動画コンペ小テク集
手術支援AIのJmeesという会社でリサーチエンジニアをしている菊地です。
医用画像処理及びコンピュータ支援外科分野の国際学会であるMICCAIにおいて開かれている内視鏡映像を題材とした学会コンペシリーズであるEndoscopic Vision Challenge Cluster (EndoVis) に2024, 2025年度と2年連続で出場する中で得られた、動画コンペに関しての知見を共有します。こちらはKaggle Advent Calendar 2025 の15日目の記事です。

本記事では以下を紹介します。
- 動画コンペの形式、タスクなどについて
- 基本的なアプローチ、モデルについて
- 取り組むにあたり覚えておくと便利な小テク
1. 動画コンペとは
動画像を用いたコンペはメダル付きのKaggleコンペではあまり多くは見られないものの、学会コンペ等においては近年見られるようになってきた題材です。
例としてここ数年毎年開かれているものを挙げると
AI City Challenge - 室内映像における複数カメラを用いたトラッキング、道路での映像を用いた安全性に関するVQAなど様々なタスクを取り上げているICCVの学会コンペ。
Ego4D Challenge - 1人称視点映像のデータセットであるEgo4D, それに第三者視点映像を加えたEgoExo4Dを用いてエピソード抽出やbody pose推定など様々なタスクを解くCVPRの学会コンペ。
EndoVISも2015年から始まり、2017年以降は毎年開かれているコンペです。
Kaggleだと動画を扱う有名なコンペといえばNFLコンペですね。スポーツの固定視点映像は記事公開時点で開催中の#22 CA x atmaCup 3rd でも扱われているように、動画コンペとしては代表的な題材です。
代表的なタスク
タスクとしてよくあるのは、まず画像でよくあるタスクの動画への拡張です。これは
- 分類/回帰
- セグメンテーション
- 動画生成
- VQA
などが挙げられます。
分類については動画そのものの分類とフェーズ分類(工程分類)のような動画内の各フレームの分類の2種類を考えることができますが、その辺は一旦置いておきましょう。
動画ならではのタスクとしては
- 点/物体トラッキング
- オプティカルフロー
- 3D再構成/自己位置推定
- アクション検出
などがあります。
こう見ると、動画ならではのタスクには”動き”に焦点を当てているという共通点があります。動画は一見、画像を時系列方向に並べているデータであり、3Dスキャンと同じようなデータのように見えます。実際3DCNNは動画でも結構働いてくれます。しかし、動画タスクを考える際には時に動き自体に焦点を当てていくことも必要になります。
動きってなんだ
動きについて更に掘り下げると、動画内に現れる動きはさらにLocal motionとGlobal Motionの2つに分けることができます。Local motionは画面内に映っている物体の動き、例えば人や車の動きです。Global motionは映像を撮る際にカメラ自身が動くことによって発生する画面全体の動きです。

上の場合、人形くんの動きはlocal motionです。対して、背景の家屋の動きはカメラの動きによるGlobal motionです。
例えば、固定視点の動画ではカメラが動かないのでGlobal motionが映像に現れることがありません。よって、Local motionを検出するだけで動画内でどこに注目するべきなのかおおよそ見当をつけることができたり、トラッキングなどで得られた速度のような情報を高い信頼度で扱うことができます。
自己位置推定はGlobal Motionのみを抽出するタスクなので、local motionの激しい領域が事前にわかると嬉しいです。逆に、local motionの激しい動画では3D再構成や自己位置推定がうまくいかないことがあります。

上は手術動画データセットのCholec80の動画(video01.mp4の先頭1000フレーム)をSLAM3Rで3D再構成させてみた様子です。
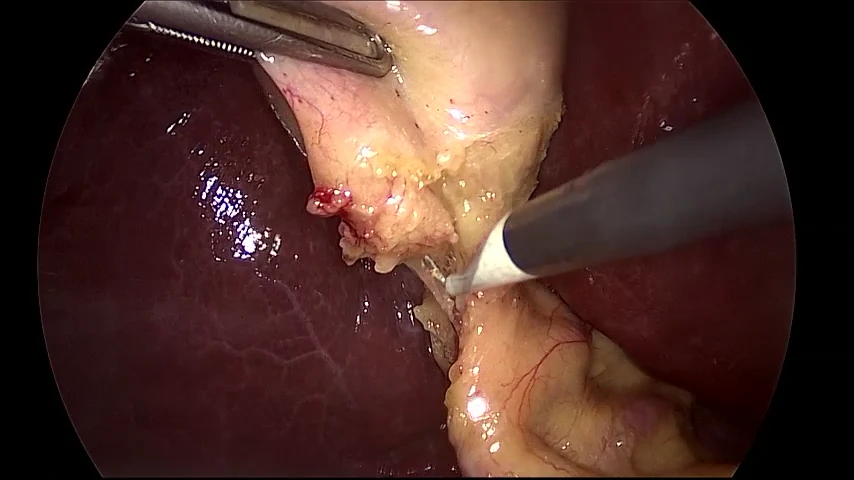
動画を見ると分かるのですが、動画内では手術に用いる器具が臓器とは独立した動きをし、臓器は臓器でdeformativeに動く上に、さらには内視鏡カメラの種類が円形の黒枠内に映像を与えるなどの理由で、このようなことになってしまいます。(ちなみにprivateのデータセットで黒枠のない手術映像を試しましたが、同じようになりました。)
2. モデル
動画コンペでよく使うモデルを見ていきましょう。
画像encoder
動画コンペとは言いましたが、現実には動画の各フレームに画像モデルを適用するだけで十分な性能が出ちゃったりします。特に、セグメンテーションと工程分類についてはその傾向が顕著です。実務でも推論速度と性能での天秤で画像モデルに軍配が上がるシーンの方が多そうです。
2.5Dアプローチも動画ではよく使います。ConvNeXtとかResNetとかタスクに合わせていい感じのやつ使えばOKです。2.5Dモデルについてはこちらを参考にするのが良いです。
動画encoder
動画自体の分類など、動画全体の理解が重要なタスクでは2.5Dモデルより3Dモデルの方が強いこともあります。
-
3DCNN
タスクによっては普通に強いです。動画長の問題や、他の実験条件が重要そうなコンペでは未だにシンプルな3D CNNが優勝していくことがあります。(例. EndoVis24 OSS Challenge) -
Swin3D
名前の通りSwinTransformerの3D版です。torchvisionに学習済みモデルごと置いてあって(torchvision.models.video.swin3d_b)、使いやすいのでよく使います。 -
TimeSFormer
transformersにおいてあって使いやすいです。信頼のfacebook research…なのですが個人的にはあまり良い印象はないです。
以下2つはアプローチっぽい話ですが…
-
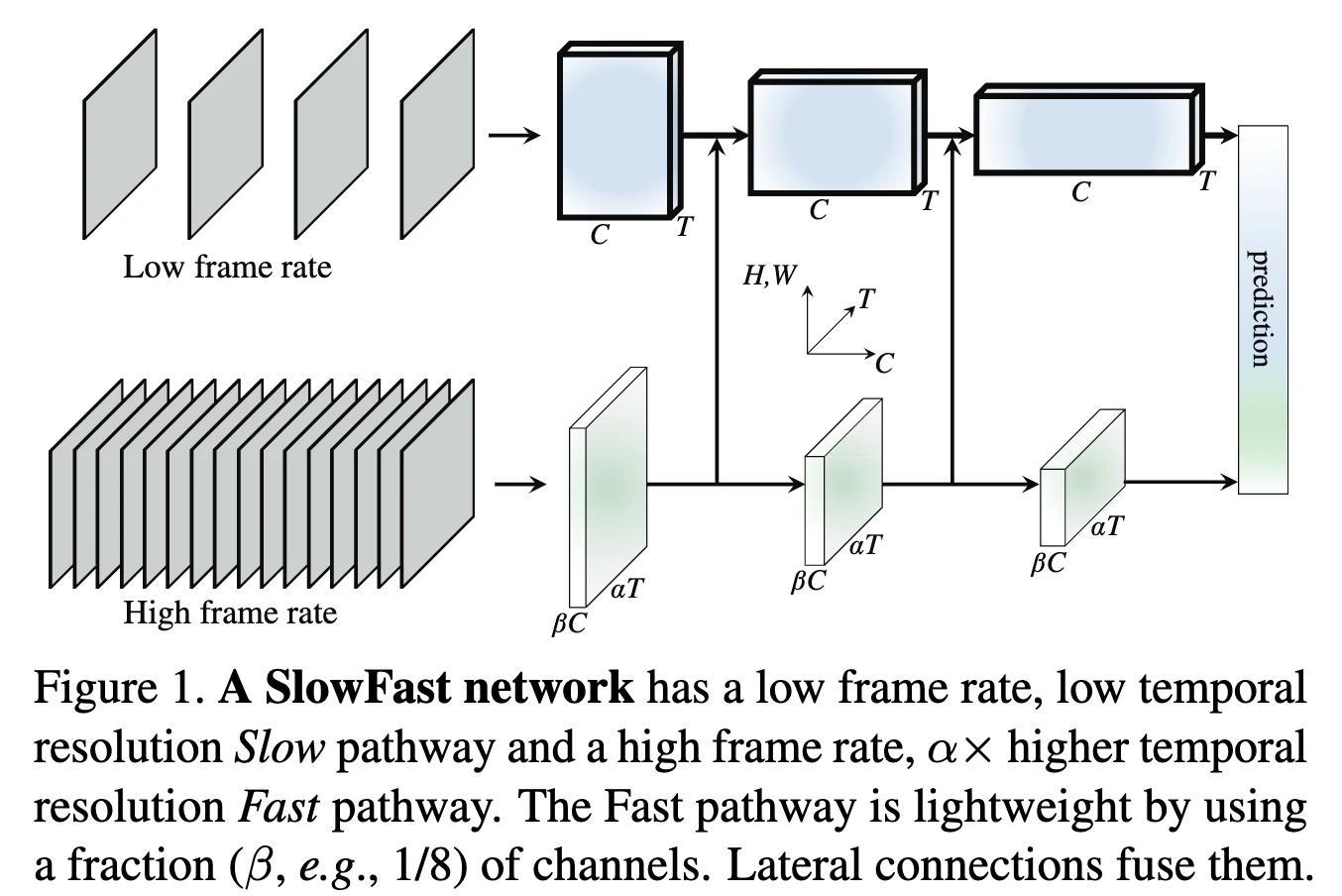
SlowFast
疎なフレームサンプリングと密なフレームサンプリングで画像と動きを別々に捉えようというアプローチです。
-
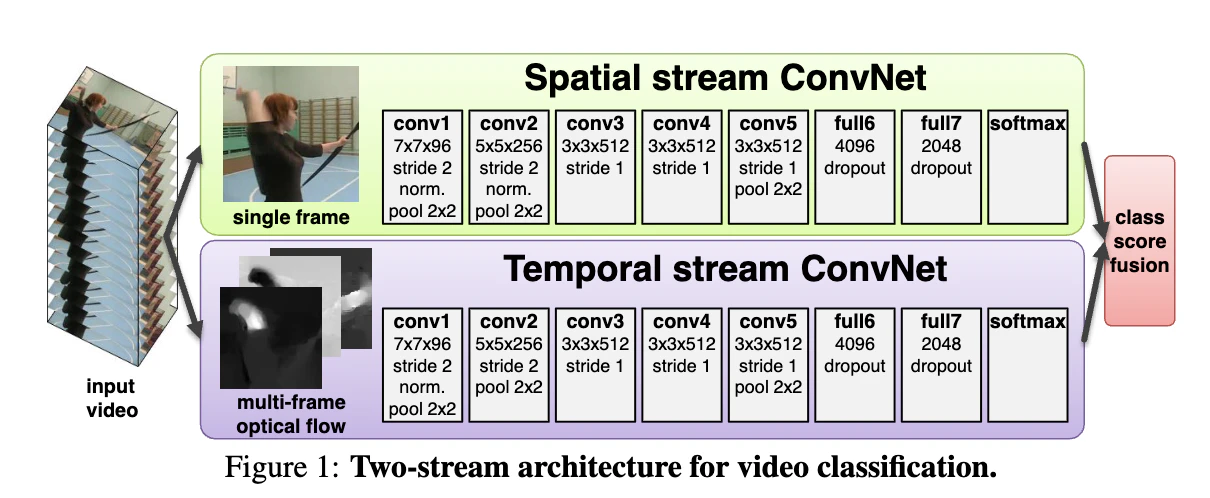
Two-stream
画像に加えてoptical flowからの特徴量抽出によって動き情報を捉えようというアプローチです。提案が2014年と古いですが、motionを捉えるという意味ではかなり本質を突いてるのではないかと思います。
optical flowのRGB画像へのモデル内での混ぜ合わせについてはこちらでも触れられています。
動画へのアプローチの考え方については古い資料ですがこちらがよくまとめられていると思います。
Optical Flow(フロー推定)
Optical Flowは大別して2種類に分けることができます。sparse型は画像の特徴点に絞って解析するものです。dense型は画像の各画素に対してフローを推定します。困ったらdense使えば良いです。sparseは大まかにカメラの動きを知りたい時とかでなら使うか...?
-
Lucas-Kanade (sparse型)
- openCVでは
cv2.calcOpticalFlowPyrLK(old_gray, curr_gray, points)から使えます。
- openCVでは
-
Gunner-Farneback(dense型)
- OpecCVでは
cv2.calcOpticalFlowFarneback(prev_frame, curr_frame)から使えます。
- OpecCVでは
-
RAFT
最近のDense Optical Flowではよく使われるモデルです。実際性能もかなり安定している印象があります。torchvisionにモデルが置いてあるので簡単に使えます。(torchvision.models.optical_flow.raft_large)

- Pytorch Ligntning Optical Flow (PTLFlow)
様々なflow推定モデルを簡単に使えるライブラリです。上に挙げたRAFTもいます。ドキュメントの方にはベンチマークも置いてあってありがたいです。
動画コンペはデータが少なくないか…?みたいなことがよくあります。そもそも動画は重いのでデータ共有が大変ですし、長動画ではアノテーションコストも高いのでラベルや補助ラベルが疎になりがちです。そこで、特徴量抽出や擬似ラベル生成のために外部データでの学習済みモデルを使います。
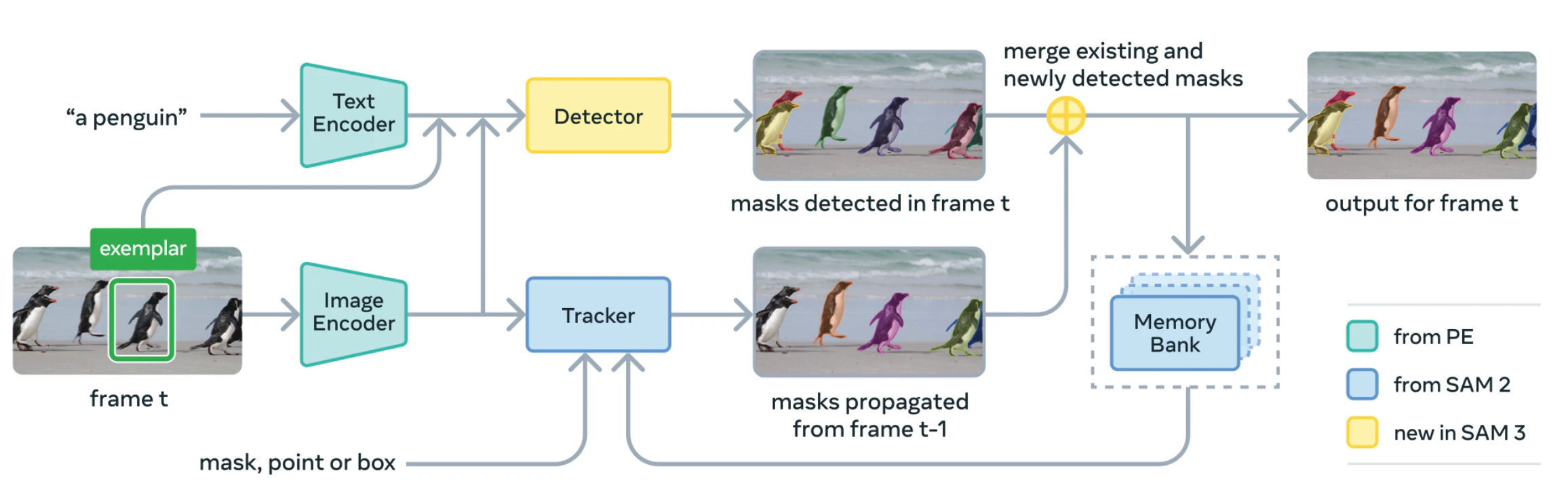
SAM2 / SAM3
セグメンテーションにおいて様々な使い方ができる汎用モデルです。プロンプト(mask, bbox, ポイントによるmask自動生成、テキストによるマスク自動生成)により画像に対するセグメンテーションを行い、それを動画上で前後に伝搬することができます。
代表的な使い方は学習用の擬似ラベル生成です。動画コンペでは動画の全フレームに対してアノテーションが与えられることは稀です。そこで、動画全体の中で一部のフレームにしか与えられないセグメンテーションマスクやbboxをプロンプトとして与え、動画全体に伝搬して全フレームの擬似ラベルを生成することができます。
SAM3ではテキスト to セグメンテーションができるようになったので、そもそもsegmentationラベルが与えられていない状態から擬似ラベルが生成可能でアツいです、コンペでも使ってみたい。
Point tracking
SAM3とも似ていますが、こちらはマスクではなく点のトラッキングに重点を置いています。key point検出の擬似ラベル生成に使う他、時系列で長く密な情報を必要とする(スキル評価など、オブジェクトの繊細な動きが分類タスクで重要な場合など)際には特徴量抽出にも使えます。
online推論でも十分強いですが、Offline推論がかなり強いです。実はtorch-hubから呼び出せて使いやすいのもポイント高いです。
torch.hub.load("facebookresearch/co-tracker", "cotracker3_offline")

あまり有名ではないようですが、こちらも安定して強いモデルです。online推論ではこちらも一考の余地があるように思います。

Depth Anything V3
今年出てきた深度推定モデルです。V3になってDepth推定以外にカメラpose推定、更には3D Gaussian Splattingの生成さえ出来るようになってしまいました。
深度情報も補助ラベルとして非常に強力です。理由としては動画から得られるvariationの少ない画像データを学習する際に良い正則化として機能することが考えられます。少データで画像情報が重要なタスクではよく使えそう。また、深度は3D空間での位置を意識させるためにシンプルに強力であることも考え得る原因です。
VGGT
複数画像から3D再構成を行うモデルです。CVPR 2025のBest Paper Awardを獲っています。
今年度のImage matching Challengeの上位解法のいくつかでは最終的に使用しない方向性になったものの、考察としてVGGTへ言及している方が多数見られました。vSLAM等の動画からの3D再構成/自己位置推定やGaussina Splattingといった新規視点からのビュー生成等は、カメラの移動が激しい動画の理解において今後非常に重要な役割を果たしていくと思われますが、コンペで使うには依然計算コストの高さや激しいlocal motionへの対応、そもそもGSを空間の情報としてモデルでどのように扱うかなど、中々ハードルの高さを感じます…でも使いこなせたらすごく強そう。
VLM (Vision-Language Model)
動画のVLMは筆者が触れたことがないため深く触れることができないのですが、Twitter見てると最近はQwen3-VLが強そう...?動画VLMについてはKaggle Advent Calendar 3日目の2COOLコンペ解法レポートの記事で詳しく解説されているので、こちらを参考にされるのが良いかと思われます。
3. 本題: 小テク
さて、上で既にpseudo-labelなどの小テク(?)にもあっさり触れてしまいましたが、残りの小テクについてもバラバラに紹介していきます。
実験効率化
-
EDAは動画で
極力EDAは画像ではなく動画で確認しましょう。動画でないと気付けないことが結構あります。例えば、どのような場合に推論がうまく行く/行かないを知りたいときに、動画では複数の推論結果を一度に比較することが可能ですし、動画の動きに推論結果が依存している際には画像単体で推論結果を比較するのは困難です。
VSCodeやCursorでは拡張機能でビデオのプレビューが可能です。videoファイルを右クリック, Open With…を選択 → 画面上部でVideo Previewを選択、で動画ファイルが再生できます。
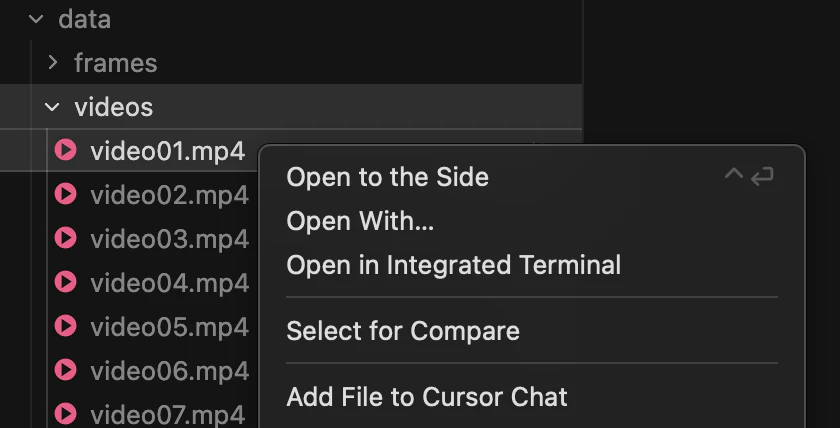
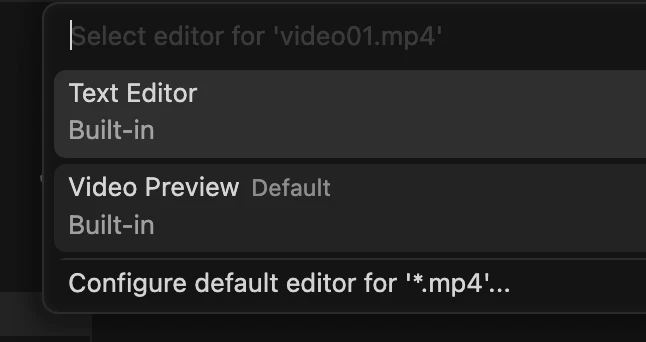
動画が長い場合や一部の拡張子, コーデックではプレビュー機能が使えないことがあります。この場合はローカルの動画プレイヤーや、サーバーの場合はリモートデスクトップ上で再生するのもおすすめです。
-
Datasetの高速化
- 動画ファイルは画像ファイルにバラそう
- segmentation mask、optical flowについても同様に事前に保存しよう
動画ファイルの画像展開にはffmpegが高速でおすすめです。使い方は以下の通りです:
ffmpeg -i input_video.mp4 -vf "fps=30,scale=-vf scale=640:-1" %05d.jpg-vf fps=30では書き出しフレームを30フレーム毎にしています。scale=640:-1では幅640, 縦はアスペクト比維持の画像にresizeして書き出します。
実際にdatasetの速度を比較してみましょう。今回は先程も用いた手術動画データセットとして有名なCholec80から10の動画を抽出して使いました。画質はfull HDでresizeなし、画像保存はjpg、読み込みには画像はOpenCVとPIL, 動画はOpenCVとPyAVを用います。n_worker=4、画像は224, 224へlodaer内でresizeさせています。作成される入力の形状は(B=1or8, C=3, H,W)です。Loaderでのrandomの有無でも条件分けします。さらに動画モデルへの複数batch入力を想定して(B=8, T=8, C=3, H,W)の入力を作るlodaerについても検証します。1秒間に回せるbatchの数を計測します。
| B=1 | B=8 | B=1 random |
B=8 random |
B=8 random 8 frames seq |
|
|---|---|---|---|---|---|
| cv2.imread | 139 | 74 | 108 | 60 | 14 |
| Image.open | 117 | 36 | 88 | 34 | 5.6 |
| torchvision.io.read_image | 109 | 32 | 92 | 41 | 7.1 |
| cv2.VideoCapture | 32 | 3.2 | 19 | 3.1 | 2.5 |
| av.open | 35 | 5.5 | 20 | 3.8 | 2.8 |
| torchvision.io.read_video | 11 | 0.63 | 4.8 | 0.63 | 0.57 |
結果はこのようになりました。いずれのケースにおいても動画から最速で読み込む場合より画像から読み込む場合の最悪のケース方が2~9倍速く読み込むことができています。
動画コンペにおいてこれはかなりの差です。動画コンペにおけるモデルの学習時間は長い動画においては1日以上かかるケースも珍しくありません。1日1実験ならまだしも1週間で1実験は中々厳しい…
同様、segmentation, optical flowなどの補助ラベルについても先に書き出しておくのがおすすめです。segmentationは1ch、optical flowは2chを使うように保存すれば1画像で保存できます。
ホモグラフィー変換による投影
動画コンペの中には複数視点からの映像を扱うものもあります。その際は同じ画面への射影変換を行うと2映像の対応がしやすくなります。
また、NFLコンペや他の固定視点スポーツ映像コンペのように位置や速度等が重要な情報となるとき、動画の画面そのままで扱うよりもBEV (Bird Eye View, 上空からの俯瞰図)でこれらを扱う方が良い場合があり、このような場合にも変換が必要です。
OpenCVではSIFTによる特徴点検出、matcherによる特徴点マッチング、cv2.findHomographyでホモグラフィー行列の推定、cv2.warpperspectiveで射影変換までを行うことができます。
ALIKED+LightGlueなど深層学習手法を用いてtorchで全てを行いたい場合はkorniaを使うのが便利です。kornia.geometryにhomographyを扱う関数があります。(余談ですが、RANSACについてはOpenCVの実装の方が高速だったり、korniaは他にも自分で実装した方が速い関数がたま〜にあるようです。。)
特徴量エンジニアリング
連続フレームの特性を活かした特徴量抽出として以下を紹介します。映像はこちらを使いました。
- 前景抽出: 固定視点映像でのみ、背景を除いた前景部の抽出が可能です。
cap = cv2.VideoCapture("1920x1080.avi")
fgbg = cv2.createBackgroundSubtractorMOG2()
while True:
ret, frame = cap.read()
if not ret:
break
fgmask = fgbg.apply(frame)
fgmask = cv2.cvtColor(fgmask, cv2.COLOR_GRAY2BGR)


- 動物体の輪郭抽出: こちらは視点が固定でなくても使えます。
cap = cv2.VideoCapture("1920x1080.avi")
while True:
ret, curr_frame = cap.read()
if not ret:
break
if prev_frame is None:
prev_frame = curr_frame
continue
contours = cv2.absdiff(prev_frame, curr_frame)

- Optical Flowからマスク検出
# せっかくなので上で紹介したPTLFlowを使いましょう
import ptlflow
from ptlflow.utils import flow_utils
from ptlflow.utils.io_adapter import IOAdapter
cap = cv2.VideoCapture("1920x1080.avi")
frame_size = (960, 540) # 高速化のため
model = ptlflow.get_model('raft', ckpt_path='things').to(device)
io_adapter = IOAdapter(model, frame_size)
prev_frame = None
while True:
ret, frame = cap.read()
if not ret:
break
frame = cv2.resize(frame, frame_size)
if prev_frame is None:
prev_frame = frame
continue
inputs = io_adapter.prepare_inputs([prev_frame, frame])
inputs['images'] = inputs['images'].to(device)
preds = model(inputs)
flows = preds['flows'].detach().cpu() # (B, 1, 2, H, W)
flows = flows[0, 0].permute(1, 2, 0).numpy() # (H, W, 2)
flow_magnitude = np.sqrt(flows[:, :, 0]**2 + flows[:, :, 1]**2)
threshold = flow_magnitude.mean() + 2 * flow_magnitude.std()
mask = (flow_magnitude > threshold).astype('uint8') * 255
mask = cv2.cvtColor(mask, cv2.COLOR_GRAY2BGR)
prev_frame = frame

もう少し頑張ればflowの大きさと向きに対してクラスタリングを使ってinstance分離などもできそうですね。
推論高速化
動画コンペではリアルタイム性を重視して推論速度に制限を設けたり、実務への応用を意識して推論環境に強めの制限がかかることがあります。
極端な例だと、NVIDIA Holoscanという独自プラットフォーム上で動かせる、SDKを用いてほぼそのまま実務応用ができる形でのアプリケーション提出を求められるタスクを見たことがあります。このタスクでは最終的にHoloscanで提出まで漕ぎ着けたチームは1チームに留まり、そのチームが優勝、という珍事がありました (EndoVis 2024 STIR challenge- 2D Latency task)。主催も反省したのか翌年には制限が撤廃されていました。
上は流石に極端なケースですが、推論時間制限下では以下について最低限知っておくと良いと思います。
-
model.eval, torch.inference_mode, torch.compile
model.evalはevalモードの指定、inference_modeはgradientのセットを無くします。torch.compileはモデルを1行追加で簡単にコンパイルできます。推論時に使う高速化としては常套手段ですがこれだけで大分速くなるので侮れないです。 -
ONNX
ONNXは機械学習モデルを異なるフレームワーク間で共有・移行するための標準フォーマットです。C++でモデルを扱ったり、ONNX-simplifierによりモデルを最適化したり、ONNX runtimeのような高速推論エンジンを使えるようになります。量子化もできます。CPU推論縛りのタスクで解法に用いた事がありますが、案外簡単に使えてよかったです。(MICCAI25 SAGES CVS challenge TaskB)
高速化は奥が深くここでは説明しきれないので、代わりに非常に参考になる記事/資料を紹介させていただきます。
4. 終わりに
小テクと言いつつ動画認識タスクについて全体を見渡すような記事になってしまった感がありますね…あとはたくさんの良記事があったのでそちらにより詳しい説明を任せがちになってしまいました。いつも学びのある記事をありがとうございます。
今年はSora2などの動画生成モデルが世間で流行った上に、上にも挙げたVGGT、SAM3、DA3といった多数の動画を扱うモデルが公開され、話題となりました。動画を扱って解けるタスクがどんどん増えていく中でこれから動画を用いたコンペはさらに増えていくのではないかと予想しています。
また”動画認識”は”画像認識”くらい広い括りで、roboticsにおける動画理解や点群、VLMなど私はまだ追いきれてない話もたくさんあるので勉強していきたいなと思いました。補足事項などがありましたら共有頂けると幸いです。
株式会社Jmeesは2021年から毎年MICCAI EndoVis Challengeに参加し、累計prize獲得数は今年で18に達しました。現在C++エンジニアを積極採用中で、カジュアル面談も実施しているそうなので、お気軽にJmees公式Twitter/XのDMへご連絡ください。