はじめに
前回の記事
音圧レベルFFT
の末尾に書いたように,ハンマで叩いた音は叩く力に依存して大きく聞こえたり小さく聞こえたりします.そのため,周波数分析する際も音圧レベルが変動すると想定されますので,力が入力された瞬間周辺のデータのみを解析することが望ましいです.
やること
・全データから,特定の力(任意値)が入力された瞬間周辺基準にトリミングし,音圧レベルFFTを行なう.
FFT条件
・解析対象は,ホワイトノイズ環境下で外壁タイルを1秒間に1回の頻度で10秒間加振した時の打音データ(前回と同じ)です.
・サンプリングレート fs:8192 Hz
・解析上限周波数:3200 Hz
・FFTブロックサイズ block_size:8192 点
・ライン数:3200 本
・オーバーラップ overlap:0.75
・周波数分解能 df:1.0 Hz
・1回のFFTにかかる時間:1.0 sec
・打音計測マイクのチャンネル本数:1 ch
・何 [N] の力をトリミング対象とするのか?:30 N(任意値で構いません)
(fs・blocksizeが何なのかについては下記のサイトを参考にしてください.個人的に,これが一番わかりやすいです)
NTi-audio
トリミング関数(非効率コード)
import numpy as np
import scipy.signal as ss
def force_base_trimming(data, block_size, goal_power):
impact_peak_index_and_number = ss.find_peaks(data[:, 0], height = 0.1, distance = 2000) # まず加振ハンマの時間波形のデータからピーク検出.これはタプル型.0.1よりも高い値をピークと判断.
impact_peak_number_only = impact_peak_index_and_number[1] # こいつはなぜかdict型.検出したインデックスのときの力はどんな値を取るのか変換
impact_peak_number_only_to_array = list(impact_peak_number_only.values())[0]
nearest_peak_index_of_array = np.argsort(np.abs(impact_peak_number_only_to_array - goal_power))
border_index = impact_peak_index_and_number[0][nearest_peak_index_of_array[0]] # ソートしたうちの0番目のインデックス➡一番目標値に近しいインデックスが摘出される
trimmed_data = data[np.int(border_index - (block_size / 2) + np.int(border_index + (block_size / 2) + 1), :]
"TODO:ダブルハンマしたときの例外処理を書く➡re-take"
calculate_peak_in_trimmed_data = ss.find_peaks(trimmed_data[:, 0], height = 0.1, distance = 100) # サンプリングデータ数が100個ずつにしたときのピークをカウント
if calculate_peak_in_trimmed_data[0].shape[0] == 1:
print('ダブルハンマなし {:.3f} N'.format(max(trimmed_data[:, 0]))) # トリムした加振ハンマの最大値を小数点以下第3位まで表示される
else:
print('ダブルハンマリング \n 1回目の再取得スタート')
border_index = impact_peak_index_and_number[0]nearest_peak_index_of_array[1]]
trimmed_data = data[np.int(border_index - (block_size / 2) + 1):np.int(border_index + (block_size / 2) + 1), :]
print('1回目の再取得完了')
calculate_peak_in_trimmed_data = ss.find_peaks(trimmed_data[:, 0], height = 0.1, distance = 100)
if calculate_peak_in_trimmed_data[0].shape[0] == 1:
print("1回目の再取得verにダブルはない")
else:
print('1回目の再取得verにダブルはまだある \n 2回目の再取得スタート')
border_index = impact_peak_index_and_number[0]nearest_peak_index_of_array[2]]
trimmed_data = data[np.int(border_index - (block_size / 2) + border_index + (block_size / 2) + 1), :]
print('2回目の再取得完了')
calculate_peak_in_trimmed_data = ss.find_peaks(trimmed_data[:, 0], height = 0.1, distance = 100)
if calculate_peak_in_trimmed_data[0].shape[0] == 1:
print("2回目の再取得verにダブルはない")
else:
print("2回目の再取得verにダブりがまだあるけど再取得しない.あきらめる.別の目標加振力を設定したほうが良い")
return trimmed_data # print('2回目の再取得verにダブルはない')のところのifに対する戻り値
return trimmed_data # 2つめのifに対する戻り値
return trimmed_data # 初めのifに対する戻り値
return trimmed_data # defの戻り値
どんな処理をしてる?(イメージ)
1⃣計測した力データを特定の数ずつに分割する.(今回は2000個のデータ群を1つの塊として扱い,複数の塊を生産)
2⃣2000個の中で0.1(任意値)を超える最大値を1つ探す.探し終わったら,別の2000個を対象に最大値を探す.終わったら次,次,次...
3⃣複数ある最大値のうち30 N(任意値)に一番近い力はどれか検索
4⃣任意値に近い力の配列番号を音圧信号の配列番号に照らし合わせ,配列番号を基準にFFT 1 ブロックの半分左右にオフセットし,トリミングする.(このようにすることで,ウィンドウ関数による音圧振幅の補正を最小限にすることができる.オリジナルデータが一番歪みにくい位置はウィンドウ関数の頂点と力が入力された瞬間がちょうど重なるとき.)
5⃣手順4⃣がダブルハンマ(短時間に2回以上加振してしまうこと.この信号をFFTすると正しく解析できない.)なのか検知するために,トリミングしたデータ(8192個)を対象に100個ずつ分割
6⃣100個の中0.1(任意値)を超える最大値を1つ探す.探し終わったら,別の100個を対象に最大値を探す.終わったら次,次,次...
7⃣複数ある最大値のうち0.1を超えるピークが2つ以上あるならそれなりに大きい力が2つ入力されていると判断できる.
8⃣ダブルハンマと見なし,2番目に近い30 Nのピークを基準にトリミング,ダブルハンマなのか再度検知,の繰り返し
結果
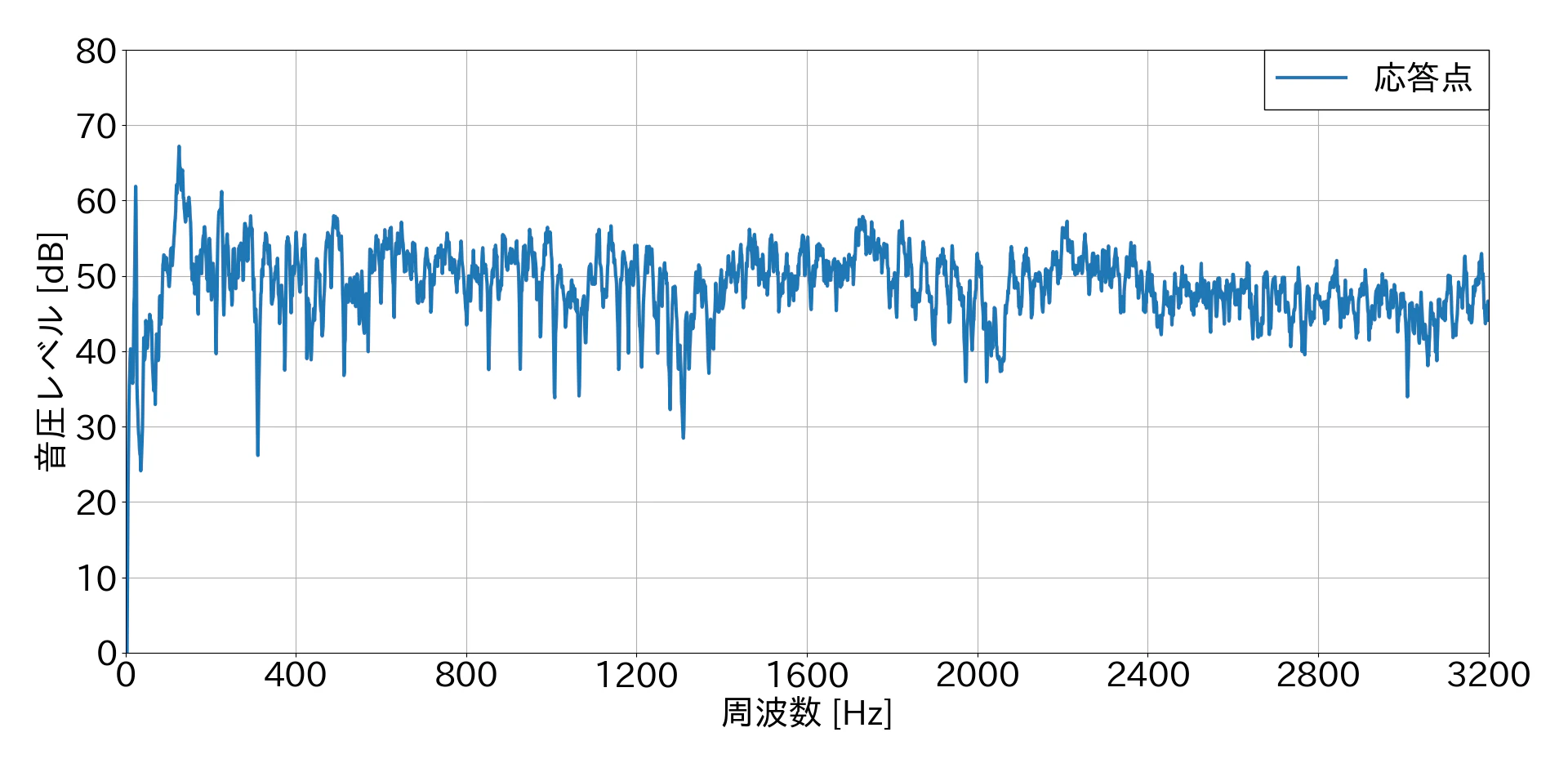
力が入力された瞬間周辺1秒間のデータをトリミングし,1回だけFFTした結果
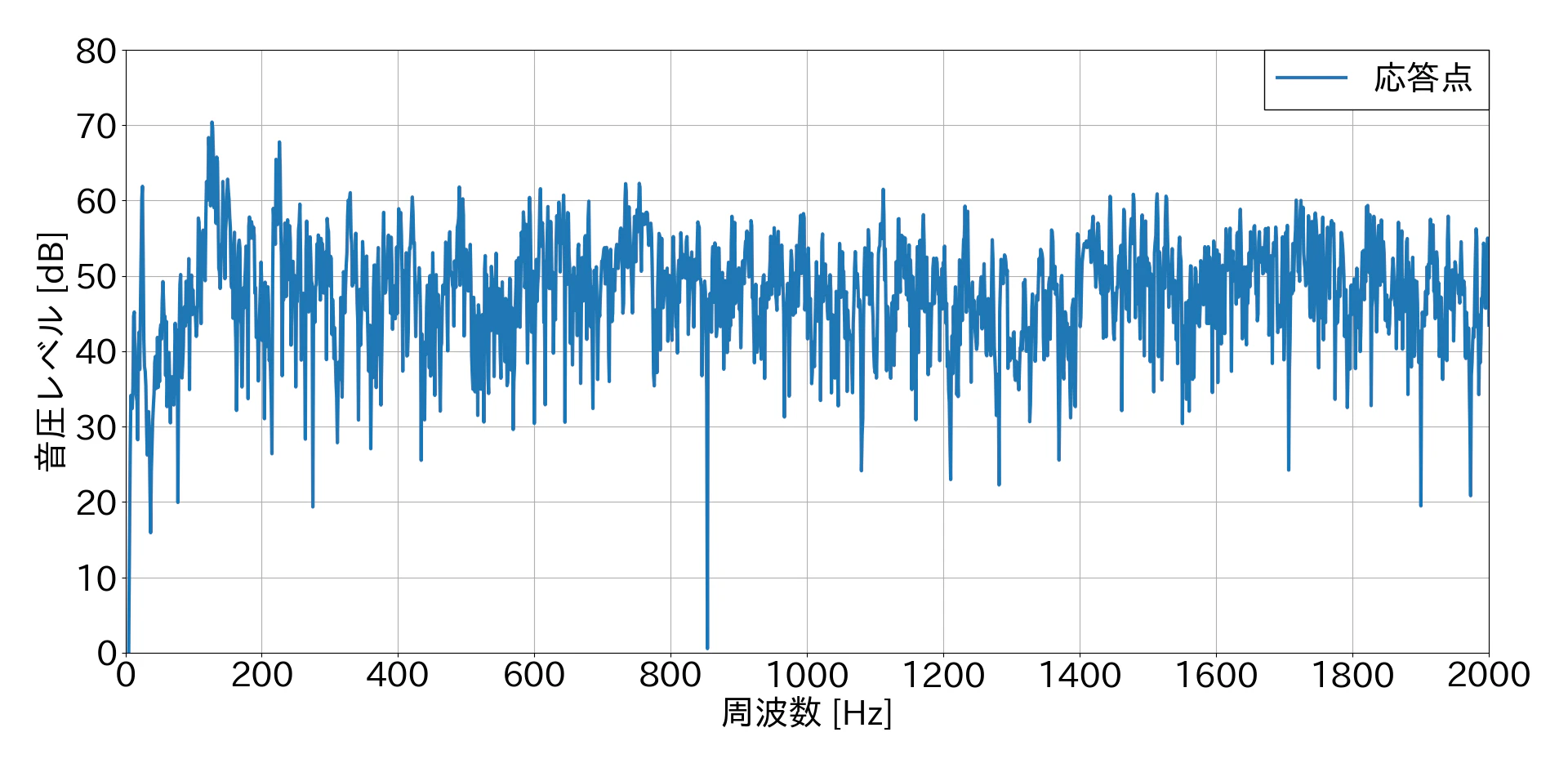
全データを対象に複数回FFTした結果(トリミングしない)
静粛環境下で同じタイルを加振し,同じ方法で1回だけFFTした結果(参考までに)
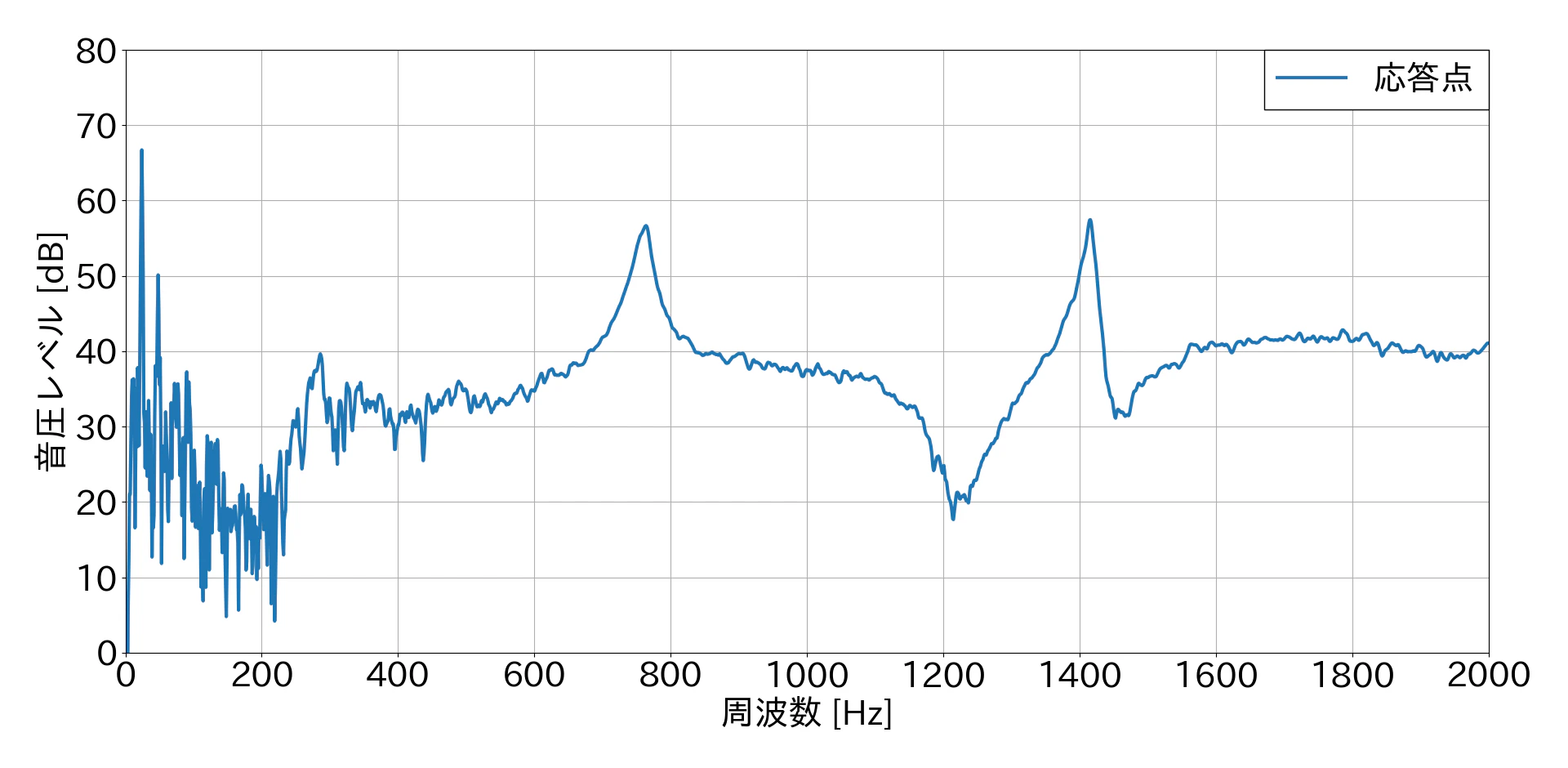
この結果から,1回だけFFTした結果の方が比較的ノイジーな音圧レベル結果となることが分かりました.しかし,特定の力が入力された瞬間の応答としてはこちらの方がふさわしいと思います.複数回FFTした結果の方がきれいなグラフになるのは,平均しているからだと思います.(間違えてたらすみません🙇.)
また,騒音環境下での結果と静粛環境下での結果を比較すると,ノイズに打音が埋もれていることが確認できるかと思います.静粛環境下での固有振動数は750 Hz・1400 Hzで約55 dBとなりはっきりとしたピークがありますが,騒音環境下では固有振動数のピークを確認することが困難であると思われます.
まとめ
ウィンドウ関数によって打音(インパルス応答)が大きく補正されないように,ウィンドウ関数の頂点と打音の最大振幅がちょうど重なるようなトリミング方法を紹介しました.その結果,複数回FFTの結果とどれほど違いが出るのかも確認しました(したつもり).正直「よくこんなコードを公開しようと思ったな?」と指摘されるほど下手なコードです.「もっとこうした方が良いのでは?」などの意見があれば嬉しいです.