動機
プログラミングをしているとプログラムを使い回したいであったり、そのプログラムを他のメンバーに使ってもらうという場面が出てくると思います。
そんなときは、コードを機能ごとにモジュール化、パッケージ化し、きちんとドキュメントを整備しておくと、他の人が使いやすくなるとなると思います。
またPythonのパッケージを作る際はVSCodeが強力なツールとなります。そこでVSCodeを使ったPythonパッケージの作り方について説明します。
またデータ分析プログラムをパッケージ化する時に役立つ情報も載せておきます。
環境
| 備考 | ||
|---|---|---|
| OS | Windows10 | |
| conda | 4.8.3 | Anaconda Promptでconda -V
|
| Anaconda | 2020.02 | Anaconda Promptでconda list anaconda
|
| Python | 3.8.2 | |
| VSCode | 1.43.2 |
環境のセットアップ
この記事を参考にVSCodeでのPython実行環境を整えてください。
VSCodeでのPython、Jupyter実行環境の構築方法
ディレクトリ構成
VSCodeでの実行環境ができたら、そこにPythonパッケージを開発するためのフォルダやファイルを作っていきます。
.
├── 好きなパッケージ名
│ ├── __init__.py
│ └── 好きなファイル名.py
├── setup.py
└── script.py
好きなパッケージ名フォルダ以下がパッケージ本体となります。
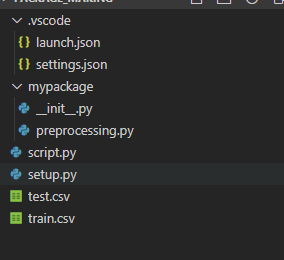
例として、VSCode上で上図のように作ってみました。例としてパッケージ名をmypackageとしてみます。
setup.pyを書く
setup.pyはパッケージにはこれから作るパッケージの依存情報、バージョン情報、パッケージ名を設定するファイルです。
setup.py
from setuptools import setup, find_packages
setup(
name='mypackage',
install_requires=['pandas','scikit-learn'],
packages=find_packages()
)
setupという関数の引数に設定を書いていきます。
例えば、install_requiresにはパッケージに必要なモジュールを書きます。
ほかにも様々な項目があるので、公式ドキュメント(setup スクリプトを書く)などで適宜調べてください。
プログラムを書く
早速プログラムを書いて行きましょう。例として今回はKaggleのタイタニック号のデータを分析するパッケージを作ろうと思います。
パッケージ内のファイル、preprocessing.pyに次のようなプログラムを書いたとします。
これはデータを前処理するプログラムです。
preprocessing.py
class Preprocesser:
"""
前処理をするクラス
"""
def process(self,data):
"""
前処理をするメソッド
"""
processed_data=data.copy()
# Ageの欠損値を中央値に
age_m=processed_data['Age'].median()
processed_data['Age']=processed_data['Age'].fillna(age_m)
#-----省略-----
# 前処理を書いていく
return processed_data
プログラムを実行する
プログラムを実行してみましょう。パッケージmypackageフォルダ直下にscript.pyというプログラム実行用の.pyスクリプトを作ります。例として、訓練データを前処理し、表示するプログラムを書きます。
script.py
def main():
from mypackage import preprocessing
import pandas as pd
train=pd.read_csv('train.csv')
# 前処理インスタンスを初期化し、前処理をする
preprocesser=preprocessing.Preprocesser()
train_processed=preprocesser.process(train)
print(train_processed.head())
if __name__=='__main__':
main()
自作パッケージのインポート方法についてですが、自作パッケージのフォルダ直下であれば、
from mypackage import preprocessing
のように
from 自作パッケージ名 import 個々のpythonコードのファイル名
でパッケージをインポートできます。
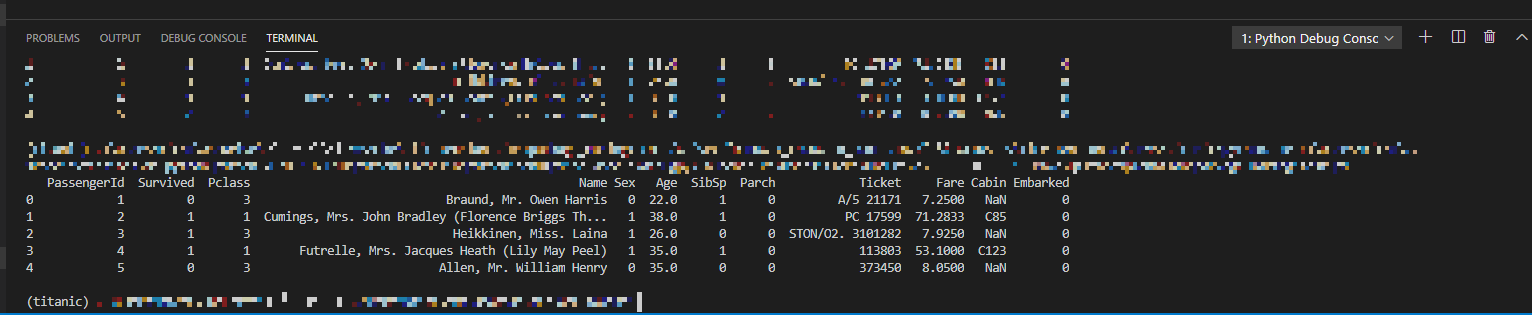
このscript.pyを開いた状態で、VSCode上でF5キーを押すと上図のようにプログラムが実行でき、実行結果がTerminal上に表示されます。
パッケージをデバッグする
VSCodeでのPython、Jupyter実行環境の構築方法 #デバッグの活用
と同様にパッケージのプログラミングでもVSCodeのデバッグ機能が使えます。
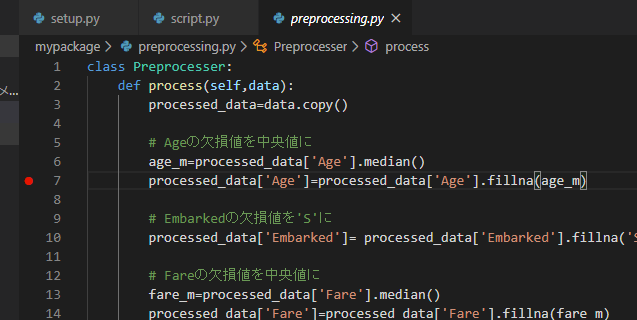
例えば、上図のようにパッケージ内のコードpreprocessing.pyの7行目でF9キーを押します。そうすると、この行の左端に赤い点が表示されます。これをブレークポイントといいます。そしてこの状態でscript.pyに戻り、F5キーを押して実行すると、
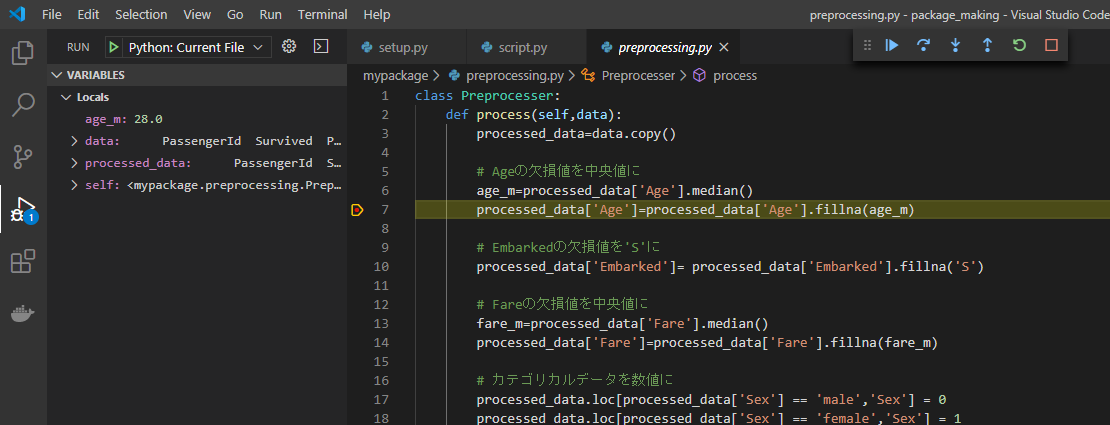
上図のようにパッケージ内の7行目で実行が一時停止し、その時宣言されている変数(ここではpreprocessing.py内の変数)が左のサイドバーに表示されています。このようにブレークポイントを用いることで、プログラムのバグ取り(=デバッグ)が捗ると思います。
パッケージをインストールする
この自作パッケージを別環境にインストールしてみます。そしてその別環境でも動くかどうか試してみます。
Anaconda Promptを開き、新しく環境を作ります。
conda create -n 好きな環境名 python=Pythonバージョン

今回は例としてsetup_testという環境を作りました。
そしてこの環境を起動します。
conda activate setup_test
そして上で編集したsetup.pyがあるフォルダまで移動します。
cd setup.pyのあるディレクトリ
そしてこの自作パッケージをインストールします。
python setup.py install
インストールできたら、この状態で上のscript.pyを実行してみます。script.pyとtrain.csvを適当な別のフォルダにコピーし、そこで実行してみます。
python script.py
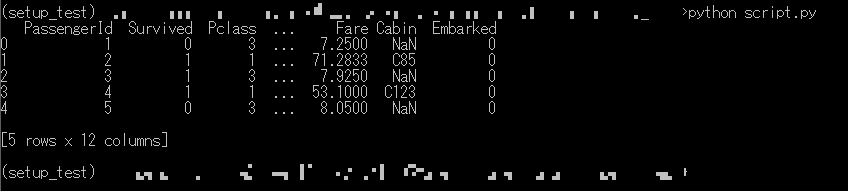
上図のように実行でき、前処理された訓練データが表示されました。このフォルダにはスクリプトとデータがあるだけで、自作パッケージのフォルダはありません。つまり、このフォルダでscript.pyで実行できたということは、この自作パッケージがこの環境にインストールできたということになります。
自作パッケージにデモ用データを用意する
自作パッケージを作る際に、ソースコード以外のデータファイルを含めたくなる場合があると思います。
例えばデータ分析用のパッケージを作って配布したとします。そして、他のメンバーがそのパッケージを使いたいと思った時に、データはすぐに用意できないけど分析の挙動を知りたい、というニーズがあると思います。そんなときに、あなたがデモ用のデータをパッケージの中に用意しておけば、その人にスムーズに説明できます。
例として、タイタニック号の訓練データをパッケージ内に用意する場合を説明します。ディレクトリにいくつかフォルダとファイルを加えます。
.
├── mymodule
│ ├── __init__.py
│ ├── preprocessing.py
│ ├── load_date.py *
│ └── resources *
│ └── train.csv *
├── setup.py
└── script.py
*:新しく追加したファイル・フォルダ
まず、自作パッケージ内にデータ用のフォルダを作ります。ここではresourcesとします。そしてその中に訓練データ(train.csv)を入れます。
パッケージ内のデータを読み込む
次のようなデモデータを読み込むコードを書き、パッケージに加えます。
load_date.py
import pkgutil,io
import pandas as pd
class DataLoader:
def load_demo(self):
train_b=pkgutil.get_data('mypackage','resources/train.csv')
train_f=io.BytesIO(train_b)
train=pd.read_csv(train_f)
return train
ここでpkgutilというPythonに標準で含まれているモジュールを使います。pkgutil.get_data()という関数は、パッケージ名とファイル名を指定するとその内容がバイナリで取得できます。
またioは読み込んだバイナリデータをファイルっぽく(file-like object)扱えるようにするために使っています。
デモデータが読み込めるかテストします。script.pyのmain()を次のように書き換え、VSCode上でF5で実行します。
script.py
def main():
from mypackage import load_data
data_loader=load_data.DataLoader()
train=data_loader.load_demo()
print(train.head())

上図のようにデモデータが読み込めました。
パッケージインストール時にデータも同時にインストールされるようにする
ただ、これだけだとこのパッケージをインストールしてもデータも一緒にはインストールされません。パッケージをインストールした際にデータも同時にインストールされるようにするために、setup.pyに一行加えます。
setup.py
from setuptools import setup, find_packages
setup(
name='mypackage',
install_requires=['pandas','scikit-learn'],
packages=find_packages(),
package_data={'mypackage': ['resources/*']}
)
package_dataにパッケージ名、フォルダ名を指定することで、パッケージインストールと同時にインストールするデータを指定することができます。
詳しくは公式ドキュメント(2.6. パッケージデータをインストールする)などを参考にしてください。
そうして上で説明したように、また新しく環境を作って、setup.pyを使って自作パッケージをインストールすると、インストールした環境でデモデータが使えるようになってることが確認できると思います。
おわりに
自分の作ったプログラムを他のメンバーに説明しやすいように、そして使いやすいようにするにはまだまだこれだけでは不十分で、本来であれば、unittestやpytestでテストを書いたり、docstringでプログラムの入出力について説明したりと、すべきことは他にもあります。
ただ、パッケージ化することはそうしたことの第一歩だと思います。
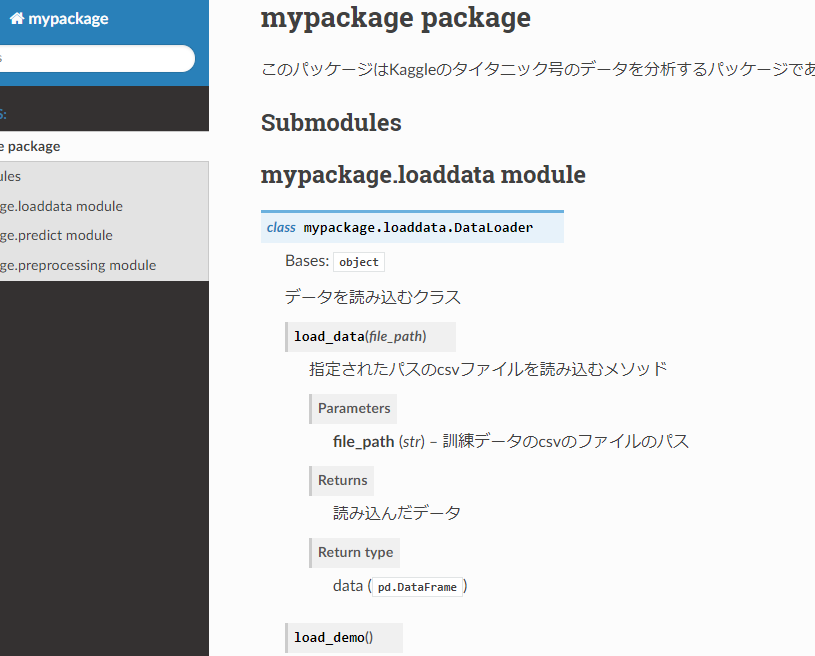
ここまで来た人はぜひ、テストを書いたり、docstringを書いたり、docstringを下のようなプログラムの仕様書に変換したりと自分のプログラムをわかりやすいものにしてください。
追加情報
Pythonコードのパッケージングについてはこの記事が大いに参考になりました。
またunittestを使ったテストの書き方についても書いてあるので参考にしてください。
(インターン向けに書いた)Pythonパッケージを作る方法
ただ、テストについてはpytestの方が使いやすいです。unittestに慣れた人は是非pytestを使ってみてください。
pytest(公式ドキュメント)
また自分のプログラムについて説明するドキュメントについてです。docstringを仕様書としてドキュメント化する事ができます。
Sphinxの使い方.docstringを読み込んで仕様書を生成
また、プログラムの使い方や理論を説明するのに図や式を用いて説明したい場合もあると思います。
そんなときはmkdocsというmarkdown 形式でドキュメントが作成できるモジュールを使うといいでしょう。
MkDocsによるドキュメント作成
このsphinxとmkdocsでドキュメントを作成し、AWSのS3などでホスティングすれば、メンバーからこのプログラムどうやって使うんだ?と聞かれた場合、忙しいときはそのURLを送ればいいので非常に便利です。
タイタニック号のデータ分析についてはここを参考にしました。
【Kaggle初心者入門編】タイタニック号で生き残るのは誰?