はじめに
本記事は、trocco® Advent Calendar 2023の9日目の記事になります。
trocco®だけを取り上げるわけではありませんが、この内容をおさえておくとその価値や使い方が理解しやすいと思いますし、もちろんユーザー以外でもデータエンジニアリング入門として読んでいただければと思います。
さて、私は今年の2月にtrocco®を提供する株式会社primeNumberに転職し、現在はtrocco®を利用したデータパイプライン/BIツールによるダッシュボード構築などを行っています。
前職は広告代理店でTableauを使ったマーケティングデータ分析を行っていたのですが、総合職の異動でたまたまデータ関連部門にいただけですし、プログラミング経験もなかったので、異業種異職種への転職でこの1年はめちゃくちゃ勉強をしてきました。
エンジニア出身の方向けには、『実践的データ基盤への処方箋』や『ビッグデータを支える技術』、『エンジニアのためのデータ分析基盤入門』といった素晴らしい入門書がありますが、これらの本は非エンジニア出身には前提となる知識が幅広く、その内容を咀嚼していくのはかなり骨が折れることになります。
では、データエンジニアリングの大枠を理解するには、どのようなことを理解しておくとよいのか、そこを過去の自分が読みたかったものとして整理してやろうというのが今回の記事の内容です。
こんな方におすすめ
- trocco®に興味があり、その価値や役割を深く理解したい
- trocco®のユーザーであり、利用方法を改めて検討する材料としたい
- 非エンジニア出身だがデータエンジニアリングに関心があり、これから学びを深めていきたい
- (エンジニア出身だが、データエンジニアリングのことについて学んでみたい/取り組まざるを得なくなってしまった)
データエンジニアリングとはなにか
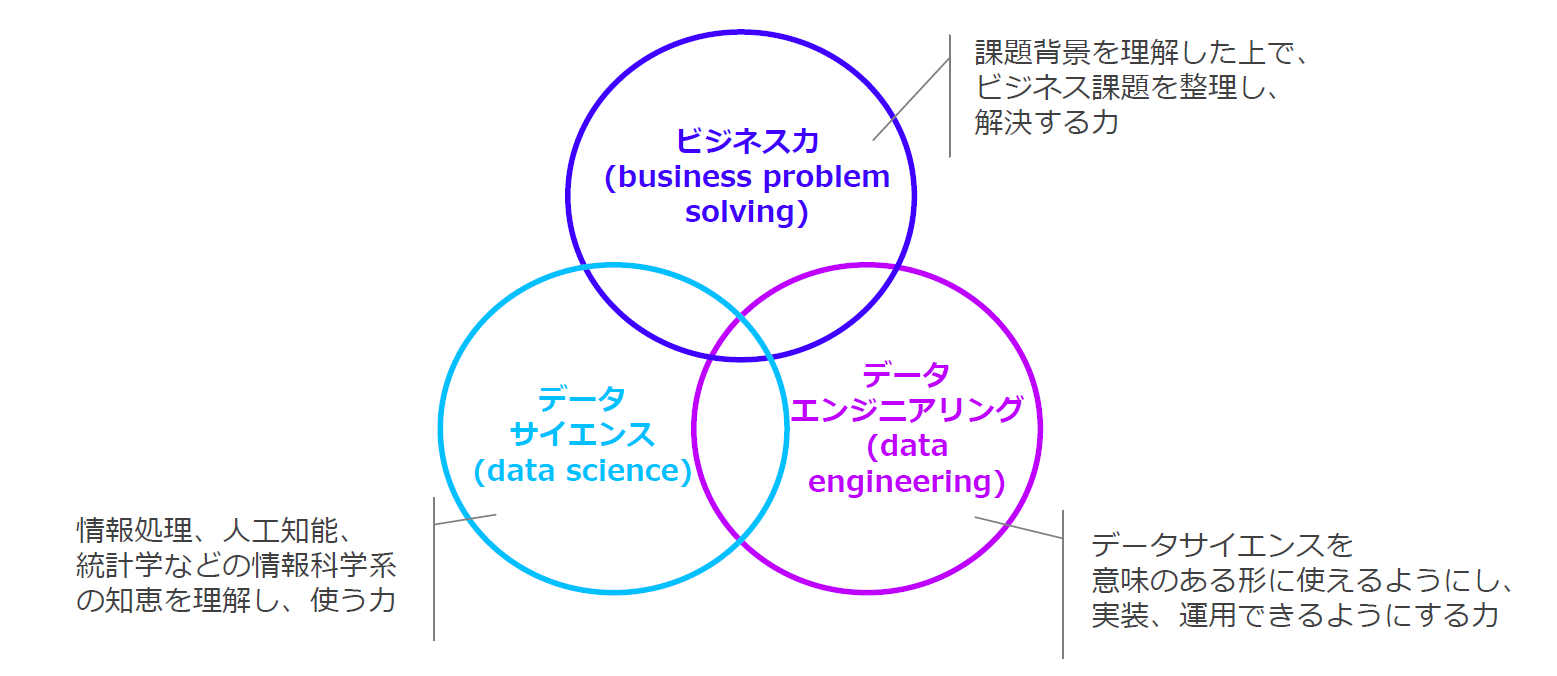
まず、概論的なところからはじめましょう。「データエンジニアリング」というと、データサイエンティスト協会が出している3つのスキルセットのうちの1つということが思い浮かびます。
(出典:一般社団法人データサイエンティスト協会スキル定義委員会[2023]「2023年度スキル定義委員会活動報告/2023年度版スキルチェックリスト&タスクリスト公開」)
ここでは、データエンジニアリングが
データサイエンスを意味のある形に使えるようにし、実装、運用できるようにする力
と定義されています。もちろんそれはそうだろうだけど、具体的にはどういうことなのかと思いますよね。では、同じ資料で提示されている、データエンジニアリングのスキル領域についてみてみましょう。

(出典:同上)
こちらは先ほどの定義よりは具体的になっていますが、技術的な知識がないと、まだどういうことかのイメージは掴みにくいでしょう。そこで、データエンジニアリングがなぜ必要かについて考えてみましょう。
データエンジニアリングはなぜ必要なのか
事業にデータを活用していくときのコンテキストを考えていくと、その意義が分かってきそうです。ということで、事業とデータについて考えてみます。
事業とデータ
そもそも、事業活動の基盤にはデータ(システム)があります。会社の基盤として従業員管理のためのデータがあり、営業活動には営業管理や顧客管理のためのデータがあり、サービス提供にはサービスの安定的な運用のためのデータがあり、生産活動には生産管理のためのデータがあり・・・など。
さらに、昨今叫ばれているDXを進めようとすると、従来からの基幹系のデータと、ユーザーの利用ログなどを含めた情報系のデータを統合/連携させてデータを起点に事業を再構築していく必要があります。
しかし、そこで問題が発生します。何かというと、「まともに使えるデータがない」のです。もう少しここで解像度を上げると、
- データが存在しない
- データが整理されていない
- データの品質が十分ではない
という意味で、データがないのです。
特に、日本ではIT技術者の多くがユーザー企業の外部にいるので、業務運用のための最低限のシステムはあったとしても、DXの推進に利用できるような攻めのデータ活用の文脈においては、特に「まともに使えるデータがない」傾向にあると考えられます。
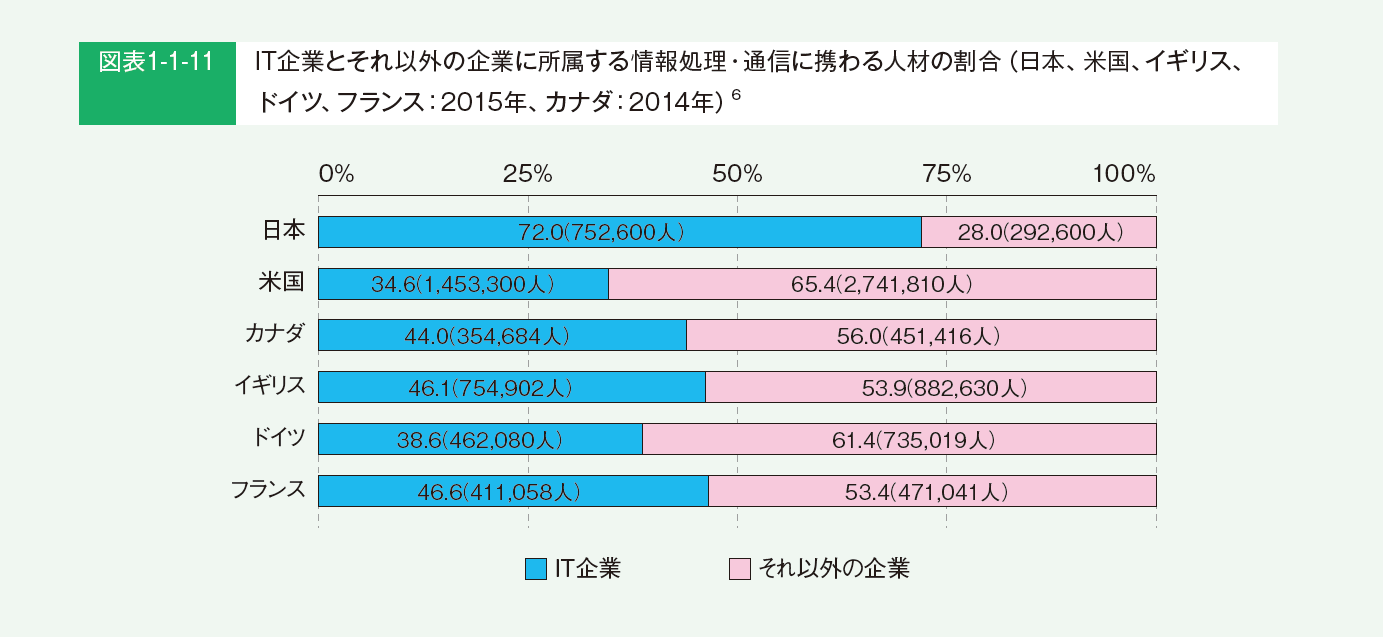
(出典:独立行政法人情報処理推進機構IT人材育成本部編[2017]「IT人材白書2017:デジタル大変革時代、本番へ~ITエンジニアが主体的に挑戦できる場を作れ~」)
データを基盤にした事業に再構築していくにあたって、この「まともに使えるデータがない」という課題を技術的に解決しようとするのが、データエンジニアリングになります。
そしてもちろん、これを効果的にやっていこうとするとITシステムの管理能力を内部化していく必要があるので、多くの企業で内製化の努力がなされてきているわけです。当然、これまでベンダー丸投げで知見を失ってきた組織にとっては、それを取り戻すのは大きな変革と投資が必要になるわけですが・・・とすみません、脱線しました。
データエンジニアリングのプロセスを理解する
具体の話に入る前に、現在私が参加しているdatatech-jpの輪読会で読んでいる、Fundamentals of Data EngineeringのData engineering lifecycleを紹介します。
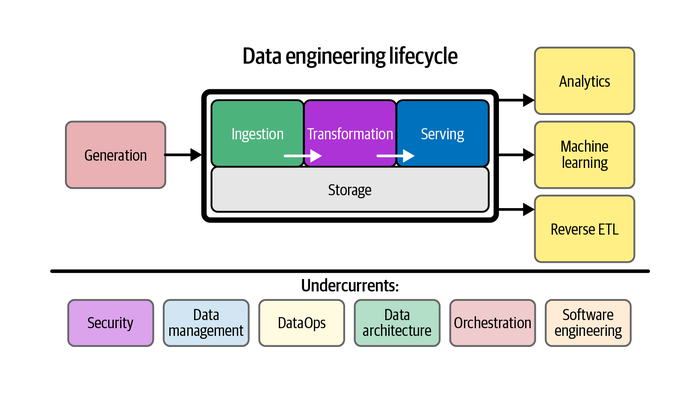
(出典:2. The Data Engineering Lifecycle - Fundamentals of Data Engineering)
ここで整理されているのは、データの活用にはソースシステムでデータを生成し、それを抽出し、加工用のストレージに格納し、加工し、提供し、分析/機械学習/リバースETLに活用するというデータの流れがあるということです。
そして、このデータの流れを基盤として支える要素として、セキュリティ、データマネジメント、DataOps、データアーキテクチャ、オーケストレーション、ソフトウェアエンジニアリングがあるという形で整理されています。
今回は入門になるので以下はライフサイクルをベースに整理していきますが、生成から活用までのデータの流れと、それを基盤として支えるものという観点の分け方は、初学者にはなじみやすいものではないかと思います。
①データの生成と抽出
まずは、ソースシステムにおけるデータの生成と抽出について取り上げます。詳細に入る前にポイントをおさえておくと、
- データは保管場所も管理者も分散しており、統合して活用することは二次利用であることが基本
- Garbage In, Garbage Outという言葉があるように、適切なデータを生成することが特に重要で、不適切に生成されたデータを後工程で調整するのはコストが過大になるか不可能になる
という2点になります。
データはどこにあるのか?
データが組織に分散していることは「サイロ化」と呼ばれますが、原則としてデータはそれぞれの目的でのシステム運用のために管理されるのが第一義であり、下記のような種別があります。
| 種別 | A)自社サービス運用のための自社管理DB | B)特定業務のための外部のサービス提供者管理DB | C)データ取得/提供のための外部システム | D)非DBデータ |
|---|---|---|---|---|
| 例 | trocco®のサービス提供のためのDB | チャットツール、MA、SFA | Google Analytics、IoTセンサー、データ提供のAPI | Excel、PDF、ウェブスクレイピング取得データ、オンラインストレージ |
| 目的 | サービスの運用を確実に行うため | 業務運用を円滑に行うため | データの生成/取得のため | 手元でデータを確認/変更するため、アドホックなデータ取得 |
| 主な管理者 | バックエンド・インフラエンジニア/情報システム部門 | サービス提供者/運用管理者 | サービス提供者/運用者 | チーム、個人 |
| DBへのアクセス | 可能だが限定されている | API/ファイルダウンロード | API/ファイルダウンロード | 連携には設計が必要 |
| 生成 | データ生成のための機能追加 | データ生成のための設定 | データ生成のための設定 | 場合による |
| 抽出 | API経由での取得 | API/ファイルダウンロード | API/ファイルダウンロード/プログラム | 場合による |
| その他 | データベースへの負荷はNG | 利用ユーザーの運用フロー整備も重要 | IoTなどハードウェアが絡むものは幅広い知識が必要 | 場合による |
以下では、それぞれのポイントについて簡単に取り上げます。
A)自社サービス運用のための自社管理DBの難しさ
この種別では、サービスの運用のためのDBとなるので、DBの構造もサービス開発の歴史的経緯を必然的に伴うものになるのが特徴です。
- 開発初期に命名された/リレーション設計されたものが、後の時期になってくると適切とは言えなくなってきて、データ利用者にとっては理解が難しいものになっている
- 機能拡張に伴いカラムが追加され、一定時期以前ではすべてNullになっている/デフォルト値が入っている
- 顧客の状況を別システムで管理しているため、サービスDB内にデータはあるように見えるが正確にメンテナンスされていない
- サービス運用上は不要だが、データ活用を考えていたときに機能として開発しておいた方がいいものがある(例えばログデータなど)
- サービスの運用だけを目的にすると履歴データは不要だが、データ活用目的に使おうとすると履歴データが必要になる
- サービス運用目的でテーブルやカラムが変更され、分析用データパイプラインに障害が発生する
抽出という側面で考えると、下記のような考慮が必要になります。
- サービスの安定運用が第一義なので、本番DBに重いクエリを投げてサービス停止させるようなことは回避しなければならない
- マスターDBではなくリードレプリカのデータにアクセスする
- DBへのアクセスを限定して、DWHに抽出後のデータを利用するように促す
B)特定業務のための外部のサービス提供者管理DB
SaaSの利用が拡大してきている昨今の状況では、この種別に当てはまるものも増えてきているでしょう。種別にもよりますが、SFAが魔境と化すというのはあるある話です。部門のユーザーが設計変更をできてしまうことに起因して、データが負債化するのを避けるよう統制を利かせていく必要があります。
- 原則として標準運用をベースに設計することでそのサービスの価値を生かせるため、自由度が高いといって変にカスタマイズを行いすぎない
- 自社事例の記事ではありますが、「Salesforceの標準オブジェクトにこだわりながら、SaaSビジネスで活用する方法とメリット 」については本当にその通りだと最近痛感しています。
- 合わせて運用も適切に設計しないと、標準オブジェクト間で適切なデータ連携がなされずに分析をしようとしたときに泣くことになる
- 運用変更に伴いカラムが大量に追加されてきたなかで、認知負荷が爆増する
- どのカラムが現在利用されている/メンテナンスされているものかがわからない
- 論理名と物理名が一致しない(例:「x1__c」という論理名だけでは何もわからないカラム)
- 物理名にタイプミスがある
- データ型の設定が適切ではない
- システム間の自動連携機能を持っているSaaSも多いが、適切に運用しないと活用につなげるには必要なデータが足りないということになることも多くある
C)データ取得/提供のための外部システム
開発が伴うものなどは個別性が高いため、Google Analyticsに関連したもののみ取り上げておきます。
- 意外と取得のための設計がややこしいことがある
- タグの管理や発火のための設定など
- マルチドメインの取扱い
- CVポイント
- 送客する側での適切な処理が必要になる
- 広告で遷移させるURLにUTMパラメータを仕込んでおくなど
D)非DBデータ
この種別もかなり多岐にわたるので、Excelに関連したもののみ取り上げておきます。
- DBではないのでスキーマが事前定義できない
- 電話番号の0飛びが発生したり、カラムに対して不正レコードの記入が行われたりする
- 日付が入っている欄に、「未確定」(文字列)が入力される
- 人間が手を加えることで、行や列を削除してしまったり、ファイルを違う場所に移動や削除してしまったりする
- 電話番号の0飛びが発生したり、カラムに対して不正レコードの記入が行われたりする
データ抽出手段としてのAPI
先ほどの一覧表でDBへのアクセスや抽出手段として、APIと記載をしていました。データ連携の処理としてはこのAPIを利用することが多いのですが、これが一体どういうことかを解説しておきます。
APIとは何か
APIとは、Application Programming Interfaceの略であり、ソフトウェアコンポーネント同士が互いに情報をやり取りするのに使うインターフェースのことです。決められた仕様通りに依頼を出すと、決められた処理をしてくれるもので、例えば窓口に行って仕様通りの書類を提出すると、決まった処理をしてくれるようなものと考えればいいでしょう。
自分が過去に書いた記事でも、「初投稿のPVが爆増したのがtrocco®とQiita APIでよくわかった話」でQiitaの記事データを取っているのはtrocco®でQiitaのAPIを叩いているものですし、「Google Apps Scriptでデータを組織に流通させる:①BigQueryにクエリを叩いてSlackに投稿する」でSlackの投稿をしているのは、Google Apps ScriptでSlackのAPIを叩いているものです。
APIの概念自体はデータ抽出目的に限定されませんが、特にデータ抽出という観点に絞れば、こういう定義のデータが欲しいというリクエストを出すことで、対象のデータというレスポンスが返ってくるというものになります。

(出典:筆者作成)
また、なぜAPIを設置するかというと、APIがなければ個別開発をすることになりますが、それは利用者に多大なコストを強いてしまうことになるからです。サービス提供者としては、外部からアクセスし利用するための窓口を設計しておくことで、他サービスからの連携を行う際の開発コストを下げ、サービスをより利用しやすくしているのです。
データ抽出におけるAPI
QiitaのAPIを例にあげると、https://qiita.com/api/v2/itemsは最新の記事データを返すAPIになっており、このURLにアクセスするとQiitaの記事データが返ってきますし、https://qiita.com/api/v2/items?query=troccoにアクセスすると?以下のクエリパラメーターで指定をしている通り、「trocco」でキーワード検索をした結果に限定した記事データが返ってきます。
なお、上記の例では認証をかける必要がないので単純なものになっていますが、セキュアにデータを取得するためには、別途接続にあたって認証を行いながらデータを取得する形になります。
データ連携を考える上では、このように各種のサービスのAPIを叩くことでデータを取得し、別のシステムに連携をしていくことが多く行われます。
APIでのデータ抽出がなぜ大変なのか
個別開発と比べると著しく楽になったとはいえ、APIでのデータ抽出の管理が大変であることも多くあります。その理由として、下記のようなことが挙げられます。
- API仕様を理解しないとリクエストを投げられないので、抽出したいシステムの数だけAPIの仕様を理解しなければならない
- API仕様はサービス提供者によって変更されることがあるので、その場合は仕様変更を検知してプログラムの修正を行わなければならない
- API仕様によっては利用に制限がある(Rate Limitや不正レコードの際の挙動)場合があり、リカバリの処理が必要になる
- そもそもネットワークを介してAPIにアクセスしにいくと、ネットワークの状態によってエラーが発生することがある
このような煩雑な対応がありますし、そもそもデータを抽出しただけでは事業価値を何も生み出していないというのもあり、データ抽出をtrocco®のようなマネージドサービスに任せることは、データ取得を安定運用することで、よりデータ活用に近い方にリソースを割けるという意味があるわけです。
この点の詳細については、MarketoのBulk Extract APIを例に別途記事をまとめていますので、ぜひそちらもご参考ください。
データ転送方式としてのBulkとStream
データ転送の方式には大きく分けて下記の2つがあります。
- Bulk:一定期間でまとめてデータを処理
- Stream:データが発生したら随時データを処理
BulkとStreamの使い分け
これらの使い分けとしては、原則Bulk、要件上どうしても必要ならStreamというのを考えればいいでしょう。というのも、Streamではデータを随時処理していくため、Bulkと比べると実装難易度が高まったり、障害発生時のリカバリの対応が複雑になったりするからです。
実際、データ活用を考えたときに、Streamでないと要件を満たせないというのはそれほど多くもないでしょう。少なくともBulkで転送頻度を上げる形で満たせるような方法を考えていくのが検討時の初手としては良さそうです。
BulkとStreamのOSS
データ領域ではOSS(Open Source Software/ソースコードが公開されており、無償で誰でも自由に改変、再配布が可能なソフトウェア)が多いですが、BulkとStreamではそれぞれEmbulkとFluentdが広く使われています。実は、trocco®のコア機能はEmbulkのマネージドサービスであることにあります。
データエンジニアリングを考えていく上では、OSSやマネージドサービスをどう使っていくかというのは論点になりますので、その点について簡単に整理しておきます。ソフトウェアサービスの運用環境には、大きく分けてオンプレミス/IaaS/PaaS/SaaSの4つがあります。
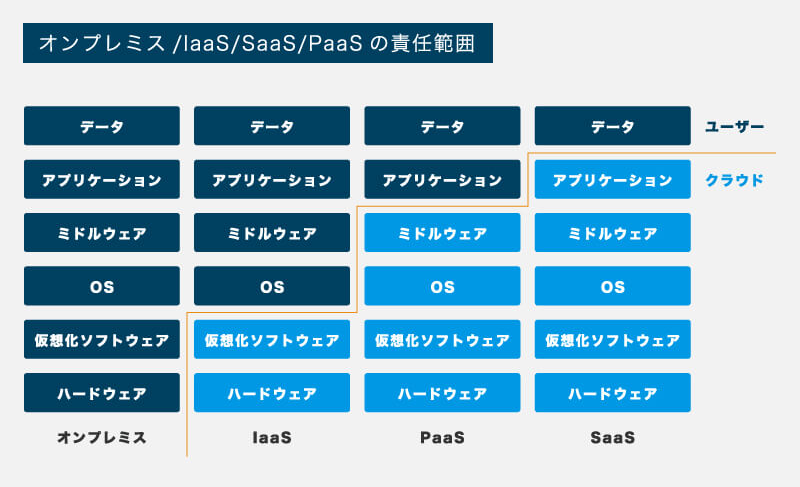
(出典:「クラウド入門!IaaS、PaaS、SaaSの違い」)
この図で整理されている通り、運用環境を誰がどこまで管理するかということが異なる点になります。OSSを自前で運用していこうとすると、今ではIaaSやPaaS環境で利用することになるでしょうが、そうするとソフトウェアの実行環境を整備する必要が出てきます。それらのメリット/デメリットは下記の通りです。
- メリット
- OSS自体の利用料はかからない
- 自身のユースケースにより適合した活用ができる
- デメリット
- 運用環境の利用料はかかる
- 構築に一定以上のスキルの人材と時間を要する
- OSSの変更に合わせて自身の環境も更新していく必要がある
構築開始からのリードタイム、運用コスト/要求人材レベル、ユースケースを踏まえて考えていくのがよいでしょう。またその際に、労働市場においてデータエンジニアは希少人材でもあるので、人件費との比較でマネージドサービスを検討するというのは1つの基準になるでしょう。
Streamの実装方法
Streamの実装としては、メッセージキューサービスを利用して疎結合にデータ自体をリアルタイム転送していく方法が代表的です。これは、抽出元のシステムと格納先のシステムを直接連携させてしまうと、ハンドリングが難しくなるため、その間で一時的にデータを保管する場所(なのでメッセージ「キュー」サービス)を準備するという考え方です。
また、CDC(Change Data Capture)という方法も利用されます。CDCではソースDBのデータの変更ログを連携することで、データを直接連携するのではない形で、転送先でデータ変更を反映していくという仕組みです。
また、全てStreamで取り扱うのではなく、Bulkと組み合わせるという設計も考えられます。少し前の記事にはなりますが、ZOZOでは日次のBulkと直近のStreamデータを組み合わせることで、リアルタイムのデータを利用可能にしているそうです。(参考:「全社共通データ基盤を廃止して新しいデータ基盤に引越した話)
これは、Stream処理に起因するデータの不整合のリスクを低減するために、過去分についてはBulkで間違いのないデータを取得し、最新のものはBulkでは取得できないためStreamで補完するという考え方になっています。
②データの格納と加工
次に、ソースシステムから抽出したデータの格納と加工について取り上げます。詳細に入る前にポイントを押さえておくと、
- 大規模データ処理にはDWHが向いている
- ELTと3層構造で、処理の役割を切り分ける
- 冪等性を担保するようにデータ処理を組む
- ワークフローで処理を連携させる
ということになります。
RDBとDWHの比較
前提として、抽出したデータを格納する場所としては、オブジェクトストレージやDWHがあります。オブジェクトストレージはファイル形式を問わずにファイルを保存できるストレージであり、DWHは分析目的のデータを保存するストレージです。
また、データの種別には下記の3種類があります。
| 観点 | 構造化データ | 半構造化データ | 非構造化データ |
|---|---|---|---|
| 形式 | 表形式に表示できるもの | 表形式にはできないがデータ自体に構造があるもの | データに構造がないもの |
| 例 | DBのテーブルやCSV | JSONやXML | 音声や画像 |
| オブジェクトストレージでの保存 | 可能 | 可能 | 可能 |
| DWH | 可能 | 可能 | 概して不可能 |
このうち、左2つであればDWHにそのまま格納してしまうことも多く、データ基盤構築の初期フェーズではまずそこから取り組み始めると考えられるので、この場ではオブジェクトストレージや非構造化データは想定しないものとします。
その上で、先の説明でサービス運用のためのDBとなることの多いRDBと、DWHとの比較を示します。
| 観点 | RDB(Relational Database) | DWH(Data Warehouse) |
|---|---|---|
| 目的 | トランザクション管理 | 大規模データ分析 |
| 要件 | データの正確性 | データ処理のパフォーマンス |
| 特性 | 行志向(行単位の挿入、更新、削除等を確実に行う) | 列志向(列単位のデータ集計を高速に行う) |
| サービス例 | MySQL、PostgreSQL、SQL Server | Google BigQuery、Amazon Redshift、Azure Synapse Analytics、Snowflake |
| 正規化 | 行うのが原則 | 行わない(大福帳やスタースキーマ)ことが多い |
ポイントとしては、RDBではデータを正確に保持しそれに基づいた処理を処理を実行できるように、DWHでは大規模データを高速に集計できるようにと、異なる目的に即して設計されているということです。
その目的として行われるデータ処理も、RDBでは行単位の更新が基本なのに対してDWHでは列単位の集計処理が行われ、これが特性の違いの背景にあります。こういった違いがあるため、活用のためのデータ基盤はDWHが利用されることになります。
なお、RDBではトランザクション管理という機能でデータの正確性を担保しています。その前提として、テーブルの正規化(テーブル分割により冗長性の削減)や、テーブル間の関係性(主キー/外部キー関係)の定義があり、それらをベースにした各種の制約(主キー制約、参照整合性制約、一意性制約、NOT NULL制約、チェック制約)やトランザクション保護の仕組みがあります。
DWHでも制約の定義は可能ですが、トランザクション管理の機能はないことはもちろん、データ転送のタイミングによって不整合が発生することは避けられず(例えばトランザクションデータの転送時刻がマスタの転送時刻よりも後だと、マスタに照合できないトランザクションデータが発生する)、RDBにおけるような厳密な整合性担保は難しいことを念頭に置いておく必要があります。
『[入門]はじめてのデータベース』はRDBの基礎を把握するのにおすすめの書籍ですので、そもそもRDBを初めて聞いたという方も流し読みしておくと参考になるでしょう。
また、OLAP(Online Analytical Processing/DWHのこと)の特性については、高速化の観点であり内容もやや難しいですが、「OLAPデータベースにおける高速化の技術」の記事が良くまとまっていました。
データをどのように格納/加工するのか?
では、ソースシステムからDWHへはどのようにデータを格納し、またどのように加工するのでしょうか。はじめにエンジニアリングの基礎的な考え方についておさえた上で、重要な考え方を取り上げていきます。
「分割して連携せよ」という考え方
ソフトウェアエンジニアリングの考え方のなかで、「単一責任の原則」という考え方があります。1つのモジュールに複数の処理を任せると、そのモジュールや関連するものに対する影響関係が複雑になるため、小さく分割して設計せよという考え方です。
データエンジニアリングでもここは同じで、目的が違う処理を一つに入れ込むとその部分の調整の難易度が高まるため、小さく切った処理を連携させていくような設計を取ります。具体的には、転送や加工を小さい部品に切り分けて、ワークフローで連携させることで処理を進めていくという形です。
ETL/ELT
データの転送と加工には、ETL/ELTという2つの考え方があります。その内容について下記にまとめます。
| 観点 | ETL(Extract/Transform/Load) | ELT(Extract/Load/Transform) |
|---|---|---|
| 概要 | ソースシステムから抽出後に、加工してからデータを格納する | ソースシステムから抽出データをそのまま格納し、その後にDWHのコンピューティングリソースを活用して(SQLで)データ加工する |
| 利点 | ストレージコストがかからない | ローデータをコピーする形なので、処理に問題があった際のリカバリが容易 |
| 概念図 |  |
 |
(図表出典:筆者作成)
かつてはストレージコストが高く、DWHのコンピューティングリソースが貧弱だったのもあり、ETLの形式が中心ではありました。しかし現在では逆にストレージコストが下がりDWHのコンピューティングリソースが強化されたことで、リカバリの容易性も合わせてELTの形を取られることも多くなっています。先ほどの考えを踏まえると、転送と加工という違う目的の処理を切り分けて取り扱うような形です。
また、ETLとして多少の加工を入れることもありますが、それには例えば下記のようなものがあります。
- データ型の調整やカラム名の統一化などの微調整
- 取扱い注意な個人情報等のデータをそのままDWHに入れたくない場合(ハッシュ化/マスキングで処理)
- SQLでは難しい処理をスクリプトで処理する
加えて、転送時刻のカラム(transferred_atなど)を追加しておくのも役立つ方法です。これをしておくと、転送先でデータの鮮度がどうなのかを判別できるようになります。
なお、trocco®は設計上ではELTを基本にしていますが、データ転送のための他のツールと合わせて「ETLツール」と呼ばれることがあります。
またtrocco®におけるELTのTである「データマート定義」では、trocco®でデータ加工をするのではなく、SQLクエリをAPI経由でDWHに投げることで、DWH側で加工処理が行われています。システム間でデータを移動するデータ転送とは行っている処理が全然違うことがポイントです。
SQLの学習については別途記事を書きましたので、そちらもご参考ください。
データ加工の3層構造
格納したデータを加工していく流れとして、3層構造の考え方があります。そのとき、3層とは下記のようなものです。

(出典:筆者作成)
| 観点 | Data Lake(層) | Data Warehouse(層) | Data Mart(層) |
|---|---|---|---|
| 目的 | ソースデータの保持 | 複数用途への利用 | 単一用途への利用 |
| データの性質 | ソースシステムから抽出したデータを無加工で格納 | ある程度共通化できるレベルまで加工/統合したデータ | 特定用途に特化した形に加工したデータ |
| 備考 | オブジェクトストレージの場合もある | どのような設計にするかは場合による | 特にBIでは参照データを適切に設計すると、表示のパフォーマンスが向上する |
テーブルデータをベースにするのであれば、これらはDWHのなかに別のテーブルとして保持することが多くあります。サービス内でテーブルを層として分けて利用するという形です。Lake層をオブジェクトストレージに置くのも良くある方法です。
これらを実際にどう設計するかは完全にケースバイケースになってしまいますが、少なくともこのような設計をしている背景としては、ソースデータの保持と、共通利用するための前処理と、特定用途に特化した追加の処理を切り分けたいからという考え方があります。ここを切り分けることで、再利用性を高めて加工のコストを下げたり、指標を共通化することにつながるというわけです。
3層構造に加えてのstg層
先ほど取り上げた3層構造に加えて、stg層というData Lake層に1:1対応する層を設けることもしばしば行われています。これは、ソースシステムによって取得できるデータに差異があるからが要因で、例えば下記のような処理をすることが考えられます。
- カラム名記法の統一:スネークケース、キャメルケースなど
- カラム名の統一
- データ型の統一
- 論理削除データの除外
ここでは、ソースデータの仕様に依存するデータ仕様の差異を吸収するのが目的になります。
日時に関わるデータ型
データ型の統一に関連して、日時データをどのように保持するかというのがあり、ソースシステムやDWHの仕様によって差異があります。具体的には、
- timestamp:UTC定義でタイムゾーンを持たないもの
- datetime:特定のタイムゾーンの日時で、タイムゾーンを持つ場合と持たない場合がある
- date:同上
などです。これらをどう処理するかは悩みどころですが、ソースシステムではtimestampで保持されていることも多いため、基本的にデータ基盤の管理としてはtimestampに統一して、利用に近いところで必要に応じてタイムゾーンに合わせた形で変換するのが良さそうではというのが現時点での自分の考えです。
日時データを持つときの命名規則も整理の際には大切であり、
- timestamp:hogehoge_at
- datetime:hogehoge_at_jst
- date:hogehoge_date(タイムゾーンが自明な場合)/hogehoge_date_jst(タイムゾーンが非自明な場合)
のような命名規則が個人的には良さそうです。
なお、サマータイムが混在するとその考慮は大変なことになりますので、グローバルなデータを取扱う際にはご注意ください。またクライアントとサーバー間でラグがあることや、旅行の際にJSTの設定のまま別のタイムゾーンに移動しているものをどう処理するかなど、きちんと考えようとすると結構な沼になります。まずは深入りしすぎずにですね。
冪等性と洗い替え/追記/差分更新
データパイプラインを構築していくときの重要な概念として、「冪等性(べきとうせい)」があります。これは、「ある操作を何度行っても同じ結果になること」を意味しています。
めちゃくちゃ大事な考え方なのでもう一度記載すると、
データパイプラインを構築していくときの重要な概念として、「冪等性(べきとうせい)」があります。これは、「ある操作を何度行っても同じ結果になること」を意味しています。
データエンジニアリングの文脈で言い換えると、
データ処理を行った際に、
- データの欠損が生じない
- データの重複が生じない
処理ができていれば、その処理は何度行っても同じ結果になり、冪等性が担保される
と言えます。
転送/加工したデータからテーブルを作成するときには、主に下記の3つの方法があります。
- データの洗い替え(Replace)
- データの追記(Append)
- データの差分更新(Upsert/Merge)
冪等性の観点を踏まえつつ、具体的なデータ処理を考えてみましょう。
データの洗い替え
データの洗い替えでは、全てのデータを削除して新たにデータを作り直すため、このままで冪等性が担保されます。
データ転送を行う際には、これに加えてもう一つ裏側の仕組みがあります(これは追記や差分更新でも同じ)。それは、
- ソースシステムから抽出したデータを一時テーブルに格納する
- 抽出したデータが間違いなく処理されているかを確認する
- 一時テーブルのデータをターゲットテーブルに転送する
- 一時テーブルを処理する
という流れで処理するということです。
なぜなら、ネットワークを経由してデータを取得してくる場合、何らかの要因で中途半端にデータを取得できてしまうことがあるからです。システムをまたぐデータの取得の処理と、システム内でのデータの移動を切り分けることで、冪等性を担保しているのです。
また、同じ洗い替えでも、テーブルを削除して同名のテーブルを作り直す方法と、テーブルからデータのみを削除してから挿入する方法があります。後者ではテーブルの設定がなくならないので、スキーマ情報が保持されたり、テーブルの補足情報がそのまま維持されます。場合によってはソースシステムのスキーマが変わることがあるので、その場合はエラーとなり検知することができるようになります。
データの追記
データの追記では、何も考えずにその処理を何度も行ってしまうと、その度にデータが重複してしまうことになります。そこで、抽出するデータを例えば前日に限定するなどの方法が考えられますが、この場合でも同日に2回実行してしまうと重複が発生してしまいます。
そこで、下記のような処理方法を行います。
- 指定期間のデータを抽出する(例えば昨日)
- 事前にターゲットテーブルのデータを削除する(例えば昨日以降のもの)
- 初回実行では削除するデータはなく、2回目以降は重複データが削除される
- ターゲットテーブルに抽出したデータを追記する
これで、何度行ってもデータの重複が発生しない形に処理できます。なお、IDをベースに追記していくものでも同じ考え方でできます。
このときに、「昨日」の部分をパラメーターで指定をしておくと、異常レコードがあったので過去からリカバリをしたいというときに、「1週間前」と指定することで1週間前からのデータのみを入れ替えて楽にリカバリをすることもできたりします。
また、この際の期間の指定はミスが起きがちなのでご注意ください。ソースシステムからの抽出で開始日と終了日を指定すると、UTCの開始日と終了日が指定されていて、一方で転送前に削除をする日付をJSTで指定してしまうというように、オフセットの違い起因でデータが重複or欠損するのはよくある話です。
データの差分更新
IDはそのままでその一部のカラムが更新されたり、あったレコードが削除されるようなときには、UpsertやMergeの処理が利用できます。
Upsertとは、Update(更新)とInsert(挿入)を行うための処理です。
- 条件に応じてレコードを抽出する
- ターゲットテーブルのIDと更新日時をベースに、下記の処理を行う
- 更新されたものはデータを更新する
- データがないものは挿入する
という流れで、データを処理することができます。
一方、ソースシステムでレコードの削除がある場合は、Deleteの処理も必要になってきます。MergeではUpdate、Insertに加えてDelete(削除)も行うことができます。
- 条件に応じてレコードを抽出する
- ターゲットテーブルのIDと更新日時をベースに、下記の処理を行う
- 更新されたものはデータを更新する
- データがないものは挿入する
- ターゲットテーブルからなくなったものは削除する
という流れで、データを処理することができます。
冪等性のまとめ
このように、データ処理にあたっては冪等性を担保するように設計していくことが非常に重要になります。ただし、後の方ほど実装が複雑になっていくので、データ量が少なくコストをそれほど気にしなくていい段階であれば、全部洗い替えで済ませてしまうのが一番シンプルな方法ではあります。
テーブル/マテリアライズドビュー/ビューの使い分け
加工したデータを保持する方法として、テーブル/マテリアライズドビュー/ビューの3つがあります。その違いは下記の通りです。
| 観点 | テーブル | マテリアライズドビュー | ビュー |
|---|---|---|---|
| データ | 保持する | 保持する | 保持しない |
| 元データの変更への追従 | しない | する | する |
データを保持する方がクエリパフォーマンスが高く、一方でデータ変更に追従する方が鮮度が高くなるという関係にあります。マテリアライズドビューは製品によっては利用できる条件が限定されているので上級者向けで、まずは業務要件を前提としたときに、テーブルの更新頻度を上げるか、ビューで済ませるか、転送元~利用先までの全体を考慮した上で選択するとよいでしょう。
ちなみに、鮮度やストレージコストを考えたときに、別の観点でも解決策はあります。それは、データ転送をなくしてしまえばいいのでは?ということです。実際これを実現する機能は、少しずつ実用化されてきています。
- RDBサービスとDWHサービスの自動連携(ETLツールを挟まないネイティブ統合)
- DWHからRDBへの直接クエリ(フェデレーテッドクエリ)
こうした方向性で機能が拡充していくのは今後も続いていくと思われますが、一方で利用するSaaSが増えてソースシステムが増加するのも生じていくでしょうから、データ転送をなくすというのは近いうちにはあまり考えられないように思います。
パーティショニング/シャーディング
クエリのパフォーマンスの向上やコストの低減を考える上では、データのスキャン量を減らすことが有益です。そのための方法として、パーティショニング/シャーディングという方法があります。
| 観点 | パーティショニング | シャーディング |
|---|---|---|
| データの分割 | 仮想 | 物理 |
| 例 | date_salesに応じて日付で分割 | sales_20231217というようにプレフィックスで分割 |
シャーディングではその分だけテーブルが増加していくというのもあり、現在ではパーティショニングを基本にして考えていくのがいいでしょう。このほかに、クラスタリングという方法もありますが、それはデータ量が増えてパフォーマンスに難が発生してから考え始めるのがよさそうです。
履歴データの保持
運用観点では現在の最新の状態が把握できればよいですが、分析観点では過去から状態がどう遷移してきたのかを知りたいということが往々にしてあります。そのために、履歴データを保持するのは1つの方法です。
前述したパーティショニングを利用して、同じデータを日次で追記し続けると、
- transferred_atをパーティショニングのキーに指定しておく
- 最新のデータを見たいときにはtransferred_atを最新日に限定する
- 過去のデータを合わせて推移を見たいときにはtransferred_atを見たい期間に限定する
ことで、用途に合わせて利用するデータ量を最適化しつつデータを活用することができます。
データ転送/加工の連動
転送/加工処理はここまでの話に即して、目的に分けたジョブとして設定していくため、最後にそれらの依存関係を定義して実行するワークフローを設計していきます。例えば、まず転送AとBを実行して、次に加工Cを実行して、最後に加工Dを実行するというようなものです。
データは定期的に更新したいので、毎日9時に起動するようにしたり、エラーが起きたときにはSlackに通知するようにしたり、エラー発生時には自動で10分後にリトライするようにしたり・・・、このような設定をすることで、データ転送/加工を自動化することができます。
個々のテーブル設計(DWHにおけるデータモデリング)
個々のテーブル設計まで入っていくと情報量が多くなりすぎてしまうので、有名なものを簡単にまとめたものとして、「データウェアハウスのデータモデリングを整理してみた」の記事を紹介しておきます。
また、こちらも発展的な内容にはなりますが、データの変更の処理方法として、「dbt snapshot から学ぶ Slowly Changing Dimension」の記事も勉強になります。
③データの提供と利用
ようやくここまでたどり着きました。データの加工が終わったら、後はそれを利用につなげていきます。ここでのポイントは下記の通りです。
- 分析目的に限定しても、ユースケースには幅がある
- データ活用は分析以外でも、システム間のデータ連携がある
データ活用の3つの方向性
データ活用にはデータ分析、機械学習への利用、リバースETLの3つの方向性があります。
| 類型 | 内容 |
|---|---|
| データ分析① | 完全アドホック分析(自由度の高い検討) |
| データ分析② | ダッシュボードによるデータの探索(自由度の低い検討) |
| データ分析③ | ダッシュボードによる定点観測(固定化された指標のモニタリング) |
| 機械学習への利用 | 学習/推論のための/推論結果の利用のためのデータ連携 |
| リバースETL | 他システムへの連携 |
データ分析については記載の通りなので割愛するとして、下の2つについて補足しておきます。
機械学習への利用
機械学習への利用と考えると、なかなか大それたことのように感じるかもしれませんが、最近ではBigQueryでも簡易な機械学習を利用できるようになってきており、シンプルな利用はそれこそtrocco®でも可能です。
データマート定義ではSQLクエリをDWHに投げる形になっていますが、SQLクエリで機械学習を取り扱える以上、trocco®で投げるクエリで機械学習が利用できるのです。
具体的な例としては、昨年のアドベントカレンダーでユーザー様による「trocco x BigQueryMLで実現するMLOps (時系列予測編)」という記事がありますし、今年は私の同僚がLLMの利用として「BigQuery × PaLM2・Cloud Natural Language API × troccoでLLMバッチ予測パイプラインを構築した話」という記事もあります。
リバースETL
リバースETLという言葉はあまり聞きなれない方も多いと思いますが、ソースシステムからDWHに転送するのをETLとしたとき、DWHから他システムに転送して戻すのをリバースETLと呼んでいます。ユースケースとしては、例えば以下のようなことが考えられます。
- 自社サービスのDBに連携して、サービスの運用のために活用
- 営業管理システム連携して、営業が日常的に確認できるように
- 広告サービスに連携して、広告成果を精緻化/パフォーマンスを最適化
- これは昨日「trocco によるオフラインコンバージョンインポート (GA4 + Google広告)」として記事にされていましたね。
さいごに
勢いに任せて書きすぎました。そしてもう少し書きたいことはあったのですが、さすがに分量が多すぎるので泣く泣く諦めました。とはいえ、この内容が1年前に自分が読みたかったことであるのは間違いないので、少しでも参考にしてもらえると嬉しいです。また、間違いや分かりにくいところがあれば、ぜひご指摘ください。
私は業務でフル活用してきたなかで「trocco®使うの楽しいしめっちゃ使えるぜ!」とずっと感じてきました。今回の記事を通して少しでもそう思ってくれる方を増やせるといいなと思っています。これまでもですが、これからも着々と機能拡充していきますので、今後のtrocco®にもご期待くださいませ!