はじめに
本記事は、TROCCO® Advent Calendar 2024 シリーズ2の22日目の記事になります。
骨太すぎたのでこちらは後半です。前半は「GitHub Actionsを月2,000分動かして学んだTerraform + TROCCO入門 前半:基礎から分かるTerraform」となっています!
昨年はデータエンジニアリング初心者から学んできたことをもとに、「1年前の自分が読みたかった、データエンジニアリング入門」を執筆し、もうすぐ40,000PV近くになるほど参考にしていただきました。
今年もまた骨太な記事を書こうとテーマを考えていましたが、今回はTerraform初心者からの経験をもとに、サンプルリポジトリ付きのTerraform + TROCCO®の入門記事を執筆することにしました。Terraformの解説の方が遥かに分量が多いので、TROCCO®を知らない/興味のない方でも参考にしていただけると思います。
Terraformはなかなか勘所を掴むのが難しく、特にCI/CDまで絡むとなおさらで、直近1か月でGitHub Actionsの無料枠である2,000分/月を溶かし切ってしまいました。私が溶かした時間を、みなさんのために捧げたいと思います。

サンプルリポジトリは以下で公開しています。
ちなみにTROCCO®としては、8月にTerraform Provider for TROCCOが公開され(参考:「TROCCO®のTerraform Provider(β版)ができたので最速で触ってみる」)、これから対応リソースが増えていくタイミングになっています。
こんな方におすすめ
- TROCCO®に関わらずTerraformが気になっているが、なんだかよくわかっていない方
- GitHub ActionsとGoogle CloudのWorkload Identity Federationについて実装コードを確認したい方
- TROCCO®でTerraformという話が出てきて、どういうものか気になっている方
- 普段からTerraformを活用していて、TROCCO®での活用を検討している方
- 勢い余って書きすぎたため、Terraformを基礎から解説している初心者向けの記事と、CI/CDを含めた運用を取り上げた中級者向けの記事に分けています
- 本記事ではGitHubの利用を前提にしていますが、Git/GitHubの利用方法まで記載すると大変なことになってしまうので、説明は割愛しています
- TROCCO®でのTerraform活用については、Advancedプランから利用できるTROCCO APIが前提になり、かつ現時点で対応しているリソースは一部になる(鋭意拡充中!)のにはご留意ください
まだ経験が浅いので、記載内容が誤っている/もっとこうしたらいいということがあれば教えていただけると大変ありがたいです!!!
TerraformのCI/CDを考える
前半の記事で、Terraformの挙動はなんとなく理解できたと思います。ここからは、実際運用に乗せるにあたって必要になる、CI/CDについて考えてみましょう。なお、こちらはある程度エンジニアリングの知識が必要になってくるので、やや難しい(かつ前半ほど解説は丁寧ではない)ものになっています。
前段の解説が長いので先に概要を紹介しておくと、以下のような形を組んでいきます(そしてこれだけでもない)。
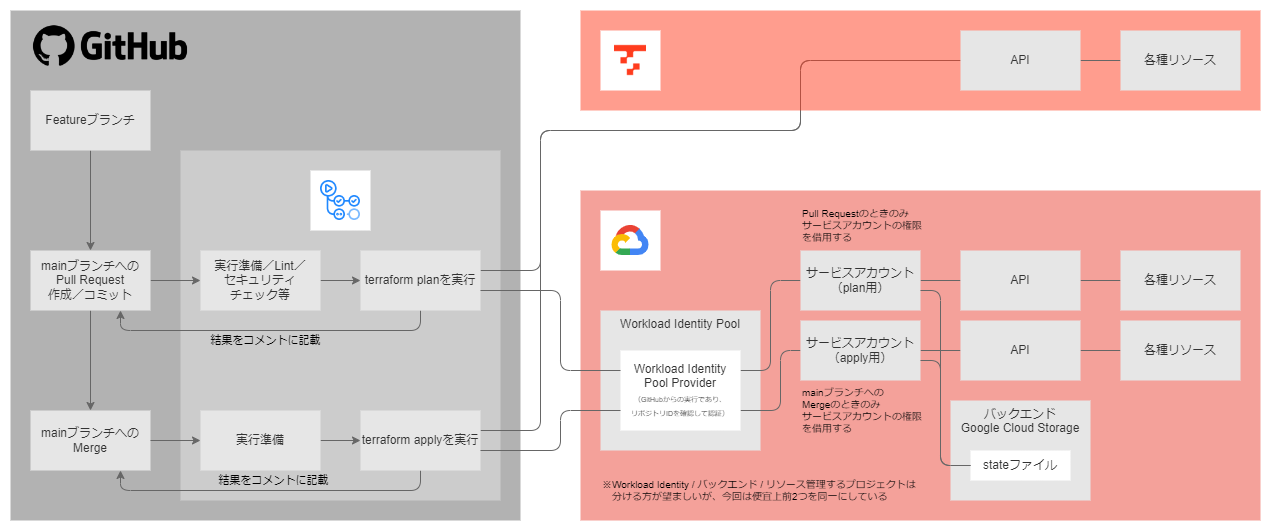
CI/CDとはなにか
CI/CDについて、Forkwell Library#67「持続可能なソフトウェア開発を支える『GitHub CI/CD実践ガイド』」の発表スライドでは、以下のように説明されています。
- CI:Continuous Integration/継続的インテグレーション
- コードの変更を頻繁にコードベースに統合し正しく動作するか繰り返し検証する
- CD:Continuous Delivery/継続的デリバリー
- いつでも安全にリリースできる状態を保ちソフトウェアを繰り返し改善する
CI/CDの具体的な内容や関係性は下記の図の通りです。
なお、今回はツールとしてGitHub Actionsをベースにしていますが、その理解にもそうですし、CI/CDを基礎からおさえるにも以下の書籍はめちゃくちゃ勉強になります。
講演の概要は記事にまとまっていたので、こちらもぜひ参考までに。
なぜTerraformでCI/CDが重要か
Terraformの運用において、CI/CDが重要なのはなぜでしょうか。前半の説明のなかで簡単に触れましたが、改めて整理しておきましょう。
- TerraformのstateファイルをSSOTとして扱えるように、実行場所を一元化しておく必要がある
- planとapplyを上手く使い分けて、実行を適切に制御する必要がある
- TerraformのコードのLintやセキュリティチェックをかけるのが望ましい
- 例えばGitHubから実行するとしたときに、GitHubからオブジェクトストレージに保管されているstateファイルにセキュアな認証認可をかける必要がある
- 実行にあたって、リソースを作成するための権限を適切に管理する必要がある
- 依存するライブラリの脆弱性を把握して対応する必要がある
以下ではもう少し詳細に説明します。
実行場所の一元化
stateファイルをクラウドストレージで管理するのはもちろんですが、実行をローカルではなくCI/CD側に寄せる必要もあります。これは運用ルールとして設定するのもそうでしょうし、そもそもアクセス権は絞った方がいいというのもあり、権限管理上制限してしまうことも必要でしょう。
実行制御/Lint/セキュリティチェック
Terraformでは、mainブランチと開発作業用のfeatureブランチの2つに分けるシンプルな開発フロー(GitHub Flow)にすることが多くあります。このとき、mainブランチにプルリクエストを上げたときにplan結果を確認して、mainブランチにマージするとapplyを実行してもらうという形が多く行われているようです。
加えて、plan時にテストが落ちていたときにマージしたらどうするか、関連する開発が並行で進んでいたときにどうするのがいいのか、関連する別のfeatureがマージされたときにどうするかなど、考慮が必要なことは多くあります。
Lintやセキュリティチェックは、前者はチーム内で書き方を統一して認知負荷を下げるためにあると望ましいものですし、後者はクレデンシャルをハードコードしていないかから、デフォルトでセキュリティにリスクがある状態になっていないか(例えばGoogle Cloudでプロジェクトを作成するとデフォルトネットワークが自動作成される)を検知することができます。
色々考えることはありますが、suzuki-shunsukeさんが開発しているtfactionに乗っかれば大抵のことができます。めちゃくちゃ便利で感動しました。
導入企業の記事として、以下のようなものがあります。
- 株式会社tacoms(直近12/16の公開記事!!)
- 株式会社Gunosy
- 株式会社Luup
- 株式会社リクルート(スタディサプリ) ※suzuki-shunsukeさんの記事
TROCCO®でもインフラ運用のベースとして活用しており、グローバル展開に向けた動きでもtfactionを活用していくことを念頭に置きながら対応が検討されていました。
では、その挙動を簡単に見ていきましょう。プルリクエストを上げるとplan結果をコメントに記載してくれます。
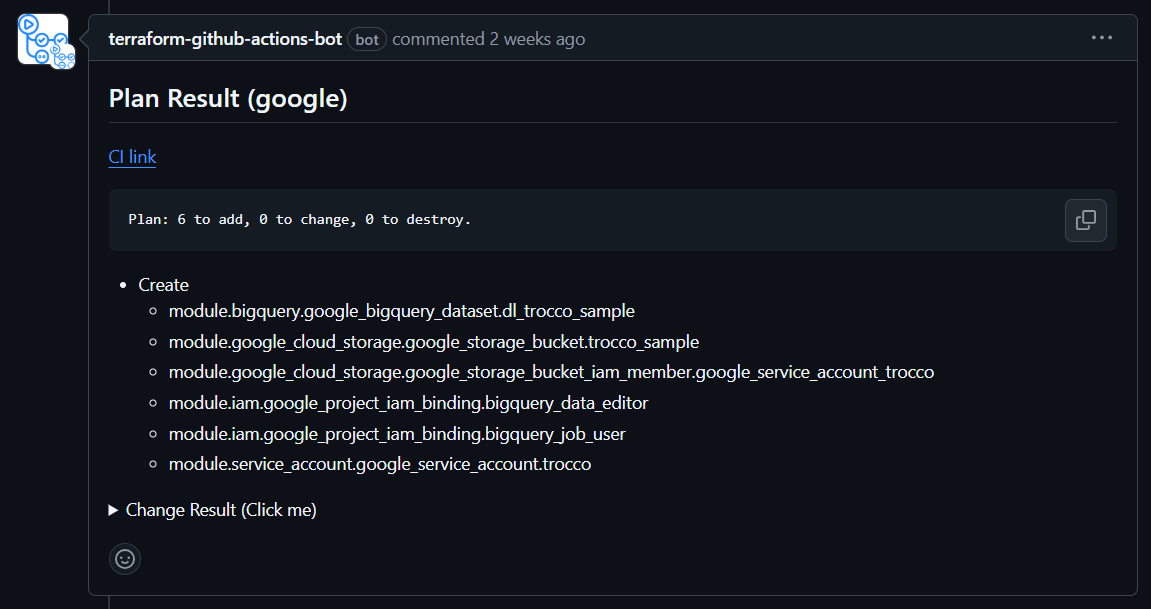
マージするとapply結果をコメントに記載してくれます。
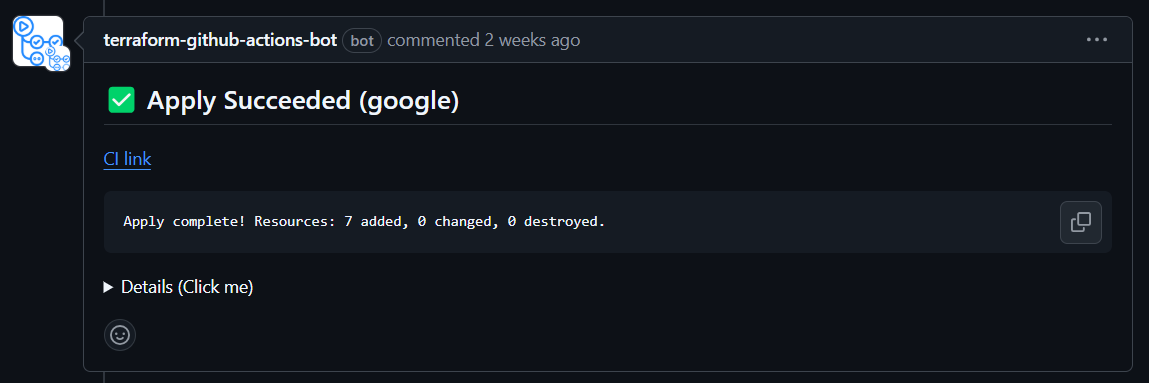
なんだこれ便利かよ・・・!!
ちなみに、planの際にセキュリティチェックをかけることもできて、怒られている例が以下の通りです。
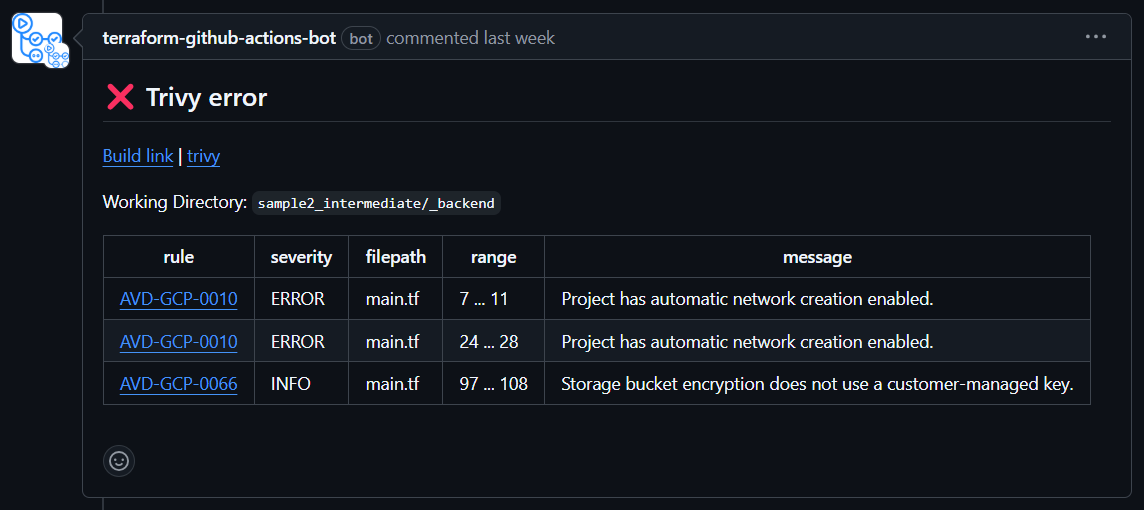
デフォルトネットワークの設定とか、指摘してくれてありがとう、気が付きませんでしたという気持ちです。
なお、Terraform自体のLint/セキュリティチェックに加えて、GitHub Actions自体のLint/セキュリティチェックのためにActionlintというものも設定しています。
認証認可
これまでの認証認可では、アクセスキーを利用したものが多く行われていました。しかし最近は、キーを利用しないような形が推奨されています。
今回のサンプルでは、Workload Identity Federationというものを活用しています。これは、実行場所がどこで、どういう実行内容なのかというのに対して、権限を付与する形になっています。
実行場所がGitHubの特定のリポジトリで、Pull Requestを上げたときという条件の実行に対して、planに必要な権限を付与して、mainブランチへのMergeであるときという条件の実行に対して、applyに必要な権限を付与しています。
なお、サンプルで設定している権限はやや雑になっていますが、本運用では最小限に限定するようにしましょう。
依存ライブラリの管理
ライブラリは時間を経て更新されていくので、ソフトウェアを適当に管理していると依存ライブラリがアップデートされ、何もしていないのに壊れます。そこで、依存ライブラリのバージョンを固定する必要があります。サンプルではCLIの管理ツールであるaquaを利用して、バージョン管理をしています。
一方で、バージョンを固定していると、脆弱性が検出されたときにそれを放置したままになりかねません。そこで、バージョンアップや脆弱性リスクを検知した上で、定期的にバージョンをアップデートしていく必要があります。それに便利なのがRenovateというGitHub Appです(GitHubにデフォルトでついているDependabotも似たツールです)。
Renovateは、新しいバージョンが公開されたときにそれを通知してくれることはもちろん、プルリクエストの自動作成や自動マージまで対応しています。関連する更新を1つのプルリクエストをまとめることもできます。
メジャーアップデートでは破壊的変更が入ることがあるので、マイナーアップデートのときでは自動マージまでして、メジャーアップデートではプルリクエストに留める、というようなこともできます。なんだこれ便利すぎるのでは。
余談ですが、TROCCO®を開発しているリポジトリを見たときに、いつもパッケージのバージョンが最新になっているのはなんでだろうと不思議に思っていたのですが、これはこういう仕組みだったようです。なるほど!!
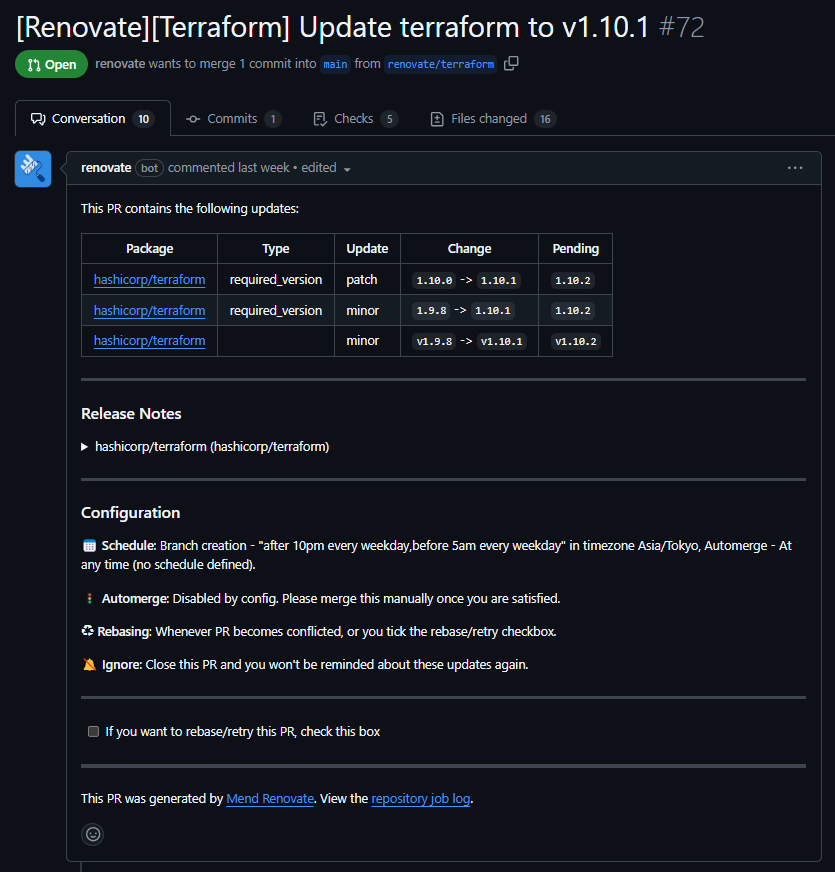
さて、Renovateを利用すると、以下のようなプルリクエストが上がってきます。リリースノートが記載されており(開くと詳細が見られる)、ファイルが16個まとめて更新された状態のプルリクエストになっています。便利すぎて感動します。
aquaとRenovateについては、suzuki-shunsukeさんが入門記事をまとめています。
ここまでsuzuki-shunsukeさんへの便乗感がすごいですが、それだけすごい方だということで・・・w
ツールの使い方を考える
データエンジニアはデータのことに集中したいので、OSSやマネージドサービスを利用することで、手組みするとややこしいものをいい感じに扱ってもらえるのはとても助かるでしょう。特にインフラの経験があまりなくても、リソース的にそこまでやらないといけないことはよくありそうなので、OSSなど便利なツールをどう使うかは非常に重要になりそうです。
一方で、OSS自体にリスクがあることを認識しておくことも重要です。今回言及しているものについては、自社も含め複数の企業が活用していることで信頼して取り上げていますが、利用者が少ないものは利用を避けること、利用する際には権限を限定することなど、適切なリスク管理/リスク認識のもとで活用するように注意しましょう。
リポジトリを保護する
なお、CI/CDの実装に加えて、リポジトリ自体の保護も重要になります。今回は検証の想定なのでかっちり固める必要はありませんが、
- リポジトリを絶対にパブリックにしない
- mainブランチへ直接コミットできない/レビューを必須にするなどブランチの保護ルールを設定する
- 署名コミットを必須化する
など、GitHubでの設定も考慮すべきポイントとしてあります。
サンプルリポジトリ解説その2:中級「GitHub ActionsによるCI/CD構築」
前置きが長くなったところで、サンプルのリポジトリの./sample2_intermediate/を参考にしながら、CI/CDまで含めた運用を考えていきましょう。地味なハマりどころがところどころあるので、スムーズに進めてもらえるかは自信がないです、すみません(泣)
そして多分リポジトリをクローンしてブランチを切ってPull Requestを上げてMergeしてとすればいいと思うですが、そこまで検証できていませんすみません・・・
さて、今回のディレクトリは以下のような構造になっています。
.
├── .github
│ └── workflows
│ ├── actionlint.yaml
│ ├── hide_comments.yaml
│ ├── terraform_apply.yaml
│ └── terraform_plan.yaml
├── sample2_intermediate
│ ├── _backend
│ │ ├── _resources.tf
│ │ ├── .trivyignore
│ │ ├── aqua.yaml
│ │ ├── locals.tf
│ │ ├── provider.tf
│ │ ├── README.md
│ │ ├── tfaction.yaml
│ │ └── versions.tf
│ ├── google
│ │ ├── _resources.tf
│ │ ├── .trivyignore
│ │ ├── aqua.yaml
│ │ ├── locals.tf
│ │ ├── provider.tf
│ │ ├── README.md
│ │ ├── tfaction.yaml
│ │ ├── train.csv
│ │ └── versions.tf
│ ├── trocco
│ │ ├── modules
│ │ │ ├── account_management
│ │ │ │ ├── _resources.tf
│ │ │ │ ├── provider.tf
│ │ │ │ ├── README.md
│ │ │ │ └── variables.tf
│ │ │ ├── connection
│ │ │ │ ├── _bigquery.tf
│ │ │ │ ├── _snowflake.tf
│ │ │ │ ├── provider.tf
│ │ │ │ ├── README.md
│ │ │ │ └── variables.tf
│ │ │ ├── datamart
│ │ │ │ ├── _bigquery.tf
│ │ │ │ ├── provider.tf
│ │ │ │ ├── README.md
│ │ │ │ └── variables.tf
│ │ │ └── transfer
│ │ │ ├── _resources.tf
│ │ │ ├── provider.tf
│ │ │ ├── README.md
│ │ │ └── variables.tf
│ │ ├── _modules.tf
│ │ ├── aqua.yaml
│ │ ├── locals.tf
│ │ ├── provider.tf
│ │ ├── README.md
│ │ ├── tfaction.yaml
│ │ └── versions.tf
│ └── README.md
├── .gitignore
├── .terraform-docs.yml
├── aqua.yaml
├── github-comment.yaml
├── README.md
├── renovate.json
└── tfaction-root.yaml
ここからの内容については以前の記事「まともなTerraform環境構築に向けたあれこれ:バックエンドGCS、Workload Identity直接アクセス、tfactionによるCI/CD」で(雑に)まとめたものがベースで、当時ドキュメントを読み漁りながらめちゃくちゃ苦労して試行錯誤していたものが、Terraformでは(上手くいけば)爆速構築できてしまうようになっています。
また、各種ファイルを編集するので、VSCodeをご利用の方は、
の拡張機能をインストールしておくと楽です。
このサンプルでできること
色々できます。というか詰め込みすぎなのでは(苦笑)
- tfactionを利用してできること
- Pull Request時のplan内容のコメントへの記載、Merge時のapply内容のコメントへの記載
- Lintや脆弱性チェック
- 実行状況に関連するラベルの付与
- そのほかでできること
- terraform-docsによる既存リソースのREADME.mdの自動生成
- github-commentによる古いコメントの非表示化
- actionlintによるGitHub Actions定義のLint
- Renovateによるパッケージのバージョン更新
実行に向けて準備を進める
色々やろうとした分結構やることが多いので、先に概要を説明しておきます。冒頭の図を再掲します。
これを実現するために、
- GitHub ActionsでTerraformを実行するために必要なGoogle側の設定をする
- TerraformのバックエンドをGoogle Cloud Storageに指定する
- GitHub Actionsを動かすために、GitHub Appを設定する
- GitHub Actionsの設定を調整する
- リソース定義を調整する
を行い、それに加えて、
- Renovateを設定する
を行っていきます。
バックエンドとWorkload Identity Federationの設定をする
まず、./sample2_intermediate/以下の各種ファイルを確認し、自身で実行できる環境を整えてください。ハマりどころは結構ある(というのをハマって理解した)のですが、上手くいけば、
terraform init-
terraform applyyes - バックエンドのGoogle Cloud Storageのコメントアウトを外して、
terraform init -migrate-state
をするだけで必要な設定は完了するはずです。爆速構築です。手動でやるのがあんなに大変だったのに。
プロジェクトやバケット、Workload Identity Pool/Workload Identity Pool Providerがさくっとdestroyできないようになっており、やり直して書くのが面倒なので細かい実行ログは割愛させてください
ハマりどころとしては、
- プロジェクトと課金の取扱い
- APIを利用するために、プロジェクトで課金を有効化しないといけない
- ただし個人アカウントでは、1つの請求先アカウントに対して課金を有効化できるプロジェクト数の上限がデフォルトで5しかない
- プロジェクトの削除には1か月の保留期間が設定されて即時削除できないので、プロジェクトを作って/壊してとやろうとすると詰む
- ただし、本運用としてはバックエンドのstateファイルを保管するためのプロジェクトと、Workload Identity Federationを設定するためのプロジェクトと、実際のリソースを管理するプロジェクトは分けた方が良いようである
- リソース定義の制約
- リソースによっては文字数上限があり、上限を超えると作成しようとしてもエラーになる
- 受付可能な文字種に制限があり、不可の文字を入れようとするとエラーになる
- Workload Identity Federationを利用するときに、サービスアカウントの権限借用ではなく直接連携が推奨されているが、実際それでGitHub Actionsからアクセスしようとするとエラーになる
- IAM周りの設定については、iam_member / iam_binding / iam_policyでTerraform管理外の既存リソースに予期せぬ影響を与えることがあり得るので、適切に理解した上で利用すること
があります。とはいえここさえおさえておけば大丈夫なはず。
作成しているリソースについての細かい話はリポジトリで記載している各種リンクを見てもらえればと思いますが、リソース間の設定を追っていくとなんとなくやっていることがわかるかと思います。ポイントだけ少し補足しておきます。
バックエンドのバケットの保護
まずは当たり前ですがバックエンドのバケットを保護するようにします。バックエンド用にプロジェクトを分けるほか、ASIA①(東京+大阪のデュアルリージョン)と設定しつつ、force_destroy = falseでバケットを削除できなくして、かつバージョン管理を有効化しています。
resource "google_storage_bucket" "terraform_backend" {
# 本当はプロジェクトを分けたい
# project = google_project.terraform_backend.project_id
project = google_project.workload_identity.project_id
name = local.google.backend_gcs_bucket_name
location = "ASIA1"
force_destroy = false
public_access_prevention = "enforced"
uniform_bucket_level_access = true
versioning {
enabled = true
}
}
初期構築はTerraformでやっていきますが、このリポジトリの管理するリソースとは切り分けていきましょう。ほぼ変更しないと思うので、ここだけバックエンドをクラウドストレージにしつつローカル実行するようにするのも良さそうです。
プロジェクトの切り分け
上記の通りバックエンドを切り分けるほか、Workload Identity関連のプロジェクトも独立させるのが望ましいです。
公式ドキュメントでは以下のように記載されています。
専用のプロジェクトを使用して Workload Identity プールとプロバイダを管理する
Workload Identity プールとプロバイダを複数のプロジェクトで管理する代わりに、1 つの専用プロジェクトで管理します。専用のプロジェクトを使用すると、次のことができます。
- Workload Identity 連携に信頼できる ID プロバイダのみを使用する。
- Workload Identity プールとプロバイダの構成へのアクセスを一元管理する。
- すべてのプロジェクトとアプリケーションの間で一貫した属性マッピングと条件を適用する。
組織のポリシーの制約を使用すると、専用のプロジェクトを使用して Workload Identity プールとプロバイダを管理できます。
これらに則ると、バックエンド用、Workload Identity Federation用、そしてリソース管理用の3つのプロジェクトを要因することになりますが、今回はプロジェクト数の制約上、前の2つは同じプロジェクトで設定しています。
Workload Identity Federationの設定
Workload Identity Federationにおいては、GitHub - Workload Identity Pool - Workload Identity Pool Provider - Service Account - API - Target Resourceという流れで機能しています。
GitHub - Workload Identity Pool - Workload Identity Pool Providerの連携
以下の条件で制限が付与されています。
oidc {
issuer_uri = "https://token.actions.githubusercontent.com"
}
attribute_condition = "assertion.repository_id == '${local.github.terraform_repository_id}'"
attribute_mapping = {
"google.subject" = "assertion.sub"
"attribute.repository_id" = "assertion.repository_id"
}
条件を設定するにあたって、制限を誤らない(誰でもアクセスできるようには絶対にしない)のはもちろん、リポジトリ名ではなくIDで指定するように気を付けてください。
重要: repository や repository_owner などの名前フィールドを使用すると、サイバースクワッティングやタイポスクワッティングなどの攻撃を受けるリスクが高くなります。GitHub リポジトリまたは GitHub 組織を削除すると、誰かが同じ名前で ID を確立できる可能性があります。この状況を防ぐには、代わりに数値 *_id フィールドを使用してください。これは一意であり、再利用できません。
(出典:公式ドキュメント)
リポジトリのIDは、GitHubの該当のレポジトリでHTMLソースを見ると簡単に確認することができます。
Workload Identity Pool Provider - Service Accountの連携
サービスアカウントの権限借用はPrincipalにWorkload Identity Userを付与することでできますが、このPrincipalに何を設定するかによって権限を調整できます。今回はPull Requestに対してplan用のサービスアカウントを、mainブランチへのMergeに対してapply用のサービスアカウントを設定しています。
terraform_principal = {
plan = "principal://iam.googleapis.com/projects/${google_project.workload_identity.number}/locations/global/workloadIdentityPools/${google_iam_workload_identity_pool.github_actions.workload_identity_pool_id}/subject/repo:${local.github.user_name}/${local.github.terraform_repository_name}:pull_request"
apply = "principal://iam.googleapis.com/projects/${google_project.workload_identity.number}/locations/global/workloadIdentityPools/${google_iam_workload_identity_pool.github_actions.workload_identity_pool_id}/subject/repo:${local.github.user_name}/${local.github.terraform_repository_name}:ref:refs/heads/main"
}
# サービスアカウントの権限借用を利用するために、Workload Identity Userの権限を付与する
resource "google_service_account_iam_binding" "tfaction_plan" {
service_account_id = google_service_account.tfaction_plan.name
role = "roles/iam.workloadIdentityUser"
members = [
local.terraform_principal.plan
]
}
# サービスアカウントの権限借用を利用するために、Workload Identity Userの権限を付与する
resource "google_service_account_iam_binding" "tfaction_apply" {
service_account_id = google_service_account.tfaction_apply.name
role = "roles/iam.workloadIdentityUser"
members = [
local.terraform_principal.apply
]
}
「注: 別のプロジェクトのサービス アカウントは、Workload Identity プールの [接続済みサービス アカウント] セクションに表示されません。」(公式ドキュメント)という話が、ちょっとやりづらくて困りました。
Service Account - API - Target Resourceの連携
これは通常通り、サービスアカウントにIAMの権限を付与すれば大丈夫です。なお、Terraformで権限付与する際には、google_iam_menber/google_iam_bingding/google_iam_policyの3つがあり、後者2つではTerraform管理されていない権限を吹き飛ばす可能性があるのでご注意ください。
詳細は同僚が書いた記事を参考にしてください。
その他
付与する権限は何をするか次第になるので、それぞれの運用で適切なものを付与してください。ちゃんとやろうとすると、何が最小権限なのかを調査するのが一番大変なのでは感はありますが・・・。
リポジトリにも各種ドキュメントへのリンクを記載していますが、以前の記事「まともなTerraform環境構築に向けたあれこれ:バックエンドGCS、Workload Identity直接アクセス、tfactionによるCI/CD」でも参考リンクをまとめているので、よろしければそちらも合わせてご確認ください。
GitHub Appを作成し、設定する
続いて、GitHub Appsを作成します。tfactionを使おうとすると、GitHub Actionsのなかでコメントを記載したり、変更になったファイルをコミットしたりを行うのですが、その際のトークンの発行のため必要になっています。作成にあたっては以下の公式ドキュメントを参考にしてください。
作成画面はどこにあるのかという感じでしたが、Settings > 最下部のDeveloper SettingsからNew GitHub Appで新規作成ができます。私は個人環境で試しているので、非公開にして個人環境のみで利用しています。(組織環境では、そもそも勝手にインストールできないようになっているはずです)
設定内容として必要事項を埋めた後、権限はRepository permissionsとして以下の通りで設定します。
- Actions: Read-only
- Contents: Read and write
- Metadata: Read-only
- Pull Requests: Read and write
planの際にはContentsはRead-onlyでいいのではと思っていましたが、初期実行時にhclファイルが追記されたのに対して書き込み権限がなくエラーになったためご注意ください。
GitHub Appが作成できたら対象のリポジトリにインストールし、APP_IDとPRIVATE_KEYを対象リポジトリのSettings > Secrets and variables > ActionsでTERRAFORM_APP_ID, TERRAFORM_APP_PRIVATE_KEYとして登録します。
また、実行時に必要になるので、同じくSecretsにTROCCO_API_KEYも設定しておきましょう。
GitHub Actionsの設定を調整する
GitHub ActionsはGitHubの機能としてビルトインされているワークフロー機能です。./.github/workflows/のディレクトリに処理を規定したyamlファイルを配置することで、CI/CDを実施することができます。
actionlintの処理が分かりやすいので参考までに載せておきます。この設定で、mainブランチ向けのPull Request起点で.github/**に当てはまるpathでファイル変更があった(=GitHub Actionsの定義ファイルが変わった)ときにワークフローが実行されます。
# GitHub Actionsの設定ファイルをLintする
name: actionlint
on:
pull_request:
branches:
- main
paths:
- .github/**
jobs:
run-actionlint:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
steps:
- uses: actions/checkout@v4.2.2
- uses: aquaproj/aqua-installer@v3.1.0
with:
aqua_version: v2.38.4
- uses: suzuki-shunsuke/github-action-actionlint@v0.1.5
なお、このpathsを./trocco/**/*.tfのようにすると、troccoディレクトリは配下の任意のディレクトリにある.tf拡張子のファイルまで対象を限定させることができます。
- uses: は外部のアクションを利用しているもので、GitHubに公開されたActionを自身の環境で活用することもできます。例えばsuzuki-shunsuke/github-action-actionlintでは、suzuki-shunsukeさんのgithub-action-actionlintというリポジトリを参照しています。
これを踏まえると、便利に使えることはもちろんですが、提供されているactionがどう作られているかを把握することができて、セキュリティリスクの判断のためにも、自己の学習のためにも活用することができます。
そのほかの詳細は詳しく見ていただければと思いますが、実行にあたっては./.github/workflows/terraform_plan.yamlと./.github/workflows/terraform_apply.yamlの上部のenvのみ修正すればよいはずです。
GitHub Actionsを動かしたくない場合は、GitHubのActionsタブから対応するworkflowを選択して、Disableに変更するか、ファイル名自体を例えばterraform.plan.disableなどと変更すると、実行対象から除外されます。
tfactionの実行対象/設定については./tfaction-root.yamlに記載の上で、実行対象のディレクトリにtfaction.yamlを配置することで調整できますが、今回は特に変更するところはありません。
設定を調整する
./sample2_intermediate/google/配下のファイルについては、./sample1_basic/とほぼ同一なので、前半の内容も参考にしつつ調整してください。
./sample2_intermediate/trocco/配下については、moduleを利用した構成にしています。今の定義ではmoduleを利用する必要は特にないのですが、Terraformではディレクトリを分けて管理しようとするとmoduleで切るしかないというのがあり、こういうことができるという参考のためにこの形にしています。
moduleで分割している場合、connectionのmoduleでoutputとして作成した接続情報IDを出力し、それをdatamartのmoduleへ入力し、datamartのmoduleでvariableとして受け取るという形で連携します。
output "bigquery_connections" {
value = {
"bigquery_sample_project" = trocco_connection.bigquery_sample_project.id
"bigquery_sample_project2" = trocco_connection.bigquery_sample_project2.id
}
description = "BigQueryの接続情報のID一覧:リソース名=IDの形になっているので、リソース名を指定することで接続情報のIDが特定できる"
}
module "account_management" {
source = "./modules/account_management"
providers = {
trocco = trocco
}
your_email = local.your_email
}
module "connection" {
source = "./modules/connection"
providers = {
trocco = trocco
}
google = local.google
snowflake = local.snowflake
}
module "transfer" {
source = "./modules/transfer"
providers = {
trocco = trocco
}
bigquery_connections = module.connection.bigquery_connections
snowflake_connections = module.connection.bigquery_connections
}
module "datamart" {
source = "./modules/datamart"
providers = {
trocco = trocco
}
bigquery_connections = module.connection.bigquery_connections
snowflake_connections = module.connection.bigquery_connections
}
variable "bigquery_connections" {
description = "BigQueryの接続情報のID一覧:リソース名=IDの形になっているので、リソース名を指定することで接続情報のIDが特定できる"
}
いざ実行!!!
ここまでの設定を調整すると、GitHubのPull Requestでplanが実行されるはずです。
実行対象と影響に関するラベルが自動付与されます。

docsを更新して自動コミットしてくれます。
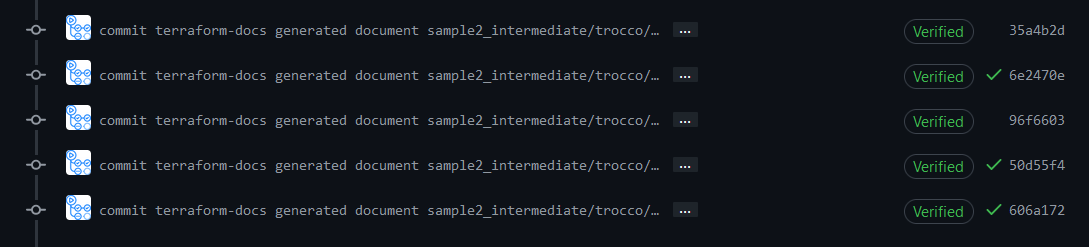
plan結果がコメントされます。
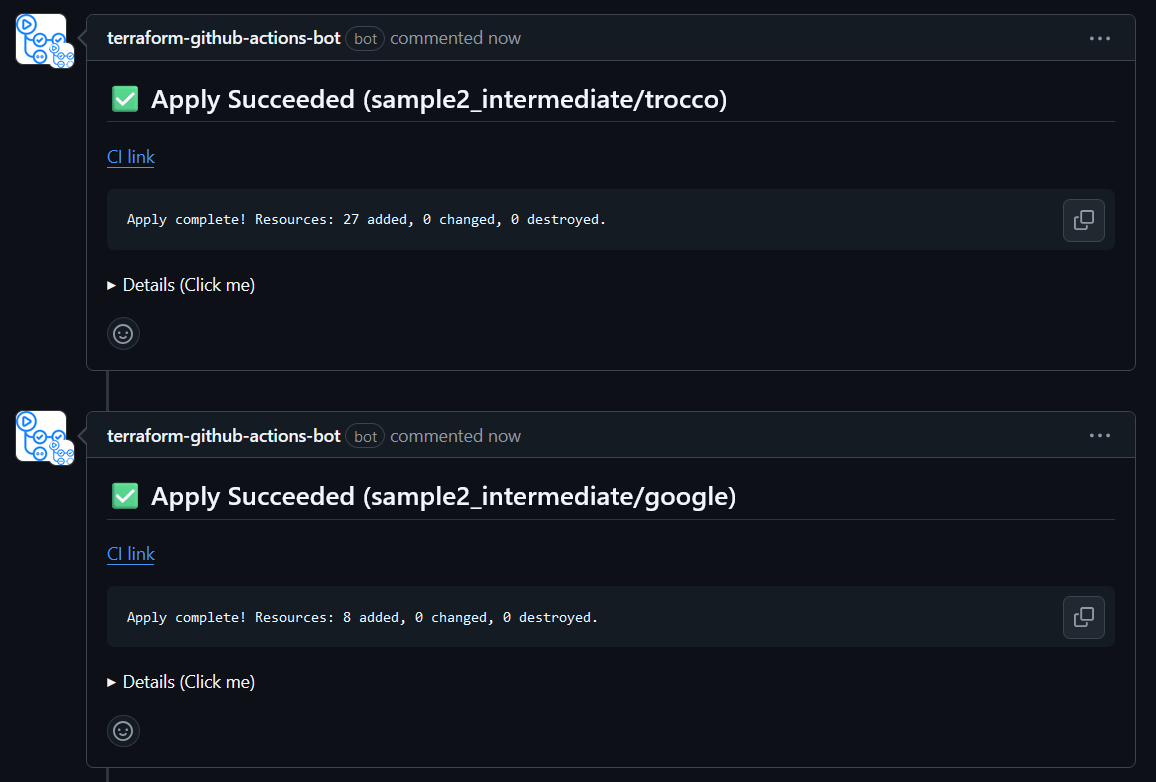
Mergeするとapplyされて、結果がコメントされます。
ここまでできた方はお疲れさまでした!!!
Renovateを設定する
最後に、Renovateの設定を行います。GitHub Appsをインストールして、設定ファイルを設置するだけです。詳細は以下の記事をご参照ください。
設定ファイルについては、既にあるものから特に変更する必要もないかと思いますが、ご自身のやりたいことに合わせて微調整してみてください。
設定が完了すると、最初にDependency Dashboardというものが生成された後、あとはパッケージがアップデートされるのに合わせて自動でのPull Requestの作成/自動でのMergeが実行されるはずです。
今回のやり残し
すごい分量になってきたので、試し/書き切れなかったものをいくつか取り上げておきます。
リソースの切り分け/取り込み
どこまでをどこで管理するかというのはTerraformに関する永遠の悩みだと思いますが、外部のリソースを取り込む方法としては、サンプルで記載しているdataブロックを活用した読み取り専用での取得のほかに、remote_stateという外部のstateファイルを読み込みにいく方法があります。
少し試してみましたが、ロックがかかっているときにエラーとなるというのがあり、使う場合はdataブロックの方がいいのではという所感でした。とはいえ更新サイクルが遅いものを切り分けるなら使えるかもしれません。
クレデンシャルの取扱い
最近リリースされたTerraform 1.10.1の機能で、ephemeralというものがあります。これは、センシティブなデータをstateファイルに残さずに、その場限りで活用するものです。
これに連動して、google-betaのプロバイダでもgoogle_service_account_keyというephemeralリソースが公開されています。
Terraform Provider for TROCCO側の改修が必要だと思いますが、近いうちにKEYの生成をTerraformで行いつつ、stateには残さないという形が実現できそうに考えています。
また、ignore_changesで指定していても、生成されたリソースから値を抜いてしまうことがあるらしいです。具体の挙動はサービス依存ですかね・・・
基本的にTerraformはAPIのラッパーなので、APIが返さない値は取りようがない(例えばTROCCOのユーザーのパスワードはAPIが返さないので、入りようがない)となっていますが、いずれにせよstateファイルを注意深く扱うことが何より重要なのだと思います。
Terraformの設計
Terraformにはworkspaceという環境分離のための機能がありますが、これは自分がいまどの環境にいるのかがわからくなりがちなので、できれば使わない方がいいらしいです。
機能自体は以下の記事を参考にしてください。
一方で、moduleの活用も含めてディレクトリや変数をどのように活用していくかは色々と考えどころがあり、また今回はGitHub Flowベースとしているブランチ戦略をどうするかも含めて、検討するポイントがありそうです。
現時点で勉強になった記事を3つ紹介しておきます。
そのほか、moduleはGitHubに公開されたものを活用することもできるらしいです。
取込/リファクタの運用
既存リソースの取り込みや、moduleを利用していったときのリファクタリングをどう進めていくかは、多くの既存リソースがある環境では非常に重要なテーマになります。
個別の処理としてはimport/moveコマンドやimport/movedブロックがありますが、これをまとめて便利にするツールとしてtfmigrateがあります。概要は弊社SREの高塚さんがまとめています。
tfactionと合わせた運用が可能なので、そのあたりも身につけておきたいですね。
そのほかimportブロックの挙動や、tfmigrateの詳細、そして実はplan差分がなくてもデフォルト値の設定に起因してズレが発生し得ることなど、以下も参考になりました。
また、大量の設定を取り込もうとすると大変なので、APIから取得して取り込みのためのコードを生成したり、stateファイルをterraform show -json > state.jsonのようにJSONファイルでエクスポートして、それを利用するのも良さそうです。
運用Tips
自分で把握しているものも多かったものの、まとまっていると便利ですね。
頑張ってまとめたあとに、本を読めば良かったのではと思ったのはここだけの話。
参考までの小ネタ(後日使うかも備忘録)
多方面に渡って解像度が高くなる記事です(tfmigrateの開発者の方でした)。
プロバイダーによってはデフォルトのタグを付与することができるそうです。既存リソースの取込時にdiffが出ないかは少し気になりますが、確かにあると便利ですね。
カスタムのテストをかけられます。
ローカルファイルを生成できます。
Terraformの話ではないですが、こういうのは運用上役立ちそうですね。
おわりに
ここまで、Terraformの基礎知識から、運用を考えたときのCI/CDの構築例まで、幅広く整理をしてきました。勉強になる記事はたくさんありますが、「とりあえずこれ読んでおけ」と使ってもらえるような記事になれると嬉しいです。
(もし変なところ/もっとこうした方がいいというところがあれば、ぜひ教えてください!)
そして、今回これを書きながらいろいろなものにお世話になりまくっているsuzuki-shunsukeさんは、2025/2/27のData Engineering Study #28で登壇をしてくださいます。
私が試していてあまりにも感動したので打診先に挙げさせていただき実現したのですが、インフラの専門家かつOSSの開発者として、今回は説明が薄くなったtfactionの詳細や、堅牢かつアジリティのあるインフラの設計/実装に向けて、データエンジニアでも参考になるお話を伺えるだろうと大変楽しみにしています。
そしてpeiさんからはデータ基盤の実装者としての立場から、データ基盤を進化させてきた過程のなかでの様々な取り組みについて、幅広くお話しいただけるのではと期待しています。
みなさまもぜひご参加くださいませ!
おまけ
色々試行錯誤をしたおかげで、謎なデバッグ知識を得ることができまして、簡単に紹介しておきます。
細かいTerraformのデバッグをする際には、terraform consoleというコマンドがあり、データ型の詳細の確認などが実施できます。Terraform上のコマンドを打ったときにどのように処理できるかを確認もできるので、必要に応じて使うと便利です
Terraformのsensitive = trueの値を確認したいとき、stateのファイルを見に行くこともできますが、outputでごにょごにょして出すこともできます。本運用ではNGでしょうが。
GitHub Actionsでデバッグをする際には、GitHubのActionsのSecretにACTIONS_STEP_DEBUG=trueという値を設定することで、実行時のログがより詳細なものになります。
とはいえ、CI/CDでデバッグしようとすると無限に時間が溶けるので、面倒くさがらずに一度ローカルで試せというのが教訓としてあります。お気をつけてください。
そして、思った通りにいかないときはたいていシェルコマンドが間違っています。自分でやろうとすると例外考慮できないがちということで、便利なツールはありがたいですね。