はじめに
前回「ChatGPTを社内に配ってもあまり使われない本当の理由」において、素のChatGPTを配っても思ったより社内で使われないのは、ChatGPTは社内情報を持っていないからという事を書きました。
つまり、ChatGPTを社内情報にも精通したエキスパートとして業務でも使っていくには、公開データではない社内情報をいかにChatGPTに読み込ませるかという事がポイントになります。
Fine-Tuningという選択肢ももちろんありますが、学習情報のアップデートや制御と評価、情報公開先の権限設定等の運用面の難しさもあり、また、以下のMSの論文でも、複数タスクでの比較で、Fine-TuningよりRAGのほうがパフォーマンスが良いという実験結果が紹介されています。
参考:Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
一長一短ではあるので、一概にどちらが良いというわけではありませんが、現時点ではおそらくファーストオプションとなるRAGについて、RAGの精度向上に使える主要な拡張手法をまとめつつ、RAGの実装戦略について考えていきたいと思います。
RAGの拡張手法
RAGの拡張手法については、アイディアベースの物も含め上げだすときりがないのですが、今回はOSSでも実装されている主要な拡張手法を中心にまとめていきます。
| # | 手法 | 概要 |
|---|---|---|
| 1 | ハイブリッドサーチ | 複数の検索方式の組み合わせによる検索性能の向上 |
| 2 | リランキング | 検索で得た文書に対して、再度ランク付けを行い、関連性が高い文書のみを利用 |
| 3 | サブクエリ | 複合的なクエリをサブクエリに分解して、それぞれのレスポンス結果を統合 |
| 4 | HyDE | クエリに対する仮回答を生成させ、仮回答で検索 |
| 5 | ステップバックプロンプト | クエリを一段抽象化させ、抽象化したクエリへの検索結果も合成して回答 |
| 6 | RAG Fusion | 類似クエリを生成させ、各クエリでの検索結果を統合して回答を生成 |
| 7 | マルチステップクエリ | クエリの分解と段階的な推進により、回答を洗練させる手法 |
| 8 | チャンク拡張 | 検索でヒットした前後のチャンクもコンテキストに含める |
| 9 | Pandas Dataframe | CSVのようなデータテーブルの構造を保ったままクエリが可能 |
| 10 | TextToSQL | 自然言語をSQLに変換して、データベースから必要な情報を抽出 |
それでは以下、簡単なデモを含めながら個別に説明していきます。
1. ハイブリッドサーチ
こちらは、性質の異なる複数の検索方式(例えばベクトル検索とキーワード検索)を組み合わせて検索精度を向上させる手法になります。
各検索方式単体の場合に比べ、性質の異なる検索方式を組み合わせ、ある種いいとこ取りをする事で、検索性能の向上が期待できます。
今回はBM25でのキーワードベースの類似度検索と通常のベクトル検索を組み合わせていきます。
BM25について簡単に説明しておくと、文脈や文章構造は完全に無視した上で、文書内の単語を全てバラバラに分割し、文書内の各単語の出現頻度と文書間におけるレア度を加味した特徴量を算出します。
つまり、特定の文書内の各単語の数をカウントしてヒストグラムを作れば、似たような文書には同じような単語がよく出るはずなので(同じようなヒストグラムの形になるので)、類似度が高くなる性質を持つという特徴量になります。
ただ、どの文書にもよく出る単語は特徴量としてあまり意味をなさないので、文書間のレア度も加味しており、特定の文書にしか出ない単語については、その重みを大きくする事で、特徴量としての表現力を上げています。
時系列的な話をすると、TFIDFやBM25といった手法がメジャーであった所にBERTが出てきて、単語や文章の意味を踏まえてベクトル化するという流れが出てきました。
つまり、これらはどちらかというと古典的な機械学習の手法に分類されますが、Azure AI Searchや様々な検索エンジンでも現役で使われている有用な手法になります。
パッと聞いただけだと「単語単位でバラバラにしてしまって大丈夫なの?」という気がするかもしれませんが、あくまで意味理解ではなく文書の類似度検索の範囲では色々とメリットが出てきます。
特に重要になるのが固有名詞です。というのも、社内情報には世間で使われる事のない多数の固有名詞があり、検索の際はその固有名詞がキーになることが少なくありません。
一方でベクトル検索は、文章全体を意味ベクトルに変換するため、全体的な意味は上手く捉える事ができますが、固有名詞を含む各単語の影響自体は薄くなってしまいます。
BERTが出た頃にやった事がある人は肌感があるかと思いますが、ニュースのカテゴリ分類やネガポジ分析といったマクロ的な処理は上手い一方で、固有名詞が多数入る社内文書の類似度検索は、TFIDFやBM25のように、固有名詞を含め、単語をそのまま使える手法のほうが精度が出たりします。
つまり、意味に強いベクトル検索とキーワードに強いBM25の検索のハイブリッドにする事で、検索精度を向上させるという目的になります。
少し前置きが長くなりましたが、簡単なデモで見ていきましょう。
サンプルは何でも良いのですが、今回は「DXレポート2.2」を使っていきます。
少し極端な例ではありますが、分かりやすさを重視するために、全14ページのPDFの中で1箇所だけ出てくる、以下の「プラットフォーム」という単語を狙いたいと思います。
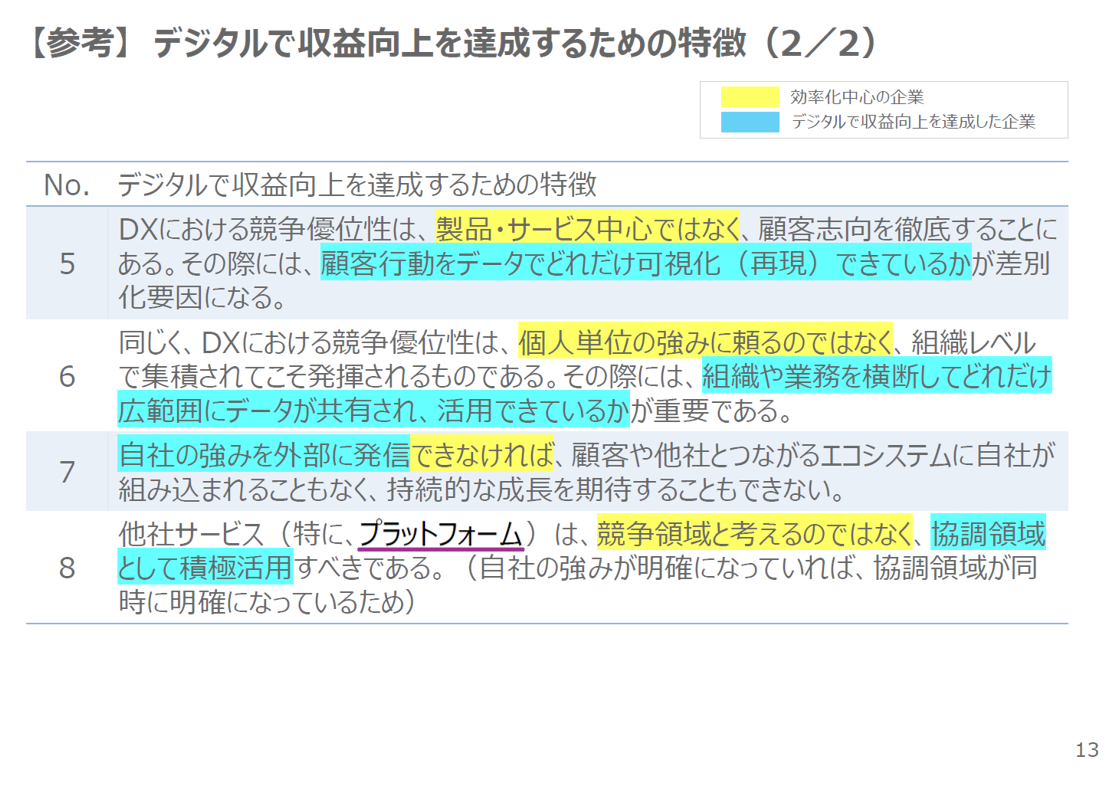
「プラットフォームについての言及はありますか?」というクエリに対する、ベクトル検索とBM25の検索結果の違いを、それぞれチャンクの上位5個までを抽出して見てみます。
まずはベクトル検索からです。
■ベクトル検索での類似チャンク取得結果(上位5個)

プラットフォームについて言及されている箇所(p13)は含まれていますが、順位としては4番目であり、類似度も0.8以下となっています。
デフォルトの取得チャンク数設定(上位2個)や、類似度の閾値のカットオフを使う場合は(0.8以上のみ取得等)、無関係なチャンクとして落としてしまう可能性があります。
続いてBM25での検索結果です。
■BM25での類似チャンク取得結果(上位5個)

こちらはベクトル検索と違い「プラットフォーム」という単語が含まれるp13が最上位に来ています。
このように、意味ベクトルに変換せずに単語をそのまま使えるため、特定の名称にヒットしやすいという利点が見てとれます。
単なる全文検索ではなく、クエリに含まれる各単語の出現パターンと類似したチャンクを取得してくれるため、ベクトル検索の苦手な所を上手くカバーしてくれる手法と言えます。
以下のMSのベンチマークでも、キーワードベースの検索とベクトル検索を組み合わせたハイブリッド検索の精度が高く出るという結果が報告されています。

引用:Azure AI Search: Outperforming vector search with hybrid retrieval and ranking capabilities
ハイブリッド検索があらゆるケースで良いというわけではないですが、ベクトル検索で上手くヒットしない場合は、ハイブリッド検索を試してみるというのは有効な選択肢になるかと思います。
2. リランキング
続いてリランキングを見ていきます。
リランキングは先ほどのように検索で取得したチャンクを、更にクエリとの類似度が高い順に並び変える手法になります。
ベクトル検索は意味的な検索ができると言いましたが、文章表現を一つの意味ベクトルに押し込んでいるため、一定の情報量は当然落ちています。
そこで、より表現力の高い言語モデルを使って、クエリと抽出したチャンクの類似度を再算出し、類似度の高い順に再度並び変えた上位チャンクのみを使うという手法になります。
「再検索するぐらいなら、なぜ最初から使わないの?」と思うかもしれませんが、ベクトル検索が単純なベクトルの内積計算であるのに比べ、言語モデルは計算コストが非常に高く、ドキュメント全体に適用するのは現実的ではないからです。
そのため、ベクトル検索やBM25で幅広く関連しそうなチャンクを取得し、その上で、リランキングによって上位チャンクだけを抽出するという形にする事で、LLMにコンテキストとして渡す参照情報の精度を上げる事ができます。
Azure AI Searchのセマンティックランキングでも、BM25等で上位50チャンクを先に抽出してから、リランクするというパイプラインになっています。
リランキングにはTransformerやLLMを使うものがありますが、今回はSentenceTransformerを使ったリランキングを試していきます。
リランキング自体は各種OSSに実装されているため、簡単に試す事ができます。
以下が、先ほどのベクトル検索結果をリランキングさせた結果です。
■ベクトル検索のリランキング結果

先ほどは4番目だったp13の該当箇所がトップの順位になっています。
このように、ベクトル検索やハイブリッド検索等で幅広く検索したチャンクをリランキングした上位チャンクだけに絞ってLLMに渡す事ができます。
しかし、Transformerを使うのは計算資源的にハードルが高い面もあるため、このリランキングをLLMにやらせるという方法もあります。
以下がLlamaIndexのLLMRerankのプロンプトサンプルですが、やっている事はシンプルで、クエリと文章を渡してクエリと関連度の高い順に並びかえさせています。

最初のベクトル検索の結果をLLMRerankに渡した場合も、先ほどと同じようにp13が最上位に並び変えられます。
ただ、Rerankは2段階のプロセスになる以上、少なくともレスポンス時間は伸びるため、こちらも通常のベクトル検索で不十分なケースでの利用を検討するのが良いでしょう。
特に、規模の大きなドキュメントから、多少レスポンスを犠牲にしても精度良く取りたいというケースでは重要になるかと思います。
ちなみに大量のコンテキストをそのまま渡さずに、Rerankで上位チャンクのみを渡す事がなぜ重要なのかについては、後半のコンテキスト長の長さの影響の箇所で改めて触れたいと思います。
3. サブクエリ
こちらは、入力クエリをそのままベクトル化して検索に利用するのではなく、入力クエリをサブクエリに分解し、それぞれのサブクエリでのレスポンスを最後に合成して回答するという手法になります。
特に入力クエリが複雑な場合や、複合的な意味を持っている場合に有効な手法と言えます。
こちらも実際の例を見ていきましょう。サンプルとして、DXレポートに関する以下のクエリを考えてみます。
■入力クエリ
「低位安定とデジタル産業宣言の意味をそれぞれ教えて」
このクエリは1文ですが、意味的には2つの事を聞いている複合的なクエリになっています。
このままベクトル化すると、どちらの意味も兼ねるような中間的なベクトルが生成され、文書内の類似度を検索する事になりますが、この2つは独立の項目であるため、中間的なベクトルでの検索によって、どちらにもヒットしにくくなるという可能性が出てきます。
一方で、入力クエリを意味的に分解したサブクエリにする事で、それぞれの意味を保持した上で、類似度の検索ができます。
実際に生成されたサブクエリと回答は以下になります(少し長いですが、そのまま載せます)。
■入力クエリ
「低位安定とデジタル産業宣言の意味をそれぞれ教えて」
■LLMによって生成されたサブクエリ
サブクエリ1:低位安定の詳細な定義とその意味は何ですか?
サブクエリ2:デジタル産業宣言の詳細な定義とその意味は何ですか?
■サブクエリへの回答
【サブクエリ1への回答】
"低位安定"は、ユーザー企業とベンダー企業が固定された関係を指します。この関係では、ユーザー企業はITを活用して業務の効率化を目指し、仕様を作り、ITベンダーを競争させてITコストを削減します。一方、ベンダー企業は労働量に対する対価として値付けし、低リスクのビジネスを享受します。しかし、この関係はベンダー任せになることでIT対応能力が育たず、ITシステムがブラックボックス化し、ベンダーロックインにより経営のアジリティが低下します。また、顧客への迅速な価値提案ができなくなり、低い利益水準により多重下請け構造が生じ、売り上げ総量の確保が必要となります。さらに、労働量が下がるため生産性向上のインセンティブが働かず、低利益率のため技術開発投資が困難になります。これらの結果、"デジタル"の提案ができなくなります。
【サブクエリ2への回答】
デジタル産業宣言は、デジタルを活用して収益向上を達成する特徴を全社に浸透させるための「行動指針」であり、社会運動論的アプローチの実践にあたり、経営者自らの「価値観」を外部へ発信するために策定されます。この宣言は、DX推進の規範的企業から得られた項目を基に、経営者の理解を高めるために5項目に集約されています。さらに、経営者が自らの宣言として練り上げることを意図しています。
■最終レスポンス
低位安定は、ユーザー企業とベンダー企業が固定された関係を示す用語です。この関係では、ユーザー企業はITを活用して業務の効率化を目指し、ITベンダーを競争させてITコストを削減します。一方、ベンダー企業は労働量に対する対価として値付けし、低リスクのビジネスを享受します。しかし、この関係は一連の問題を引き起こす可能性があります。
一方、デジタル産業宣言は、デジタルを活用して収益向上を達成する特徴を全社に浸透させるための行動指針です。これは、経営者自らの価値観を外部へ発信するために策定され、DX推進の規範的企業から得られた項目を基に、経営者の理解を高めるために5項目に集約されています。
ーーーーーーーーーーーーーー
複合的なクエリが個別のサブクエリに分解され、ある種シャープな検索と回答が実現できています。
クエリの分解と回答の合成は同期させる必要がありますが、サブクエリ単位の処理は並列化できるため、サブクエリが増えた分、線形でレスポンスが遅くなるというわけではありません。
ユースケースにもよりますが、特に入力クエリが複雑であったり、長い傾向にある場合、そのままベクトル化するよりもサブクエリ単位で処理する方が効果的な場合があるかもしれません。
4. HyDE
HyDEはHypothetical Document Embeddingsの略で、入力クエリを直接ベクトル化させるのではなく、LLMに仮の回答を作らせて、その仮の回答をベクトル化して検索に使うという方法です。
このモチベーションがどこにあるのかというと、ベクトル検索は、入力クエリとドキュメントの類似度が高い箇所を検索しますが、これはいわば、Q&Aで言うと、QとAを当てにいく関係なるので、必ずしもそれが近いとは限らないからです。
例えば、ドキュメントにレストランの情報の一覧があったとして、「何か美味しい物が食べたい」というクエリとドキュメントのレストランの情報の類似度が高いかと言うと、必ずしもそうとは限りません。
それよりも、「何か美味しい物が食べたい」というクエリに対して、LLMに仮の回答を生成させ(例えば「近くに〇〇料理のお店があります」というような仮回答)、その仮回答で検索させたほうが、Q&Aで言うと、A同士でヒットさせる事になるので、特にクエリと回答の内容が大きく異なるようなケースで有効になるのではないかという事です。
論理的には確かにそうだなと思いつつも、LlamaIndexのドキュメントにも上手くいかないケースについての言及があるため、今回はあえて失敗する事例を載せておきます。
DXレポートに対して、「低位安定とは?」というクエリで試してみましょう。
低位安定自体は、以下の意味になります。
「低位安定とは、ユーザー企業とベンダー企業が固定された関係にある状態を指します。この状態では、ユーザー企業はITの活用目的として業務の効率化を追求し、ITベンダーを競争させてITコストを削減します。一方、ベンダー企業は労働量に対する対価として値付けし、低リスクのビジネスを享受します。しかし、この関係はIT対応能力の育成や迅速な価値提案、技術開発投資などの面で問題を引き起こす可能性があります。」
それでは、HyDEを使って「低位安定とは?」に対する仮の回答を生成させてみましょう。結果は以下です。
■クエリ
低位安定とは?
■HyDEによる仮回答
低位安定とは、気象学の用語で、大気の状態を表すものです。これは、地表近くの空気が冷たく、高度が上がるにつれて空気が暖かくなる状態を指します。この状態では、地表近くの冷たい空気は重く、上昇することが難しくなります。その結果、大気は安定し、乱流や積乱雲の発生が抑制されます。このような状態は、晴れた日によく見られます。また、低位安定は大気汚染物質が地表近くに滞留しやすい状態を作り出すため、大気質にも影響を与えます。
仮回答自体はLLMに生成させるため、このように必ずしも期待するような範囲の回答ではない可能性があります。
これでベクトル検索をしても、意味が全く異なるため、むしろ検索精度が落ちてしまうでしょう。
もちろんHyDEが有効な場面もあるかと思いますが、そもそもRAGにおいてはLLMの自由度の高さをどう制御して行くかという事が重要なポイントであり、HyDEの場合は、内部でLLMの生成処理が更に入るので、制御の複雑さが一段上がってしまうとも言えます。
入力クエリと参照すべきドキュメントの類似度が低いケースでは有効な手法となる可能性がある一方、仮回答の生成と制御がそもそも難しいという点は認識しておく必要があるかと思います。
5. ステップバックプロンプト
こちらは入力クエリをそのまま利用するのではなく、一段抽象化した質問内容(ステップバック質問)を生成し、入力クエリとステップバック質問それぞれで検索を行う手法になります。
ステップバック質問のサンプルは以下です。
入力クエリ:理想気体の圧力Pについて、温度が2倍に増加し、体積が8倍に増加した場合、圧力Pはどう変化しますか?
ステップバック質問:この質問の背後にある物理学の原理は何ですか?
入力クエリ:エステラ・レオポルドは1954年8月から11月の間にどの学校に通っていたか?
ステップバック質問:エステラ・レオポルドの教育歴はどうなっているか?
つまり、入力クエリを一段抽象化させる事によって、入力クエリに対してピンポイントで該当箇所がないケースでも、ステップバック質問の検索結果と合成する事で、推論が可能になるケースがあります。
以下が原論文からのイメージです。

引用:Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
ステップバックプロンプトはRAGに関係なく使える手法ではありますが、RAGで使う場合は、以下のように入力クエリのコンテキストとステップバック質問のコンテキストを合わせて回答を生成させます。
response_prompt_template = """You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.
{normal_context}
{step_back_context}
Original Question: {question}
Answer:"""
こちらも一見良さそうな手法ですが、HyDEと同様に、LLMによる生成がもう一つ入る事になるので、制御が難しいという側面があります。
例えば以下のようなケースです。
入力クエリ:大谷翔平は2010年に何をしましたか?
ステップバック質問:2010年に特定の人物が何をしたか?
この場面での期待値としては、「大谷翔平の経歴は?」というような質問の生成でしたが、大谷翔平自体が抽象化され、2010年にどのような出来事が起こったか?にフォーカスが当たってしまっています。
ただし、抽象化という意味では間違いではなく、この問題設定で難しいのは、抽象化して欲しい箇所と抽象化して欲しくない箇所が暗黙的に存在するという事です。
実際のステップバック質問の例では、ケース毎にFew-shotプロンプトを用意して、この辺りの期待値を制御しようとしています。
ユーザーのクエリがかなりピンポイントで、対向のドキュメントとの意味的な粒度が揃っていない場合に検索精度が向上する可能性がありますが、こちらもLLMの生成処理が内部でもう一つ入るという制御の難しさは認識しておく必要があるかと思います。
6. RAG Fusion
こちらは入力クエリに類似したクエリをいくつか生成し、それぞれのクエリの検索結果を統合した上で、上位に来るチャンクを回答に利用するという方法です。
入力クエリだけでなく、類似したクエリをLLMに複数生成させて検索する事で、関連性の高い箇所を幅広く取得する事が期待できます。
類似クエリでも上位に来るチャンクは重要なチャンクだという仮定で、簡単に言えば投票制で、重要なチャンクを取得する方法になります。
RAG Fusionの基本的な流れは以下です。
■RAG Fusionの流れ
- 類似クエリの生成:LLMを用いて、入力クエリに類似するクエリを複数生成
- 検索:入力クエリと生成された類似クエリそれぞれで検索を実行
- リランキング:各クエリの検索結果のランキングを統合し、上位チャンクを取得
- レスポンス:リランキングで抽出された上位のコンテキスト情報を元に、回答を生成
やっている事は非常にシンプルで、以下のLangChainの記事の図がわかりやすいです。
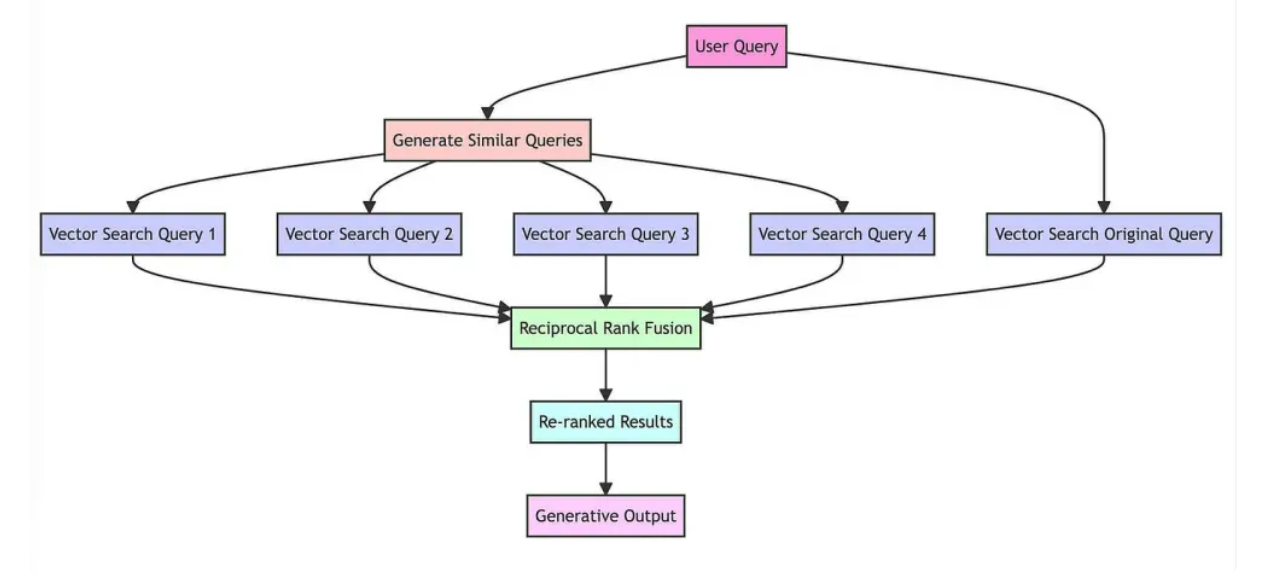
引用:Query Transformations/LangChain
この図では、検索がベクトル検索となっていますが、Reciprocal Rank Fusionは単純に順位で統合するため、異なる検索手法の結果も統合する事ができます。
つまり、ベクトル検索とBM25のようなハイブリッド検索でも利用可能で、生成した類似クエリをベクトル検索とBM25にそれぞれ投げた上で最終的に結果を統合させることができます。
以下、RAG Fusionのサンプルです。
■入力クエリ
低位安定とは?
■生成された類似クエリ
- 低位安定の定義とは?
- 低位安定の具体的な例
- 低位安定の理論とその応用
- 低位安定に関する研究文献
■最終的な回答
低位安定とは、ユーザー企業とベンダー企業が固定された関係にある状態を指します。この状態では、企業はITシステムの効率化やコスト削減を目指し、ITベンダーと競争させる一方で、ベンダー企業は労働量に対する対価として低リスクのビジネスを享受します。しかし、この関係はIT対応能力の育成を阻害し、ITシステムがブラックボックス化する可能性があります。また、ベンダーロックインにより経営のアジリティが低下し、顧客への迅速な価値提案が困難になる可能性があります。
ーーーーーーーーーーーーーーー
今回は問題設定が簡単なのであまり有用度がわかりにくいかもしれませんが、生成された類似クエリを見てみると、入力クエリ単体に比べて、関連箇所を幅広くヒットさせられるイメージが湧くのではないでしょうか。
HyDEやステップバックプロンプトに比べると、単一の生成ではなく多数決のような状態になるので、頑強性の高さの面でも使いやすい手法なのではないかと思います。
幅広く検索させるものの、こちらもサブクエリと同様に並列化できる点も、大きな利点の一つになります。
7. マルチステップクエリ
こちらはサブクエリやRAG Fusionのような並列的な手法とは異なり、多段階の推論を順番に実施していく方式になります。
サブクエリと同様にクエリを分解しますが、並列に処理するのではなく、各クエリの回答を踏まえて、次のクエリが生成されます。
つまり、各クエリとその回答の結果を踏まえて次のクエリを生成するという事を繰り返して、回答を段階的に洗練させながら、最終的なアウトプットを生成するという手法になります。
以下が概略図ですが、1つ目の質問に対する回答の「Y Combinator」が次の質問で使われている事がわかります。

いわばReActやエージェントのような動きなので、精度は上がるだろうなと思いつつ、直列でしか処理できないため、レスポンスの待ち時間として許容できるかという事が論点になるかと思います。
8. チャンク拡張
こちらは、特に具体的な名前がついているわけではない非常に単純な手法ですが、検索でヒットしたチャンクの前後のチャンクもコンテキストに含めてLLMに渡すという方法になります。
というのも、検索にヒットしたチャンクの前後には、その内容の前提となる情報なども含め関連性の高い情報がある可能性が高いため、検索には直接ヒットしないものの、コンテキストとしては渡したほうが回答精度が高くなる事が期待できるためです。
チャンクサイズ自体を大きくするというのも一つですが、チャンクを大きくすればするほど、ベクトルとしては情報が薄くなるため、チャンクサイズをあまり大きくすると検索精度が下がるという報告も出ています。
実際にベクトル検索をやってみると、文脈として前後の情報も渡した方が良さそうだなと思う場面は少なくないので、シンプルな手法ではあるものの、ユースケースによっては、試してみると効果的に機能するかもしれません。
9. Pandas Query
ここからは少し毛色が違いますが、CSVなどのテーブルデータの処理に関してです。
小さいCSVであればテキストのまま処理しても上手くいきますが、一定大きなCSVの場合は、通常のテキスト処理とチャンク分割ではデータテーブルの構造が落ちてしまうので、テーブル構造を保持したまま処理する事が重要になります。
今回は、以下の5列からなる従業員サンプルデータ1000行を使っていきます。
■サンプルデータ(1000行の従業員データ)

こちらに対して、通常のベクトル検索と、Pandasで処理できるPandasQueryを使っていきます。
まずは通常のベクトル検索です。
| # | クエリ | ベクトル検索での回答 |
|---|---|---|
| 1 | 従業員は全部で何名いますか? | 従業員は合計で57名います。 |
| 2 | 加藤陽一さんの従業員IDを教えて下さい | 従業員IDに関する情報は提供されていませんので、加藤陽一さんの従業員IDを提供することはできません。 |
| 3 | 山口淳さんの所属部署は? | 山口淳さんの所属部署についての情報は提供されていません。 |
| 4 | マーケティング部と開発部にはそれぞれ何名いますか? | マーケティング部には7名、開発部には13名います。 |
| 5 | 2020年以降に入社した人は何名いますか? | 2020年以降に入社した人は15名います。 |
ちなみにこれは全て間違っています。
いわゆる合計のような演算が必要な処理の場合は、チャンク分割で処理する事はできない上に、ヘッダ情報は最初のチャンクにしかないため、所属部署や従業員IDのような情報を上手く認識できていない事がわかります。
続いてPandasQueryを見てみましょう。わかりやすいように、内部で生成されているPandasの処理も記載します。
| # | クエリ | 内部で自動生成されたPandasの処理 | PandasQueryの回答 |
|---|---|---|---|
| 1 | 従業員は全部で何名いますか? | df['従業員ID'].count() | 1000 |
| 2 | 加藤陽一さんの従業員IDを教えて下さい | df[df['名前'] == '加藤陽一']['従業員ID'].values[0] | 9 |
| 3 | 山口淳さんの所属部署は? | df[df['名前'] == '山口淳']['所属部署'].values[0] | 人事部 |
| 4 | マーケティング部と開発部にはそれぞれ何名いますか? | df[df['所属部署'].isin(['マーケティング部', '開発部'])]['所属部署'].value_counts() | 開発部214, マーケティング部188 |
| 5 | 2020年以降に入社した人は何名いますか? | df[df['入社日'].apply(lambda x: int(x.split('/')[0]) >= 2020)].shape[0] | 429 |
こちらは全て正解であり、いわゆるコードインタープリターのような形で、自然言語の入力クエリから必要な内部クエリを自動で生成し、データフレームへのクエリ結果をレスポンスとして返しています。
テーブルの構造を維持したまま処理できるうえに、CSVのサイズが大きくなっても、実体はプログラム処理なので、LLMの消費トークン自体は非常に小さいという特徴があります。
10. TextToSQL
こちらは、以前別の記事でも記載しましたが、自然言語でのデータベースからの検索になります。
データベースの接続情報だけを渡しておくと、自然言語の入力クエリをインプットに、テーブル名やカラム名からSQLを自動で生成・実行して、最終的な回答を返してくれます。
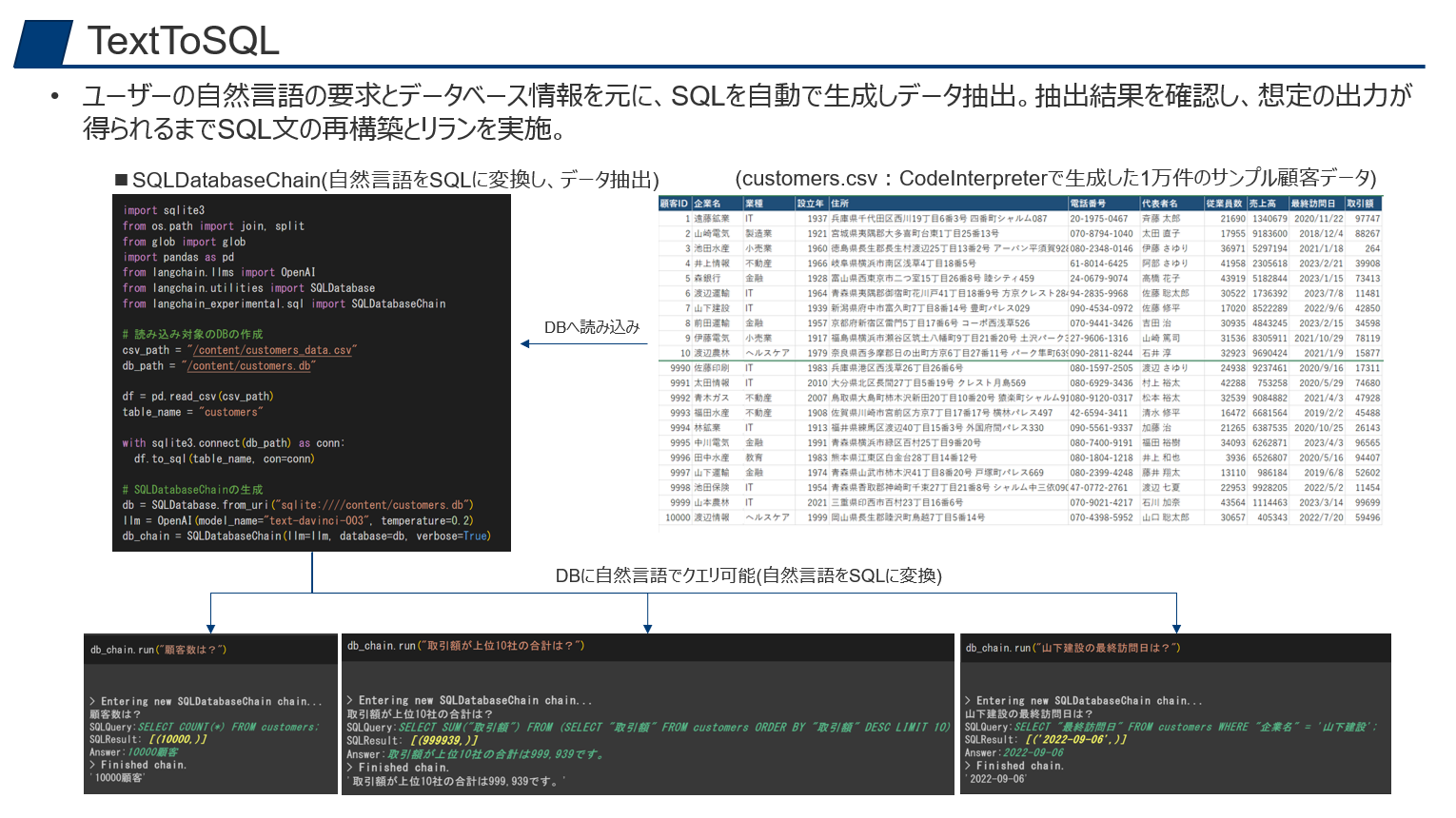
インプットがCSVの場合は、Pandas Queryを使えば良いですが、社内のデータベースをインプットにしたい場合はこちらを利用するのが良いでしょう。
テーブルやカラムの個別説明なしでも、テーブル名やカラム名から自動で類推してくれるので、SQLがわからないユーザー向けの翻訳ツールとして機能します。
基本的には標準的なBIをなるべく用意するべきかとは思いますが、チャットベースでピンポイントにデータベースの情報を取得できるようになると、データの利活用と民主化が進むのではないでしょうか。
SQLが一回で上手く生成できないケースは当然あるので、Agentで回すのが良いかと思います。
RAGの拡張手法に関する所感
ここまで色々と紹介してきましたが、個人的にはハイブリッドサーチとRAG Fusionの組み合わせのコスパが良さそうだなと感じました。
ユーザーからのインプットが複合的なクエリになりがちなケースの場合は、サブクエリも効果的かもしれませんが、どちらかというとユーザーからのクエリはシンプルすぎて困るケースのほうが多いので、RAG Fusionで横に拡張してあげると機能するケースが多いのかなと思います。
RerankerでTransformer系を使うのは、GPU等の環境面でのハードルが高いため、LLMベースがまずは手軽かなと思いますが、トークン数が増えるのと、レスポンスは当然遅くなるので、その辺りも踏まえた上での採用検討になるかとは思います。
数行程度のテーブルであれば、テキストとしてそのまま読み込んでも大丈夫ですが、一定のサイズのあるテーブルデータの場合はトークン数的にも限界があり、またテーブルの構造的な意味を落とさないようにPandas QueryやTextToSQLを使うのがマストになると思います。
様々な拡張手法があるものの、LangChainの記事にも「There is no "one-size-fits-all" solution because different problems require different retrieval techniques.」との記載があるように、RAGの拡張手法については、とりあえずこれをやっておけば良いというベストプラクティスはないので、あくまでパターンとして把握しておき、対象のユースケースに合わせて要否を検討していく事が重要になります。
実際のRAGの進め方
ここまでRAGの拡張手法についてまとめてきましたが、実際にRAGを進める際は、とにかく実装を頑張れば良いという訳ではなく、以下の3つを分けて考える必要があります。
①ユーザークエリに問題がないか
②参照ドキュメントに問題がないか
③RAGの実装に問題がないか
そもそも論として、AIがやっているのはインプットを元にしたアウトプットへの変換処理なので、インプットが悪ければ良いアウトプットは出せません。
つまり、ユーザーから渡されたクエリと参照ドキュメント自体の質が悪ければ、どれだけAIが賢くても良いアウトプットは出せないという事です。
あなたがどれだけ賢かったとしても、よくわからない指示と、誰もメンテしていないマニュアルを渡された場合に上手く仕事を進められないのと同じ話です。
つまり、プロトタイプで上手く行かなかった場合は、①クエリの問題なのか、②ドキュメントの問題なのか、③RAGの実装の問題なのかを見極めながら対処していく必要があります。
簡単なチェックポイントとしては、「自分がそのクエリとドキュメントを渡されて回答できるか?」という事を考えてみるのが良いのではないかと思います。
自分でも回答できないのであればそもそものインプットが悪いという話になりますし、自分なら回答できるという事であれば、検索と応答生成の問題のため、RAGの実装を見直した方が良いでしょう。
インプット自体が悪い状態でRAGの実装をひたすら頑張るのは、大量のノイズや欠損データを含むビッグデータを渡されたエンジニアが、ディープラーニングのチューニングだけをひたすら頑張るのと同じ話で(結局精度が出ないので)、まず見直すべきは上流のインプットになります。
ユーザークエリの改善については、自由入力をやめてみるというのも1つポイントになるかと思います。
というのも、自由入力は必ずしもユーザビリティが高くないからです。
例えば、AIアシスタントに「今日は何が食べたいですか?何でも言って下さい」と言われるより、「今日は何が食べたいですか?イタリアンであれば、近くに有名な〇〇のお店がありすぐに予約が取れます。中華料理であれば~~、和食であれば~~」というように、何でも聞いてという形より、提案型で、ある種考える範囲を絞ってもらうほうが楽という場合もあると思います。
つまり、自由入力で全てをユーザー側に考えさせるのではなく、適切に誘導させながら対象範囲を絞っていくという形にする事で、ユーザーも、そのインプットを受け取るAIも楽になる可能性があります。
自由入力のインプット枠だけ用意して、「意図がよくわかるように詳細に入力して下さい」とユーザーにお願いするのは無理があるので、プルダウンや聞き返す等のアクションも利用しながら、AIに入る前の入力の質を上げる設計も重要な考慮ポイントになります。
ドキュメントの改善については、クレンジングの観点で、AIに校正させるという事も一つの有効な手になります。
誤字脱字や重複箇所、記載内容が不明瞭な箇所や、複数のドキュメントで記載内容が矛盾している箇所などのチェックを全て人手でやるのは難しいので、校正の補助プロセスでAIを使い、クレンジングしてからインデックス化するというのが、まずはそれほど手間をかけずに実施できる施策かと思います。
プログラミングにおけるコーディングチェックツールのような位置付けで、ドキュメントの自動チェックをパイプライン化してしまうと尚良いかもしれません。
なかなか一筋縄にはいかないですが、端的に言ってしまうと、ドキュメント全体がMECEになっていれば、ベクトル検索で問題なく取得できるはずで、優秀な人が作る、誰にとっても読みやすいドキュメント(構成の綺麗なドキュメント)は、AIにとっても読みやすいと言えます。
いかにAIにコンテキスト情報を渡すかという事が論点になっていく世界感においては、そのベースとなるナレッジマネジメントがある種最も重要になるかもしれません。
いずれにしても、エンジニアに実装だけ丸投げしても上手くいかないので、「どこがボトルネックなのか?」という事を見極めて、プロジェクトとして対処していく必要があります。
入力可能なトークン数が長くなるとRAGはやらなくても良い?
最近リリースされたLLMモデルの特徴として、入力可能なトークン数が大幅に増えたという点があります。
gpt4は最大約32,000トークンですが、gpt4-Turboでは128,000トークン、Gemini Pro1.5では最大約100万トークンまで処理可能というような情報が出ています。
この情報を見ると、「入力可能なトークンが増えたんだから、もうRAGでベクトル検索とかやらずに全部コンテキストに突っ込めばいいんじゃないの?」という疑問が湧いてきます。
これに関しては、今時点で何とも言い難いのですが、少なくとも、コンテキスト長が長くなるほど、LLMの精度が下がるという事象が報告されている事は頭に置いておいたほうが良いと思います。
以下、論文からの抜粋になりますが、10万や100万トークンというレベルよりはるかに小さい、3000トークン以下でも、インプットのトークン数の増加に伴う精度の低下が報告されています。
(テキストの赤い塗りつぶしが関連する箇所、それ以外が無関係な箇所で、右に行くほど、無関係なインプットも渡されている状態)

また、こちらのMSの論文でも同様に、インプットとして渡すドキュメント数が多くなるほど精度が下がるという事象が報告されており、加えて、重要なドキュメントがプロンプトの中盤に位置していると精度が落ちる(先頭や最後を重視する傾向にある)という興味深い事象も報告されています。
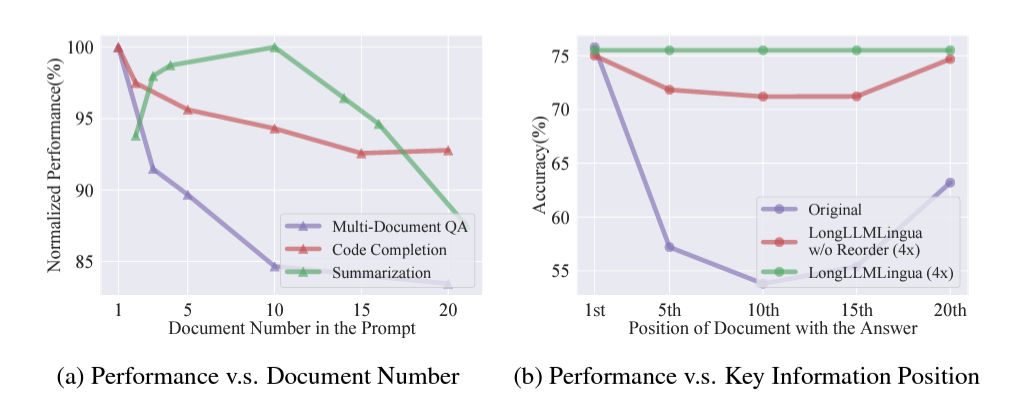
引用:LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
上記を踏まえると、ほぼ無関係なものも含むドキュメントを大量に渡して、この中から関連個所を見つけて回答してというのは、手放しで採用できる方式ではないのではないかと思います。
ベクトル検索で関連箇所を抽出し、更にリランカーで先頭から並び替えたものをインプットにすると精度が高くなるというのは、上記の結果からも筋が通っているのではないでしょうか。
そもそも、トークン数が大幅に増えるというのは、タスクとしては当然より難しくなるので、精度としてはトレードオフにならざるを得ません。
極端な言い方をすると、精度を度外視して良ければ、いくらでも入力トークン数自体は増やせるはずなので、入力トークン数が増加したモデルが発表された場合は、単純に以前より良くなったという訳ではなく、精度は担保できているのか?という視点が重要になるかと思います。
普段からよく使っている人は、取得するチャンク数(simirality-top-kのサイズ)を単純に大きくするとプロンプトの指示をあまり守らなくなったり、大量文章の要約で中盤がやや軽視されているような事象を体感されているのではないかと思います。
そもそも無関係なものも全て渡すというのは、消費トークン数も常に大きくなりますし、おそらく管理の収集がつかなくなるため、どちらかというとドメイン単位でインデックスを分け、対象ドキュメントに対するRAGの最適化も含めてモジュール化し、上手くルーティングさせる方法を考える方が運用面や効率面を踏まえても良い気がします。
もちろんコンテキスト長が長くなると精度が低下する事象については、LLMの開発者達も当然認識しているはずなので、徐々に改善していくのではないかと思います。
ただ、今のところ、とにかく最大長に収まるなら何でも突っ込んで良いという話ではない事は意識しておく必要があるかと思います。
まとめ
いかがだったでしょうか。
今回はRAGの拡張方式の紹介を中心に、ボトルネックとして検討すべきポイント、コンテキスト長の増加に伴うRAGの考え方について簡単に記載しました。
拡張手法は色々とありますが、いわゆる銀の弾丸はなくユースケースに大きく依存するため、今回紹介した手法やそれ以外の手法も含めて引き出しとして持っておき、いかにPDCAを速く回せるかが重要になるのではないかと思います。
試行錯誤を重ねながら既に前に進んでいる企業と、抽象度の高い机上ベースの議論に留まっている企業に少しずつ差が出てきている印象のため、RAG実装を含む、生成AIの利活用を進める一助になれば幸いです。