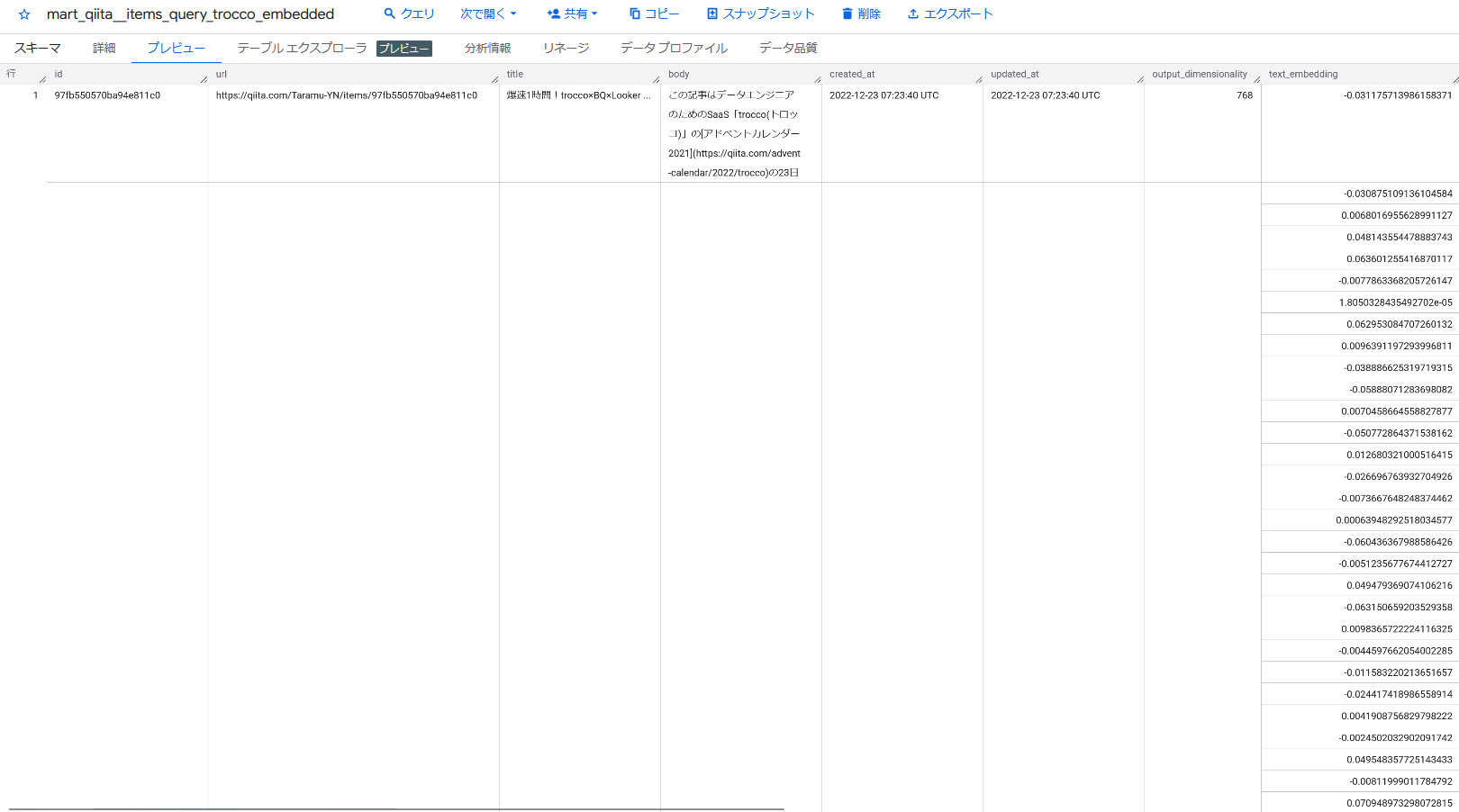
検索する文字列についても同様にベクトルを生成することで、N次元ベクトル間の距離を数学的に算出し、類似度を判定できるようになっています。
このとき、変数としては、
- どのモデルで変換するか
- 今回は
text-multilingual-embedding-002を利用している
- 今回は
- 変換の処理方法をどうするか
- 今回の方法では、Task Typeという設定があり、情報検索、類似度判定、分類などの目的によって処理方法が調整できるようになっている
- 何次元のベクトルに変換するか
- 今回は768次元としている
というものがあり、検索の際には、
- 利用するモデルや次元は上記と共通
- 処理方法は上記に合わせたもの
として処理を行い、
- 類似度判定のロジックをどうするか
- 今回はコサイン類似度を利用しているが、ほかにユークリッド距離などもある
- 類似度の上位いくつをレスポンスとして返すか
といったところが出てきます。処理の流れに沿って整理すると以下の通りです。
レスポンスをどうRAGとして処理するかは別途出てくるのですが、それは今回の実装外なので、末尾で改めて触れるようにします。
さて、仕組みとしてはこのようなものなので、実装内容を簡単に紹介していきます。
各種実装
ここから、各種実装の概要を紹介します。詳細についてはリポジトリを確認してください。
Lambdaの実装
API Gatewayからリクエストを受け取って、S3 Vectors APIとやり取りをするシンプルな構成です。Search APIからのリクエストのみ、テキストが入力された場合はVertex AI APIでEmbeddingを行い、S3にリクエスト/レスポンスを保存するようにしています。
余談ですが、リクエストのバリデーションのために初めてPydanticを利用してみて、非常に便利でした。型が適切に処理できるのはAIを利用する上ではかなり助かります。
Terraformの実装
ベクトルバケットやインデックス、API Gateway、Lambda等をTerraformでデプロイしています。
ベクトルバケットとインデックスをTerraform管理に寄せて、個々のベクトルデータはAPI経由で操作するという形にしています。
データ管理のためのAPIについては、アクセス元をTROCCOのグローバルIPのみに制限することで、APIキーと合わせてセキュアなアクセスにしています。
検索APIはGoogle Apps Script経由なので、IPが固定できずキー認証のみという課題はありますが、簡易な検証目的なので今回はこの構成としています。
TROCCOの実装
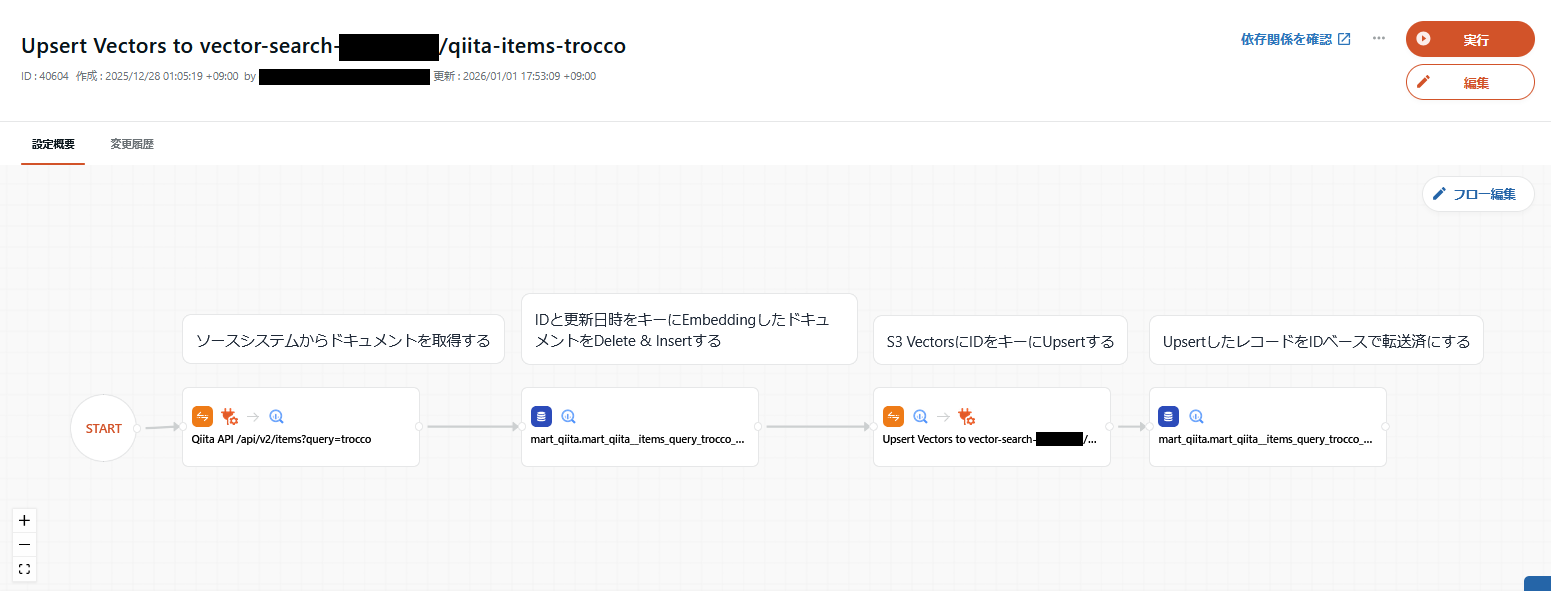
次のように、
- ソースシステムからドキュメントを取得する
- IDと更新日時をキーにEmbeddingしたドキュメントをDelete & Insertする
- S3 VectorsにIDをキーにUpsertする
- UpsertしたレコードをIDベースで転送済にする
という流れを取っています。
ベクトル化はBigQuery MLのml.generate_text_embedding関数を利用して処理しています。
いちいちクエリを書くのが面倒なので、この処理をUDTFでいい感じにできないかと思ったものの、ml.generate_text_embedding関数が動的なパラメータを受け付けないため、中途半端な処理になってしまったのは課題です。
また、転送先カスタムコネクタでデータを連携する際のリクエストテンプレートは次の通りです。これによってDWH上で各カラムとして保持していたデータをリクエストに必要なJSON形式に変換してくれます。
{
"vectorBucketName": "vector-search-********",
"indexName": "qiita-items-trocco",
"vectors": [
{%- for row in rows %}
{
"key": "{{ row.id }}",
"data": {"float32": [{{ row.text_embedding_str }}]},
"metadata": {
"url": "{{ row.url }}",
"title": "{{ row.title }}",
"source_created_at": "{{ row.source_created_at }}",
"source_updated_at": "{{ row.source_updated_at }}",
"embedding_provider": "{{ row.embedding_provider }}",
"embedding_model": "{{ row.embedding_model }}",
"text_embedded_at": "{{ row.text_embedded_at }}"
}
} {%- unless forloop.last -%},{%- endunless -%}
{%- endfor %}
]
}
転送先カスタムコネクタの詳細については次の記事を参考にしてください。
Google Apps Scriptの実装
基本的にはAPI Gatewayの検索APIにリクエストを送って、レスポンスを表示するだけのシンプルな仕組みです。Webアプリとして公開してユーザーの権限で実行するため、メールアドレスおよびドメインでアクセス制限をかけて、利用者を限定するとともにそのIDをS3に保存するように連携しています。
備考
TROCCOからS3 Vectors APIへ直接アクセスさせていないのは、一定の処理を入れるためというのもありますが、認証にSigV4というヘッダーが固定にならない認証方法を取る必要があり、SDK経由にするしかなかったからです。
また、Vertex AI APIの利用にあたってはサービスアカウントキーをSSMに保存することで対応していますが、この処理でそろそろTerraformのEphemeral Resources(Stateに保存せずにクレデンシャルを取り扱える)の出番では・・・?と思ったものの、まだ外部連携には対応していませんでした。そろそろ対応して欲しいところです。
In future, when write-only arguments are added to resources in the Google provider, ephemeral resources such as google_service_account_key could be used to set field values when creating managed resources.`
Ephemeral Resourcesについてはこちらを参考までに。
なお、本番運用時はWorkload Identity Federationのキーレス認証の方がいいというのは言うまでもないですが。
拡張に向けての論点
ここまでで、データの更新およびベクトル検索を安価に行う仕組みを紹介してきました。データパイプラインに乗っかってベースのドキュメントを更新しつつ、簡易な仕組みを構築するという意味では使えそうな構成に思っています。
一方で、AIで利用するRAGシステムとしてはまだまだ検討の余地があります。何を目的として、そのために何を素材としてどう使うかというユースケースをベースにしつつ、
- DWHにデータを取り込みするまでの前処理
- 例えばHTMLをMarkdownに変換するなど、ソースのデータ形式に応じた共通化の処理
- テキストをどう処理するか
- 長文テキストの場合、そのまま突っ込んでも取り回しが悪くなる
- そこで、チャンク化(テキストの分割)をするわけだが、これをどういう単位で切って、チャンク間での重複を持たせるかなど
- どうベクトル化するか
- 前述したような、モデル、処理方法、次元数等
- どう検索するか
- 検索対象の入れ方、フィルタ条件
- 検索結果をどう後処理するか
- チャンク化したときの周辺コンテキストの取扱い(周辺の文章も合わせて処理するなど)
- 更新日などの別指標や、全文検索など別の検索結果も組み合わせたリランキング
- 評価と改善
- 処理の適切性をどういった指標で評価し、数多くある変数のどこを調整して改善していくか
といった点が論点として挙がってきます。前掲していた図を拡張すると、次のようになります。
このあたりはちょうど以下の記事が公開されていました。チューニングしていくのがやはり大変そうですね・・・。
おわりに
実装が簡単でありコードを見てもらった方が早そうなので、記事としては短くまとめています。いずれにせよシンプルながら使えそうに思いますし、ベクトル検索の仕組みを理解する上でも非常に勉強になったので、参考にしていただけると嬉しいです!