本記事の位置付け
こちらの勉強会 英語で技術書を読もう:Fundamentals of Data Engineering 第25回 に参加し、発表するためにまとめたもの。
- 今回の対象は以下
- Chapter8 Queries, Modeling, and Transformation
- Techniques for Modeling Batch Analytical Data より
- Wide denormalized tables
- Modeling Streaming Data (Transformation の手前まで)
- Techniques for Modeling Batch Analytical Data より
- Chapter8 Queries, Modeling, and Transformation
Chapter8 Queries, Modeling, and Transformation
Techniques for Modeling Batch Analytical Data
第23回で以下を翻訳済。
資料はこちら
- 冒頭
- Inmon
- Kimball
- Fact Tables
第24回で以下を翻訳済。
資料はこちら
- Dimension tables
- Star schema
- Data Vault
- Hubs
- Links
- Satellites
「Wide denormalized tables」
- InmonやKimballのような厳密なモデリングは、DWHが高価でオンプレで計算資源やストレージに制限されていた時代に記述された。
- バッチデータモデリングがこのように厳密な方法を取った一方で、より緩やかな方法が共通になってきている。
- 理由その1
- クラウドの普及によってストレージが格安になった。
- ストレージ内でデータをどのように表現するかに苦悩するよりも、ひとまず格納するだけのほうが安く済む。
- 理由その2
- JSON等のネスト化されたデータの普及により、データソース(出元)や分析システム(出先)におけるスキーマは柔軟になった。
- 理由その1
- 厳密なモデル化をするのもワイドーテーブルに全部ぶっ込むのもあなたの自由。
- ワイドテーブルは聞いての通り、非正規化されて幅広に多数の列を持っていて、列志向データベースで典型的なもの。
- 一つのフィールドに一つの値、またはネストされたデータを格納する。
- データは一つまたは複数のキーで統合されていて、これらのキーはデータの粒度に非常に関連している。
- ワイドテーブルは、
- 数千の列を持つ可能性もある
- 一般的にはまばらなもので、そのほとんどのフィールドはnullであることが多い。
- 列志向データベースでは
- Nullは実際にはスペースを取らない。
- クエリで指定された列だけを読み取るし、NULLは無なので読み取りが速い。
- 伝統的なRDBは、
- 列の数は100未満というのが一般的
- 全てのフィールドに一定の空白を割り当てるので、非常にコスト高。
- 広いスキーマの場合、読み取りが非常に遅くなる。
- 各行はスキーマによって指定されたスペースを割り当てなければならないからだ。
- ワイドテーブルとは、一般的には、スキーマの進化を通して発生する。エンジニアは時間をかけてフィールド(列とか?)をちょい足ししていくものだ。
- スキーマの進化は、時間がかかり、リソースに負荷をかけるプロセス。
- カラムナーデータベースでは、フィールドを追加することが最初のメタデータ変更になる。
- データが新しいフィールドに追加される際、新しいファイルが列に追加される。
- ワイドテーブルへの分析クエリは、多くのJOINを必要とする正規化されたテーブルに対する同等のクエリよりも速いことが多い。
- JOINを取り除くことはスキャンのパフォーマンスに大きく影響を与える。
- ワイドテーブルには、厳密なモデリングではJOINされるはずだったデータが全て入っている。
- ファクトもディメンジョンも同じテーブルに入っている。
- データモデルの厳密性に欠けるということは、多くのことを考える必要がないということでもある。
- データをワイドテーブルにロードしてクエリを始めよう。
- 特にソース・システムのスキーマがより適応的で柔軟になっているため、このようなデータは通常、大量のトランザクションに起因し、つまりデータ量が多いことを意味する。
- このようなデータをネスト化されたデータとして分析ストレージに格納することは、多くのメリットがある。
- 全部のデータを一つのテーブルにぶっ込むことは、厳密なデータモデラーからしてみれば異端に見えるかもしれない。我々は多くの批判を見てきた。
- 最大の批判
- データを混ぜると、分析においてビジネスロジックを失う。
- もうひとつの批判
- 配列の要素などを更新する際のパフォーマンスが非常につらいことになる
- ワイド・テーブルの例(表8-21)を見てみよう。
- 先ほどの正規化の例で非正規化した元のテーブルを使用する。
- このテーブルはもっと多くの列を持つことができる。
- ご覧のように、このテーブルは様々なデータタイプを組み合わせており、ある日付のある顧客からの注文群、という粒度に沿って表現されている。
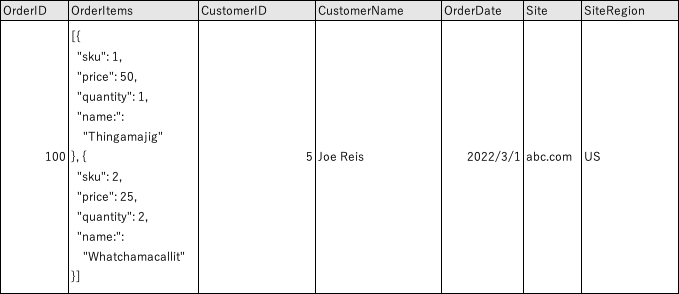
(表8-21)
- データモデルを気にしない場合や、伝統的に厳密なデータモデリングよりも柔軟さが必要なデータがたくさんある場合にはワイドテーブルはお勧めする。
- ワイドテーブルはストリーミングデータにも使えるが、それは次の章。
- データがより速く動くスキーマに乗るようになり、ストリーミング中心になるにつれ、新たなデータモデルの潮流を予見し、おそらく「緩和された正規化」のようなものが登場すると予想される。
第10パラグラフ What If You Don’t Model Your Data?
- データモデリングをしない、という選択肢もあるが、その場合、データソースにそのままクエリをかけることになる。
- よくあるケースだが、特に企業が始めたばかりで手早く何かを見つけたい時や、ユーザと分析結果を共有したい時にこうなる。
- 様々な質問に回答する時に、以下のことに気をつけなければならない。
- データモデリングしていないならば、どうやってクエリが一貫性があると確認できるのか。
- データソース内に適切なビジネスロジックの正しい定義はあるのか?そしてクエリは正しく信頼できる回答をもたらすのか?
- 私のクエリはどの程度の負荷をシステムにかけるのか?そのシステムのユーザへの影響はどれほどか?
- いつしか、より厳密なバッチデータシステムのパラダイムや、高負荷をソースシステムにかけない専用データアーキテクチャに傾倒するかもしれない。
「Modeling Streaming Data」
- バッチでは多数のデータモデリング手法がある一方で、ストリーミングデータに関してはそうではない。
- 無限かつ継続的なストリーミングデータの性質ゆえに、Kimballのようなバッチの技術をストリーミングに転用することは、不可能ではなくともむずかしい。
- 例えば、データのストリームがあったとして、データウェアハウスをダウンさせることなく、Type-2のSlowly Changing Dimensionを継続的に更新するにはどうすればよいだろうか?
- 世界はバッチからストリーミングへ、オンプレからクラウドへ進みつつある。
- 古いバッチの手法の制約はもはや通用しない。
- とはいえ、流動的なスキーマの変更、動きの速いデータ、セルフサービスに対してビジネスロジックの必要性の平衡を保つ為に、データをどのようにモデル化するかについては大きな疑問が残る。
- ストリーミング・データ・モデリングに関する合意されたアプローチは(まだ)存在しない。
- 私たちはストリーミング・データ・システムの多くの専門家に話を聞いたが、その多くは、従来のバッチ指向のデータ・モデリングはストリーミングには当てはまらないと語った。
- 何人かは、ストリーミング・データ・モデリングのオプションとしてData Vaultを提案した。
- ご記憶の通り、ストリームには主にイベント・ストリームとCDCの2種類がある。
- ほとんどの場合、これらのストリームのデータの形状は、JSONのような半構造化である。
- ストリーミング・データをモデリングする際の課題は、ペイロードのスキーマが不意に変更される可能性があることだ。
- 例えば、最近ファームウェアをアップグレードし、新しいフィールドを導入した IoT デバイスがあるとする。
- その場合、下流のデータウェアハウスや処理パイプラインがこの変更に気づかず、壊れてしまう可能性がある。
- 別の例として、CDCシステムがフィールドを異なる型にリキャストすることがある。
- 例えば、国際標準化機構(ISO)のdatetimeフォーマットの代わりに文字列を使用する場合。
- 繰り返しになるが、宛先のシステムはこの一見ランダムな変更をどのように処理するのだろうか?
- 例えば、最近ファームウェアをアップグレードし、新しいフィールドを導入した IoT デバイスがあるとする。
- ストリーミング・データの専門家に話を聞くと、ソース・データの変化を予測し、柔軟なスキーマを維持することを勧める人が圧倒的に多い。
- つまり、分析データベースには硬直したデータモデルは存在しないということだ。
- その代わりに、ソース・システムが現在存在する正しいビジネス定義とロジックで正しいデータを提供していると仮定する。
- また、ストレージは安価であるため、最近のストリーミングデータと保存された履歴データを一緒にクエリできる方法で保存する。
- 柔軟なスキーマを持つデータセットに対して、包括的な分析を最適化する。
- さらに、レポートに反応する代わりに、ストリーミング・データの異常や変化に反応する自動化を作ってはどうだろうか。
- データモデリングの世界は変化しており、データモデル・パラダイムにも間もなく大きな変化が起こると考えています。
- このような新しいアプローチでは、ソース・システムの上に直接置かれるストリーミング・レイヤーに、メトリクスやセマンティック・レイヤー、データ・パイプライン、従来の分析ワークフローが組み込まれることになるでしょう。
- データはリアルタイムで生成されているため、ソースシステムとアナリティクスシステムを人為的に2つの異なるバケットに分けるという考え方は、データがゆっくりと予測可能に動いていた頃ほど意味をなさないかもしれない。
- 時間が解決してくれるだろう。
ストリーミング・データの将来については、第11章で詳しく述べる。