これは「Happiness Chain Advent Calendar 2024」の16日目の記事です。
はじめに
RAGの回答精度向上のためにはどこを工夫すべきか、LangChain(AIアプリ開発のフレームワーク)が公開しているrag-from-scratchをベースに整理してみました。
rag-from-scratchについては@FukuharaYohei様の所で詳細にまとめられていますので、本記事では基礎の部分となる、①Indexing、②Retrieval、③Generationを中心にまとめてみようと思います。
ちなみに、rag-from-scratchはハンズオン出来ます(しかもYouTubeで解説付き!)。LangChain様、ありがとうございます。
そもそもRAGとは?
RAGは「Retrieval Augumented Generation」の略で、「検索拡張生成」のことです、と言われてもわかりませんが、rag-from-scratchでは以下のように述べられています。
Retrieval augmented generation (RAG) has emerged as a popular and powerful mechanism to expand an LLM's knowledge base, using documents retrieved from an external data source to ground the LLM generation via in-context learning.
つまり、「ユーザーの質問を基にデータベースからデータを検索し検索結果を踏まえて(=拡張)AIに回答を生成させること」です。これを使うとAI(流行のChatGPTとかです)が持っていないデータを与えて回答を生成させることができるので、自社のナレッジを与えて社内FAQなどの作成もできるようになります。また、AIへの情報の与え方がテキストによる質問となるため、Fine-tuning(AIの各パラメータなどを調整し再学習させること)と比べて非常に容易です。さらに、回答精度もFine-tuningと比べて良い結果になる報告もあります。
これだけ聞くと良いことづくめのRAGですが、回答の内容が質問に関連しない、関連するがデータが抜け落ちるなどの課題があります。これらの課題を改善し、回答精度を向上させる様々な手法が、rag-from-scratchではRAGの場面毎に述べられています。
場面毎に工夫すべき点を考える
RAGは①Indexing、②Retrieval、③Generationの順に行われます。
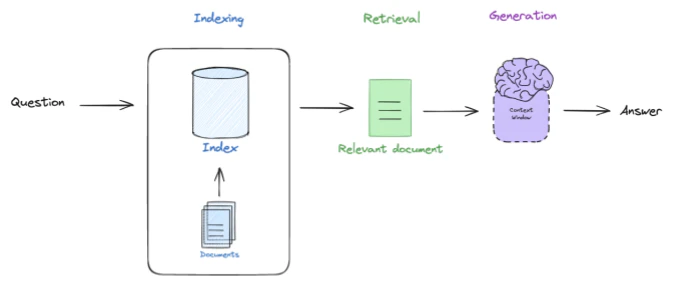
①Indexing
まず、AIに与えるためのデータを加工し、データベース(以下DB)に保存します。工程としては以下の順となります。
- データの読み込み(図のDocuments)
- データの分割(図のSplits)
- 検索用にデータを変換(図のEmbedding)
- DBに保存(図のVectorstore)
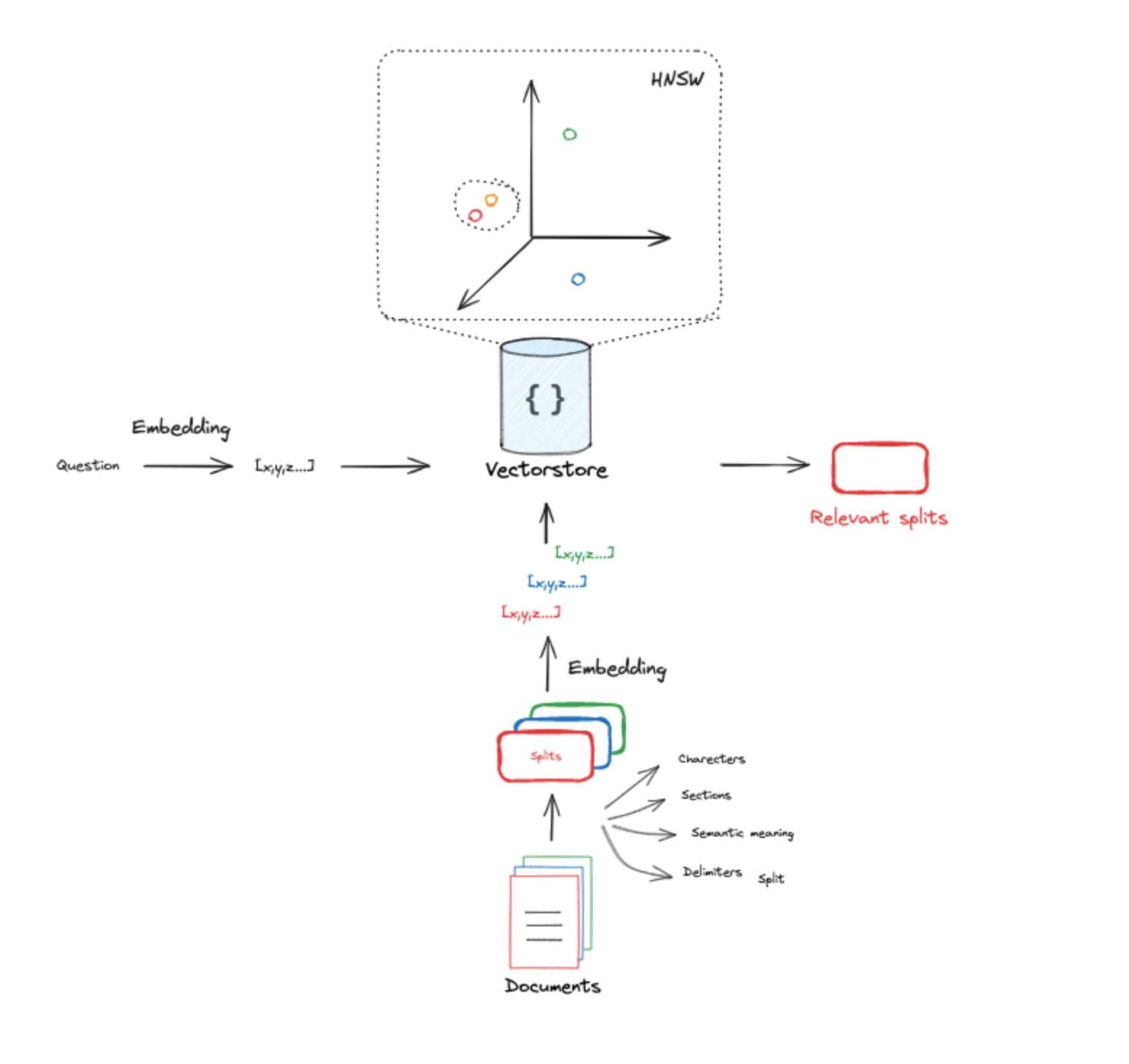
引用:rag_from_scratch_1_to_4.ipynb
1. データの読み込み
データの形式毎(.pdf, .xlsxなど)に読み込みます。LangChainを用いても良いですが、スクラッチでももちろんできます。この後の工程も、できる所はスクラッチでの実装がおすすめです。LangChainは便利ですが、フレームワークのためアルゴリズムが見えにくいのと、回答精度に直接影響を与える細かい所の制御が難しいためです(データの分割とか)。スクラッチの場合は、例えばPythonでPDFならPyMuPDFなどを使います。
以上より、工夫すべき点は以下になります。
| 場面 | 工夫すべき点 | rag-from-scratch |
|---|---|---|
| Indexing | データの読み込み | N/A |
2. データの分割
読み込んだデータは適切な単位に分割する必要があります。なぜならAIに与えられるデータ量には上限があるのと、以下のようにデータ量が大きいと回答精度が悪くなる報告もあるためです。
分割方法としては、固定長、区切り文字、ページ単位など様々ですが、分割された単位(以下チャンク)でデータの検索が行われ、質問に織り込まれます。
以上より、工夫すべき点は以下になります。
| 場面 | 工夫すべき点 | rag-from-scratch |
|---|---|---|
| Indexing | データの分割 | Semantic Splitterなど |
3. 検索用にデータを変換
DBから検索する際はユーザーの質問と各チャンクの類似度を計算し、類似度が大きいチャンクを質問に織り込みます。類似度を計算するためにはチャンクをベクトル化する必要があり(類似度はベクトル同士で計算するので質問もベクトル化します)、ベクトルモデル(text-embedding-3-largeなど)を使ってチャンクをベクトルに変換後、DBにインデックスとしてベクトルと変換前のデータを保存します。このインデックスをキーにデータの検索が行われます。
以上より、工夫すべき点は以下になります。
| 場面 | 工夫すべき点 | rag-from-scratch |
|---|---|---|
| Indexing | 類似度計算 | ColBERTなど |
| 検索用のインデックス | Parent Documentなど |
4. DBに保存
ベクトルを用いるためベクトルDB(Chromaなど)を用います。ベクトル検索に加えてキーワード検索やグラフ検索を合わせたハイブリッド検索にも対応できるDB(Neo4jなど)もあります。
以上より、工夫すべき点は以下になります。
| 場面 | 工夫すべき点 | rag-from-scratch |
|---|---|---|
| Indexing | DB | N/A |
②Retrieval
IndexingによりデータがDBに保存された後は、質問と関連するデータを検索します(図のRelevant documents)。
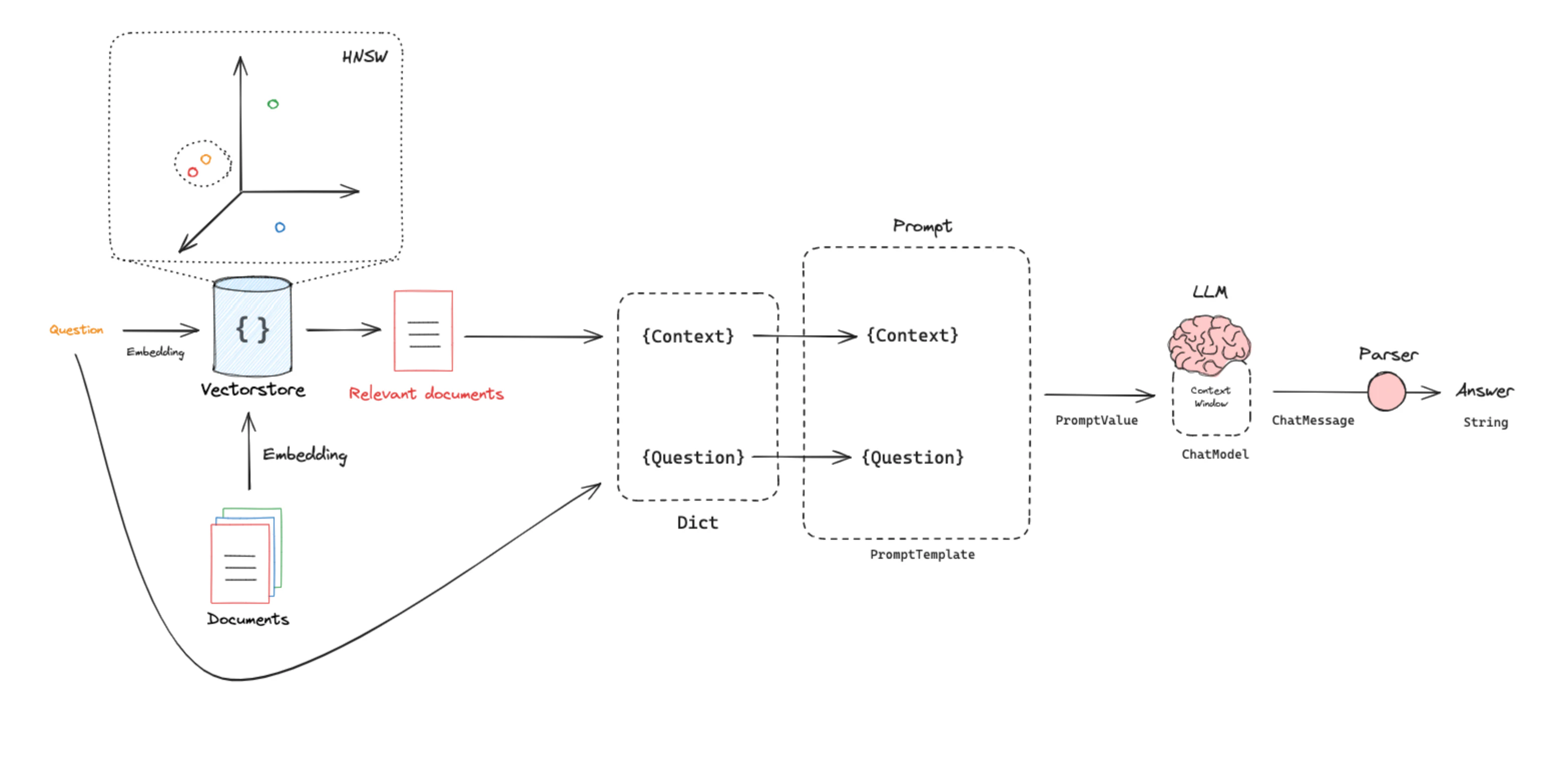
引用:rag_from_scratch_1_to_4.ipynb
例です。
質問:
社員が休暇を申請する際のフローについて教えてください。
ベクトルDBの検索結果:
検索結果1: 社内規定第5章: 休暇
検索結果2: 上司に口頭またはメールで申請意図を伝える。
検索結果3: 勤怠管理システム(e.g., WorkFlow)にログインし、
類似度計算の結果、質問に関連するチャンクとして検索結果1~3が候補として挙げられています。これらを次の③Generationで質問に追加し、AIに問い合わせを行います。よって、質問により検索結果が変わるため質問内容は重要です。また、データの検索場所・検索方法・検索結果の並び替えもポイントとなります。
以上より、工夫すべき点は以下になります。
| 場面 | 工夫すべき点 | rag-from-scratch |
|---|---|---|
| Retrieval | 質問 | Multi-queryなど |
| 検索場所 | Logical routingなど | |
| 検索方法 | Text-to-SQLなど | |
| 検索結果の並び替え | Re-Rankなど |
③Generation
質問と関連するデータを検索した後は、検索結果を質問に織り込み、AIに問い合わせを行い回答を生成します(図のDict~Answer)。
引用:rag_from_scratch_1_to_4.ipynb
例です。
質問:
社員が休暇を申請する際のフローについて教えてください。
以下の検索結果を踏まえて回答してください。
# 検索結果1: 社内規定第5章: 休暇
# 検索結果2: 上司に口頭またはメールで申請意図を伝える。
# 検索結果3: 勤怠管理システム(e.g., WorkFlow)にログインし、
AIの回答:
社員が休暇を申請する際のフローは以下のとおりです:
上司への連絡: 社員は、まず直属の上司に口頭またはメールで休暇申請の意図を伝えます。
勤怠管理システムへの申請: 次に、勤怠管理システム(例: WorkFlow)にログインし、休暇申請を行います。
これらのステップは社内規定第5章に基づいて実施されます。
AIの回答を見ると、質問に織り込まれた検索結果を踏まえて回答していることがわかります。このように、検索結果の質問への織り込み方法は、回答精度に直接影響を与えるため重要です。また、回答形式の固定化や回答の評価もポイントになります。
以上より、工夫すべき点は以下になります。
| 場面 | 工夫すべき点 | rag-from-scratch |
|---|---|---|
| Generation | 検索結果の質問への織り込み | N/A |
| 回答形式の固定化 | N/A | |
| 回答の評価 | Self-RAGなど |
まとめ
以上より、場面毎に工夫すべき点をまとめると以下になります。rag-from-scratchでは詳しく言及されていないものもあります。
| 場面 | 工夫すべき点 | rag-from-scratch |
|---|---|---|
| Indexing | データの読み込み | N/A |
| データの分割 | Semantic Splitterなど | |
| 類似度計算 | ColBERTなど | |
| 検索用のインデックス | Parent Documentなど | |
| DB | N/A | |
| Retrieval | 質問 | Multi-queryなど |
| 検索場所 | Logical routingなど | |
| 検索方法 | Text-to-SQLなど | |
| 検索結果の並び替え | Re-Rankなど | |
| Generation | 検索結果の質問への織り込み | N/A |
| 回答形式の固定化 | N/A | |
| 回答の評価 | Self-RAGなど |
デバッグ
上記①〜③を実行する中で、なかなか精度が出ない時はデバッグが必要ですが、@jw-automation様の記事が素晴らしかったので引用させていただきました。補足として、本記事に照らすと以下①クエリ=質問、②ドキュメント=データとなります。
上手く行かなかった場合は、①クエリの問題なのか、②ドキュメントの問題なのか、③RAGの実装の問題なのかを見極めながら対処していく必要があります。
簡単なチェックポイントとしては、「自分がそのクエリとドキュメントを渡されて回答できるか?」という事を考えてみるのが良いのではないかと思います。
自分でも回答できないのであればそもそものインプットが悪いという話になりますし、自分なら回答できるという事であれば、検索と応答生成の問題のため、RAGの実装を見直した方が良いでしょう。
引用:RAGの実装戦略まとめ
おわりに
本記事では、RAGの回答精度向上のためにはどこを工夫すべきかについて、基礎的な所を中心に整理してみました。
RAGに唯一絶対の正解はなく、ユースケース毎に様々な手法があります。いずれはAIが人間並(以上)に進化し、どのようなユースケースでも回答精度100%も難しくないかもしれません。
AI、人間超えた説もタイムリーに出てきました。
参考文献