はじめに
MLOps Advent Calendar 2022 9日目の記事です。
日本マイクロソフト株式会社で Cloud Solution Architect - AI をやっている伊藤と言います。よろしくお願いします。(ステマ回避の所属明言)
2022年12月現在、MLOps をやっていこうと思うとコードを書くことは不可避です。パイプラインをデプロイする Python スクリプト、API の構成を表現した yaml とコマンド、ジョブを実行するための Github Actions の定義 yaml などなど、MLOps をやっていくためには ML 周辺を固めるサービスを操作してやる必要があり、その操作は大抵コードで表現されています。そうなると各種サービスが備える SDK、 CLI、 API あたりの使い心地が MLOps の実装しやすさに直結することは想像に難くありません。
そういうわけで、今日は Azure における MLOps を支えるキーサービスである Azure Machine Learning を操作するために使えるプログラマブルなインターフェースである CLI v2 と SDK v2 がいかにイケてるか紹介しようと思います。
前提の話
Azure Machine Learning
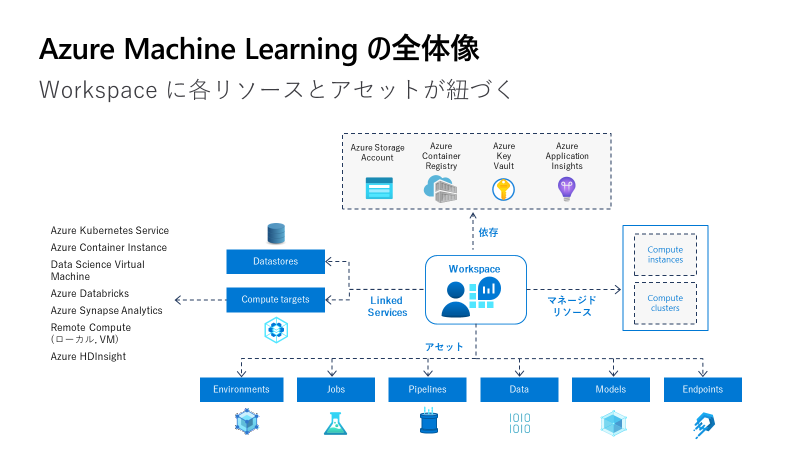
Azure Machine Learning (以下 AzureML)は機械学習のプロセス単位から各種プロセスを統合した MLOps まで幅広く取り扱うことを指向した PaaS です。
AzureML は配下に「アセット」を持ちます。
- Environment: ジョブや API の実行環境
- Jobs: 実験の記録
- Pipelines: 処理をひとまとめにしたもの
- Data: Datastores 上のデータセット
- Models: ML モデル
- Endpoints: API もしくはバッチ推論
このアセットを組み合わせて様々な ML のプロセスを表現することができます。
AzureML v2
半年程前に AzureML の大規模なアップデートが行われました。大規模アップデート以前の AzureML を v1、以後を v2 と呼び、アセット単位で v1 と v2 に分かれ、2022年12月現在両者は併存しています。
併存していると言っても v2 は v1 との互換性がかなりの範囲で失われるほどの大規模な破壊的変更であり、例えば v1 で作られた Dataset アセットを v2 の Pipeline に渡すことはできませんし、v2 で作られた Data アセット (名称変更された) を使用して v1 の AutoML を実行することはできません。
アセットは名称変更、仕様変更、廃止、追加を経て整理され、それらを取り扱う CLI と SDK も v1 と v2 で互換性を失い、v2 向けの新たな CLI と SDK がリリースされました。
一例として Dataset は Data に変更された上で大幅に仕様が変わり、Experiment は Job に名称変更された上でより包括的な「実験」を管理する仕組みとして刷新され、推論 API 関連の機能は v2 向けの新たな仕組みが実装され強化されました。Kubernetes 統合機能も新たな仕組みが登場し、AKS のみならず任意の Kuberentes クラスターをアタッチして AzureML のジョブ実行基盤や推論 API ホスト基盤として利用できるようになりました。
AzureML v1 と v2 の大きな違いはいくつかありますが、アーキテクチャ上の大きな変更はリクエストを受ける口の変更です。v1 では AzureML Workspace がリクエストの受け口となっていましたが、v2 では Azure Resouce Manager が大半のリクエストを受け付けるようになりました。これにより、AzureML で行うあらゆる操作を RBAC で制御できるようになった他、CLI できることが大幅に拡充されました。
Azure Machine Learning CLI v2
2022年5月末に AzureML v2 が登場したタイミングで Azure Machine Learning CLI v2 も GA になりました。
従来の CLI v1 はできることがかなり限定的で、 AzureML の Azure リソースとしての側面を管理する機能に留まっていました。要するに、AzureML Workspace やコンピューティングリソースを作ったり消したり設定を変えたりできるだけで、AzureML Workspace 配下のアセットは (コンピューティング関係以外) 触れませんでした。
これに対し CLI v2 ではジョブの実行や推論 API のデプロイなど、AzureML のアセット操作が可能になりました。
CLI v2 のイケてるところ 1 : az コマンドとアセット操作の統合
CLI v2 は Azure CLI と統合され、az mlコマンドによって様々なアセット操作が可能になりました。
コマンドの形でアセット操作可能になったことで、AzureML はワークフローツールと組み合わせて使うことが容易になりました。すなわち、Github Actions や Azure Pipelines から簡単にアセット操作を実施できるようになり、CI/CD 的な操作を実装しやすくなりました。
認証周りもかなり楽になりました。
従来であれば SDK v1 で Python スクリプトでアセット管理のためのコードを書いた上で、スクリプト内からサービスプリンシパルなどを使用して認証を通す必要がありましたが、azコマンドと統合されたことでaz loginで済むようになりました。
Azure Pipelines であれば Service Connection というサービスプリンシパルをラップしたような機能によってシークレットのやり取りなしにaz loginによる認証を通すことができますし、Github Actions では OpenID Connect を使用してシークレットのやり取りなしにaz loginを通すことができます。
CLI v2 のイケてるところ 2 : yaml による静的定義
以下に示すジョブ実行の例のように、yaml 形式の設定ファイルに静的に実験設定を定義し、az ml コマンドでアセットの作成、削除、更新などの操作が可能になりました。
これにより、アセット操作の再現性確保が可能になりました。
az ml job create -f pipeline.yml
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: ../02_python_script
command: >-
python build_model.py --input_train_data ${{inputs.train_data}} --input_valid_data ${{inputs.valid_data}} --mode remote
environment:
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:20220504.v1
conda_file: ../environment.yml
inputs:
train_data:
type: uri_file
path: azureml:mlow-nyc-taxi-train@latest
valid_data:
type: uri_file
path: azureml:mlow-nyc-taxi-valid@latest
compute: azureml:cpu-cluster
experiment_name: mlow-nyc-taxi-regression-job
description: mlops workshop nyc taxi dataset regression
yaml の形でアセットの設定を保存できるようになったことで、Git との相性が大幅に向上しました。設定ファイルを Git の管理対象とすることでその変更履歴を追跡することはもちろんのこと、設定変更をトリガーとしてをアセット作成を再実行するようなことも可能になりました。IaC の ML バージョンです。
なお、yaml の設定をコマンド引数でオーバーライドすることができるので、動的な記述にもある程度は対応できます。しかし動的な操作を快適に行いたいなら、後述の SDK v2 がおすすめです。
CLI v2 まとめ
-
az mlコマンドでアセット操作が可能になって嬉しい- 認証楽になった
- Github Actions/Azure Pipelines と相性良くなった
- yaml で設定定義できるようになって嬉しい
- 再現性が高まった
- Git との相性が良くなった
Azure Machine Learning SDK v2
CLI v2 に遅れることおおよそ半年、2022年10月に Azure Machine Learning SDK v2 が GA になりました。
実装パターンが大幅に変更されて、Azure SDK と同様のものが採用された他、従来の SDK v1 が備えていた AzureML に実験のパラメーターやメトリックを記録するための機能がバッサリ削り取られました。
この2点の変更がダイレクトに SDK のイケてるところに繋がってきます。
SDK v2 のイケてるところ 1 : MLflow による実験記録
SDK v1 では以下のようなコードをスクリプトに差し込むことで AzureML に実験ログを送信できるようなっていましたが、SDK v2 ではこうしたことが一切できなくなっています。
run.log('alpha', alpha)
ではどうやって実験記録を取るのかというと、OSS の実験管理ツールである MLflow を使うようになりました。
実は以前から AzureML は MLflow Tracking Server として機能する互換エンドポイントを備えていて、SDK v1 の時代でも MLflow を使って実験記録を取ることが可能でした。
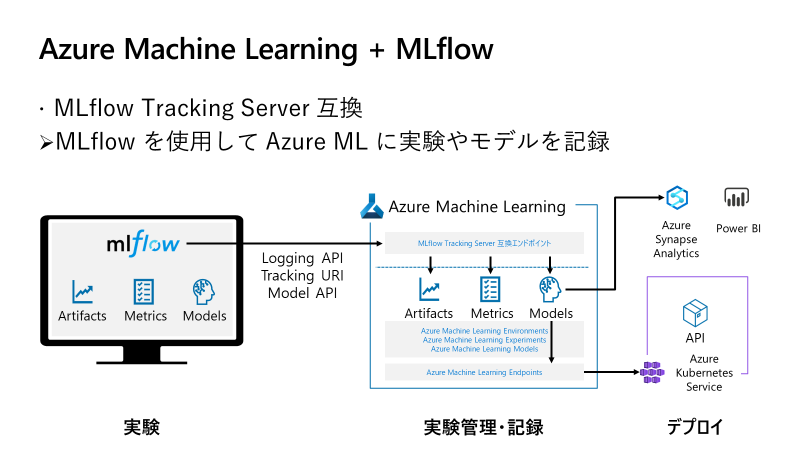
azureml-mlflowというパッケージを使用して MLflow に AzureML をサポートする補助機能を追加した上で、AzureML が発行する互換エンドポイントの URI を MLflow に渡すことで成立しています。
mlflow.set_tracking_uri(uri)
v2 では大胆にもこの互換エンドポイントの仕組み1本で実験記録を取ることにして、自前のログ機能を完全に捨て去りました。
クラウドベンダーの社員が何を言っているかと思われそうですが、SDK v1 が備えていたログ記録の仕組みは、僕個人としては実験のためのスクリプトをベンダー特有のコードで『汚染』することは避けたいと思っていたことと、インターフェースに統一感が欠けていて書き味が好みではなかったことの2点からあまり使っていませんでした。
代わりに推していたのが、比較的汎用性の高い OSS であり、インターフェースに統一感があって書きやすかった MLflow を使う方法です。こんな記事を書いたりお客様を支援する際にも MLflow を使う方法を推奨するくらいには MLflow 推しだった僕ですので、この変更を見たとき「開発よく分かってる……弊社開発マジ推せる……」とリモートワークしてる日本の部屋から海の向こうの北アメリカ大陸西海岸に居るであろう開発に向けて絶対聞こえない独り言を呟いてました。
参考までに、AzureML 上の Compute Cluster でジョブを実行する場合の、SDK v1 と MLflow のログを取るコードを以下に記載します。
run.log('alpha', alpha)
run.log('mse', mse)
run.log_image(name='plot', plot=plot)
run.log_list('accuracy', accuracy_list)
SDK v1 にはパラメーターを記録する関数はありません (少なくとも僕は知りません) が、ジョブ実行時の引数などは記録可能です。log関数を使ってメトリックを記録していき、画像などはそれ専用の関数を使います。Confusion matrix を記録する専門関数など、MLflow にはない関数もあります。
mlflow.log_params(param)
mlflow.log_image(image)
mlflow.log_metric('alpha', alpha)
mlflow.log_metrics(accuracy_dict)
MLflow では単数形の場合は key と value を引数に受付、複数形の場合は辞書を受け付けるようにできています。
ちなみに MLflow 統合はログ記録以外でもかなり進んでいて、例えば AzureML Model Registry では MLflow Models を受け付けるようになっており、モデルを登録するときにきちんとsignatureというモデルの入出力形式を定義する情報を与えておくことで、Managed Online Endpoint という ML の推論 API を提供する仕組みにクリック一発で推論 API をデプロイできるようになっています。本来であれば推論用にスクリプトを書く必要があるのですが、それが不要になります。
SDK v2 のイケてるところ 2 : Azure SDK と統一されたデザイン
かつての SDK v1 では、各アセット単位のクラスが存在し、そのクラス配下に操作用の関数が存在するという形式でした。
例えばジョブを実行する場合、関わるアセットのクラスからインスタンスを生成し、それらのインスタンスを最後にジョブ実行用の config クラスに渡して Experiment のsubmit関数に渡すという流れでした。
from azureml.core.workspace import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core.runconfig import DockerConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import ScriptRunConfig
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
ws = Workspace.from_config()
experiment_name = 'train-on-local'
exp = Experiment(workspace=ws, name=experiment_name)
myenv = Environment("myenv")
myenv.python.conda_dependencies = CondaDependencies.create(conda_packages=['scikit-learn', 'packaging'])
docker_config = DockerConfiguration(use_docker=True)
cpu_cluster_name = "cpu-cluster"
try:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2',
max_nodes=4)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
src = ScriptRunConfig(source_directory=project_folder,
script='train.py',
compute_target=cpu_cluster,
environment=myenv,
docker_runtime_config=docker_config)
run = exp.submit(src)
この流れが SDK v2 では以下のように変更されました。
from azure.ai.ml import MLClient
from azure.ai.ml import command
from azure.ai.ml import Input
from azure.identity import DefaultAzureCredential
ml_client = MLClient(
DefaultAzureCredential(),
"subscription_id",
"resource_group",
"workspace"
)
job = command(
code="./src", # local path where the code is stored
command="pip install -r requirements.txt && python main.py --iris-csv ${{inputs.iris_csv}} --epochs ${{inputs.epochs}} --lr ${{inputs.lr}}",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"epochs": 10,
"lr": 0.1,
},
environment="environment_name@latest",
compute="cpu-cluster",
display_name="pytorch-iris-example",
description="Train a neural network with PyTorch on the Iris dataset.",
)
returned_job = ml_client.create_or_update(job)
AzureML を操作するためのMLClientインスタンスを生成し、そのcreate_or_update関数にジョブなどのアセットに対応するクラスから作ったインスタンスを渡すことで実際の操作が非同期的に実行される仕組みです。(result()を末尾に付ければ同期的に実行できます)
この流れは操作する対象のアセットが何であっても不変で、行いたい操作によってどこから何をすれば良いのかが自明ではなかった (experiment に job 定義を submit することでジョブ実行することが直感的に理解できない) SDK v1 と比べて大きな改善でした。
このような操作の仕方は Azure SDK 全体で共通となっています。他社含め最近のバージョンの SDK だとこの実装パターンをよく見かけますが、これは Command デザインパターンということでいいんでしょうかね。
なお、各アセットに対応するクラスから作ったインスタンスを渡すこともできますが、既存のアセットであれば名前を指定するだけで事足ります。
SDK v2 で依存アセットを作ってもいいですが、CLI v2 と組み合わせて IaC 的に展開しておくという選択肢も現実的になりました。この方式の利点は、多分に動的な性質を持つジョブの実行と比較的静的な各種アセットの定義を分離して、それぞれ独立して操作できるところですね。
AzureML SDK v1 では独自だった認証の仕組みが Azure SDK 全体の汎用的な形 (DefaultAzureCredential()などを使う形) に改められている点も好評価です。
SDK v2 まとめ
- 実験記録が MLflow に一本化された
- OSS のコードで AzureML に限らない汎用性
- インターフェースがキレイ
- Azure SDK と同様のデザインパターンに統合された
- 操作が直感的になった
おわりに
AzureML v2 で登場した CLI v2 と SDK v2 のイケてるところを紹介しました。
静的なアセット定義とコマンドによる展開が可能になり Git とワークフローツールとの相性が良い CLI v2 に対し、ログ記録においては MLflow と役割分担しつつ Azure SDK と共通のデザインパターンを採用し動的にパラメーターが変動するような操作において無類の強さを発揮する SDK v2 ということで、同じような操作が可能であってもそれぞれ得意とする領域が異なっています。
MLOps を実現するためには静的動的問わず様々なアセット操作を自動化していく必要がありますが、CLI v2 と SDK v2 という性質が異なる2つの道具を手に入れたことで、Azure における MLOps 実装を進めることが現実的になりました。
Azure で機械学習を実行している皆様にはぜひこれらを活用して MLOps を進めて欲しいですし、Azure の使用を検討している皆様には今後の AzureML 採用のための検討材料に加えていただければ幸いです。
我々日本マイクロソフトの CSA-AI 有志で MLOps について以下のような資料を公開している他、社内でも MLOps を推進する様々な取り組みを進めています。今後とも Azure および Azure Machine Learning をよろしくお願いいたします。それでは少し早めですが、Merry Christmas!&良いお年を。