1. この記事の目的
最近は右も左もLLMという風潮
ぜひ、自分のPCで使ってみたいと思ったが、パラメータ数◯Bという表記
馴染みの無い(特に日本人には)単位で実際にどこまでのサイズが自分の
PCで実行できるか、分からず検証してみようと
2. GPUメモリ使用量について
-
LLMのGPUメモリ使用量の計算方法
推論に必要なメモリは大まかに FP16の1パラメータ(2バイト)に対してパラメータ数◯Bとすると
$必要なメモリ(GB) = 2 \times ◯$
となります。意外とシンプルです。 [1] -
GPUメモリ使用量の実測
GPUtil[2]を使用して次のコードで計測。
import GPUtil
def get_gpu_used_memory(device_id):
byte_gpu_used_memory = GPUtil.getGPUs()[device_id].memoryUsed
GB_gpu_used_memory = byte_gpu_used_memory / 1024
return GB_gpu_used_memory
3. モデル
- 計測対象モデル
- TinyLlama-1.1B-Chat-v1.0
- phi-2
- Mistral-7B-v0.1
- zephyr-7b-beta
- SOLAR-10.7B-Instruct-v1.0
- LLaMA-MoE-v1-3_5B-4_16
- xglm-4.5B
- idefics-9b-instruct
- Yi-6B
- Qwen-1_8B-Chat
- パラメータ数の実測
torchinfo[3]を使用して、次のコードで計測。
from torchinfo import summary
def get_billion_param(model):
billion = 1000**3
return round(summary(model, verbose=0).total_params / billion, 2)
4. コードと結果
- コード全体
from torchinfo import summary
def get_billion_param(model):
billion = 1000**3
return round(summary(model, verbose=0).total_params / billion, 2)
ここ[4]にもおいています。
- 結果
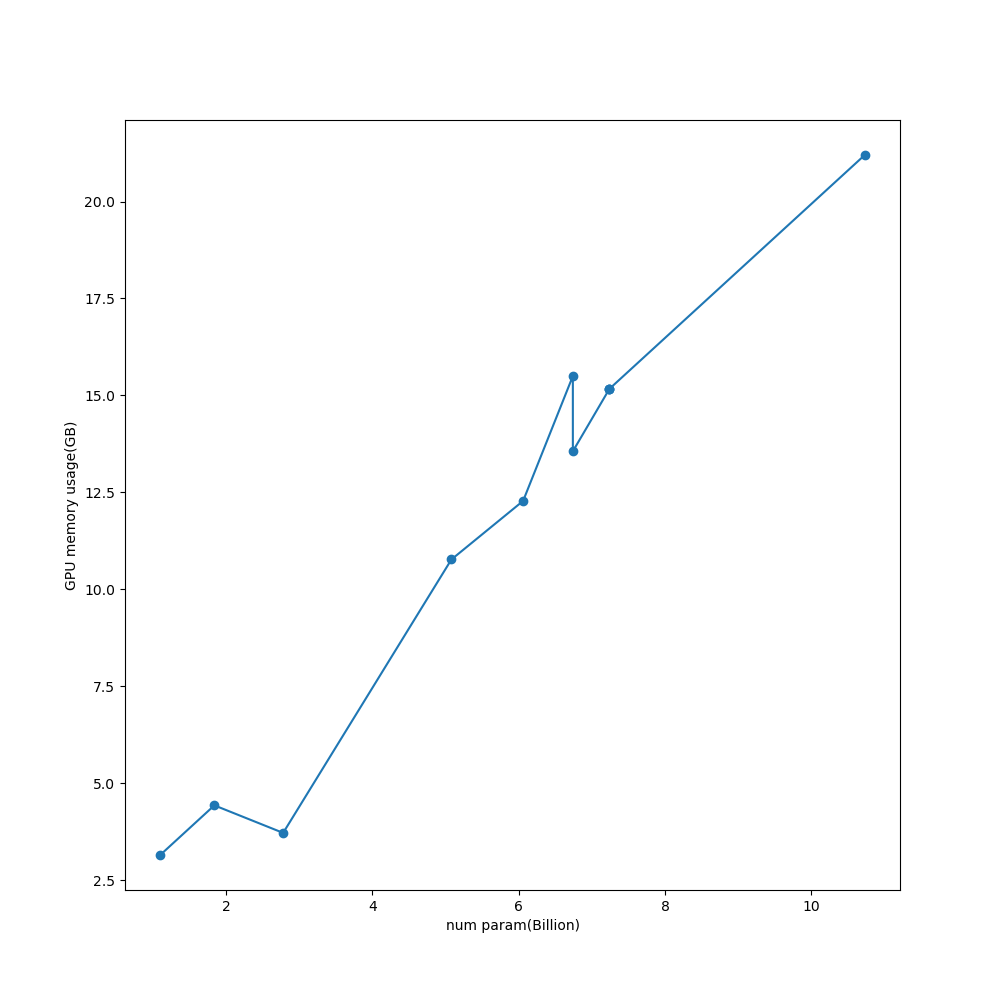
おおまかには
GPUメモリ使用量について
の通りになっています。
ただし、いくらか誤差もありそうで内部で使用しているアルゴリズムの差もあるかもしれません。
5. まとめ
今後、モデルのファインチューニングをしてみたいと考えています。
モデルの全てのパラメータの再学習には
$必要なメモリ(GB) = 4 \times ◯$
が必要なよう[1]なので、Phi-2くらいがローカルPCで使用できる最高ラインくらいになりそうですね。
6. 参考
6.1. メモリ使用量についての質問
6.2. gputil
6.3. torchinfo
6.4. 作成リポジトリ