2019/7/8 現在Kaggleのコンペに取り組んでいます。あまりアウトプットができていませんが、インプットは滞りなく進んでますので、どこかでまとめてアウトプットしたいです。
私は現在SIerで勤務していますが、将来的なキャリアアップも兼ねて2019年5月より本格的にデータサイエンティストに向けての勉強を行っています(SIerについての私の愚痴を言ってるだけの記事はこちら)。
今後実際に勉強してきた内容を**「データ分析未経験SEがデータサイエンティストを目指す」**なる記事にしていく予定なのですが、
まずは最初に私が想定している勉強ロードマップを紹介したいと思います。
これはこの記事内にて「スキルパス」と呼んでいるものを、参考文献を使って自分なりに定義したものとなります。
※データ分析未経験SEの勝手な妄想であり、これがデータサイエンティストになるための最短の勉強法とは限りません。今後勉強しながら加筆修正できればと思います。
本記事の対象は、**『平均的なSIerにいるようなデータ分析業務未経験のSE』となります。
もっとも、ある程度の数学的素養やプログラミング・アルゴリズムの知識があることを前提にしています。
また、本記事における「データサイエンティスト」とは、ただ「機械学習やディープラーニングのプログラムが書ける」だけではなく、「実際の業務において顧客(あるいは自分)の課題解決をAIを用いて実行するために必要な幅広いのスキル」**を持つ人と定義します(当然私には具体的にどんなスキルかわからないため、曖昧な言葉でぼかしております)。
ロードマップ
今回、データサイエンティストとしての」を規定するにあたり、一般社団法人データサイエンティスト協会が提示した「スキルチェックリストVer2.00」を主に活用させていただきました。
さて、データサイエンティストに必要なスキルを表現した図として以下の図をよく見ます。
http://www.datascientist.or.jp/news/2014/pdf/1210.pdf
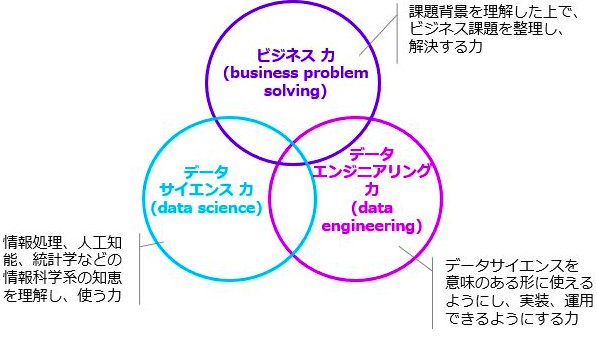
SEとして実際に働く身としては、この図より、以下の「AIによる課題解決のプロジェクトモデル」に即した形のほうがわかりやすく思いました。
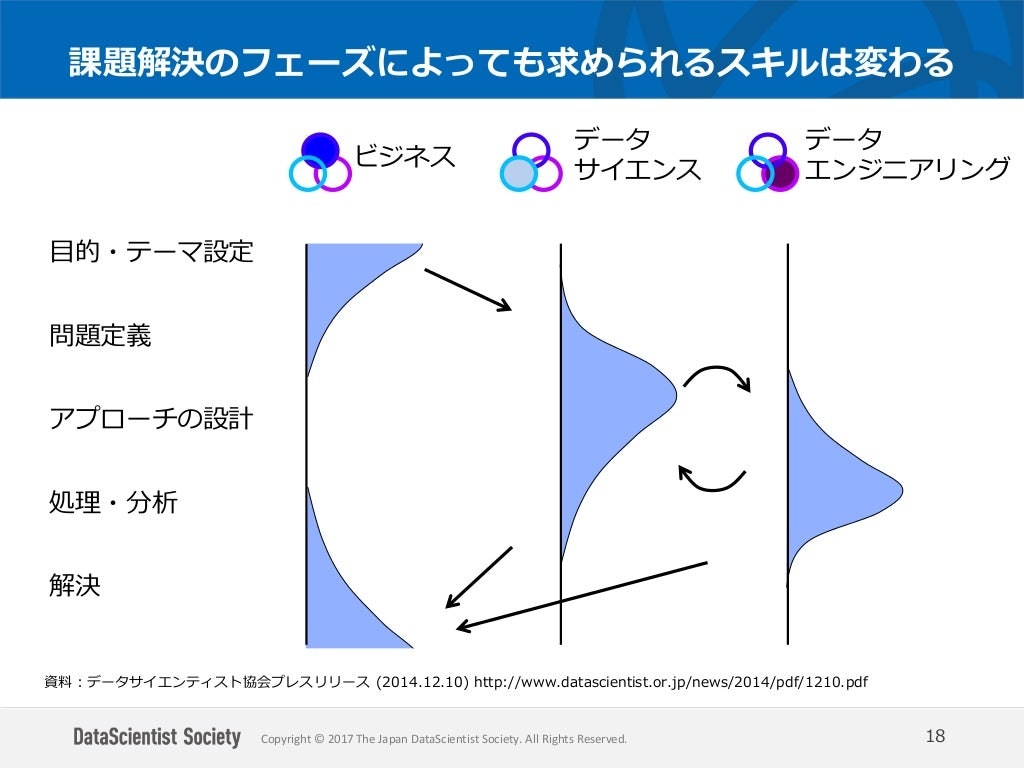
すなわち、
- SIerのウォーターフォールモデルにおける「上流工程」、すなわち**「要件定義」「マネジメント」で求められるのが「ビジネス力」**
- SIerのウォーターフォールモデルにおける上流と下流の間の工程、すなわち**「基本設計」および「システムテスト」等の上位テスト**で求められるのが「データサイエンス力」
- SIerのウォーターフォールモデルにおける下流工程、すなわち**「実装」「単体テスト」**で求められるのが「データエンジニアリング」力
という荒っぽい考え方ができます(データ分析未経験であるがゆえにこう表現せざるを得ないのですが)。
ここからわかることは、「データエンジニアリング力」だけでは**SIerでいう「下流工程しかできない作業者」**扱いでしかないということ。
そして、**機械学習・ディープラーニング入門を謡う本やサイトの9割はデータエンジニアリング力の表層のPythonといくつかのライブラリ程度しか教えてない(気がする)**ため、多くのデータ分析初学者は「これさえできればデータサイエンティストになれる」という勘違いをしているのではないか。
だからこそ、**3つの力の内訳を総合的に把握し勉強することができれば(たとえすべてを今すぐ勉強するのが無理でも、必要な能力が何であり、それを勉強するためのプランニングが十分できていることを見せることができれば)、データサイエンティストとしての転職活動において非常に有利になるに違いない、**というのが、今の私の考えている妄想となります。
(もちろん、「データエンジニアリング力」が不要というわけではありませんが、最近ではPython~Scikit-learnの入門書は爆発的な勢いで増えてきており、「データエンジニアリング力」を身に着けるためのハードルは加速度的に低くなっているのではないでしょうか?)
また、蛇足になりますがこちらの記事でもこんな一文があります。
多くの企業ではAIならびにデータサイエンスのプロジェクトにはデータサイエンティストだけではなく、様々な専門のスキルを持った人たちが必要ということが分かってきました。データ・エンジニア、データ・アーキテクト、データの可視化の専門家、そして、おそらく一番重要であろうトランスレーター(翻訳する人)といった人たちです。
ここでトランスレーターと言っているのは何も言語の翻訳をする人のことではありません。データサイエンスの言葉とビジネスの言葉を仲介することができる人のことです。つまり、データサイエンティストやデータエンジニアといった人たちの技術的な専門性とビジネスの前線に出ているマネージャー達のマーケティング、サプライチェーン、製造、金融などといった業務に関する専門性を結びつける役を担う人たちです。
上述の3つの力を(それなりのレベルで)全て兼ね備えた上で、ドメイン知識を兼ね備えてビジネス領域との橋渡しができる人材こそ、SEが目指すべきデータサイエンティスト像なのだろうと思います。
これから、現在私の考えているロードマップの詳細を説明していきます。
データエンジニアリング力
AI実装力を総合的に鍛えるサイトとして、**Kaggle**を使っていきます。
データ分析未経験者が転職時、実務力をアピールするためにKaggleの成績はほぼ必須?とまで書いてある記事も見ました。
データエンジニアリング力① Pythonとそのライブラリ
この範囲に関しては大量の入門書が粗製乱造されていると思うので、詳細は割愛します。
Scikit-learnに入るまでのPythonとか各種ライブラリははっきりいってAIを実現するための手段でしかないので、正直つまらないです。
言語リファレンスのようなものをひたすら書き連ねているような本ははっきり言ってつまらなすぎるので、インタラクティブ学習サイトで実際にコードを書きながら覚えていきます。
学ぶ技術の想定
- Python
- Numpy(行列計算など)
- Scipy(仮説検定など)
- Pandas(メモリ上のデータ操作ツール)
- Matplotlib, Seaborn(データ可視化)
- OpenCV(画像操作ツール)
- Scikit-learn, Keras, TensorFlow etc…(機械学習フレームワーク)
教材候補
Codecademy :英語がスラスラ読めるならおすすめのインタラクティブ学習サイト。講座は機械学習までで、深層学習の講座はなし。でも、AIだけじゃなくてWebとかいろいろと異常な量の講座があるので個人的には大好き。機械学習講座はKaggleの導入にもなっている。
Aidemy :日本語のインタラクティブ学習サイト。英語がだめならインタラクティブ学習サイトとしては現状唯一の選択肢でしょうか。Codecademyと違い深層学習の口座が充実しているが、Codecademyより割高な印象。
DL4US :機械学習まで学んで深層学習に進む際の選択肢としては現状これ一択なのでは?とすら思える、素晴らしすぎるKerasでの深層学習講座。
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装: 一時期書店のプログラミング部門ランキングトップに居座り続けてた本。今ならDL4USの方がいいかも?
**図解速習 DEEP LEARNING
データエンジニアリング力② データクレンジング
機械学習の精度を高める上で重要なのがデータ加工(データ前処理・データクレンジング)です。
学ぶ技術の想定
(工事中)
教材候補
基本的には、「データエンジニアリング力①」と同じ教材で事足りると思っています。
Codecademy
Aidemy
Kaggle
(6/27追記)KaggleのKernelで勉強して内容をまとめようと思います。
専門的に学ぶならこのあたりの書籍になるでしょうか?(意外とデータ前処理を扱った書籍は少ないです)
前処理大全
データエンジニアリング力③ Webスクレイピング
既にあるデータを使うのではなく、ネット上から独自のデータを収集してくる場合に重要なのが、Webスクレイピングの技術です。
WebスクレイピングについてはPythonだけではなくWebの知識を強く要求されるので、苦手意識があるなら後回しでもいいのかもしれません。(すでにデータがあるなら不要ですし)
学ぶ技術の想定
Codecademy :とりあえず、HTMLとCSSとJavaScriptまでは学べます。
Progate :日本語インタラクティブサイトでも十分学べます。
教材候補
データエンジニアリング力④ データ分析基盤
ビジネスで扱われるような特に大規模のビッグデータを扱う上で重要なのがデータ分析基盤の構築だそうです。
ビッグデータは持っているけど、そのデータをいきなり学習させるのはもちろん不可能です。かといって普通のOracleみたいなDBMSではデータが巨大すぎて非効率的。なので分散処理で高速な専用のプラットフォームを使おうということ。
SIerで学んだSQLの知識やDBMS構築経験がある程度役に立ちそうな分野でもあります。
学ぶ技術の想定
Hadoop + Apache Sparkが現在の主流だそうです。
こちらの記事が非常によく概要がまとめられています。
AWSやAzureなどクラウド上でのデータ分析基盤についても学んでおきたいです。私はAzureでの開発経験があるので、その延長線上になるのかな。Azure Data Lake Analyticsとか?
教材候補
データサイエンス力
データサイエンス力は端的に言ってしまえば「理論」であり、学問的な要素が強くかつ非常に多岐に渡るため学ぶのが特に大変そうに思います。
一朝一夕の付け焼刃でどうにかなるものでもないので、日頃からの学習習慣が求められてきそうです。
よほど数学に強い人でない限り、先に実装(データエンジニアリング力)から入るほうが良さそうです。
顧客への提案やモデル設計に説得力を持たせるためにも理論の理解は重要です。
ただ、我々は新しいアルゴリズムを構築したりするわけではなく、既に広く認知されたアルゴリズムさえ使用できればよいはずなので、小難しい本を読むのは程ほどでいいと思いますし、ましてや研究論文を読むのは不要だと思っています(甘いでしょうか?)。
※現在の私でははっきりいって全貌が見えないので、ざっくりと使えそうな教材だけ書いておきます。
教材候補
ディープラーニングG検定 ジェネラリスト問題集: ディープラーニング協会が行っているG検定は、データサイエンス力(機械学習とディープラーニングの理論)を身に着ける上でのベンチマークとして有益だと思います。E検定は高すぎるので当分やりませんが。
**Deep Learning :無料で読めるMITの教科書。データサイエンス力を身に着ける上での登竜門だと思っています。**私はまだ3分の1しか読めていません。日本語訳版もありますがちらっと見た限り直訳してるだけにしか思えなかったので買っても読めない人は読めなさそう。こんな感じの理論の本でもっと簡単に読めるものがあればAI人材が増えそうなものだが…
DL4US :「データエンジニアリング力①」にも書きましたが、Kerasでの実装だけでなく深層学習の理論についても参考文献を交えて丁寧に紹介されています。
統計学入門 :統計学のバイブルらしい。私は理一2年の時統計学びましたが、この本ではなかったです。でも多分どれも書いてある内容は同じ。
はじめてのパターン認識 :機械学習の理論的側面を学ぶにあたって一番いろんな人がお勧めしている本。ただし、専門書なので難しいらしい。
言語処理のための機械学習入門: 自然言語処理のバイブルらしい。(適当)
ゼロから作るDeep Learning ❷ ―自然言語処理編: 同じく自然言語処理で高い評価の本。(適当)
経済・ファイナンスデータの計量時系列分析: 時系列分析のバイブルらしい。(適当っていうかこういうの真面目に網羅するなら大学で学びなおしたほうが良い気がしてきた)
ビジネス力
一般的なビジネス力は普通のSEでも十分身に着けられる能力なので、SEがデータサイエンティストを目指すなら積極的にアピールできるようになりたいです。
逆に、「データサイエンティスト特有のビジネス力」は実際に現場に携わらないと身につかなそうに思えます。
実際に職に就くまでに、この本を読んで内容をまとめて記事化することを考えています。
戦略的データサイエンス入門
学習スケジュール(6/13修正 Qiitaに履修内容のまとめを投稿することを以って完了とする!)
現在~2019/6下旬 :データエンジニアリング①(DL4US、ゼロから作るDeep Learning①②) + Kaggleコンペ初参加
2019/7上旬 :データエンジニアリング② + Kaggleコンペ挑戦開始
2019/7中旬~下旬 :データエンジニアリング④ + 「戦略的データサイエンス入門」読破(遅らせました)
2019/8上旬~ :統計学復習 + 「はじめてのパターン認識」読破
2019/8上旬~9 :AWS上で何らかのAIアプリを開発し、公開する
2019/9末目標 :Goodfellow本読破
余裕があれば: 上記記載したデータサイエンス力向上のための書籍を読む
並行してWebスケジュールも作成。
2019/7 CodecademyのReact
2019/8 CodecademyのVue, Node, Bootstrap
2019/9 CodecademyのExpress, Angular
その他
- 上記には記載しませんでしたが、セキュリティやネットワーク等の一般的な知識はデータサイエンティストに限らずどんなIT業界においても使えるスキルだと思います。
これらについてはIPAの資格取得を通じて学ぶのが最も効率がいいと思います。詳細は割愛します。 - ビジネス力の中で、ビジネスマン共通のスキルである論理的思考力やプレゼンテーション力などについては割愛します(暇なら書くかも)。
- 余談ですが、「アルゴリズムとデータ構造」について体系的に学ぶなら競プロ関連の書籍がおすすめです。
- データ分析に当たってRを使っている人が多いですが、今から学ぶならPythonだけに絞った方がよさそうだと思いました。Rじゃないとできないことってあまりなさそうなので。Pythonデータ分析を十分学んで余裕があれば学びます。