はじめに
こんにちは、イトーです。
「データ基盤が未整備だけどデータを CSV で貰って機械学習して、良い感じのモデルができた。本番投入どうしよう」というような状況の案件に支援に入ることが今年何度かありました。このような場合には運用を支える基盤が必要になるのですが、今のところデータレイクハウスと機械学習基盤の組み合わせから始めるとなかなか良いのではないかと思っており、~~今日はこの組み合わせで Azure 上にデータ処理基盤&機械学習基盤を実装してみようと思います。~~実装をしている時間がなくなってしまったので概念の説明だけしようと思いますすいません。
アーキテクチャ
データレイクハウス概要
データレイクハウスは、データ処理エンジンから直接アクセス可能な低コストなストレージを中心に据えたデータ管理アーキテクチャです。
「データ処理エンジンから直接アクセス可能な低コストなストレージ」は、技術的にはデータレイクとして使われるストレージとニアリーイコールであり、データレイクを中心に据えたアーキテクチャと言い換えることができます。
データウェアハウス→データレイク→データレイクハウスと進化してきた歴史とそれぞれのアーキテクチャ間の差異は、 Databricks から拝借した1以下画像によくまとまっています。
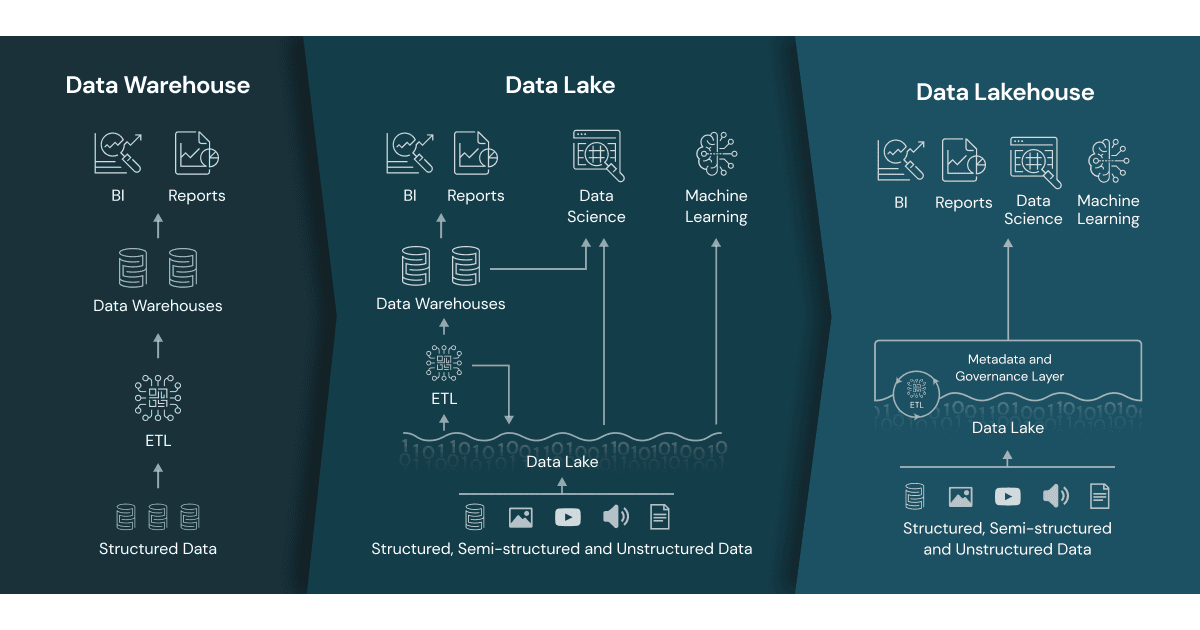
生データから加工済みのデータまで、全段階のデータを保持する役割をデータレイクが担います。データレイクアーキテクチャ時代までは加工済みのデータはデータウェアハウスに保管していましたが、データレイクハウスでは基本的に全てのデータを (主に parquet 形式で) データレイク上に配置します。(データレイクハウスの図にはデータウェアハウスがありませんが、BI ツールが発行するクエリの応答速度を改善するためにデータレイクと BI ツールの間に配置される等、要件次第ではデータウェアハウスを使うこともあります)
データレイク上のデータは、処理の度合いに応じて3つに分類・配置されます。これをメダリオンアーキテクチャと言います。
- Bronze : 未処理の生データ
- Silver : 最低限度の ETL 処理が行われた状態のデータ
- Gold : BI ツールで読み込んで可視化に供することができる水準まで処理されたデータ
データレイクハウスにおいては中心となるデータレイクの役割を担うストレージと、ストレージに対して ETL 処理を実行できるデータ処理エンジンが必要となります。
まとめると以下図のようになります。
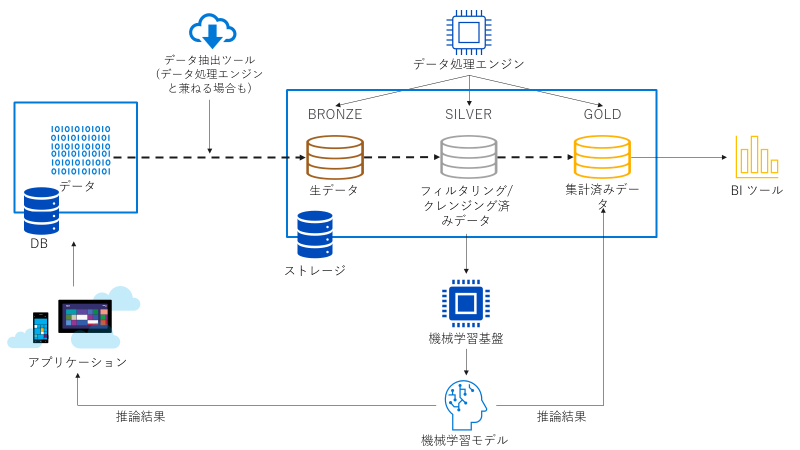
データ処理エンジンには増大していくデータに随時対応できるように、スケーラビリティを持つことが求められます。Azure においては以下の選択肢があります。
- Azure Synapse Analytics Serverless SQL Pool2
- Azure Synapse Analytics Apache Spark3
- Azure Databricks4
- Azure Data Factory5
- Azure Synapse Pipeline6
それぞれクエリの処理量に応じた課金か停止を含むオートスケールを前提とした時間課金かの差はありますが、基本的にデータの規模に応じて計算リソースのスケールを変更でき(または自動で変更され)、その結果としてデータの規模に応じて課金されるサービスとなります。
ストレージに求められる条件は非構造化データを格納できて安価であることに加え、上記のデータ処理エンジンからの操作を受け付けられることとなり、この時点で Azure におけるストレージの選択肢は事実的に Azure Data Lake Storage Gen2 のみとなります。
データレイクハウスという概念をどこが言い出したのか僕はよく分かっていないのですが、少なくともDatabricks がこの方向性を推していて、さらに Microsoft と Databricks が戦略的提携を結びファーストパーティサービスの Azure Databricks があったために Azure 上では早い段階からこの概念が実現されていたことは把握しています。また現在では AWS7 や GCP8 も追随しています。
Databricks から論文も出ているみたいです。興味がある方はどうぞ。
さて、ファイル形式、具体的には parquet 形式で全てのデータをデータレイクに配置するということは、以下の問題が生じるということを意味します。
- 行レベルの削除や更新が難しい (できなくはないが実質的にデータを再書き出しすることになる)
- ACID トランザクションができず、整合性問題が生じる
- 表形式データであってもスキーマを定義できない
- 性能が出ない
こうした問題を解決するために、Databricks では Delta Lake9 と呼ばれる parquet ベースで互換性を維持しつつ拡張する仕組みを開発して OSS として公開しており、既に Databricks 以外にも様々なサービスが対応を始めています。現状上記問題に対応できる Delta Lake 以外の選択肢となると、Snowflake のようにデータレイクハウスそのものをラップしたような構造を持つ大きなサービスを使うことになるかと思います。しかし全てを包括するサービスを採用するとよりシームレスな UX と引き換えにデータレイクハウスの利点の1つである技術選択の柔軟さを喪失することにつながるため、選定にあたっては組織が要求する要件との兼ね合いを考える必要がありそうです。
データレイクハウスに注目している理由
「機械学習を起点に先に進もうとしている状況」においては、スケーラブルである点が何より重要と考えています。
機械学習をするにはそれなりにちゃんとした状態のデータが必要です。メダリオンアーキテクチャで言うところの Silver 以上の水準が欲しいところです。機械学習を始める以前よりデータを取り扱う専任のチームの手により既にデータ基盤が整備されているならば話は非常に簡単ですが、現実は往々にしてそうではありません。データ基盤が無いならばデータを毎回手動で貰って来るというような運用方法になりますが、ML プロジェクトの規模が PoC レベルや小規模なうちは何とかなってもちょっと規模が大きくなってくるとすぐに破綻します。故に ML のスケーラビリティのためにはデータ基盤が必須であろうと考えています。
しかし「ML 基盤を整備したいけどまずはデータ基盤なんとかしないと」というような段階で大きな予算がつくことはあり得ません。従来からあるデータレイクアーキテクチャで ETL したデータを保存する先であるデータウェアハウス部分は特にコストがかかるところで、予算が付いていない段階での構築は非常に困難です。そういうときに、データを処理する部分のコストが規模に応じた課金で、定常的にかかる費用はブロックストレージのコストぐらいというデータレイクハウスアーキテクチャが輝きます。上にも下にもスケーラブルなので、スモールスタートして徐々に拡張していくことが可能です。
世の中価値をちゃんと示せていないものにはお金がつきにくいのにお金がないと価値を生みにくいわけで、そのジレンマに対する現実的な答えがスモールスタートなんですね。
他にも構造化データと非構造化データに対する統一的な方法でのアクセスを実現できることとか、処理済みデータへのアクセスにあたって必ずしも SQL が必要ではなくなるので Python スキルしか無い状況でも取っつきやすいこととか、計算リソースとストレージが分離されるためにスケーラビリティが確保できる上に技術選定がより自由になることとか、色々利点があります。
一番の理由として「スモールスタートを可能にするスケーラビリティ」を挙げましたが、「技術選定の自由度」も要件によっては非常に重要な利点となる特徴です。Azure の場合、 Python もしくは Scala で頑張りたいなら Synapse Spark か Databricks 、SQL で頑張りたいなら Synapse Serverless SQL か Databricks、コード書きたくないなら Data Factory か Synapse Pipeline といった具合に自由に使用するデータ処理エンジンを選べる上に、計算リソースとストレージが分離されているが故にデータ処理エンジンは何個あっても良いので、例えば SQL が得意な人は Synapse Serverless SQL を使い、Spark の知見がある人は Databricks を使うといった形で併用することも可能です。今後、例えば Golang が SQL や Python (PySpark) の立ち位置を脅かしてデータ処理言語の覇権を握る日が来たら Golang で処理するエンジンに切り替えることもできます。もちろん管理のポリシーとか開発方針(パイプラインのメンテのめんどくささと分散化はどの程度許容できるのかとか)との兼ね合いは考えておかないといけません。
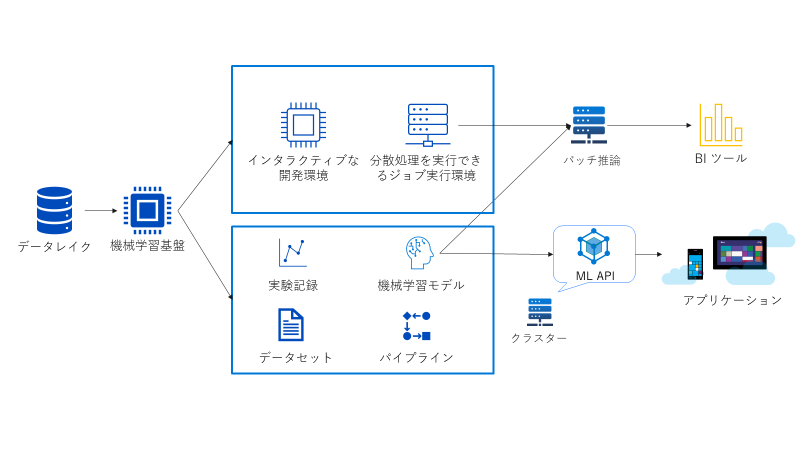
機械学習基盤
将来 MLOps を実現していくためのコアとなる機械学習実行基盤ですが、欲しい機能はざっくり以下4つです。
- インタラクティブに機械学習モデルの開発と実験を行えること
- ジョブとして分散環境で大規模な機械学習を実行できること
- パイプラインを定義して、学習の再実行を容易に行えること
- 実験の管理ができること
OSS ならば Kubeflow とか MLflow とか色々ツールがあるので、それらを要件に応じて組み合わせて使用することになります。
Azure においては Azure Machine Learning か Azure Databricks となります。両サービスとも ML 基盤に求める4つの条件の全てを満たしていますが、Azure Databricks が Azure Databricks 単体で完結するサービスを志向している一方、Azure Machine Learning は単体で完結させることもできるし必要に応じて外から呼び出して一部だけ使うこともできるようなサービスとなっています。すなわち Azure Machine Learning を選んだ場合は Azure Databricks を後から追加して連携動作 (パイプラインへの Databricks ノートブックの組み込みや Azure ML への実験記録) させることが可能ですが、逆は少々面倒です。
データレイクハウスでストレージと計算リソースを分離したことによって任意のデータ処理サービスを利用できるようになったことと同様に、 Azure Machine Learning に実験記録・モデル・データセット・パイプラインといったアセットの管理 (ストレージ的要素) を担わせ、計算処理や開発については用途に合わせて Azure Databricks やそれ以外の様々な計算リソースに任せる方向性を探っています。こうすることで、今後より優れた機械学習の処理基盤が現れた場合に速やかにシステムに取り込むことができることを期待しています。
関連して以下のような記事を今年度アドベントカレンダーで書きました。
参考までに Azure Machine Learning の構成は以下の通りです。
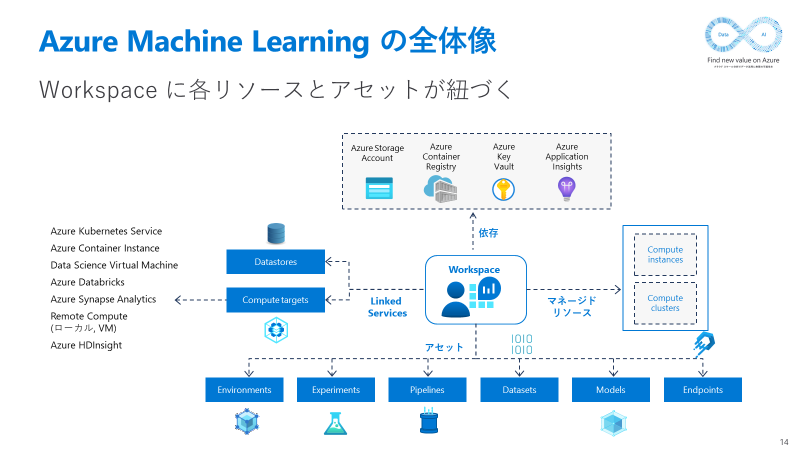
アーキテクチャのまとめ
データレイクハウスアーキテクチャ
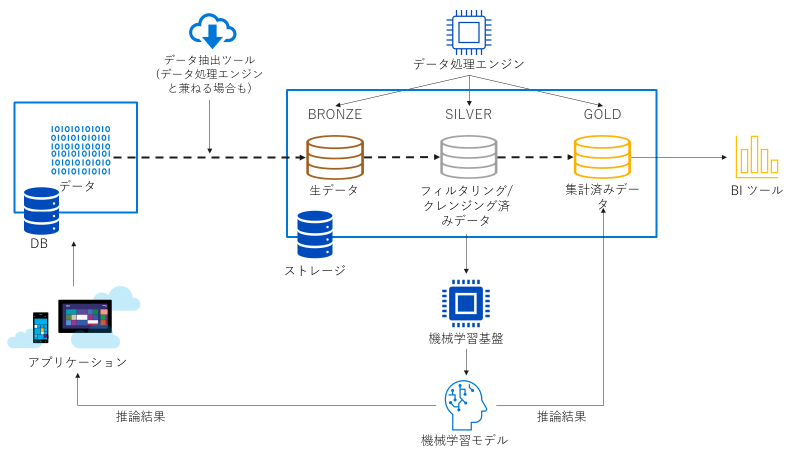
Azure で実現する場合、以下のようにコンポーネントを選択します。
ストレージ
- Azure Data Lake Storage Gen2
データ抽出ツール
- Azure Data Factory
- Azure Synapse Pipelines
オンプレミスとの接続要件がある場合は Data Factory の方が向きます。
データ処理ツール
- Azure Synapse Analytics Serverless SQL Pool
- Azure Synapse Analytics Apache Spark
- Azure Databricks
- Azure Data Factory
- Azure Synapse Pipeline
SQL を使う場合 Serverless SQL Pool か Databricks、Spark (Python, Scala) を使いたい場合 Synapse Spark か Databricks、ノーコードで済ませたい場合は Data Factory か Synapse Pipleine となります。
データ処理ツール側で Delta Lake を利用することで整合性の確保やパフォーマンス向上が見込め、複数のデータ処理ツールを用途に応じて併用するようなシステム構成も現実的になります。
機械学習基盤
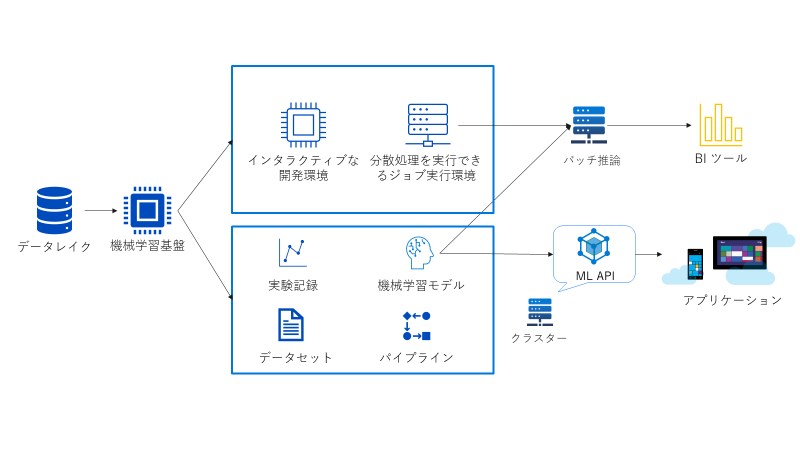
Azure においては選択肢は2つあります。
Azure Machine Learning
機械学習基盤として Azure Machine Learning を選択した場合、計算リソースとしては Azure Machine Learning 管理下のコンピューティングインスタンスやクラスターを使って Azure Machine Learning のみで完結させることも可能ですが、Azure Databricks や Azure Arc によって Azure Machine Learning のジョブを受け入れるように設定された Kubernetes 等、幅広い計算リソースと併用利用することも可能になります。計算リソースを使う目的に合わせ、最適な環境を選択することができます。
Azure Databricks
機械学習基盤として Azure Databricks を選択した場合、一連の作業を全て Azure Databricks で完結させることが可能です。基本的に Azure Databricks の Spark クラスター上で動作するノートブック環境でインタラクティブな開発もジョブ実行もこなすことになります。データレイクハウスのデータ処理エンジンとして Azure Databricks を選択している場合は、データ処理から機械学習まで同一の基盤上で切れ目なく実行することも可能となります。
別の計算リソースと連携動作する余地はあまり大きくありませんが、統合されているマネージド MLflow を外部から呼び出して実験記録やモデルの登録を行うことはできるので、例えば開発環境としてのローカルと本番環境としての Azure Databricks といった分離は可能です。
おわりに
機械学習の本番運用を考え始めると、データ基盤と機械学習基盤が必要になってきます。本記事ではデータ基盤にデータレイクハウスアーキテクチャを採用する利点と、Azure 上で実現する場合に使用できるサービスを説明するとともに、機械学習基盤として使用できる2つのサービスとその特徴を説明しました。
全体として、 Azure 上でデータ基盤及び機械学習基盤をスモールスタートで作る場合の抽象的な枠組みを整理できたかなと思います。
今回示した枠組みの中でも組み合わせは色々とあります。
- データ部分は Synapse Pipelines のみ、機械学習部分は Azure Machine Learning のみ使う
- データから機械学習まで全て Azure Databricks を使う
- パイプライン管理をデータ部分は Azure Data Factory、機械学習部分は Azure Machine Learning に任せ、全領域にまたがる計算リソースとして Databricks を使う
- データ部分は Synapse Pipelines + Synapse Spark、機械学習部分は基本的には Azure Machine Learning を使い、状況に応じて計算リソースとして Azure Databricks を使う
- ...etc.
それぞれどのサービスが適しているか否かは要件次第となるので、ここが基盤を担当するエンジニアの腕の見せ所になりそうです。
来年はここまでの枠組みに MLOps も併せて深堀して、より具体的なアーキテクチャに落とし込んでいきたいと思います。
それでは皆様、よいお年を。
-
https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql/on-demand-workspace-overview ↩
-
https://docs.microsoft.com/ja-jp/azure/synapse-analytics/spark/apache-spark-overview ↩
-
https://docs.microsoft.com/ja-jp/azure/databricks/scenarios/what-is-azure-databricks ↩
-
https://docs.microsoft.com/ja-jp/azure/data-factory/introduction ↩
-
https://docs.microsoft.com/ja-jp/azure/data-factory/concepts-pipelines-activities?context=/azure/synapse-analytics/context/context&tabs=synapse-analytics ↩
-
https://aws.amazon.com/jp/big-data/datalakes-and-analytics/data-lake-house/ ↩
-
https://cloud.google.com/blog/ja/products/data-analytics/open-data-lakehouse-on-google-cloud ↩