はじめに
次の "小さい1" 万能チューリングマシンに関する論文から、UTM(2, 18)について理解するために作ったメモです。
https://www.sciencedirect.com/science/article/pii/S0304397596000771
したがって、以下に書くものはこの論文を私なりに解釈したものの羅列であり、私の主張ではありません。また、論文からも意味がずれている可能性があります。ご了承ください。
数学徒ではないので大雑把な解釈が多いです。ので、元論文と一緒に読むことを想定しています。
事前知識
- この論文を読むには、チューリングマシンとは?という概念を理解することが必要です。説明は他の方がたくさんされていると思うので、ここでは省略します。(他力本願)
- UTM(2, 18) とは、内部状態が(たった)2つ、テープ状の記号が18つである万能チューリングマシンを指します。この論文では、そのようなマシンが構成できることが示されています。
- カードゲームの始祖、「Magic: the Gathering」がチューリング完全であることもこのチューリングマシンを用いて証明されています。2
Abstract
この論文では、以下の、状態及び(テープに書き込む)記号数を持つ万能チューリングマシンが存在することを証明しています。(今回興味があるのはUTM(2, 18)のみです。)
| クラス名 | 状態数 | 記号数 |
|---|---|---|
| UTM(24, 2) | 24 | 2 |
| UTM(10, 3) | 10 | 3 |
| UTM( 7, 4) | 7 | 4 |
| UTM( 5, 5) | 5 | 5 |
| UTM( 4, 6) | 4 | 6 |
| UTM( 3,10) | 3 | 10 |
| UTM( 2,18) | 2 | 18 |
1. Introduction
割愛。
2 - 事前知識
- TM を、チューリングマシンの略称とします。
- TMの様相(Configuration)とは、TMの現在の状態です。
- 内部状態、現在のテープに書き込まれている記号、現在のヘッドの(相対的な)位置の3つをまとめたものです。
- タグシステム(tag-system)とは、計算模型の一種です。3
- 帰納的関数(Recursive function)とは様々な条件から再帰的に定義される関数の種類です。4
私は数学に明るくないので「計算可能な関数」ととることにします。 - 帰納的集合(Recursive set)とは、その集合の各要素が、集合に属しているかを判断する関数が帰納的関数であるような集合です。5
- 普遍関数(Universal function)とは、ある自然数$i$を引数としてとり、それを変えることによって引数の数が1つ少ないすべての関数を表すことができるような関数です。6
例: $Ψ(y, x_1)$が普遍関数であるなら、yを変化させることで任意の$f(x_1)$と値を一致させることができる。- $F_M(α)$ という関数(後述)に対して$Ψ(n, α)$という普遍関数を定義する、という文脈で使われているようです。
- 部分関数(Partial function) とは、入力の一部にしか値が定義されていない関数です。7
- ゲーデル数(Godel number)とは、ここでは、チューリングマシンの各構成要素 (テープ記号や内部状態...)を数値化したものです。8
- 違う構成のチューリングマシンのゲーデル数は、違う数値になると思われます。
- 創造的集合(Creative set)とは、その集合の任意の部分集合だけを区別できるような計算可能な関数がその各部分集合ごとに上手く定義できる(well-defined)ような集合だと思われます...たぶん。
2. Equivalent definitions for universal Turing machines
ここでは、チューリングマシンに関する沢山の用語定義をしています。
(しかし、後の話の構成にあまり影響があるわけではないので、UTM(2,18)の構成方法だけ知りたいなら定義1以降をとばして3に飛ぶことをお勧めします。)
-
$α, β$ は、あるTMの様相です。
-
$β↓$ は、この様相が最後である、という事実です。
- この様相でチューリングマシンが停止することを示しているようです。
-
$β_1 \xrightarrow{M} β_2$ は、Mの様相が 1ステップによって $β_1$から$β_2$へと変化したことを示します。
-
$β_1 \overset{M}{\Rightarrow} β_3$ は、Mの様相が 任意のステップによって $β_1$から$β_3$へと変化したことを示します。つまり、例えば $β_1 \xrightarrow{M} β_2 \xrightarrow{M} β_3$ を表します。
-
$B$は、全てのチューリングマシンの様相すべての集合です。
-
$B_M$は、Mをある特定のチューリングマシンとしたとき、Mの様相すべての集合です。
- $B$も$B_M$も帰納的集合であることが知られています。
-
$ F_M(α) = β$ は、チューリングマシン$M$ が、様相$α$を変化させ、最終的に様相 $β$ で停止することを示します。
- この定義は、本文中では次の様に記されています。
F_M(α) = β \text{ if and only if } α \overset{M}{\Rightarrow} β, \text{ where } α,β \in B_M \text{ and } β↓- $\mathrm{Def}(F)$ は関数$F$の定義域を示します。
- $\mathrm{Val}(F)$ は関数$F$の値域を示します。
これより下は、さらに複雑な定義(多分こっちが本題なんだけど)をしています。
定義1
ここでは、あるチューリングマシンが万能チューリングマシンであるかどうかの定義をしています。私はとりあえず大雑把に解釈しました。
- チューリングマシンUが万能チューリングマシン(Universal) であるとは、入力を様相に変換した後にチューリングマシンを通し、停止した際の様相を出力に変換したものが、普遍で帰納的な部分関数である、ということです。
- もっと大雑把に言うと、万能チューリングマシンは普遍で帰納的な部分関数として解釈できるTMの事です。
この定義の中で、二つの関数の概念が定義されています。
- 符号関数 (coding function) とは、長さが固定されている任意の入力をチューリングマシンUの様相に変換する関数の事です。$ρ()$で表されます。
- この記事では、「符号関数を用いて入力を変換し、出力としてAを得ること」を「Aに符号化する」と呼ぶことにします。
- 復号関数 (decoding function) とは、チューリングマシンUの様相を、普遍関数の出力に変換するような関数です。$λ()$で表されます。
- この記事では、「復号関数を用いて入力を変換し、出力としてAを得ること」を「Aに復号化する」と呼ぶことにします。
この関数2つを踏まえて大雑把な解釈を言い直すと、
- チューリングマシンUが万能チューリングマシン(Universal) であるとは、任意の2入力を、Uの様相に符号化したものを、チューリングマシンに入力し、TMが停止したときの様相を復号化した結果が、同じ入力をある普遍で帰納的な部分関数に通したものと一致する、ということです。
備考1
上の定義1は、ほぼDavisという人の定義と一致するようです。
定義2
ここでは、あるTMが別のTMをシミュレートするとはどういうことかという定義をしています。
- チューリングマシンMがチューリングマシンTをシミュレートするとは、Tの全ての様相について、「その様相をMについての様相に符号化したものを、それにMを適用し、終了した際の様相をTについての様相に復号化したもの」が、「それにTを適用し、終了した際の様相」と一致するような符号関数と復号関数が存在することです。
- 大雑把にいうと、あるTについての様相をいい感じに解釈したものをMに通すと、同じ様相から始まったTの終了時の様相と一致することです。
備考2
上の定義2は、Hermanという人の定義を元にしたものだそうです。
定義3
はじめに、次の定義があります。
- $T_n$はゲーデル数が$n$であるようなチューリングマシンです。
上の定義を踏まえ、ここでは、あるチューリングマシンが万能チューリングマシンであるかどうかの別の定義をしています。
- チューリングマシンUが万能チューリングマシン(Universal) であるとは、次の二つを満たすことです。
- Uは各チューリングマシンTをシミュレートすることができる。
- そのTの様相をUについての様相に変換する符号関数と復号関数を、効率的(effectively)に得ることができる。
- 別の言い方をすると、Uが万能TMであるとは、任意の様相$α$($α\in B$)と、任意のチューリングマシンTについて、以下の二つの条件を満たすことです。
- 次の二つの関数が存在すること
- 「Tのゲーデル数を与えると、αをUの様相に符号化する符号関数としてふるまう関数」
- 「Tのゲーデル数を与えると、Uの様相をTの様相に復号化する復号関数としてふるまう関数」
- 様相$α$から始めてTを実行したときと、符号関数と復号関数を用いてUを実行したとき、終了した様相が等しいこと
- 次の二つの関数が存在すること
備考3
定義3 の「Tのゲーデル数を与えると、復号関数としてふるまう関数」は、単に「復号関数としてふるまう関数」(=復号関数)としても良いそうです。
定理
ここでは、次に示す事柄が正しいということを言っています。
- 定義1と定義3による万能チューリングマシンの定義は等価です。
つまりUが任意のチューリングマシンTをシミュレートすることができ、その方法も知ることができる(定義3を満たす)なら、そのTMは定義1を満たすということです。
補助定理群 (Lemma)
数学難しいし、私はまずはUTMの組み立て方が分かればいいのでスルーします。
ここでは、なんやかんやで 定理 が証明されたとします。
定義4
ここでは、万能チューリングマシンのまた別の定義を紹介しています。
- Maltsevさんによれば、チューリングマシンTが万能チューリングマシン(Universal) であるとは、そのTMが受け入れる様相の集合が創造的集合であることです。
私は、「入力される様相を、計算可能な関数によっていくらかのグループに分けることができるならばそれは万能チューリングマシンである」と解釈しました。(多分違う)
備考4
この定義4は定義1及び定義3による万能TMの定義よりは広いそうです。
定義4の定義だと定数関数しか受け取らないチューリングマシンが存在するからだそうです。
私の頭はこの辺りで解釈をやめていました。
3-事前知識
- 語(word) とは、あるシステムが処理する記号の羅列です。(ここではタグシステム$T$)
- 例: abbcab
- アルファベット(alphabet) とは、語を表す記号の事です。
- 例: {a, b, c, d}
- 文字(letter) とは、今注目している語を構成するアルファベットの事です。
- 空語(empty)とは、長さ0の語のことです。
- TM $U$ の記号(symbol)とは、ここではチューリングマシン $U$ が使うテープ上の記号の事です。
- チューリングマシンでは、記号を、対応する記号に書き換えることであたかも「記号に印がついた」ように見せることを良く行います。
例: $b$ を $b'$ に書き換える、等 - 次の章では、万能TMの構成に関する一般的な方法が述べられています。解説にあたり、万能TMの構成ごとに異なる個所では、「適切に」という表現を用いることにします。
3. Preliminaries: How to construct a universal Turing machine
ここでは、万能チューリングマシンの構成する方法についての予備知識(Preliminaries)が示されています。
まず、この論文において、これから定義されるいくつもの万能チューリングマシンは、タグシステムをシミュレートするとしています。そして、そのタグシステムの説明が続いています。
- 処理対象の語を$β$とします。 m-タグシステムとは、$β$に対して次の処理を繰り返し、その処理が出来なくなるか、$β$の先頭がある特定のアルファベットであった時点で停止するシステムです。
- 処理:$β$の先頭からm文字を消し、(消す前の)$β$の先頭だった値によって決められる語を$β$の右端に付け加える。
タグシステムについては、このブログが参考になります。(脚注2と同じ)
定義5
ここでは、タグシステムの丁寧な定義をしています。
-
タグシステムとは、「正の整数 $m$ 」「有限個のアルファベット $A$ 」「アルファベット $A$ の要素を並べた語を、別の、文字の並びに変換する規則 $P$」の3つの要素で構成される組です。
- とくに、m-タグシステムとは、正の整数 $m$ を用いるタグシステムの事です。
- タグシステムの 生成物(production) とは、規則 $P$ が生成する文字の並びです。
- 生成物は、通常、以下で表されます。
- 入力のアルファベット1文字をある語(生成物)に置き換える操作
- $a_{n+1}$ の時に停止する操作
- 生成物は、通常、以下で表されます。
- $a_{n+1}$ は、アルファベット $A$ の内の1つであり、いわゆる終了記号です。
- 処理対象の語を $β$ とします。タグシステムの計算は、次のステップで行われます。
- $β$ の最初の $m$ 文字を消去する
- その消去した最初の文字に対する生成物を$β$に付け加える。
- 上の2つの処理を $β$ の長さが $m$ 文字以下になるか、$β$の最初の文字が $a_{n+1}$ になるまで繰り返す。
定義後、タグシステムの例が記述されています。
-
例
次のような規則 $P$ によって表される2-タグシステムを考えます。
a_1 \rightarrow a_2 a_1 a_3 \\
a_2 \rightarrow a_1 \\
a_3 \rightarrow STOP \\
この2-タグシステムに語 "$a_2a_1a_1$" を与えると、以下の様に動作します。
a_2a_1a_1 \rightarrow a_1a_1 \rightarrow a_2a_1a_3 \rightarrow a_3a_1
解説を加えると、こう:
| 現在の語 | 消す語 | 生成物 | 次の語 |
|---|---|---|---|
| $a_2a_1a_1$ | $a_2a_1$ | $a_2 \rightarrow a_1$ | $a_1a_1$ |
| $a_1a_1 $ | $a_1a_1$ | $a_1 \rightarrow a_2a_1a_3$ | $a_2a_1a_3$ |
| $a_2a_1a_3$ | $a_2a_1$ | $a_2 \rightarrow a_1$ | $a_3a_1$ |
| $a_3a_1$ | STOP |
Minskyさんによって、2-タグシステムである万能チューリングマシンが存在すると証明されているそうなので、これ以降はタグシステムといえば2-タグシステムを指すことにするそうです。
この2-タグシステムには以下の制約が追加されています。
- 語の長さが2未満になっても停止しない。(停止記号によってのみ停止する。)
- 生成物は空語ではない。(必ず1文字以上の何かを語の後に付け加える。)
そして、ようやく、タグシステムをシミュレートする万能チューリングマシンの構成方法に着きました。(今は論文の220ページ目です。)
これ以降は、チューリングマシン $U$ を用いて、タグシステム $T = (2, A, P)$ をシミュレーションしたい として説明されています。
- $A$ はアルファベットの集合です。
- $A$に含まれている、各アルファベットを $a_i$ とします。$a_1, a_2$ ...から $a_{n+1}$ まであります。
- $P$ は生成規則です。
- アルファベット $a_i$ を受け取って語$α_i$を返します。
タグシステム $T$ を、チューリングマシン $U$ の上で次のように構成します。
-
タグシステム $T$ の各文字は、記号列$u$を、$N_i$回繰り返したもので表されます。
- $u$ は、TM $U$の記号を 適切に 並べたものです。
- $N_i$ は、各文字ごとに 適切に 決められた正の整数です。
- $A_i$ は、こうして表現された、 $T$ の各文字に対する$U$の記号の列です。
- (一般的には、1つの文字に対して表現形式が二つありますが、UTM(2, 18)では1つしか用いません。)
-
上の様にして、文字を変換したものを並べる時、TM $U$の記号を 適切に 並べた記号列で区切る必要があります。この記号列は2種類ある場合があります。
- (そうしないと記号列($u$)がいくつ繋がっているか分かりませんし... )
- マーク(separation mark, または単にmark)とは、この区切り記号列です。
-
タグシステム $T$ の文字を変換する生成規則の内1つ ($P_i$) は、規則が出力する語の各文字を、逆順に並べたもので表されます。
例えば、$T$においてある文字を語abcに変換する規則は、次の様に表されます。
[cを$U$上で表したもの] [区切り] [bを$U$上で表したもの] [区切り] [aを$U$上で表したもの]
- タグシステム $T$ の最初の語 ($β$) は、その語の各文字を、その順番で並べたもので表されます。
- $S$は、こうして表現された、タグシステム$T$の最初の語に対応する、$U$の記号の列です。
例えば、タグシステム$T$がaabという語から開始するということは、次の様に表されます。
[aを$U$上で表したもの] [区切り] [aを$U$上で表したもの] [区切り] [bを$U$上で表したもの]
これまでの定義を用いて、($T$をシミュレートする、)万能TM $U$ のテープは、以下の状態で初期化されます。
Q_LP_{n+1}P_{n}...P_1P_0 S Q_R
$U$の最初のヘッドの位置は、UTM(2,18) の場合、$P_0$を表す記号の内、最も右の記号です。
- $Q_L$, $Q_R$ は 適切に 決められた空白記号の列です。無限の長さを持ちます。
- (テープの長さは無限ですからね)
- $P_0$は、 適切に 決められたマークの列です。
これで概念的な構成方法が分かりました。つづけて、動作原理が説明されています。
チューリングマシン U の動作原理の概説
まず、TM $U$の目指す動作について:
- タグシステム $T$ 上で $β_1$ という語が $β_2$ に変換された場合、つまり $β_1 \overset{T}{\rightarrow} β_2$ という変換が起きたとき、このタグシステムをシミュレートするTM $U$ は以下のように変化します。($S_1$を$β_1$のTM $U$上での表現とします。$S_2$も$β_2$を同様に表します。)
Q_LP_{n+1}P_{n}...P_1P_0 S_1 Q_R \overset{U}{\Rightarrow} Q_LP_{n+1}P_{n}...P_1P_0 RS_2 Q_R
- ここで、$R$ は「文字を消すことによって生まれる空白記号列」を表しています。実行が進むほど長くなります。
- 空白記号は例によって 適切に 決められています。
- $P_0$ は、TM $U$ のいくつかの記号を並べた列です。ここの長さが実行について重要です(後述)。
- $\overset{U}{\Rightarrow}$ であることに注意してください。タグシステムの1ステップに対してTMは何ステップも動作します。
そして、TM $U$ の動作は次の3ステップに分かれるようです。
-
手順1: まず、タグシステム $T$ の語の先頭文字に対応する生成規則( $P_r$ ) を探しに行き、見つけておきます。その後戻ってきて先頭文字2つを表す記号列を( $A_rA_s$ の2つを)消去します。
-
手順2: 次に、見つけた生成規則が生成する語を、テープの右端 ($Q_R$の位置) に書き込みます。(生成規則は逆に表されているので、この書き込みは逆順になります。)
-
手順3: 最後に、1. と 2. を実行するために変更した記号を元に戻します。
-
ここで、先頭のアルファベットを表す記号列($A_r$)とそのアルファベットに対応する生成規則($P_r$)の間には、必ずそのアルファベットごとに決まった長さの記号列があります。先頭文字の表現が含む繰り返し数(つまり、$A_r$がもつ$u$の数)は、この長さと深く関係があるように決定されます。
続いて、上の手順を踏むごとにTM $U$のテープの状態がどう変わるかが説明されています。
-
手順1の後:
Q_LP_{n+1}P_n ... P_{r+1}P_rP_{r-1}'P_1'P_0'R'A_r'A_s'A_t' ... A_wQ_R
TM $U$のヘッドは$A_r'$と$A_s'$ の間のマークを指しています。
- この後、今指しているマークを消す(特定の記号に置き換える)ことで、文字の表現$A_r$と$A_s$がくっつき、手順2の中で完全に消去されます。
- $A_r$に対応す る生成規則$P_r$を見つけていることに注目してください。
-
手順2の後:
TM $U$のヘッドは、記号列$P_r''$のもっとも左の記号を指しています。
Q_LP_{n+1}P_n ... P_{r+1}P_r''P_{r-1}''P_1''P_0''R''A_t ... A_wA_{r1}A_{r2} ... A_{rm_r}Q_R- $A_{r1}A_{r2} ... A_{rm_r}$は生成規則$P_r$の生成する語を表現した物です。
- 生成規則が生成する語の表現がテープの右端に書き込まれ,、しかも$A_r$と$A_s$が消去されていることに注目してください。
-
手順3の後:
TM $U$のヘッドは、記号列$R$のもっとも右の記号を指しています。
Q_LP_{n+1}P_n ... P_1P_0RA_t ... A_wA_{r1}A_{r2} ... A_{rm_r}Q_R- 実行中に変化した記号達(ダッシュ記号がついていたやつ)が元に戻っているのに注目してください。
このようにチューリングマシンの構成の概説をした後、最後に具体的な構成の解説の為にある記述方法の定義をして終わっています。
- TM $U$上の記号列$a$と$b$を用意します。この時、
- aRb は、「TMのヘッドがaを右(R)に移動していった結果、その部分がbに書き換えられる」ことを表します。
- aLb は、「TMのヘッドがaを左(L)に移動していった結果、その部分がbに書き換えられる」ことを表します。
- 例えば、「10L01」は、「TMのヘッドが10を読みながら左に移動していった結果、その部分が01に書き換えられた」ことを表します。
- Ra(b)L は、「TMのヘッドが右(R)に移動していきながらaを読んだとき、ヘッドの移動方向が左(L)に代わり、しかもその部分はbに書き換えられる」ことを表します。
- La(b)R は、「TMのヘッドが左(L)に移動していきながらaを読んだとき、ヘッドの移動方向が右(R)に代わり、しかもその部分はbに書き換えられる」ことを表します。
4-9
今回はUTM(2,18)にしか興味が無いので、ここは省略します。
10-これまでのポイントのおさらい
初期のテープ
($T$をシミュレートする、)万能TM $U$ のテープは、以下の状態で初期化されます。
Q_LP_{n+1}P_{n}...P_1P_0 S Q_R
$U$の最初のヘッドの位置は、UTM(2,18) の場合、$P_0$を表す記号の内、最も右の記号です。
文字の表現
タグシステム $T$ の各文字は、記号列$u$を、$N_i$回繰り返したもので表されます。
$N_i$は、「そのアルファベットの表現が先頭に来た時の、対応する生成規則との距離」に深く関係があります。
生成規則の表現
- タグシステム $T$ の文字を変換する生成規則の内1つ ($P_i$) は、規則が出力する語の各文字を、逆順に並べたもので表されます。
語の表現
- タグシステム $T$ の最初の語 ($β$) は、その語の各文字を、その順番で並べたもので表されます。
10. The UTM with 2 states and 18 symbols
ここでは、ついにUTM(2,18)の具体的な構成を説明しています。
-
UTM(2, 18)は、テープ状の記号が18つで、状態は2つの万能チューリングマシンです。
-
空白記号は、$\overleftarrow{1}$ です。
- ややこしいことに、$\overleftarrow{1}$は空白記号以外の意味にも用いられます。
- 各アルファベットは、記号$"1"$ ($ = u$)を、一定の回数繰り返すことで表現されます。
- (i+1)種類目のアルファベットの表現の繰り返し回数($N_{k+1}$)は、i種類目のアルファベットの表現の繰り返し回数($N_k$)を用いて、以下の様に決められます。
- 1種類目のアルファベットの表現は、1回
- (i+1)種類目のアルファベットの表現は、[(i種類目のアルファベットの繰り返し回数) + (i種類目のアルファベットに対応する生成規則が出力をする語の文字数) + 1] 回
- i種類目のアルファベットに対応する生成規則は、以下で表されます。(bの周辺に注意!)
P_i = bb(\text{"1"の繰り返し})1b(\text{"1"の繰り返し})1 ... (\text{"1"の繰り返し})1b(\text{"1"の繰り返し})- bはマーク(区切り記号)と論文にはありますが、実質的に1bをマークとみなすことになります。
- 特に、生成規則の最も右にある部分($P_0$)は、$bb$で表されます。
- 特に、終了を表す生成規則($P_{n+1}$)は、$\overleftarrow{c_1}\overleftarrow{c_1}$ で表されます。
- タグシステムTの最初の語は、以下で表されます。
S = (\text{"1"の繰り返し})c(\text{"1"の繰り返し}) ... c(\text{"1"の繰り返し})c(\text{"1"の繰り返し})c- cはマーク(区切り記号)です。
-
空白記号は、$\overleftarrow{1}$ です。
-
この万能TMのコントローラーは、以下のように動作します。(論文よりコピー)
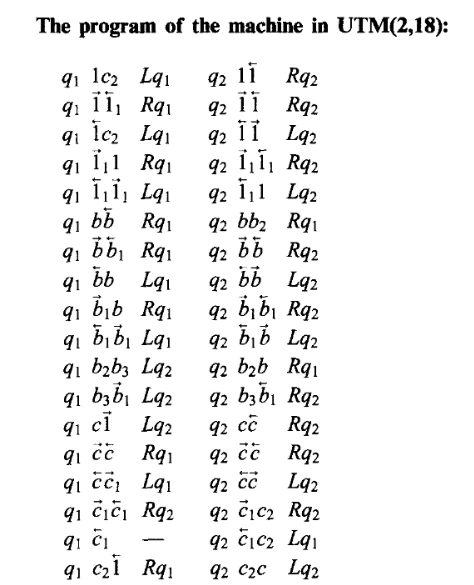
残りの部分はなぜこの動作でいいかが順を追って説明されています。
(初期化)
まず、テープは、以下の状態で初期化されます。(再掲)
Q_LP_{n+1}P_{n}...P_1P_0 S Q_R
$U$の最初のヘッドの位置は、$P_0$を表す記号の内、最も右の記号( $b$ )です。
手順1
この手順では、先頭文字に対応する生成規則を見つけることを目的とします。マーク$c$をみつけたら、そのマークを消去し、次の手順に行きます。
-
まず、先頭文字を構成する$1$を見つけに行きます。
c_2\ R\ \overleftarrow{1} \\ b\ R\ \overleftarrow{b} -
$1$を見つけたら、向きを変えて...
R\ 1\ (c_2)\ L -
それに対応するマーク$b$(生成規則の区切り記号)を見つけるまで戻っていきます。
1\ L\ c_2 \\ \overleftarrow{1}\ L\ c_2 \\ \overleftarrow{b}\ L\ b \\ -
その$b$を書き換えたらまた$1$を探しに行きます。
L\ b\ (\overleftarrow{b})\ R -
そうして、最終的に、マーク$c$に到達したら消して次の手順に行きます。
q_1\ c\ \overrightarrow{1}Lq_2(上は、内部状態が$q_1$の時に$c$を読んだら、それを$\overrightarrow{1}$に書き換え、左に移動し、状態が$q_2$になることを示します。)
この処理の後、テープは以下のようになっているはずです:
Q_LP_{n+1}P_n ... P_{r+1}P_rP_{r-1}'P_1'P_0'R'A_t' ... A_wQ_R
$A_r$と$A_s$ の間の区切り記号を書き換えたことにより、$A_r$と$A_s$は$R'$に吸収されてしまいました。
ヘッド位置は$R'$の中にあり、状態は$q_2$になります。
手順2
この手順では、手順1で発見した生成規則ひとつの各文字をテープの後ろに書き写していきます。ステップ1では、文字内の$1$を書き写していきます。ステップ2では、文字が切り替わるときの$b$を処理します。この2つのステップをループします。
生成規則の先頭($bb$)に到着したら、この手順は終了します。
ステップ1
このステップでは、生成規則から$1$をとってきて末尾に追加します。
-
まず、印がつけられていない生成規則を探しに戻っていきます。
\overleftarrow{1}\ L\ \overrightarrow{1} \\ \overleftarrow{c}\ L\ \overrightarrow{c} \\ \overleftarrow{b}\ L\ \overrightarrow{b} \\ -
その生成規則を構成する$1$を見つけたら折り返して...
L\ 1\ (\overleftarrow{1})\ R -
テープの右端(つまり、空白記号)まで戻っていきます。
\overrightarrow{b}\ R\ \overleftarrow{b} \\ \overrightarrow{1}\ R\ \overleftarrow{1} \\ 1\ R\ \overleftarrow{1} \\ c\ R\ \overleftarrow{c} \\ \overrightarrow{c}\ R\ \overleftarrow{c} \\この部分で、生成規則と語の間($R'$)に含まれる記号はすべて同じになります。
-
で、右端に着いたら、そこに$1$(の印付き)を書いて折り返し、また生成規則から$1$をとりに行きます。
R\ \overleftarrow{1}\ (\overrightarrow{1})\ L -
このタイミングで$\overleftarrow{c_1}$を見つけたら、このTM$U$は停止します。(この記号は終了規則にしか存在しないため)
q_2\ \overleftarrow{c_1}c_2\ Lq_1 \\ q_1\ \overleftarrow{c_1}\ -この処理では、内部状態が$q_1$でも内部状態が$q_2$でも必ず$q_1$になって終了するようにしています。
-
$1$を探しに行く途中でマーク$b$を見つけたら、折り返してステップ2に行きます。
L\ b\ (b_2)\ Rここで、TM $U$ の内部状態が$q_2$から$q_1$になります。
ステップ2
- まず、生成規則の区切り記号$b$に対応する文字の区切り記号$c$を書き込むために右端に戻っていきます。
\overrightarrow{b}\ R\ \overleftarrow{b_1} \\ \overrightarrow{1}\ R\ \overleftarrow{1_1} \\ \overrightarrow{c}\ R\ \overleftarrow{c} \\ - で、右端に着いたら(空白記号を見つけたら)、そこに$c$(の印付き)を書いて折り返します。(この時点ではまだ内部状態は$q_1$です。)
R\ \overleftarrow{1}\ (c_2)\ L - そして、見つけた$b$が$1b$(普通の文字の区切り記号)なのか$bb$(生成規則の先頭)なのかを判断するために、生成規則の方に戻っていきます。
\overleftarrow{1_1}\ L\ \overrightarrow{1_1} \\ \overleftarrow{c}\ L\ \overrightarrow{c_1} \\ \overleftarrow{b_1}\ L\ \overrightarrow{b_1} \\-
以下のように $1b$ を読み込んだら...(この時点で内部状態が$q_2$になります)
L1b_2(\overleftarrow{1}\overleftarrow{b_1})R- テープの処理対象の語を表す部分につけた印を消しつつ、ステップ1に戻ります。(テープの右端には印付きの記号$c$がありますね)
\overrightarrow{1_1}\ R\ \overleftarrow{1_1} \\ \overrightarrow{b_1}\ R\ \overleftarrow{b_1} \\ \overrightarrow{c_1}\ R\ c_2 \\ R\ c_2\ (c)\ L \\ \overleftarrow{1_1}\ L\ 1 \\ c_2\ L\ c \\ \overleftarrow{b_1}\ L\ \overrightarrow{b} \\ -
以下のように$bb$を読み込んだら、生成規則の先頭まで来たので、手順3に進みます。(この時点で内部状態が$q_2$になります)
Lbb_2(bb)R
-
手順3
この手順では、テープ上の色々な所に着けられた印を消していきます。
- まず、生成規則の部分についた印を消しながら、処理対象の語を表す部分に向かいます。
\overleftarrow{1_1}\ R\ 1 \\
\overleftarrow{b_1}\ R\ b
- そして、語の部分(語の先頭にある記号$c$)に到着したら、ここを$\overleftarrow{c_1}$としてマークし...
q_1\ \overrightarrow{c_1}\overleftarrow{c_1}\ Rq_2 \\
- 語の部分も戻していきます。手順2の$1b$を読み込んだ時と似たような処理です。
\overrightarrow{1_1}\ R\ \overleftarrow{1_1} \\
\overrightarrow{c_1}\ R\ c_2 \\
R\ c_2\ (c)\ L \\
\overleftarrow{1_1}\ L\ 1 \\
c_2\ L\ c \\
- 最終的に、TM$U$のヘッドが$R$(生成規則と語の間の空白記号列)の右端の位置に戻ったら、手順1を再び開始します。
q_2\ \overleftarrow{c_1}c_2\ Lq_1 \\
これですべての動作の説明が完了しました。論文の読解はこれにて終了です。
終わりに
読めば読むほどその巧さがしみわたる論文でした。
で、実際に実装してみたくなったので、またその件で記事を書きたいなぁ...。
-
「何が」小さいのかは各チューリングマシンによって違います。 ↩