はじめに
自己紹介

IT系の事業会社で働く20代サラリーマンの@Sinhaliteです。企画職なので業務でプログラミングをする機会はありませんが、プログラミングが好きなので、休日にPython,Ruby,Javaなどを学んでいます。趣味はタイトルから分かる通り…競馬です。
きっかけ
馬=茶色…というのが普通の人の認識かと思いますが、実は競走馬には様々な毛色の馬がいます。有名どころの馬だと、2010年のダービーを制したエイシンフラッシュは黒光りしたかっこいい馬体をしていますし、2012年の有馬記念を制したゴールドシップは白い馬体とつぶらな瞳で実力を兼ね備えたアイドルホースとして活躍しました。
今回ディープラーニングで画像の分類器を実装してみたいな~と何となく思っていたのですが、毛色による分類ならある程度精度が出るんじゃないかと思い、やってみることにしました。また競走馬の中には、微妙な毛色をしていてどれに分類したらよいか分かりづらい馬もおり、そういった馬がディープラーニングで正確に分類できれば面白いんじゃないか…という部分もあります。
分類対象の画像について
まずは毛色の種類について確認したいと思います。
JRAが公開している「サラブレッド講座」によると、
サラブレッドの毛色は、(公財)ジャパン・スタッドブック・インターナショナルで認められているものが全部で8種類あります。
競走馬もこれにあわせて分類されます。
とのことでしたので、この毛色の区分に合わす形で分別したいと思います。
ただし実際の競走馬の毛色の分布には偏りがあり、圧倒的に多い種類が**鹿毛(かげ)**という茶色の馬になります。
その次に多い種類が、**黒鹿毛(くろかげ)**という黒っぽい毛の馬と、**栗毛(くりげ)**というキャメル色の毛の馬になります。
今回はサンプルとなる画像数が少ないため、この3種類以外の毛色の競走馬は対象外とし、「鹿毛」「黒鹿毛」「栗毛」の3種類に分類したいと思います。

手順
1. スクレイピングによる画像収集
単純に競走馬の画像を集めるだけなら簡単ですが、今回は高い精度を狙っていきたいので、なるべく同じアングルからの画像を揃えたいと思います。
競馬には一口馬主という複数人で馬主の権利を分け合う制度があります。一口馬主は、「クラブ」という馬主資格を持つ法人が会員を集め、権利を販売する形をとるのですが、会員が出資する馬を決める際には馬体のチェックが必須となるので、競走馬を横からのアングルで撮影した画像が必ず提供されています。
ということで、今回は一口馬主の馬に関する情報がまとまっている、netkeibaさんのページの競走馬画像を利用させていただくことにしました。
一口馬主 | 一口ライフを総合サポート - netkeiba.com
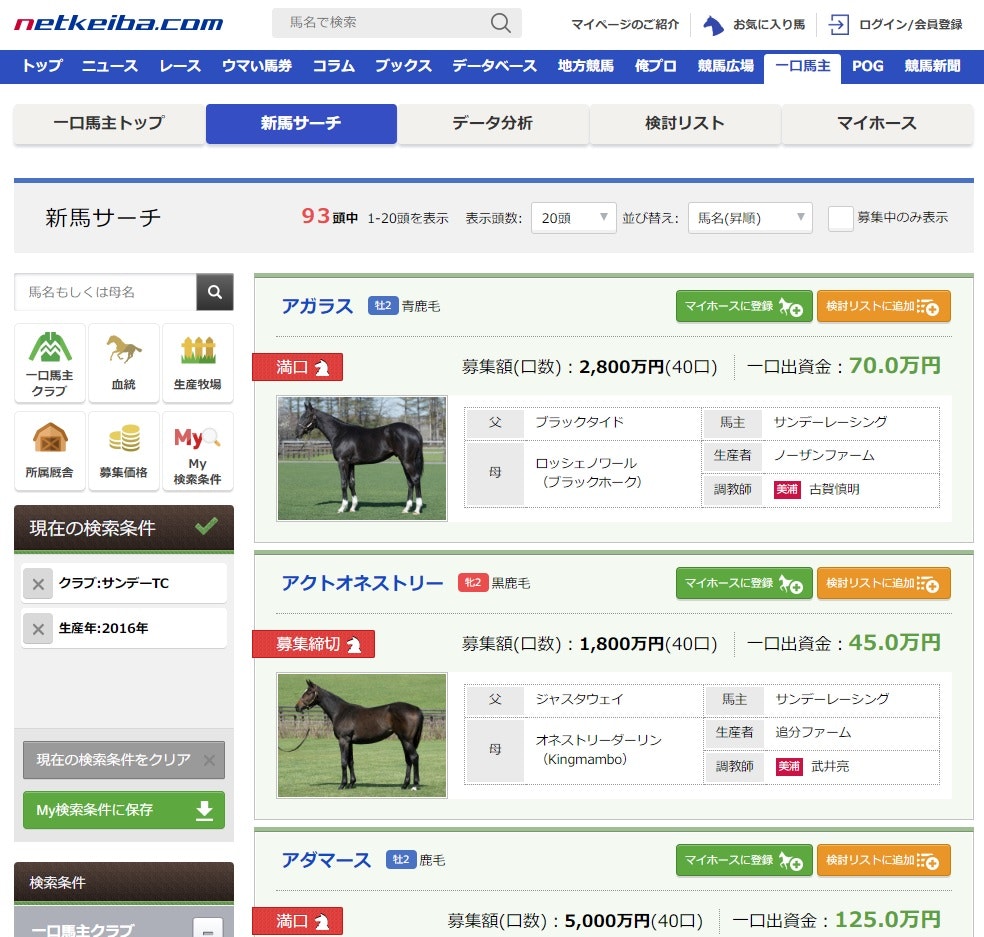
↑こんな感じで競走馬の情報と画像が一覧になっています。
ログイン不要のページだったので、ささっとスクレイピングできるかと思ったのですが、いざソースを取得すると肝心な競走馬の情報が空の状態…。動作を確認してみると、どうやらajaxで競走馬のリストを取得しているようでした。ついてはSelenium+PhantomJSを利用して動的に表示されたページを取り込み、BeutifulSoupを使って欲しい情報を切り出して格納していきます。
全頭だとかなりの量があるのですが、画像の有無をチェックしたところ、生まれの古い競走馬や小さめのクラブでは競走馬画像が無いことが目立ったので、主要クラブ+最近の馬に絞って画像を取得することとしました。
from bs4 import BeautifulSoup
import urllib.request as req
from selenium import webdriver
import os
from time import sleep
host = "http://owner.netkeiba.com/"
page = "1"
url = "http://owner.netkeiba.com/?pid=search_horse&sort=horse_name-asc&limit=100&page=" + page
driver = webdriver.PhantomJS(service_log_path=os.path.devnull)
driver.get(url)
# クラブを指定
# 1:社台TH, 2:サンデーTC, 3:ウインRC, 4:キャロットC, 6:シルクHC
club_list=["1","2","3","4","6"]
driver.find_element_by_css_selector("#sm1").click()
for i in club_list:
driver.find_element_by_css_selector("#sm1_body > ul > li:nth-of-type(" + i + ") > label").click()
sleep(5)
# 生年を指定(2013-2016)
# 3:2016, 4:2015, 5:2014, 6:2013
year_list=["3","4","5","6"]
driver.find_element_by_css_selector("#sm2").click()
for i in year_list:
driver.find_element_by_css_selector("#sm2_body > ul > li:nth-of-type(" + i + ") > label").click()
sleep(5)
# 2ページ以降を取得する際、クラブ/生年指定をするとページ1に戻ってしまうため,
# 再度アクセスする
driver.get(url)
sleep(5)
driver.save_screenshot("result_ss.png")
res = driver.page_source.encode('utf-8')
soup = BeautifulSoup(res, "html.parser")
horse_img_list = soup.select(".HorseImg > img")
horse_color_list = soup.select(".Color")
horse_name_list = soup.select(".Name > a")
for i, horse_img in enumerate(horse_img_list):
horse_img_url = horse_img.get("src")
print(horse_img_url)
if horse_color_list[i].string == " ":
continue
req.urlretrieve(horse_img_url, "./horse_image/" + horse_color_list[i].string + "/" + horse_name_list[i].string + ".jpg")
馬の絞り込みのために、検索条件のチェックボックスをクリックする処理が入っていますが、都度ajax通信を行っているため、処理が完了してから次の操作を行う必要があり、適宜sleep処理を入れています。sleepだと前段の処理が終了したかどうか判定できないため、本来は不適切ですが、今回はSeleniumからスクショを撮影することで、意図した状態になっていることを確認しています。
この段階で毛色の情報も同時に取得して、毛色ごとに自動でフォルダ分けを行います。これによってラベリングの手間を大きく削減できました。
何ページ分か画像ダウンロードしたところ、毛色ごとにそれぞれ100枚弱集まりましたので、次のステップに移りたいと思います。
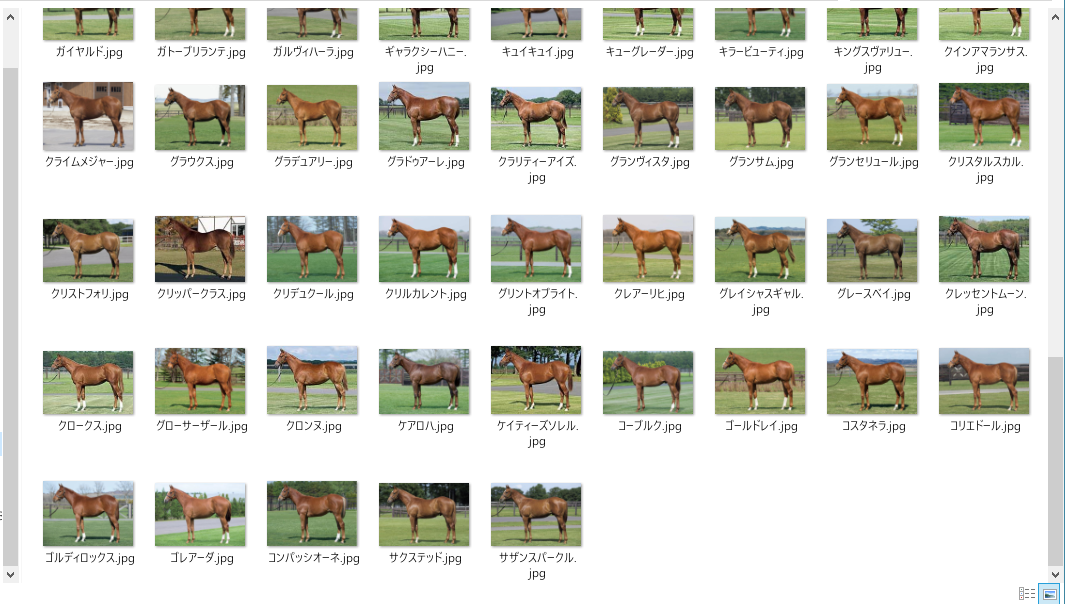
↑栗毛画像をダウンロードしたフォルダ。全部同じ馬に見える…かもしれませんが、よく見ると微妙に毛色や背景が異なります。
2. 学習データの作成
ここからの手順は、『Pythonによるスクレイピング&機械学習 開発テクニック』内の牛丼画像分類のコードを、大幅に参考・流用させていただいております。この本は非常に情報量が多く、分かりやすく、それでいて実践的ですので、おすすめです。
ここでやっている作業は、主に以下の3つです。
- 学習データとテストデータの分割
- 画像データの水増し
- 画像データの変換
今回は取得した画像のうち、7割を学習データ、3割をテストデータとすることとしました。データを分割後、このままだと学習データの数が不十分ですので、左右それぞれ20°のレンジで1°ずつ傾けたデータを作成します。これによって、学習データを約40倍まで増加させることができました。その後、ディープラーニングで扱えるように、画像ファイルを配列化して格納します。
from PIL import Image
import os, glob
import numpy as np
import random, math
# 設定
root_dir = "./horse_image/"
categories = ["鹿毛","黒鹿毛","栗毛"]
nb_classes = len(categories)
image_size_x = 115
image_size_y = 80
# 画像データの読み込み
X = [] # 画像データ
Y = [] # ラベルデータ
def add_sample(cat, fname, is_train):
img = Image.open(fname)
img = img.convert("RGB") # カラーモードの変更
img = img.resize((image_size_x, image_size_y)) # 画像サイズの変更
data = np.asarray(img)
X.append(data)
Y.append(cat)
if not is_train: return
# 1度ずつ角度を変えてデータを追加
for ang in range(-20, 20):
img2 = img.rotate(ang)
data = np.asarray(img2)
X.append(data)
Y.append(cat)
def make_sample(files, is_train):
global X, Y
X = []; Y = []
for cat, fname in files:
add_sample(cat, fname, is_train)
return np.array(X), np.array(Y)
# ディレクトリごとに分けられたファイルを収集する
allfiles = []
for idx, cat in enumerate(categories):
image_dir = root_dir + "/" + cat
files = glob.glob(image_dir + "/*.jpg")
for f in files:
allfiles.append((idx, f))
# シャッフルして学習データとテストデータに分ける
random.shuffle(allfiles)
th = math.floor(len(allfiles) * 0.7)
train = allfiles[0:th]
test = allfiles[th:]
X_train, y_train = make_sample(train, True)
X_test, y_test = make_sample(test, False)
xy = (X_train, X_test, y_train, y_test)
np.save("./horse_image/horse.npy", xy)
print("ok,", len(y_train))
3. ディープラーニングによる学習・テスト
ここでは畳み込みニューラルネットワークのモデルを構築します。
ディープラーニングの実際の動作や、それぞれの層の役割については、私もまだ理解が追いついていないところですので、勉強していきたいと思っています。
学習データ作成のプログラムと同様、こちらも牛丼画像分類のコードを参考・流用させていただきました。
畳み込みニューラルネットワークについては、以下の記事が分かりやすいかと思います。
Convolutional Neural Networkとは何なのか - Qiita
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.utils import np_utils
import numpy as np
# 分類対象のカテゴリ
root_dir = "./horse_image/"
categories = ["鹿毛","黒鹿毛","栗毛"]
nb_classes = len(categories)
# データをロード
def main():
X_train, X_test, y_train, y_test = np.load("./horse_image/horse.npy")
# データを正規化する
X_train = X_train.astype("float") / 256
X_test = X_test.astype("float") / 256
y_train = np_utils.to_categorical(y_train, nb_classes)
y_test = np_utils.to_categorical(y_test, nb_classes)
# モデルを訓練し評価する
model = model_train(X_train, y_train)
model_eval(model, X_test, y_test)
# モデルを構築
def build_model(in_shape):
model = Sequential()
model.add(Convolution2D(32, 3, 3,
border_mode='same',
input_shape=in_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(64, 3, 3, border_mode='same'))
model.add(Activation('relu'))
model.add(Convolution2D(64, 3, 3))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
# モデルを訓練する
def model_train(X, y):
model = build_model(X.shape[1:])
model.fit(X, y, batch_size=32, epochs=10)
# モデルを保存する
hdf5_file = "./horse_image/horse-model.hdf5"
model.save_weights(hdf5_file)
return model
# モデルを評価する
def model_eval(model, X, y):
score = model.evaluate(X, y)
print('loss=', score[0])
print('accuracy=', score[1])
if __name__ == "__main__":
main()
これにてすべて準備が整いました。ここまでたどり着くまでが長かった…。
いざこちらのプログラムを実行します!
実行結果:
Using TensorFlow backend.
Epoch 1/10
8938/8938 [==============================] - 145s 16ms/step - loss: 0.2323 - acc: 0.8993
Epoch 2/10
8938/8938 [==============================] - 144s 16ms/step - loss: 0.0658 - acc: 0.9749
Epoch 3/10
8938/8938 [==============================] - 143s 16ms/step - loss: 0.0272 - acc: 0.9897
Epoch 4/10
8938/8938 [==============================] - 143s 16ms/step - loss: 0.0213 - acc: 0.9922
Epoch 5/10
8938/8938 [==============================] - 143s 16ms/step - loss: 0.0226 - acc: 0.9916
Epoch 6/10
8938/8938 [==============================] - 143s 16ms/step - loss: 0.0195 - acc: 0.9940
Epoch 7/10
8938/8938 [==============================] - 144s 16ms/step - loss: 0.0125 - acc: 0.9957
Epoch 8/10
8938/8938 [==============================] - 144s 16ms/step - loss: 0.0122 - acc: 0.9959
Epoch 9/10
8938/8938 [==============================] - 143s 16ms/step - loss: 0.0336 - acc: 0.9895
Epoch 10/10
8938/8938 [==============================] - 144s 16ms/step - loss: 0.0115 - acc: 0.9958
94/94 [==============================] - 0s 5ms/step
loss= 1.016921601396926
accuracy= 0.9007092156308762
計8938枚の画像を10回学習させたモデルでテストしたところ、なんと90%の正答率を得ることができました。
正直ここまで上手くいくと思ってなかったので、個人的には満足な数字です。

↑適当に画像をピックアップしてテストしてみましたが、正確に判定できてます。
4. 追記(2018/6/17):芦毛馬の学習
ダウンロードするページ数を増やして、芦毛馬の画像もある程度確保できたので、4種類への分類へ挑戦したいと思います。
芦毛馬の画像が60枚弱で一番少ないので、他の毛色画像も同じ枚数になるようアンダーサンプリングし、学習させます。
サンプル数の偏りの対処法は、以下の記事が参考になると思います。
不均衡データに対するClassification - Qiita
芦毛の馬は幼少期は灰色っぽい体をしているのですが、年齢を重ねるにつれ白っぽくなっていくという特徴をもっています。毛色が安定していないので、一番分類が難しいのではないかと思いますが、良い結果が出ることを願って学習・テストを行います。
※なおこのタイミングで、学習用画像データの中に、一部アングルが微妙な画像だったり、NoImageの画像があったため除外しています。
実行結果:
Epoch 1/10
7544/7544 [==============================] - 126s 17ms/step - loss: 0.2022 - acc: 0.9135
Epoch 2/10
7544/7544 [==============================] - 125s 17ms/step - loss: 0.0314 - acc: 0.9893
Epoch 3/10
7544/7544 [==============================] - 126s 17ms/step - loss: 0.0195 - acc: 0.9928
Epoch 4/10
7544/7544 [==============================] - 126s 17ms/step - loss: 0.0194 - acc: 0.9935
Epoch 5/10
7544/7544 [==============================] - 126s 17ms/step - loss: 0.0153 - acc: 0.9954
Epoch 6/10
7544/7544 [==============================] - 128s 17ms/step - loss: 0.0207 - acc: 0.9933
Epoch 7/10
7544/7544 [==============================] - 130s 17ms/step - loss: 0.0088 - acc: 0.9973
Epoch 8/10
7544/7544 [==============================] - 126s 17ms/step - loss: 0.0035 - acc: 0.9991
Epoch 9/10
7544/7544 [==============================] - 126s 17ms/step - loss: 0.0080 - acc: 0.9976
Epoch 10/10
7544/7544 [==============================] - 132s 17ms/step - loss: 0.0231 - acc: 0.9943
80/80 [==============================] - 0s 5ms/step
loss= 0.27924579977989195
accuracy= 0.96875
まさかの精度向上。やったぜ。
芦毛の特徴をしっかり学習できているのは素晴らしいと思います。
追記(2018/6/25)
分類の際には
model.compile(loss='binary_crossentropy')
ではなく
model.compile(loss='categorical_crossentropy')
にする必要がありそうです。
変更後,テストデータの正答率は87.5%でしたが、それでもなかなかの精度といえるのではないでしょうか。
おわりに
感想
- 特に統計や数学の知識の薄い私でも、豊富なライブラリを組み合わすことによって、想像以上の成果をだすことができました。技術の進歩ってすごい()
- 学習データの作成や学習フェーズについては、他の方の書いたコードを参考にできるので、あまり苦労しませんでした。スクレイピングでいかに楽に画像を集められるかだったり、簡単にラベリングするか仕組みを作ることが大切だと思いました。
今後の課題
芦毛画像も学習させて、4分類で判定させる。- 背景込みの画像を学習させているので、馬体を物体認識した上で学習したら、更に精度が上がるかもしれない。
- 毛色の決定は遺伝子的な要素が強いようなので、両親の毛色データを一緒に学習させると良さそう。(できるんだろうか)