今回、完全プログラミング初心者の私がWebアプリ開発コース(3ヶ月)を受講し、ようやくここまで完成・・・
開発環境(Macbook Pro)
・GoogleColaborabory
・Anaconda(VSCode Ver 1.55.2)
・Python(Ver 3.6.13)
成果物
初音ミク判別アプリ
Webページをインターフェイスとしてアニメキャラクターの写真を投稿すると、
その写真が初音ミクかそうでないかを文字として出力するWebアプリを使用しました。
使用した主なモジュール
・学習プログラム側・
OpenCV
画像処理に使用されるモジュール。
イメージファイルの読み込み、サイズ変更、特徴点の抽出を行う
TensorFlow
Googleが開発した機械学習のためのモジュール。
主にDNNやCNNなどのニューラルネットワークの構築や学習、モデルの作成を行う
Numpy
配列の計算などに使用されるモジュール。
リスト化された要素(ここでは主にFloat型の数字)をArrayとしてある意味リスト化し
各要素の計算を高速で行うことができる。
・Webアプリ側・
Flask
主にPythonで使用されるWebフレームワーク。
小規模ながらカスタマイズ性が高いことで評価されている。
Webページ上でアップロードされた画像データを学習プログラム側に引き渡し結果を返す
・Webページ側
HTML
Webページ作成で使用される言語
CSS
HTMLで作成されたページをより細かくカスタマイズすることができる
学習プログラムの作成
まず、データセットを探すところから・・・
色々探したのですが、なかなかこれだ!というものが見つからなかったので
下記サイトから今回はアニメキャラのデータセットを選択しました。
最初はたくさんあるアニメキャラの画像をアップロードすると何のキャラクターかを判別するプログラムを組んでみようと思ったのですが、難易度が高そうだったので今回は「初音ミク」のみをピックアップ、「初音ミクかそうでないか」というYes or Noスタイルで作ってみることにしました。
そこで最終的に出来たコードがこちら。
CNNとVGG16による転移学習を併せて学習を行っています。
1.必要となる初音ミクの画像と、そうでない画像を保存したフォルダをGoogleDriveにアップロードした上でGoogleColabにマウントします。
2.その後、os.listdirにてフォルダ内のファイル名を取得します。
3.そしてimg_hatsumeとimg_not_hatsumeの空のリストを作成
4.for文を使って保存された画像ファイルのフルパスをimreadで読み込みます
そしてそれをリサイズし、img_hatsuneリストにappendします
これをimg_hatsumeとimg_not_hatsumeの両方に行います。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
from google.colab import files
# 2
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'
path_hatsune = os.listdir('/content/drive/MyDrive/hatsune/')
path_not_hatsune = os.listdir('/content/drive/MyDrive/not_hatsune/')
# 3
img_hatsune = []
img_not_hatsune = []
resize_image_size = 50
# 4
for i in range(len(path_hatsune)):
img = cv2.imread('/content/drive/MyDrive/hatsune/' + path_hatsune[i],1)
img = cv2.resize(img, (resize_image_size,resize_image_size))
img_hatsune.append(img)
for i in range(len(path_not_hatsune)):
img = cv2.imread('/content/drive/MyDrive/not_hatsune/' + path_not_hatsune[i],1)
img = cv2.resize(img, (resize_image_size,resize_image_size))
img_not_hatsune.append(img)
5.テスト用データ(X)としてimg_hatsuneとimg_not_hatsuneリストをアレイ化して結合、yは正解ラベルとして初音を0、初音でない場合を1と定義。
6.rand_indexにてトレーニング用データXをランダムに入れ替える。
7.そしてX_train X_test y_train y_testとして使用する割合を設定(80%)
8.to_categoricalにてワンホット表現とするためにそれぞれの正解ラベルを正規化
# 5
X = np.array(img_hatsune + img_not_hatsune)
y = np.array([0]*len(img_hatsune) + [1]*len(img_not_hatsune))
# 6
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# 7
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# 8
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
9.ここでようやく学習器の作成に入る。
まず、投入するデータのサイズを50x50にし、RGBの3つで投入する。
その後、VGG16による転移学習を行うコードを作成。
10.top_model = Sequentialから以下がそれ以降のDNNコードとなる。
11.for文を使用してVGGの抽出した特徴量を19層まで固定する
12.model.compileにて分類方法を指定、今回はcategorical_crossentropyを使用
13.ここでようやくmodel.fitで学習を開始!
# 9
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 10
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(128, activation="relu"))
top_model.add(Dense(2, activation='softmax'))
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# 11
for layer in model.layers[:19]:
layer.trainable = False
model.compile(loss='categorical_crossentropy',optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),metrics=['accuracy'])
# 12
model.fit(X_train, y_train, batch_size = 5, epochs = 1)
13.def pred_hatsume関数で予測をしpredに返す関数を作成
14.scores = model.evaluate(X_test, y_test, verbose=1)で損失値をscore変数へ格納
print関数でロスと正確性を表示
15.forを使用して各イメージをBGRに分解、それをRGBの順にマージする。
16.model.predictで行った予測をpred変数に格納、次行でprint
17.学習したモデルを保存するため、resultディレクトリを作成しそこにmodel.hatsume.h5としてダウンロード
# 13
def pred_hatsune(img):
pred = np.argmax(model.predict(img.reshape(1,50,50,3)))
return pred
# 14
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# 15
for i in range(5):
img = cv2.imread('/content/drive/MyDrive/hatsune/' + path_hatsune[i],1)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
# 16
pred = np.argmax(model.predict(X_test[0:10]), axis=1)
print(pred)
model.summary()
# 17
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
model.save(os.path.join(result_dir, 'model.hatsune.h5'))
files.download( '/content/results/model.hatsune.h5' )
そしてこのコードで学習を行なった結果↓

正確性を示す数値であるTest accuracyを見てみると、0.625と記載されているのですが、これは62.5%であることを示しています。
また、Test lossは検証用データの損失を表しており、損失数値も大きい。
結果↓
Test loss: 3.1071865558624268
Test accuracy:0.625
[0 1 1 0 1 1 1 0]
加えて正確性では流石に学習しているとは言えないので、epoch数を20にしてみました。
epoch数とは、学習を行う回数を指定するためのパラーメーターで、#12で記載している
`model.fit(X_train, y_train, batch_size = 5, epochs = 1)'の部分です。
結果↓
Test loss: 2.028750419616699
Test accuracy:0.75
[1 1 1 1 1 0 1 0]
75%と10%弱上がってない。
しかし、ロスは若干下がってるからまだ上がる余地はあるかなぁ・・・
そこで、epoch数を15,batch_sizeを8にしてみる。
batch_sizeは学習時に一度に投下されるデータの量を表しています。
結果↓
Test loss: 1.0087106227874756
Test accuracy:0.875
[0 1 0 1 1 0 0 1]
お!87%だしロス率もまぁ低くはないけど高すぎない!
最終的に仕上がったコードがこちら↓
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
from google.colab import files
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'
path_hatsune = os.listdir('/content/drive/MyDrive/hatsune/')
path_not_hatsune = os.listdir('/content/drive/MyDrive/not_hatsune/')
img_hatsune = []
img_not_hatsune = []
resize_image_size = 50
for i in range(len(path_hatsune)):
img = cv2.imread('/content/drive/MyDrive/hatsune/' + path_hatsune[i],1)
img = cv2.resize(img, (resize_image_size,resize_image_size))
img_hatsune.append(img)
for i in range(len(path_not_hatsune)):
img = cv2.imread('/content/drive/MyDrive/not_hatsune/' + path_not_hatsune[i],1)
img = cv2.resize(img, (resize_image_size,resize_image_size))
img_not_hatsune.append(img)
X = np.array(img_hatsune + img_not_hatsune)
y = np.array([0]*len(img_hatsune) + [1]*len(img_not_hatsune))
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(128, activation="relu"))
top_model.add(Dense(2, activation='softmax'))
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
for layer in model.layers[:19]:
layer.trainable = False
model.compile(loss='categorical_crossentropy',optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),metrics=['accuracy'])
model.fit(X_train, y_train, batch_size = 8, epochs = 15)
def pred_hatsune(img):
pred = np.argmax(model.predict(img.reshape(1,50,50,3)))
return pred
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
for i in range(5):
img = cv2.imread('/content/drive/MyDrive/hatsune/' + path_hatsune[i],1)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
pred = np.argmax(model.predict(X_test[0:10]), axis=1)
print(pred)
model.summary()
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
model.save(os.path.join(result_dir, 'model.hatsune.h5'))
files.download( '/content/results/model.hatsune.h5' )
さて・・・・ここまでが学習モデルの作成なのですがもうここで既に講師の方々にたくさんご協力いただいており、自力で出来ているのかと言われればNOな訳で・・・
まだまだ勉強する必要がありますね。
その後、作成してあった下記FlaskのコードとHTML,CSSを作成。
Flaskコード
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
os.environ['KMP_DUPLICATE_LIB_OK']='True'
classes = ["初音です","初音ではありません"]
image_size = 50
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model_hatsune.h5')
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
img = image.load_img(filepath, grayscale=False, target_size=(image_size,image_size,3))
img = image.img_to_array(img)
data = np.array([img])
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted]
return render_template("index.html",answer=pred_answer) return render_template("index.html",answer="")
if __name__ == "__main__":
app.run()
HTMLコード
<!DOCTYPE html>
<html lang='ja'>
<head>
<meta charset='UTF-8'>
<meta name='viewport' content="device-width, initial-scale=1.0">
<meta http-equiv='X-UA-Compatible' content="ie=edge">
<title>初音ミク判別</title>
<link rel='stylesheet' href="./static/stylesheet.css">
</head>
<body>
<header>
<img class='header_img' src="https://aidemy.net/logo-white.8748c46e.svg" alt="Aidemy">
<a class='header-logo' href="#">初音ミク判別</a>
</header>
<div class='main'>
<h2> 送信された画像が初音ミクかを判別します</h2>
<p>画像を送信してください</p>
<form method='POST' enctype="multipart/form-data">
<input class='file_choose' type="file" name="file">
<input class='btn' value="submit!" type="submit">
</form>
<div class='answer'>{{answer}}</div>
</div>
<footer>
<img class='footer_img' src="https://aidemy.net/static/media/logo.eb4d1a66.svg" alt="Aidemy">
<small>© 2019 Aidemy, inc.</small>
</footer>
</body>
</html>
総仕上げ
これらを写真のようにAidemy_Appフォルダに格納
最後にAnacondaからターミナルを開いてhatsune.pyを実行すると・・・
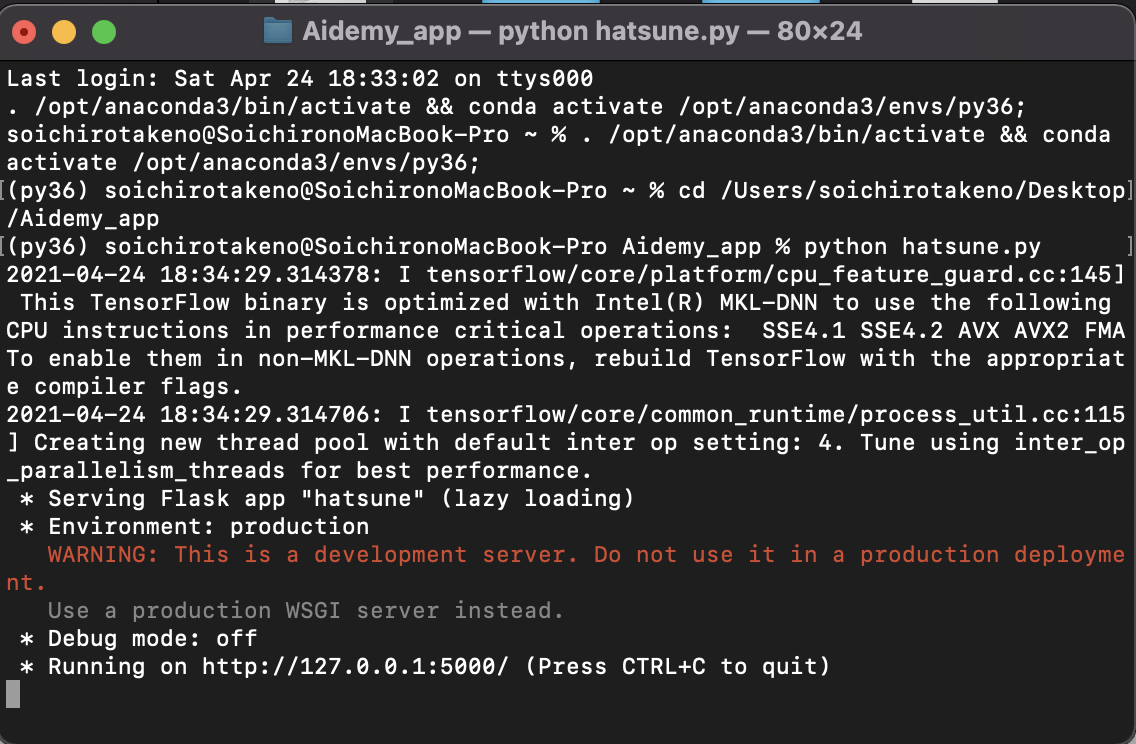

出来たああああああ!!
画像を投稿してみると下の写真のような結果を得られます。
初音ミクが映っている写真をSubmitすると「これは初音です」と表示され、
それ以外のキャラの写真をSubmitすると「これは初音ではありません」と表示されます。
これは、上記Flaskのコード内に記載されているclasses = で定義されており、
その後にmodel = load_model('./model_hatsune.h5')で先ほど作成したモデルをロードします。
pred_answer = "これは " + classes[predicted]にてclassで定義されたセリフをpred_answerという変数として格納、return render_template("index.html",answer=pred_answer)で作成したhtmlページに返すことで、下のような結果を得られるわけですね〜。

実際に使ってみる
使ってみた感想としては、
10回ほど初音ミクのデータをSubmitしたところ
9回成功:1回失敗
10回ほど初音ミクではないデータをSubmitしたところ
8回成功:2回失敗
なぜか、カードキャプターさくらの画像を初音ミクと認識してしまうことが判明しました。
髪の毛の色も違うので、何かが原因で初音ミクと認識してしまっているようです。
ここは要確認ですね・・・
苦戦した点
まず、学習をする前段階でのデータの読み込みがうまくいかず、コードを細かく分けて動作するかを検証する作業が非常に大変でした。
また、学習をする際にはarrayのshapeを50.50.3にしないとRGBで読み込んでもらえないのでそこのarrayのshapeへの理解が難しかったことですかね。
FlaskとHTML、CSSはあくまでもインターフェイス寄りなので1回作ってしまえばいいのですが、やはり学習モデル作成の部分の細かい理解がより必要だなと感じたので、継続して勉強していきます!
改善点
<モデル構築>
モデル作成でのaccuracyの数値を95%くらいまで目指すためにモデル構築のパラメーターを細かく変更して調整していくと共に、より細かい知識を習得必要あり
<Flask>
コードの読み込みで内容の理解を深める
<HTML>
より細かい作りのページを作成できるようにこれから沢山のページを作成して慣れる必要あり
<CSS>
上記HTMLに加えて色々なパターンの装飾を試してバリエーションを増やす