一:基礎知識
1.PyCharm のショートカットキー
①設定 → キーマップ

②コマンドラインのショートカット
# 現在のパスを表示する:pwd
# 内容を一覧表示する:ls
# ディレクトリを移動する:cd
# ファイルを作成する:touch 新規ファイル.txt
2.コメント
一行コメント:#(シャープ)
複数行コメント:''' ''' """ """ 三重クォート(さんじゅう クォート)
文字コード指定:# coding = utf-8
3.変数
命名規則:スネークケース user_name
変数を定義する際は、必ず値を代入します。
Python では変数に型はなく、値(データ)に型があります。
# 変数名 = 値
name = '张三'
# type() でデータ型を確認する
print(type(name)) # str
4.データ型
①整数型(int)
# 数値が大きい場合、アンダースコアで3桁ずつ区切ることができる
salary = 12_000_000
②浮動小数点数(float)
# 科学記数法で表す
3.4e+2 # 3.4 × 10 の 2 乗
7.8e9 # 7.8 × 10 の 9 乗
1.496E8 # 1.496 × 10 の 8 乗
2.998E+8 # 2.998 × 10 の 8 乗
1e-3 # 1 × 10 の -3 乗
1E-3 # 1 × 10 の -3 乗
✨浮動小数点数の精度制御
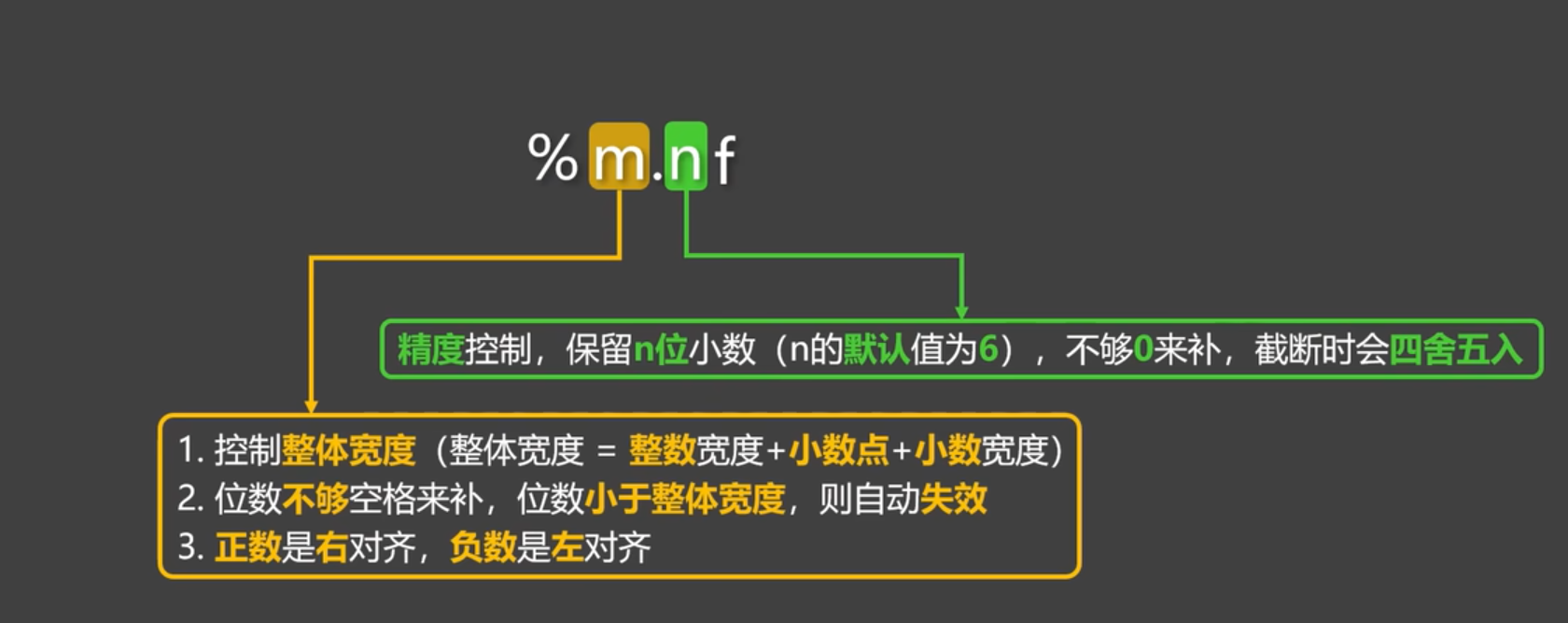
weight = 65.55
# %9.3f:浮動小数点数を表し、小数点以下を3桁に指定し、表示幅は9、右寄せで表示する
info = '体重は%9.3fです' % weight
print(info) # 体重は 65.550です
③ブール値(Boolean / bool)
0以外の数値は、ブール型に変換するとTrueになる
空文字列以外の文字列は、ブール型に変換するとTrueになる
1はTrue、0はFalseを表す
④文字列
# 文字列のフォーマット出力には f-string を使います。
info = f'私は{name}です。{gender}で、体重は{weight}、年齢は{age}です。'
5.演算子
①算術演算子
除算の結果は浮動小数点数になる
//:整数除算(切り捨て)
%:剰余
**:累乗(るいじょう)(ダブルアスタリスク)
②比較演算子
文字列の場合は、Unicode のコードポイントを比較します。
# ord() を使って、指定した文字の Unicode コードポイントを確認する
print(ord('我')) # 25105
# chr() を使って、Unicode コードポイントを文字に変換する
print(chr(97)) # a
③論理演算子
and(かつ)
両方がTrueの場合にのみ、結果はTrueになる
or(または)
どちらか一方がTrueであれば、結果はTrueになる
# and/orは必ずしもブール値を返すわけではなく、演算に参加した値そのものを返します。
# 補足:and/or演算に使われる値がブール値でない場合、Pythonは自動的にブール値に変換してから論理演算を行います。
# andはまず左側を評価し、左側がFalseの場合は左側をそのまま返し、左側がTrueの場合は右側を返します。
print(2 - 2 and True) # 0
print('' and True) # ""
print(True and 8 / 2) # 4.0
print(3 + 3 and 3 * 4) # 12
# orはまず左側を評価し、左側がTrueの場合は左側をそのまま返し、左側がFalseの場合は右側を返します。
print(7 - 2 or False) # 5
print('你好' or '尚硅谷') # 你好
print(False or 8 / 2) # 4.0
print(2 - 2 or 3 * 4) # 12
not(否定)
真偽値を反転させる
6.データ型の変換
# 1.指定したデータを文字列に変換する:str() どの型のデータでも文字列型に変換できる
# 2.指定したデータを整数型に変換する:int()
print(int(15.6))
print(int('79'))
print(int(' 79 '))
print(int(48))
# エラー例
# print(int(' 7 9 '))
# print(int('你好'))
# print(int('79个'))
# print(int('15.6'))
# 3.指定したデータを浮動小数点数に変換する:float()
print(float(18))
print(float('15.6'))
print(float(' 5.7 '))
print(float(14.8))
print(float('48'))
# エラー例
float(' 5. 7 ')
float('你好')
float('5.7元')
float('5.23.12')
# 4.指定したデータをブール型に変換する:bool()
7.エスケープ文字
# 1 \' :' を出力する
# 2 \n :改行
# 3 \\ :\ を出力する
# 4 \b :直前の1文字を削除する
# 5 \r :カーソルを行頭に戻し、上書き出力する
print('67%\r68%') # 結果:68%
# 6 \t :カーソルを次のタブ位置に移動する
print('ab\tcd')
1234 1234 1234
ab cd
print('abcd\ta')
1234 1234 1234
abcd a
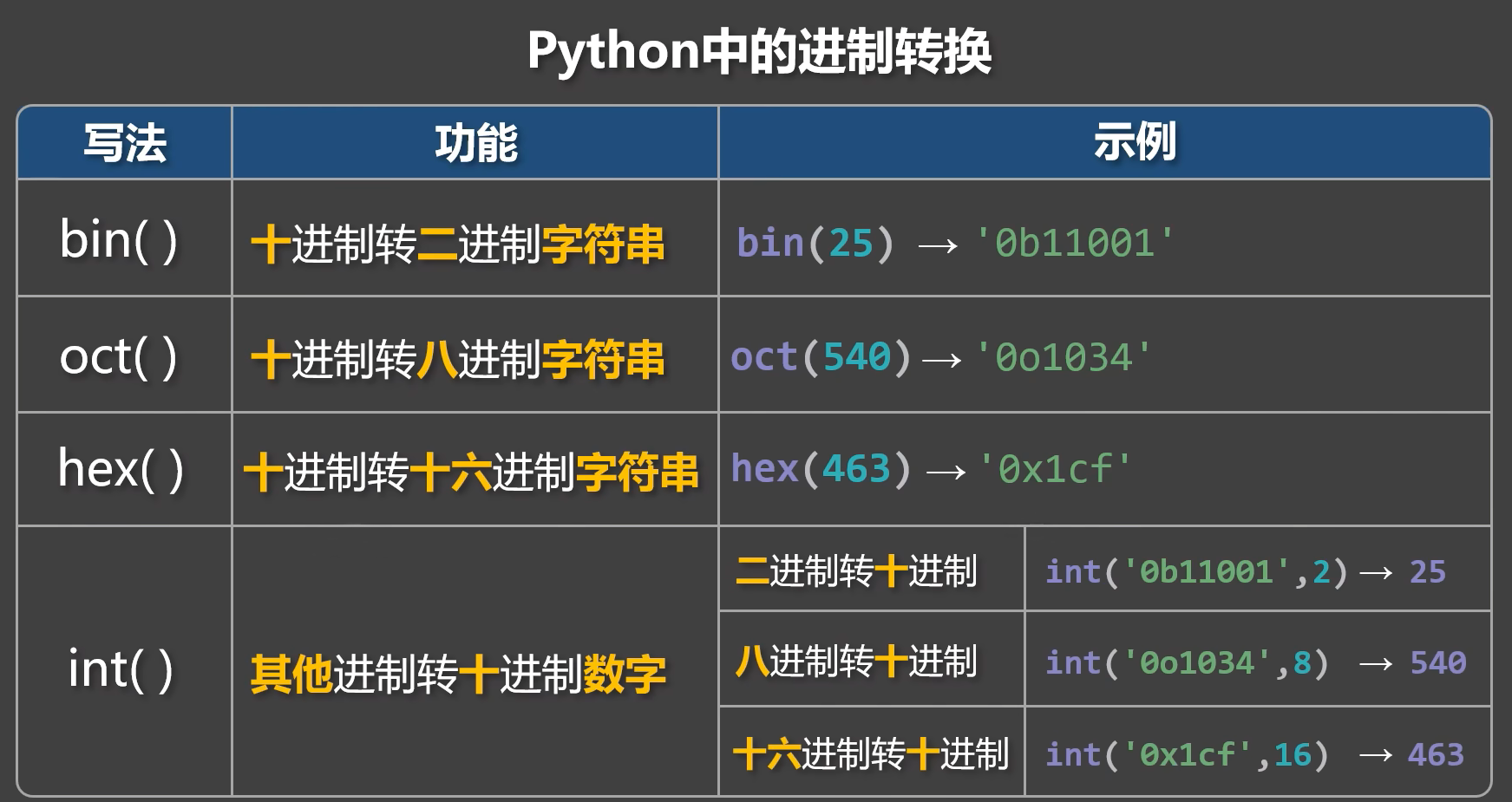
8.進数変換
9.入力文
# input() を使ってユーザーの入力を取得する
name = input('あなたの名前を入力してください:')
age = input('あなたの年齢を入力してください:')
# input() で取得した値は、すべて文字列型になる
print(type(age))
# age を整数型に変換する
age = int(age)
# 情報を表示する
print(f'{name}さん、今年の年齢は{age}歳です')
二:制御構文
1.単分岐
age = 20
if age >= 18:
print('成人です')
2.二分岐
age = 15
if age >= 18:
print('成人です')
else:
print('未成年です')
3.多分岐
score = 85
if score >= 90:
print("優秀")
elif score >= 80:
print("良好")
elif score >= 60:
print("合格")
else:
print("不合格")
4.ネストした分岐
# 参加年齢は18~45歳でなければならない
# 大会参加前に健康診断書を提出する必要があり、提出していない場合は参加できない
# 大会終了後、会員ランクに応じて異なる景品を受け取る
# 1:Tシャツ 2:ランニングシューズ 3:ヘッドホン
age = int(input('年齢を入力してください:'))
has_report = input('健康診断書を提出しましたか?(はい/いいえ):')
level = int(input('会員ランクを入力してください(1/2/3):'))
if 18 <= age <= 45:
print('年齢は参加条件を満たしています')
if has_report == 'はい':
print('健康診断書を提出済みのため、参加できます')
if level == 1:
print(f'{level}級会員のため、Tシャツを受け取れます')
elif level == 2:
print(f'{level}級会員のため、ランニングシューズを受け取れます')
elif level == 3:
print(f'{level}級会員のため、ヘッドホンを受け取れます')
else:
print('入力された会員ランクが正しくありません')
elif has_report == 'いいえ':
print('健康診断書を提出していないため、参加できません')
else:
print('健康診断書の入力内容が正しくありません')
else:
print('参加年齢は18~45歳である必要があります')
5.whileループ
n = 1
while n <= 10:
print(f'こんにち{n}')
n += 1
6.forループ

# for 文を使って、range() で指定した数値の範囲を繰り返し処理する
for n in range(1, 11):
print(f'{n}回目、こんにちは')
# for 文を使って文字列を1文字ずつ処理する
for m in 'abcdefg':
print(m)
三:関数
1.フォーマット

2.引数
①種類と制限
def greet(name, gender, age, height):
print(f'{name} さん、性別 {gender}、年齢 {age} 歳、身長 {height} cm')
# 位置引数
greet('張三', '男', 18, 172)
# キーワード引数:関数呼び出し時に、引数名 = 値 の形式で渡す
greet(name='李四', gender='女', age=25, height=180)
# 混合:キーワード引数を使用する場合、位置引数は必ずキーワード引数の前に置く
greet('王五', '男', age=30, height=165)
# 関数で引数の渡し方を制限する
# / の前は位置引数のみ、* の後はキーワード引数のみ
# / と * を同時に使用する場合、/ は * の前に置く必要がある
def greet(name, /, gender, *, age, height):
print(f'{name} さん、性別 {gender}、年齢 {age} 歳、身長 {height} cm')
# 呼び出し例
greet('王五', '男', age=30, height=165)
②デフォルト引数
# 引数のデフォルト値:関数定義時に、引数名 = 値 の形式でデフォルト値を指定する
# greet を呼び出す際、msg が渡されなければデフォルト値を使用し、渡された場合はその値で上書きされる
# デフォルト引数は、必須引数の後に置く必要がある
# msg はオプション引数
def greet(name, gender, age, height, msg='こんにちは'):
print(f'{name} さん、性別 {gender}、年齢 {age} 歳、身長 {height} cm')
print(f'伝えたいこと:{msg}')
# デフォルト値を使用
greet('王五', '男', 30, 165)
# 渡された値で上書き
greet('王五', '男', 30, 165, 'hello')
# キーワード引数で渡す場合も同様
greet('王五', '男', 30, 165, msg='hello')
③可変長引数
# 可変位置引数
# 関数定義時に、引数名の前に * を付けることで、任意の数の位置引数を受け取り、タプルとしてまとめる
# args には、関数呼び出し時に渡されたすべての位置引数が格納される
def test1(*args):
print(args)
test1('張三', '男', 18, 175) # ('張三', '男', 18, 175)
# 可変キーワード引数
# 関数定義時に、引数名の前に ** を付けることで、任意の数のキーワード引数を受け取り、辞書としてまとめる
# kwargs には、関数呼び出し時に渡されたすべてのキーワード引数が格納される
def test2(**kwargs):
print(kwargs)
test2(name='張三', gender='男', age=18, height=175)
# {'name': '張三', 'gender': '男', 'age': 18, 'height': 175}
# 可変位置引数と可変キーワード引数は同時に使用できる,ただし、必ず可変位置引数を先に記述する
def test3(*args, **kwargs):
print(args) # ('張三', '男')
print(kwargs) # {'age': 18, 'height': 175}
test3('張三', '男', age=18, height=175)
# 可変位置引数・可変キーワード引数は、他の種類の引数と組み合わせて使用することもできる
def test4(a, b, *args, c='尚硅谷', **kwargs):
print(a) # 張三
print(b) # 男
print(args) # ('喫煙', '飲酒')
print(c) # atguigu
print(kwargs) # {'age': 18, 'height': 175}
test4('張三', '男', '喫煙', '飲酒', c='atguigu', age=18, height=175)
3.None
None は空の値・値が存在しないこと・意味を持たないことを表す。
型は NoneType であり、bool 型に変換すると False になる。
数値演算には使用できず、文字列との連結もできない。
関数に戻り値を指定しない場合、デフォルトで None が返される。
4.グローバルスコープ/ローカルスコープ
# a, b はグローバル変数であり、同一ファイル内のどこからでも使用できる
# c, d はローカル変数であり、定義された関数内でのみ使用できる
a = 100
b = 200
def test():
c = 'hello'
d = 'world'
global a # a がグローバル変数であることを宣言する
# (新しいローカル変数を作るのではなく、外側のグローバル変数 a を参照する)
a = 300 # グローバル変数 a の値を直接変更する
print(a) # 300
print(b)
print(c)
print(d)
test()
print(a) # 300
print(b)
# print(c) # c, d はローカル変数のため、関数の外では使用できない
# print(d)
# グローバルスコープおよびグローバル変数は、
# プログラム開始時に生成され、プログラム終了時に破棄される
n = 100
def test3():
global n
n += 1
print(n)
test3() # 101
test3() # 102
test3() # 103
5.関数のドキュメント
def add(n1, n2):
"""
2つの数を加算した結果を計算する
:param n1: 1つ目の数
:param n2: 2つ目の数
:return: 2つの数を加算した結果
"""
return n1 + n2
result = add(1, 2)
print(result)
四:リスト
1.インデックス
負のインデックス:右から左へ数える
2.追加・削除・更新・検索
nums = [10, 20, 30, 40, 50]
# 追加
# ① リストの末尾に要素を追加する:リスト.append(要素)
# ② リストの指定したインデックスに要素を追加する:リスト.insert(インデックス, 要素)
# ③ イテラブルオブジェクトの要素を順に取り出し、リストの末尾に追加する:リスト.extend(イテラブルオブジェクト)
nums.append(20)
print(nums) # [10, 20, 30, 40, 50, 20]
nums.insert(1, 100)
print(nums) # [10, 100, 20, 30, 40, 50, 20]
nums.extend([100, 200, 300])
print(nums) # [10, 100, 20, 30, 40, 50, 20, 100, 200, 300]
# 削除
# ① 指定した位置の要素を削除する:del リスト[インデックス]
# ② 指定した位置の要素を削除し、その要素を返す:リスト.pop(インデックス)
# ③ リスト内で最初に見つかった指定の値を削除する:リスト.remove(値)
# ④ リスト内のすべての要素を削除する(空のリストにする):リスト.clear()
del nums[0]
print(nums) # [100, 20, 30, 40, 50, 20, 100, 200, 300]
nums.pop(4)
print(nums) # [100, 20, 30, 40, 20, 100, 200, 300]
nums.remove(100)
print(nums) # [20, 30, 40, 20, 100, 200, 300]
# nums.clear()
# print(nums)
# 更新
# インデックスを指定して要素を更新する:リスト[インデックス] = 値
nums[0] = 1000
print(nums) # [1000, 30, 40, 20, 100, 200, 300]
# 検索
# インデックスを指定して要素を取得する:リスト[インデックス]
print(nums[0]) # 1000

3.よく使うメソッド
nums = [40, 20, 60, 40, 99]
# ① 指定した要素がリスト内で最初に出現するインデックスを取得する
# 戻り値:インデックス
# リスト.index(値)
# ② 指定した要素がリスト内に出現する回数をカウントする
# 戻り値:出現回数
# リスト.count(値)
# ③ リストを反転する(元のリストが変更される)
# リスト.reverse()
# ④ リストをソートする(昇順:小さい順、元のリストが変更される)
# reverse はソート順を制御するための引数
# リスト.sort(reverse=真偽値)
print(nums.index(60)) # 2
print(nums.count(40)) # 2
nums.reverse()
print(nums) # [99, 40, 60, 20, 40]
nums.sort(reverse=True)
print(nums) # [99, 60, 40, 40, 20]
nums.sort(reverse=False)
print(nums) # [20, 40, 40, 60, 99]

4.よく使う組み込み関数
nums = [40, 20, 60, 40, 99]
# ① コンテナを並び替える(昇順。元のコンテナは変更されない)
# reverse は並び替えの順序を制御するための引数
# 戻り値:並び替え後の新しいコンテナ
# sorted(データコンテナ, reverse = 真偽値)
#
# ② コンテナ内の要素数を取得する
# 戻り値:要素数
# len(データコンテナ)
#
# ③ コンテナ内、または複数の値の中から最大値を返す
# 戻り値:最大値
# max(データコンテナ)
#
# ④ コンテナ内、または複数の値の中から最小値を返す
# 戻り値:最小値
# min(データコンテナ)
#
# ⑤ コンテナ内のすべての要素を合計する(数値型のみ)
# 戻り値:すべての要素の合計
# sum(データコンテナ)
print(sorted(nums, reverse=True)) # [99, 60, 40, 40, 20]
print(len(nums)) # 5
print(max(nums)) # 99
print(min(nums)) # 20
print(sum(nums)) # 259

5.反復処理
①while
nums = [40, 20, 60, 40, 99]
index = 0
while index < len(nums):
print(nums[index])
index += 1
②for
nums = [40, 20, 60, 40, 99]
# ①
for item in nums:
print(item)
# ②
for index in range(len(nums)):
print(nums[index])
# ③
for index, item in enumerate(nums):
print(index, item)
6.まとめ
リストは異なる型の要素を格納することができ、要素には順序があります。
要素の重複が許されており、追加・削除・更新・検索(CRUD)が可能です。
長さは固定されておらず、操作に応じて自動的にサイズが調整されます。
五:タプルTuple
1.概念
タプルはリストと似ていますが、タプルの要素は変更できません。
リストは追加・削除・更新・検索が可能ですが、タプルは検索しかできません。
t1 = (18, 36, 55, 87, 94)
# インデックスを使って要素を取得
print(t1[1]) # 36
# タプルの中に可変型(リスト)が含まれている場合、その可変型(リスト)の中身は変更可能
t1 = (18, 36, 55, [18, 19])
t1[3][0] = 88
print(t1) # (18, 36, 55, [88, 19])
2.定義
# 空のタプルを定義
t1 = ()
print(t1) # ()
# 要素が1つだけのタプルを定義
t2 = (18,)
print(t2) # (18,)
3.よく使うメソッド
# index:タプル内で指定した要素が最初に出現するインデックスを取得する
# count:タプル内で指定した要素が出現する回数を数える
t1 = (10, 20, 30, 20, 50)
print(t1.index(20)) # 1
print(t1.count(20)) # 2
4.よく使う組み込み関数
# ① max:タプル内の最大値を返す
# ② min:タプル内の最小値を返す
# ③ len:タプル内の要素数を返す
# ④ sorted:タプルを並び替える(元のタプルは変更されず、新しいリストを返す)
# ⑤ sum:タプル内のすべての要素の合計を返す(要素は数値である必要がある)
t1 = (10, 20, 30, 20, 50)
print(max(t1)) # 50
print(min(t1)) # 10
print(len(t1)) # 5
print(sorted(t1)) # [10, 20, 20, 30, 50]
print(sum(t1)) # 130
関数の可変長引数 *args はタプルである
def demo(*args):
return sum(args)
result = demo(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
print(result) # 55
# 関数定義時に、*args を使用すると、受け取った複数の引数がタプルとしてまとめられる
def test(*args):
print(f'私はtest関数です。受け取った引数は:{args}、引数の型は:{type(args)}')
list1 = [100, 200, 300, 400]
tuple1 = ('你好', '北京', '尚硅谷')
# 関数呼び出し時に、リストやタプルをそのまま引数として渡す場合
test(list1)
# 私はtest関数です。受け取った引数は:([100, 200, 300, 400],)、引数の型は:<class 'tuple'>
test(tuple1)
# 私はtest関数です。受け取った引数は:(('你好', '北京', '尚硅谷'),)、引数の型は:<class 'tuple'>
# 関数呼び出し時に、* を使ってリストやタプルを展開(アンパック)してから引数として渡す場合
test(*list1)
# この書き方は次と同じ意味:test(100, 200, 300, 400)
test(*tuple1)
# この書き方は次と同じ意味:test('你好', '北京', '尚硅谷')
# 関数を呼び出す前に、「一つのまとまりとして渡したいのか」「複数の独立した値として渡したいのか」を確認する。
# まとまりとして渡したい場合 → * を付けない
# 複数の値として渡したい場合 → * を付ける
5.反復処理
①while
t1 = (10, 20, 30, 20 ,50)
index = 0
while index < len(t1):
print(t1[index])
index += 1
②for
t1 = (10, 20, 30, 20 ,50)
for item in t1:
print(item)
6.まとめ
タプルは異なる型の要素を格納することができ、順序を持ち、重複も許可されます。
ただし、要素の追加・削除・変更はできず、参照(取得)のみ可能です。
長さは固定されており、一度作成すると要素数を増減することはできません。
タプルは読み取り専用のデータコンテナです。変更されないデータをまとめて保存したい場合は、タプルを使用するのが適しています。
六:文字列
1.よく使うメソッド
# ① index:文字列の中で、指定した文字が最初に出現するインデックスを取得する
# ② split:指定した文字を区切り文字として文字列を分割し、リストとして返す
# ③ replace:文字列内の一部の文字列を、指定した文字列に置き換える
# ④ count:指定した文字が文字列中に出現する回数を数える
# ⑤ strip:指定した文字列に含まれる任意の文字を削除する
# 文字列の両端から削除し、指定した文字列に含まれない最初の文字に出会ったところで処理を終了する
msg = '你好,尚硅,谷'
print(msg.index('好')) # 1
print(msg.split(',')) # ['你好', '尚硅', '谷']
print(msg.replace(',','!')) # 你好!尚硅!谷
print(msg.count('你')) # 1
str = '666你好666'
print(str.strip('6')) # 你好
str2 = ' 日本'
print(str2.strip()) # 日本(余分な空白を削除)
2.よく使う組み込み関数
# len関数:文字列に含まれる文字数を数える
msg = 'welcome to python'
print(len(msg)) # 17
3.反復処理
①while
msg = 'welcome to python'
index = 0
while index < len(msg):
print(msg[index])
index += 1
②for
msg = 'welcome to python'
for item in msg:
print(item)
七:シーケンス
1.概念
# シーケンス:要素を連続して格納できるデータコンテナで、要素には順序があり、インデックスを使ってアクセスできる。リスト・タプル・文字列はいずれもシーケンスである。
# シーケンス[開始インデックス : 終了インデックス : ステップ]
# ステップ:ステップが n の場合、n−1 個分を飛ばして要素を取得する
# スライス:シーケンスから指定した範囲の要素を取り出し、新しいシーケンスを作成する操
# 開始インデックスが終了インデックスより大きい場合、ステップは負の値でなければならず、そうでない場合は空のリストになる
list1 = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120]
list2 = list1[1:10:2]
print(list2) # [20, 40, 60, 80, 100]
list3 = list1[7:2:-2]
print(list3) # [80, 60, 40]
# 開始インデックスと終了インデックスの両方を省略し、ステップが負の値の場合、Python は自動的に開始位置を反転させる
list4 = list1[::-1]
print(list4) # [120, 110, 100, 90, 80, 70, 60, 50, 40, 30, 20, 10]

2.シーケンスの演算
①連結
# シーケンスの連結
# 新しいシーケンス = シーケンス1 + シーケンス2
# 同じ型のシーケンス同士でなければ連結できない
list1 = [10, 20, 30]
list2 = [40, 50, 60]
list3 = list1 + list2
print(list3) # [10, 20, 30, 40, 50, 60]
②繰り返し
# シーケンスの繰り返し
# 新しいシーケンス = シーケンス * n
# n は整数でなければならない
tuple1 = (10, 20, 30)
print(tuple1 * 3) # (10, 20, 30, 10, 20, 30, 10, 20, 30)
八:集合Set
1.概念
# 集合の要素には順序がなく、重複は許可されず、インデックスによるアクセスはできない
# 集合の中に可変な集合を入れることはできないが、不変(イミュータブル)な集合は入れることができる
# 可変な集合
s1 = set()
# 不変な集合
s2 = frozenset()
2.追加・削除・更新・検索
①追加
# ① set.add(要素):集合に要素を追加する
# ② set.update(要素):集合に複数の要素を一括で追加する
# (リスト・タプル・集合などの反復可能オブジェクトを受け取る)
s1 = {10, 20, 30}
s1.add(40)
print(s1) # {40, 10, 20, 30}
s1.update([50, 60])
print(s1) # {40, 10, 50, 20, 60, 30}
②削除
# ① set.remove(要素):集合から指定した要素を削除する
# ※ 要素が存在しない場合はエラーになる
# ② set.discard(要素):集合から指定した要素を削除する
# ※ 要素が存在しない場合でもエラーにならない
# ③ set.pop():集合から任意の要素を1つ削除する
# 戻り値:削除された要素
# ④ set.clear():集合の中身をすべて削除する
s1 = {10, 20, 30, 40, 50}
s1.remove(20)
print(s1) # {50, 40, 10, 30}
s1.discard(30)
print(s1) # {50, 40, 10}
s1.pop()
print(s1) # {40, 10}
s1.clear()
print(s1) # set()
③更新
# remove + add
s1 = {10, 20, 30 ,40, 50}
s1.remove(10)
s1.add(100)
print(s1) # {50, 20, 100, 40, 30}
④検索
s2 = {10, 20, 30 ,40, 50}
print(10 in s2) # True
print(100 not in s2) # True

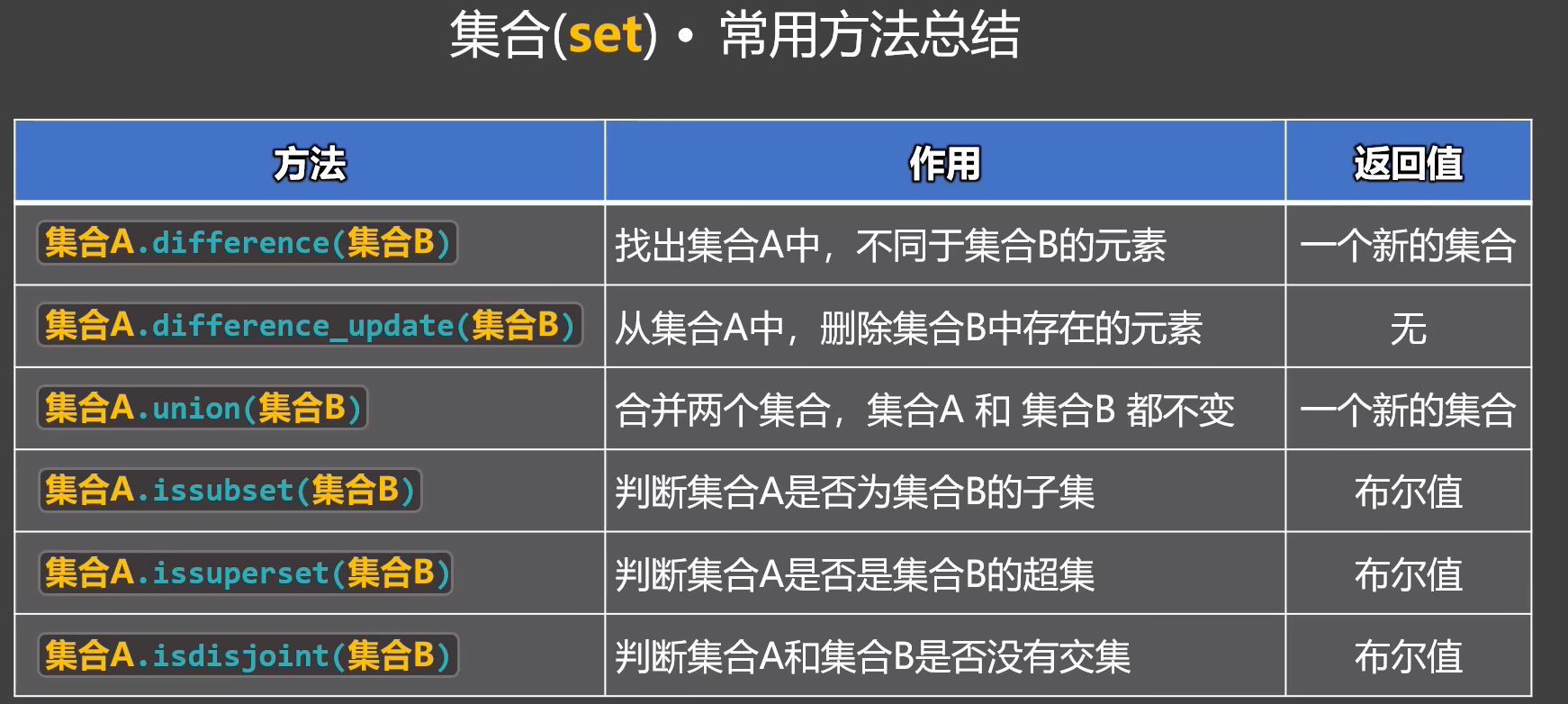
3.よく使われるメソッド
# ① setA.difference(setB)
# 集合Aにあって、集合Bにはない要素を取得する(集合A・集合Bはいずれも変更されない)
# 戻り値:新しい集合
# ② setA.difference_update(setB)
# 集合Aから、集合Bに存在する要素を削除する(集合Aは変更されるが、集合Bは変更されない)
# ③ setA.union(setB)
# 2つの集合を結合する(集合A・集合Bはいずれも変更されない)
# 戻り値:新しい集合
# ④ setA.issubset(setB)
# 集合Aが集合Bの部分集合かどうかを判定する
# 戻り値:真偽値(bool)
# 集合Aのすべての要素が集合Bに含まれていれば True、そうでなければ False
# ⑤ setA.issuperset(setB)
# 集合Aが集合Bの上位集合(スーパーセット)かどうかを判定する
# 戻り値:真偽値(bool)
# 集合Aが集合Bのすべての要素を含んでいれば True、そうでなければ False
# ⑥ setA.isdisjoint(setB)
# 集合Aと集合Bに共通要素がないかどうかを判定する
# 戻り値:真偽値(bool)
# 共通要素が1つもなければ True、1つでも共通要素があれば False
s1 = {10, 30, 50, 70, 80, 99}
s2 = {10, 20, 30, 50, 70, 80}
print(s1.difference(s2)) # {99}
4.数学演算
# ① 和集合(并集):A | B
# ② 積集合(交集):A & B
# ③ 差集合:A - B
# ④ 対称差集合:A ^ B
s1 = {10, 20, 30, 40, 50, 60}
s2 = {40, 50, 60, 70, 80, 90}
print(s1 | s2) # {70, 40, 10, 80, 50, 20, 90, 60, 30}
print(s1 & s2) # {40, 50, 60}
print(s1 - s2) # {10, 20, 30}
print(s1 ^ s2) # {70, 10, 80, 20, 90, 30}

5.反復処理
s1 = {10, 30, 50, 70, 80, 99}
for item in s1:
print(item)
6.まとめ
集合の要素には順序がなく、インデックスによるアクセスはできません。
要素は重複せず、可変な集合と不変な集合があります。
集合の要素には不変型(イミュータブル型)しか格納できず、数値・文字列・タプルなどが使用できます。
集合は数学的な演算をサポートしており、要素の順序を気にせず、「存在するかどうか」だけを判定したい場合には、集合を使用するのが最適です。
九:辞書Dict
1.概念
# key(キー)は重複できません。重複した場合、後から書いた値で上書きされます
# key(キー)は不変型でなければなりません。value(値)は任意の型を使用できます
from asyncio import start_unix_server
d = {'张三': 62, '李四': 60, '王五': 85}
print(d) # {'张三': 62, '李四': 60, '王五': 85}
# 空の辞書
d2 = {}
print(d2) # {}
d3 = dict()
print(d3) # {}
# 辞書はネスト(入れ子)することができます
student_dict = {
2025001: {'姓名': '张三', '年龄': 18, '成绩': 66},
2025002: {'姓名': '李四', '年龄': 19, '成绩': 99},
2025003: {'姓名': '王五', '年龄': 20, '成绩': 88}
}
# {2025001: {'姓名': '张三', '年龄': 18, '成绩': 66},
# 2025002: {'姓名': '李四', '年龄': 19, '成绩': 99},
# 2025003: {'姓名': '王五', '年龄': 20, '成绩': 88}}
print(student_dict)
2.追加・削除・更新・検索
①追加
d = {'张三': 62, '李四': 60, '王五': 85}
d['赵六'] = 100
print(d) # {'张三': 62, '李四': 60, '王五': 85, '赵六': 100}
②削除
# ① 指定した key に対応するキーと値のペアを削除する
# ② 指定した key に対応するキーと値のペアを削除し、その key に対応する値を返す
# ③ pop メソッドではデフォルト値を設定でき、削除したい key が存在しない場合でもエラーにならず、そのデフォルト値を返す
# ④ 辞書を空にする
d = {'张三': 62, '李四': 73, '王五': 85, '赵六': 99}
# ①
del d['张三']
print(d) # {'李四': 73, '王五': 85, '赵六': 99}
# ②
print(d.pop('李四')) # 73
print(d) # {'王五': 85, '赵六': 99}
# ③
print(d.pop('张三', '削除に失敗しました')) # 削除に失敗しました
# ④
print(d.clear())
③更新
# 変更の書き方は追加と同じです。辞書に該当するキーが存在する場合は「変更」、存在しない場合は「追加」になります。
d = {'张三': 62, '李四': 60, '王五': 85}
d['张三'] = 100
print(d) # {'张三': 100, '李四': 60, '王五': 85}
# 一括変更
d.update({'李四': 100, '王五': 99})
print(d) # {'张三': 100, '李四': 100, '王五': 99}
④検索
# ① キーが存在しない場合、エラー(KeyError)が発生します
# ② キーが存在しない場合、デフォルト値を返します
# (デフォルト値を指定しない場合は None を返します)
d = {'张三': 62, '李四': 60, '王五': 85}
print(d['张三']) # 62
print(d.get('赵六', '抱歉,key不存在')) # 抱歉,key不存在

3.よく使われるメソッド
# ① keys:辞書の全てのキーを取得する(返り値の型は dict_keys)
# dict_keys はループで回せるが、インデックスでアクセスはできない
# list 関数で dict_keys をリストに変換可能
# ② values:辞書の全ての値を取得する(返り値の型は dict_values)
# ③ items:辞書の全てのキーと値のペアを取得し、タプルの形式で返す(返り値の型は dict_items)
d = {'张三': 62, '李四': 73, '王五': 85, '赵六': 99}
print(d.keys()) # dict_keys(['张三', '李四', '王五', '赵六'])
print(d.values()) # dict_values([62, 73, 85, 99])
print(d.items()) # dict_items([('张三', 62), ('李四', 73), ('王五', 85), ('赵六', 99)])

4.反復処理
d = {'张三': 62, '李四': 60, '王五': 85}
for key in d:
print(f'{key}的成绩是 {d[key]}')
for key in d.keys():
print(f'{key}的成绩是 {d[key]}')
5.まとめ
辞書のデータは key:value の形式で保存されます。
キーは重複できず、不変型 でなければなりません。値は任意の型を使用できます。
辞書の要素は インデックス(下標)ではアクセスできません。
辞書は 追加・削除・変更・検索 をサポートしています。
一意の識別子に対応する情報構造が必要な場合は、辞書を使うのが最適です。
十:データコンテナ
# ① list関数:空のリストを定義 / イテラブルオブジェクトをリストに変換
# ② tuple関数:空のタプルを定義 / イテラブルオブジェクトをタプルに変換
# ③ set関数:空の集合を定義 / イテラブルオブジェクトを集合に変換
# ④ str関数:空の文字列を定義 / イテラブルオブジェクトを文字列に変換
# ⑤ dict関数:空の辞書を定義 / イテラブルオブジェクトを辞書に変換
# すべてのデータコンテナは in / not in をサポートし、要素がコンテナに含まれているかを判定可能
res1 = list(range(8))
res2 = list('欢迎来到尚硅谷')
res3 = list({10, 20, 30, 40, 50})
res4 = list({'张三': 62, '李四': 73, '王五': 85}.items())
print(type(res1), res1) # <class 'list'> [0, 1, 2, 3, 4, 5, 6, 7]
print(type(res2), res2) # <class 'list'> ['欢', '迎', '来', '到', '尚', '硅', '谷']
print(type(res3), res3) # <class 'list'> [50, 20, 40, 10, 30]
print(type(res4), res4) # <class 'list'> [('张三', 62), ('李四', 73), ('王五', 85)]
str = '欢迎来到尚硅谷'
print('欢迎' in str) # True
まとめ
for 文で反復処理(ループ)でき、要素を一つずつ取り出せるオブジェクトをイテラブルオブジェクトという。例えば、リスト、タプル、文字列、辞書、集合、range オブジェクトなどがある。


| データ型 | 書き方 | 順序 | インデックスアクセス | 重複 | 可変性 | 主な特徴 | 主な使用場面 |
|---|---|---|---|---|---|---|---|
| リスト(List) | [] |
あり | 可能 | 可 | 可変 | 追加・削除・変更・参照が可能、長さが可変 | データを頻繁に操作する場合 |
| タプル(Tuple) | () |
あり | 可能 | 可 | 不可変 | 読み取り専用、作成後は変更不可 | 変更しないデータを保存する場合 |
| セット(Set) |
{} / set()
|
なし | 不可 | 不可 | 可変 | 要素は一意、順序なし、重複排除に便利 | 順序を気にせず存在確認する場合 |
| 辞書(Dict) | {key: value} |
なし* | 不可 | key は不可 | 可変 | キーと値のペアで管理、key で value にアクセス | 一対一のデータ管理 |
十一:オブジェクト指向
1.クラス/インスタンス
# クラス名:パスカルケース(アッパーキャメルケース)
class Person:
# __init__メソッド:初期化メソッド
# 主な役割は、現在生成されているインスタンスオブジェクトに属性を追加すること
# 引数:現在生成されているインスタンス(self)、その他の任意の引数
# インスタンス生成時に、自動的に __init__ が呼び出される
def __init__(self, name, age):
# インスタンスに属性を追加する(self.属性名 = 値)
self.name = name
self.age = age
# インスタンスを生成
p1 = Person('张三', 18)
# インスタンスの属性にアクセス
print(p1.name) # 张三
# インスタンス.__dict__ を使って、インスタンスが持つすべての属性を確認できる
print(p1.__dict__) # {'name': '张三', 'age': 18}
# インスタンス生成後でも、インスタンス.属性名 = 値 の形で新しい属性を追加することができる
p1.gender = 'male'
print(p1.__dict__) # {'name': '张三', 'age': 18, 'gender': 'male'}
# type関数を使うことで、あるインスタンスオブジェクトがどのクラスから生成されたかを確認できる
print(type(p1)) # <class '__main__.Person'>
2.ユーザー定義メソッド
class Person:
def __init__(self, name, age):
# インスタンス.属性名 = 値 の形でインスタンスに追加した属性を、インスタンス属性と呼ぶ
# 各インスタンスはそれぞれ独立したインスタンス属性を持ち、インスタンス同士で互いに影響し合うことはない
self.name = name
self.age = age
# 独自メソッド:インスタンスに振る舞い(動作)を追加する
# speakメソッドが受け取る引数:speakメソッドを呼び出したインスタンスオブジェクト(self),その他の引数
# speakメソッドは1つだけ定義され、Personクラスに属している
# Personクラスのすべてのインスタンスからspeakメソッドを呼び出すことができる
def speak(self, msg):
print(f'私の名前は{self.name}、年齢は{self.age}歳です。{msg}と言いたいです。')
p1 = Person('张三', 18)
p1.speak('你好') # 私の名前は张三、年齢は18歳です。你好と言いたいです。
3.クラス属性
class Person:
# max_age はクラス属性で、クラスに保存される
# クラス属性は、クラスからもインスタンスからもアクセスできる
# クラス属性は通常、「共通データ」を保存するために使われる
max_age = 120
def __init__(self, name, age):
self.name = name
if age <= Person.max_age:
self.age = age
else:
print(f'年齢が範囲を超えています。年齢を最大値 {Person.max_age} に設定しました')
self.age = Person.max_age
# インスタンス.属性名 = 値 の操作を行っても、影響するのはそのインスタンス自身の属性だけで、クラス属性には影響しない
p1 = Person('张三', 18)
p1.max_age = 30
print(p1.max_age) # 30
4.メソッド
# クラスメソッド @classmethod
# 引数:現在のクラス自身(cls)、および任意の引数
@classmethod
def test1(cls, data):
print(cls, data)
# 静的メソッド @staticmethod
# 引数はすべて任意の引数で、メソッド内部ではクラスやインスタンスの内容には一切アクセスしない
# isinstance(instance, Class): あるオブジェクトが、指定したクラスまたはそのサブクラスのインスタンスかどうかを判定する
# issubclass(Class1, Class2): あるクラスが、別のクラスのサブクラスかどうかを判定する
# クラスの中で、インスタンス用のメソッドを定義する場合にのみ self を書き、self は現在のオブジェクト自身を指します。
# クラスの外では、オブジェクトを生成し、そのオブジェクトでメソッドを呼び出したり、属性を追加したりします。
| 方法类型 | 写法 | 是否写在类里 | 是否用 self / cls | 什么时候用(大白话) | 怎么调用 |
|---|---|---|---|---|---|
| 实例方法 | def func(self, ...) | ✅ 是 | self | 操作某一个具体对象的数据 | 对象.func() |
| 类方法 |
@classmethod def func(cls, ...) |
✅ 是 | cls | 操作整个类,和具体对象无关 | 类.func() / 对象.func() |
| 静态方法 |
@staticmethod def func(...) |
✅ 是 | 不用 | 只是放在类里的普通工具函数 | 类.func() / 对象.func() |
| 初始化方法 | def init(self, ...) | ✅ 是 | self | 创建对象时,给对象设置初始属性 | 创建对象时自动调用 |
5.継承
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def speak(self, msg):
print(f'私は{self.name}です。年齢は{self.age}歳で、言いたいことは:{msg}')
class Student(Person):
def __init__(self, name, age, gender):
# サブクラスで親クラスの初期化メソッドを呼び出し、継承した属性を初期化する
super().__init__(name, age)
self.gender = gender
s1 = Student('张三', 18, '男')
s1.speak('頑張ろう') # 私は张三です。年齢は18歳で、言いたいことは:頑張ろう
多重継承
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def speak(self, msg):
print(f'私の名前は{self.name}で、年齢は{self.age}歳です')
class Worker:
def __init__(self, company):
self.company = company
def do_work(self):
print(f'私は{self.company}でアルバイトをしています')
class Student(Person, Worker):
def __init__(self, name, age, company, gender):
# サブクラス(子クラス)内で親クラスの初期化メソッドを呼び出し、継承した属性を初期化する
Person.__init__(self, name, age)
Worker.__init__(self, company)
self.gender = gender
def study(self):
print(f'私の性別は:{self.gender}です')
s1 = Student('张三', 18, 'マクドナルド', '男')
s1.speak('こんにちは') # 私の名前は张三で、年齢は18歳です
s1.do_work() # 私はマクドナルドでアルバイトをしています
s1.study() # 私の性別は:男です
6.メソッドのオーバーライド
# 子クラスで親クラスと同じ名前のメソッドを定義すると、子クラスのメソッドが親クラスのメソッドをオーバーライド(上書き)します
def speak(self, msg):
super().speak(msg)
print(f'私の名前は{self.name}で、年齢は{self.age}歳です。伝えたいことは:{msg}')
7.3つの権限
class Person:
def __init__(self, name, age, idcard):
self.name = name # 公開属性:現在のクラス内、サブクラス内、クラス外からもアクセス可能
self._age = age # 保護属性:現在のクラス内およびサブクラス内からアクセス可能
self.__idcard = idcard # プライベート属性:現在のクラス内でのみ使用可能

8.getter/setter
Pythonでは、属性名の先頭に _ を付けることで「保護された属性」を表し、外部から直接アクセスしないことを意図します。
この場合、getterメソッドを定義して@propertyデコレータを付けることで、クラスの外からは通常の属性のように値を取得できます。
また、この保護された属性を変更したい場合は、同名のsetterメソッドを定義し、@属性名.setter デコレータを付けます。
外部からは通常の属性に代入するのと同じ書き方で値を変更でき、setter内で妥当性チェックなどのロジックを追加することも可能です。
class Person:
def __init__(self, name, age, idcard):
self.name = name
self._age = age
self.__idcard = idcard
# age属性的getter方法を登録する。
# Personのインスタンスのage属性にアクセスすると、以下のageメソッドが自動的に呼び出される
@property
def age(self):
return self._age
# age属性的setter方法を登録する。
# Personのインスタンスのage属性を変更すると、以下のageメソッドが自動的に呼び出される
@age.setter
def age(self, value):
if value <= Person.max_age:
self._age = value
else:
print('年齢が不正なため、変更に失敗しました')
p1 = Person('張三', 18, '11111111111')
print(p1.name) # 張三
print(p1.age) # 18
p1.age = 20
print(p1.age) # 20
9.特殊メソッド
# __xxx__ の形式で命名された特殊メソッドを「マジックメソッド」と呼ぶ
# Python は特定の場面で、これらのメソッドを自動的に呼び出す
# len(Personのインスタンス) を実行したときに呼び出される
def __len__(self):
return len(p1.__dict__)
# Personのインスタンス1 > Personのインスタンス2 を実行したときに呼び出される
def __gt__(self, other):
return self.age > other.age
# Personのインスタンスに存在しない属性へアクセスしたときに呼び出される
def __getattr__(self, item):
return f'アクセスしようとした属性「{item}」は存在しません'
p1 = Person('張三', 19)
print(p1.__dict__) # オブジェクト自身が持っている属性
print(dir(p1)) # オブジェクトがアクセス可能な属性(自身のもの+継承されたもの)

十二:多態性および抽象クラス
1.多態性
# ポリモーフィズム:同じメソッド名でも、異なるオブジェクトに対して呼び出すと、異なる振る舞いを示すこと
class Animal:
def speak(self):
print('動物が鳴いています')
class Dog(Animal):
def speak(self):
print('ワンワン')
class Cat(Animal):
def speak(self):
print('ニャーニャー')
def make_sound(animal: Animal):
animal.speak()
a1 = Animal()
d1 = Dog()
c1 = Cat()
# ダック・タイピング(ダックポリモーフィズム):オブジェクトの型はチェックせず、そのオブジェクトが「何ができるか」、つまり対応するメソッドを持っているかどうかに注目する
2.抽象クラス
抽象クラス:
@abstractmethod を持つクラスで、直接インスタンスを生成することはできません。
抽象メソッド:
名前だけを定義し、具体的な実装は書かず、サブクラスに実装を強制します。
サブクラスは、すべての抽象メソッドを実装して初めて、インスタンスを生成し、メソッドを呼び出すことができます。
核心となる考え方:
抽象クラスは「ルールブック」のようなもので、サブクラスはそのルールを守らなければ使用できません。
クラスが抽象クラスになるためには、ABC を継承しており、かつ 1 つ以上の抽象メソッドを持っている必要があります。
# 抽象クラス:直接インスタンス化できないクラス。
# 通常は「仕様(ルール)」として使われ、サブクラスが継承し、定義された抽象メソッドを実装する
class MustRun(ABC):
@abstractmethod
def run(self):
pass
class Person(MustRun):
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def run(self):
print(f'私は{self.name}です。一生懸命走っています')
p1 = Person('張三', 18, '男')
p1.run()
3.可変/不変オブジェクト
可変オブジェクト:list、dict、set、ユーザー定義クラスのインスタンス
不変オブジェクト:int、float、bool、str、tuple、frozenset、None
十三:関数
1.作用
# 1. 関数には動的に属性を追加できる
def welcome():
print('こんにちは')
welcome.desc = 'これは挨拶を行う関数です'
welcome.version = 1.0
print(welcome.desc)
print(welcome.version)
# 2. 関数は変数に代入できる
say_hello = welcome
say_hello()
print(say_hello.desc)
print(say_hello.version)
# 3. 関数は引数として渡すことができる
def caller(f):
print('caller関数が呼び出されました')
f()
caller(welcome)
# 4. 関数は戻り値として返すこともできる
def welcome():
print('こんにちは')
def show_msg(msg):
print(msg)
return show_msg
welcome()('尚硅谷')
# 関数の複数戻り値
def calculate(x, y):
res1 = x + y
res2 = x - y
return res1, res2
res = calculate(1, 2)
print(res)
r1, r2 = calculate(1, 2)
print(r1, r2)
2.引数のパックとアンパック
# 1. 引数をパックして受け取る
# *args はすべての位置引数をパックし、タプルになる
# **kwargs はすべてのキーワード引数をパックし、辞書になる
def show_info(*args, **kwargs):
print(*args)
print(**kwargs)
show_info(10, 20, 30, name='張三', age=18, gender='男')
# 2. 引数をアンパックして渡す
# *変数名:タプルを分解し、個々の位置引数として渡す
# **変数名:辞書を分解し、key=value 形式のキーワード引数として渡す
def show_info(num1, num2, num3, name, age, gender):
print(num1, num2, num3)
print(name, age, gender)
nums = (10, 20, 30)
person = {'name': '張三', 'age': 18, 'gender': '男'}
show_info(*nums, **person)
# 3. 引数のパックとアンパックを組み合わせて使用する
def show_info(*args, **kwargs):
print(args)
print(kwargs)
nums = (10, 20, 30)
person = {'name': '張三', 'age': 18, 'gender': '男'}
show_info(*nums, **person)
3.高階関数
# 高階関数:
# 処理(振る舞い)を独立させ、異なる関数を渡すことで異なるロジックを実現できる
def info(msg):
return '[通知]: ' + msg
def warn(msg):
return '[警告]: ' + msg
def error(msg):
return '[エラー]: ' + msg
def log(func, text):
print(func(text))
log(info, 'ファイルの保存に成功しました')
log(warn, 'ディスクの空き容量が不足しています')
log(error, '該当するユーザーは存在しません')
4.条件式
# 条件式:値1 if 条件 else 値2
# 使用シーン:二者択一の場合
age = 15
text = '成人' if age >= 18 else '未成年'
print(text)
5.無名関数
# 無名関数(lambda式)
# 書式:lambda 引数 : 式
# 使用シーン:関数を一度だけ使う場合や、簡単な処理を行う場合
# 注意点:
# ・1行しか書けない(複数行は不可)
# ・コードブロックは書けない(if、for、while などは不可)
# ・コロンの右側は必ず「式」でなければならず、1つの式のみ書ける
# ・その式の結果が自動的に戻り値になる
add1 = lambda x, y: x + y
add2 = lambda x: x + x
add3 = lambda: '私はadd3関数です'
result1 = add1(1, 2)
result2 = add2(30)
result3 = add3()
print(result1, result2, result3)
6.データ処理関数
map
# map関数:map(操作する関数, イテラブル)
# データ集合内の各要素に対して、同じ処理を一括で実行し、新しいデータを生成する # 戻り値はイテレータオブジェクトのため、走査(ループ)または型変換が必要
# データの一括処理
nums = [10, 20, 30, 40]
result1 = map(lambda x: x * 2, nums)
print(list(result1))
print(nums)
# 文字列変換
names = ('java', 'python', 'js')
result2 = map(lambda x: x.upper(), names)
print(tuple(result2))
# 型変換
str_number = {'1', '2', '3'}
result3 = map(int, str_number)
print(set(result3))
print(str_number)
filter
# filter関数:filter(フィルタリング関数, イテラブル)
# データ集合から、条件を満たす要素を抽出し、新しいデータの集合を生成する
# 数値の抽出
nums = [10, 20, 30, 40]
result1 = filter(lambda x: x > 30, nums)
print(list(result1))
print(nums)
# 成人の抽出
persons = [
{'name': '張三', 'age': 20, 'gender': '男'},
{'name': '李四', 'age': 15, 'gender': '女'},
{'name': '王五', 'age': 18, 'gender': '男'}
]
result2 = filter(lambda x: x['age'] >= 18, persons)
print(list(result2))
# 不正な文字列の除外
names = ['張三', '', '李四', None]
result3 = filter(lambda x: x, names)
print(list(result3))
# 関数を指定しない場合、偽と判定される値は自動的に除外される
data = [0, 1, '', 'hello', (), 5]
result4 = filter(None, data)
print(list(result4))
sorted
# sorted関数:sorted(イテラブル, key=xxx, reverse=xxx)
# データ集合を並び替え、新しいデータを返す
# 数値の並び替え
nums = [50, 20, 70, 40]
result1 = sorted(nums, reverse=True)
print(result1)
# 文字列の長さで並び替える
names = ['python', 'sql', 'java']
result2 = sorted(names, key=len)
print(result2)
# 辞書の特定のフィールドを基準に並び替える
persons = [
{'name': '張三', 'age': 20, 'gender': '男'},
{'name': '李四', 'age': 15, 'gender': '女'},
{'name': '王五', 'age': 18, 'gender': '男'}
]
result3 = sorted(persons, key=lambda x: x['age'], reverse=True)
print(result3)
# min / max 関数も key 引数を指定して、比較基準を設定できる
result4 = max(persons, key=lambda x: x['age'])
print(list(result4))
reduce
# reduce関数:reduce(結合関数, イテラブル, 初期値)
# データ集合の要素を順次結合し、最終的に1つの結果にまとめる
# 使用するには functools モジュールをインポートする必要がある
from functools import reduce
# 数値の集計
nums = [1, 2, 3, 4, 5]
result1 = reduce(lambda x, y: x + y, nums, 10)
print(result1)
# 文字列の連結
str_list = ['ab', 'cd', 'ef']
result2 = reduce(lambda x, y: x + y, str_list)
print(result2)
7.リスト内包表記
# リスト内包表記:[式 for 変数 in イテラブル]
# イテラブルから新しいリストを生成する
nums = [10, 20, 30, 40]
result1 = [n * 2 for n in nums]
print(result1) # [20, 40, 60, 80]
result2 = [n * 2 for n in nums if n > 20]
print(result2) # [60, 80]
8.よく使われる組み込み関数
# 一:入力と出力
# 1. input():ユーザー入力を取得する
# 2. print():指定した内容を出力する
# 二:型変換
# 1. int():整数に変換する
# 2. float():浮動小数点数に変換する
# 3. str():文字列に変換する
# 4. bool():真偽値に変換する
# 5. list():リストに変換する
# 6. tuple():タプルに変換する
# 7. set():セットに変換する
# 8. dict():辞書に変換する
# 三:数値関連
# 1. abs():絶対値を取得する
print(abs(-9))
# 2. round():四捨五入
# 5 の場合は奇数か偶数かを見て、奇数は切り上げ、偶数は切り捨て
print(round(7.5))
# 3. pow():べき乗
print(pow(2, 3))
# 4. divmod():商と余りを同時に取得する
print(divmod(10, 3))
# 5. max():最大値
# 6. min():最小値
# 7. sum():合計を求める
# 8. map():データを一括加工する
# 9. filter():条件に基づいてデータを抽出する
# 10. reduce():結合して計算する
# 11. sorted():並び替え
# 四:データコンテナ関連
# 1. len():コンテナ内の要素数を取得する
# 2. range():数値のシーケンスを生成する(ループで使用可能)
for index in range(0, 10, 2):
print(index)
# 3. enumerate():シーケンスにインデックスを付与する
# 4. zip():複数のシーケンスを要素ごとにまとめる
names = ('張三', '李四')
scores = [60, 70, 80]
result1 = zip(names, scores)
for item in result1:
print(item)
# 五:型判定・オブジェクト関連
# 1. type():型を確認する
# 2. isinstance():型を判定する
# 3. issubclass():クラス間の継承関係を判定する
# 4. id():オブジェクトのメモリアドレスを取得する
# 六:論理判定関連
# 1. all():すべて True の場合に True を返す
l1 = [10, '尚硅谷', {1, 2, 3}, -9]
print(all(l1))
# 2. any():1つでも True があれば True を返す
l2 = [0, '', None, False, 10]
print(any(l2))
# 七:文字列補助関連
# 1. ord():文字の Unicode コードポイントを取得する
# 2. chr():Unicode コードポイントから文字に変換する
十四:コピー/スコープ/クロージャ/デコレータ/型注釈
1.コピー
浅いコピー
import copy
# 直接代入:2つの変数が同じオブジェクトを参照するため、どちらかを変更すると、もう一方にも影響する
nums1 = [10, 20, 30, 40, 50]
nums2 = nums1
nums2[2] = 99
print(nums1[2]) # 99
print(nums2[2]) # 99
# シャローコピー:外側のコンテナは新しく作成されるが、内部の要素は元のオブジェクトへの参照のまま
nums3 = copy.copy(nums1)
nums3[2] = 100
print(nums3[2]) # 100
print(nums1[2]) # 99
# nums2 = nums1(参照代入)
# → 2 つの変数が同じオブジェクトを参照するため、片方を変更するともう一方にも影響します。
# nums2 = nums1.copy()(浅いコピー)
# → 新しいリストオブジェクトが生成されるため、互いに影響しません。
# シャローコピーの問題点:
# ネストされたデータは共有されたままなので、ネスト内部を変更すると相互に影響する
nums4 = [10, 20, 30, [40, 50]]
nums5 = copy.copy(nums4)
nums5[3][0] = 400
print(nums4[3][0]) # 400
print(nums5[3][0]) # 400
ディープコピー
import copy
# ディープコピー:
# 外側のコンテナを新しく作成し、内部のすべての「変更可能(mutable)」な子オブジェクトを再帰的にコピーする
# ディープコピーを使うことで、データ同士の相互影響を完全に防ぐことができる
# なお、変更不可(immutable)なオブジェクトに対してはコピーせず、そのまま参照が使われる
nums1 = [10, 20, 30, [40, 50]]
nums2 = copy.deepcopy(nums1)
nums2[3][0] = 400
print(nums2[3][0]) # 400
print(nums1[3][0]) # 40
# 注意点:
# ディープコピーは変更可能なオブジェクトのみをコピーし、変更不可なオブジェクトはそのまま参照される
# タプルの中身がすべて変更不可なオブジェクトの場合、ディープコピーを行っても効果はない
a = 666
b = copy.deepcopy(a)
print(id(a)) # 4343808528
print(id(b)) # 4343808528
2.スコープ
①変数にアクセスする際、Python は L → E → G → B の順番でスコープを探索する(LEGB ルール)。
②ローカルスコープ(L)
関数内で定義された変数のことで、その関数の内部でのみ参照可能。
③エンクロージングスコープ(E)
関数がネストして定義されている場合にのみ存在するスコープ。
内側の関数から外側の関数の変数を参照できるが、外側の変数を変更するには nonlocal キーワードを使用する必要がある。
④グローバルスコープ(G)
.py ファイル自体がグローバルスコープにあたる。
グローバル変数は同じ .py ファイル内のどこからでも参照可能で、関数内から変更する場合は global キーワードを使用する。
⑤ビルトインスコープ(B)
Python によってあらかじめ定義されているオブジェクトが含まれるスコープ。
すべての .py ファイルから直接利用できる。

3.クロージャ
# クロージャ(閉包)= 内側の関数 + 内側の関数から参照される外側の変数
# 条件:
# 1. 関数がネストして定義されていること
# 2. 内側の関数から外側の関数の変数にアクセスしていること
# 3. 外側の関数が内側の関数を返していること
# 注意点:
# 1. 外側の関数を n 回呼び出すと、n 個の異なるクロージャが生成され、それぞれは互いに影響し合わない
# 2. 内側の関数で使用される外側の変数が変更可能(mutable)なオブジェクトであっても、複数のクロージャ間で影響し合うことはない
def outer():
num = 10
def inner():
nonlocal num
num += 1
print(num)
return inner
f1 = outer()
f1()
f1()
f1()
print('*****')
f2 = outer()
f2()
f2()
4.デコレータ
①関数デコレータ
add / sub 関数のコードを変更せずに、実行前に共通で「こんにちは。計算を開始します」と表示したい。さらに、このデコレータは(「加算 / 減算」などの)引数も受け取れるようにする。
引数付きデコレータの構造は、外側で引数を受け取り → 中間で関数を受け取り → 内側で実際の処理を実行する、という三層構造になる。
この三層は同時に実行されるのではなく、「三つの異なるタイミング」で順番に実行される。
# デコレータ
# 1. 呼び出し可能なオブジェクトで、通常は関数である関数を引数として受け取り、新しい関数を返す
# 2. 元の関数のコードを変更することなく、関数の機能を拡張・変更できる
# 実際の利用例:
# 元の関数を変更せずに、ログ出力、処理時間の計測、入力チェック、キャッシュなどの共通機能を関数に追加できる
# 重要なポイント
# 1. デコレータは装飾対象の関数を受け取り、新しい関数(wrapper)を返す
# 2. デコレータが返すのは wrapper 関数であり、以後、呼び出されるのも wrapper 関数になる
# 3. 引数の互換性を保つため、wrapper 関数は *args と **kwargs で引数を受け取る
# 4. wrapper 関数の中では、元の関数を呼び出してその処理を実行し、戻り値を必ず return する必要がある
def say_hello(msg):
def outer(func):
def wrapper(*args, **kwargs):
print(f'こんにちは。計算を開始します')
return func(*args, **kwargs)
return wrapper
return outer
@say_hello('加算')
def add(a, b, c):
res = a + b + c
print(f'{a} と {b} と {c} を足した結果は {res} です')
return res
# 通常どおり add 関数を呼び出す
result1 = add(1, 2, 3)
print(result1)
@say_hello('減算')
def sub(a, b):
res = a - b
print(f'{a} と {b} を引いた結果は {res} です')
return res
# 通常どおり sub 関数を呼び出す
result2 = sub(1, 2)
print(result2)
# 複数のデコレータを同時に使用する
def test1(func):
print('私は test1 デコレータです')
def wrapper(*args, **kwargs):
print('test1 によって追加された処理です')
return func(*args, **kwargs)
return wrapper
def test2(func):
print('私は test2 デコレータです')
def wrapper(*args, **kwargs):
print('test2 によって追加された処理です')
return func(*args, **kwargs)
return wrapper
@test1
@test2
def add(a, b):
res = a + b
print(f'{a} と {b} を足した結果は {res} です')
return res
result = add(1, 2)
print(result)
②クラスデコレータ
# クラスデコレータ
# 1. __call__ メソッドを持つクラスは、クラスデコレータとして使用できる
# 2. 関数を呼び出すようにクラスデコレータのインスタンスを呼び出すと、__call__ メソッドが実行される
# 3. __call__ メソッドは通常、関数を引数として受け取り、新しい関数を返す
class SayHello:
def __init__(self, msg):
self.msg = msg
def __call__(self, func):
def wrapper(*args, **kwargs):
print(f'こんにちは。{self.msg} の計算を開始します')
return func(*args, **kwargs)
return wrapper
# @ 構文糖(デコレータ構文)を使ってクラスデコレータを適用する
@SayHello('加算')
def add(a, b):
res = a + b
print(f'{a} と {b} を足した結果は {res} です')
return res
# 通常どおり add 関数を呼び出す
result = add(1, 2)
print(result)
# 複数のクラスデコレータの使用
class Test1:
def __call__(self, func):
def wrapper(*args, **kwargs):
print('test1 によって追加された処理です')
return func(*args, **kwargs)
return wrapper
class Test2:
def __call__(self, func):
def wrapper(*args, **kwargs):
print('test2 によって追加された処理です')
return func(*args, **kwargs)
return wrapper
@Test1()
@Test2()
def add(a, b):
res = a + b
print(f'{a} と {b} を足した結果は {res} です')
return res
result = add(1, 2)
print(result)
5.注釈
①変数の型注釈
# 変数の型注釈:変数に型情報を付与する |
num: int = 100
# 注意:変数の型注釈を先に記述し、後から代入することもできる
school: str
print('*****', school)
school = '尚硅谷'
# hobby はリストで、リスト内のすべての要素は str 型でなければならない
hobby: list[str] = ['抽烟', '喝酒', '烫头']
# hobby はリストで、リスト内の要素は str または int 型を許可する
hobby: list[str | int] = ['抽烟', '喝酒', '烫头']
hobby.append(100)
# 上記コードの旧来の書き方は以下の通り
from typing import Union
hobby: list[Union[str, int]] = ['抽烟', '喝酒', '烫头']
# citys は集合(set)で、すべての要素は str 型でなければならない
citys: set[str] = {'北京', '上海', '深圳'}
# citys は集合で、要素は str / float / bool 型を許可する
citys: set[str | float | bool] = {'北京', '上海', '深圳'}
# persons は辞書で、キーは str 型、値は int 型
persons: dict[str, int] = {'张三': 19, '李四': 22, '王五': 25}
# persons は辞書で、キーは str または int 型、値は int 型
persons: dict[str | int, int] = {'张三': 19, '李四': 22, '王五': 25}
# scores はタプルで、任意個数の要素を持ち、
# 各要素の型は int または str 型
scores: tuple[int | str, ...] = (60, '70', 80, '90', 100)
# Python は初期代入に基づいて変数の型を推論する
# 1. 通常の変数の場合:後から型を変更しても警告は出ない
# 2. コンテナ型の変数の場合: 内部要素の型は推論された型と一致している必要があり、一致しない場合は警告が出る
②関数の型注釈
# 関数の型注釈:関数の引数および戻り値に型情報を付与する
# 関数名(引数1: 型, 引数2: 型) -> 戻り値の型
# 1. 引数の型注釈と戻り値の型注釈を設定する
def add(x: int, y: int) -> int:
return x + y
# 2. 引数にデフォルト値がある場合でも、戻り値の型注釈を設定する
def add(x = 1, y = 1) -> int:
return x + y
# 3. 複数の戻り値に対する型注釈を設定する
def show_nums_info(nums: List[int]) -> tuple[int, int, float]:
max_value = max(nums)
min_value = min(nums)
result = max_value / min_value
return max_value, min_value, result
# 4. *args の型注釈を設定する
# args 内の各引数はすべて int 型である必要がある
def add(*args: int) -> int:
return sum(args)
# 5. **kwargs の型注釈を設定する
# kwargs の各値は str または int 型である必要がある
def show_info(**kwargs: str | int):
print(kwargs)
# 関数の型注釈情報を取得する
print(add.__annotations__)
十五:例外
1.タイプ
# 1. ZeroDivisionError:除数が 0 の場合に発生する
# 2. TypeError:操作対象のデータ型が正しくない、または互換性がない場合に発生する
# 3. AttributeError:オブジェクトに指定された属性やメソッドが存在しない場合に発生する
# 4. IndexError:インデックスが範囲外の場合に発生する
# 5. NameError:存在しない変数を使用した場合に発生する
# 6. KeyError:辞書に存在しないキーにアクセスした場合に発生する
# 7. ValueError:型は正しいが、値が不正な場合に発生する
2.処理
# 例外処理(初級)
# 1. 例外が発生する可能性のあるコードを try に記述し、例外発生時の処理を except に記述する
# 2. try 内のコードで例外が発生すると、try 内のそれ以降のコードは実行されず、自動的に except に処理が移る
# 3. try 内のコードで例外が発生しなかった場合、except 内のコードは実行されない
# 4. 例外が発生したかどうかに関係なく、try-except の後のコードは引き続き実行される
# 5. except を単独で記述すると、Python のすべての例外を捕捉してしまうため、推奨されない
print('本プログラムをご利用いただきありがとうございます')
try:
a = int(input('1つ目の数値を入力してください: '))
b = int(input('2つ目の数値を入力してください: '))
result = a / b
print(f'{a} を {b} で割った結果は:{result}')
except:
print('申し訳ありません。プログラムで例外が発生しました')
print('これは後続の別の処理1です')
print('これは後続の別の処理2です')
# 例外処理(特定の例外型を捕捉する)
print('本プログラムをご利用いただきありがとうございます')
try:
a = int(input('1つ目の数値を入力してください: '))
b = int(input('2つ目の数値を入力してください: '))
result = a / b
print(f'{a} を {b} で割った結果は:{result}')
except ZeroDivisionError:
print('プログラムエラー:0 は除数として使用できません')
except ValueError:
print('プログラムエラー:数値を入力してください')
print('これは後続の別の処理1です')
print('これは後続の別の処理2です')
# 1つの except で複数の例外を捕捉する
print('本プログラムをご利用いただきありがとうございます')
try:
a = int(input('1つ目の数値を入力してください: '))
b = int(input('2つ目の数値を入力してください: '))
result = a / b
print(f'{a} を {b} で割った結果は:{result}')
except (ZeroDivisionError, ValueError, Exception) as e:
if isinstance(e, ZeroDivisionError):
print('プログラムエラー:0 は除数として使用できません')
elif isinstance(e, ValueError):
print('プログラムエラー:数値を入力してください')
else:
print(f'プログラムエラー:{e}')
print('これは後続の別の処理1です')
print('これは後続の別の処理2です')
# プログラムが想定外の状況に遭遇した場合:raise 文を使用する
print('年齢判定システムへようこそ')
try:
age = int(input('あなたの年齢を入力してください: '))
if 18 <= age <= 120:
print('成人')
elif 0 <= age < 18:
print('未成年')
else:
# print('入力された年齢が不正です。年齢は 0〜120 の整数である必要があります')
raise ValueError('年齢は 0〜120 の整数である必要があります')
except Exception as e:
print(f'プログラムエラー:{e}')
3.例外の詳細情報を取得する
print('本プログラムをご利用いただきありがとうございます')
try:
a = int(input('1つ目の数値を入力してください: '))
b = int(input('2つ目の数値を入力してください: '))
result = a / b
print(f'{a} を {b} で割った結果は:{result}')
except ZeroDivisionError:
print('プログラムエラー:0 は除数として使用できません')
except ValueError:
print('プログラムエラー:数値を入力してください')
except Exception as e:
print(f'プログラムエラー:例外メッセージ:{e}')
print(f'プログラムエラー:例外の型:{type(e)}')
print(f'プログラムエラー:例外の引数:{e.args}')
print(f'プログラムエラー:例外が発生したファイル:{e.__traceback__.tb_frame.f_code.co_filename}')
print(f'プログラムエラー:例外が発生した行番号:{e.__traceback__.tb_lineno}')
print('これは後続の別の処理1です')
print('これは後続の別の処理2です')
# traceback を使って例外をトレース(遡及)する
# import traceback
# print(traceback.format_exc())
4.書き方
# 例外処理の完全な書き方
# 1. try : 例外が発生する可能性のある処理を実行する
# 2. except : 例外が発生した場合の処理
# 3. else : 例外が発生しなかった場合に実行する処理
# 4. finally: 例外の有無にかかわらず必ず実行される処理
print('本プログラムをご利用いただきありがとうございます')
try:
a = int(input('1つ目の数値を入力してください: '))
b = int(input('2つ目の数値を入力してください: '))
result = a / b
print(f'{a} を {b} で割った結果は:{result}')
except (ZeroDivisionError, ValueError, Exception) as e:
if isinstance(e, ZeroDivisionError):
print('プログラムエラー:0 は除数として使用できません')
elif isinstance(e, ValueError):
print('プログラムエラー:数値を入力してください')
else:
print(f'プログラムエラー:{e}')
else:
print('try 内のコードでは例外は発生しませんでした')
finally:
print('例外の有無にかかわらず、計算処理は終了しました')
print('これは後続の別の処理1です')
print('これは後続の別の処理2です')
5.自作例外クラス
# クラス名は通常 Error で終わり、Exception クラスまたはそのサブクラスを継承する
class SchoolNameError(Exception):
def __init__(self, msg):
super().__init__('【学校名エラー】' + msg)
def check_school_name(name):
if len(name) > 10:
raise SchoolNameError('学校名が長すぎます')
else:
print('学校名は有効です')
try:
check_school_name('atttttttttttttttttttttt')
except SchoolNameError as e:
print(f'プログラムエラー:{e}')
十六:モジュール/パッケージ/環境
1.モジュール
# よく使われるモジュールのインポート方法
# 1. import モジュール名
# 2. import モジュール名 as 別名
# 3. from モジュール名 import 要素1, 要素2, ...
# 4. from モジュール名 import 要素1 as 別名1, 要素2 as 別名2, ...
# 5. from モジュール名 import *
# __all__
# from モジュール名 import * でインポートできる内容を制御する
# __all__ の値はリストやタプルを指定できる
# __name__ の値について
# メインプログラムとして直接実行された場合、__name__ の値は "__main__" になる
# 他のプログラムからモジュールとしてインポートされた場合、__name__ の値はモジュールのファイル名(.py を除く)になる
# 標準ライブラリモジュール
# Python と一緒にインストールされているモジュール
# 1. import copy : オブジェクトのコピー
# 2. import os : OS 関連の操作
# 3. import random : 乱数関連の処理
# 4. import time : 時間に関する操作
# 5. import math : 数学関連の処理
# 6. import sys : Python インタプリタ関連の操作
2.パッケージ
# パッケージ
# 命名規則:すべて小文字のアルファベットを使用する
# よく使われるパッケージのインポート方法
# 1. import パッケージ名.モジュール名
# 2. import パッケージ名.モジュール名 as 別名
# 3. from パッケージ名.モジュール名 import 要素1, 要素2, ...
# 4. from パッケージ名.モジュール名 import 要素1 as 別名1, 要素2 as 別名2, ...
# 5. from パッケージ名.モジュール名 import *
# 6. from パッケージ名 import モジュール名
# 7. from パッケージ名 import モジュール名 as 別名
# 8. from パッケージ名 import *
# 9. import パッケージ名
# __init__.py ファイルについて
# 1. パッケージの初期化ファイルであり、
# パッケージがインポートされると自動的に __init__.py が実行される
# 2. パッケージの初期化処理を記述することができる
# 3. 定義された内容は、from パッケージ名 import * の形式ですべてインポートされる
# 4. __all__ を使用することで、from パッケージ名 import * でインポート可能なモジュールを制御することもできる

3.環境
