何ができるか
BigQueryなどのデータウェアハウスやデータベースのデータに対して、いわゆるELT処理のTを構築管理することができるソフトウェアorサービスです。
使い方は、クラウドサービスの dbt cloud かローカルに構築して使う dbt CLI の2通りあるようです。
dbt cloud の画面はこんな感じです。
こちらの記事は基本クラウドを使う前提で書いています。
DB側の準備 (BigQuery)
BigQueryに対して使う場合、BigQuery側にデータを配置し、サービスアカウントをdbtのために発行するだけです。サービスアカウントに付与するロールは、以下のとおりです。(参照元)
- BigQuery Data Editor
- BigQuery User
パイプラインの構築
SQLファイルの作成で変換処理を書く
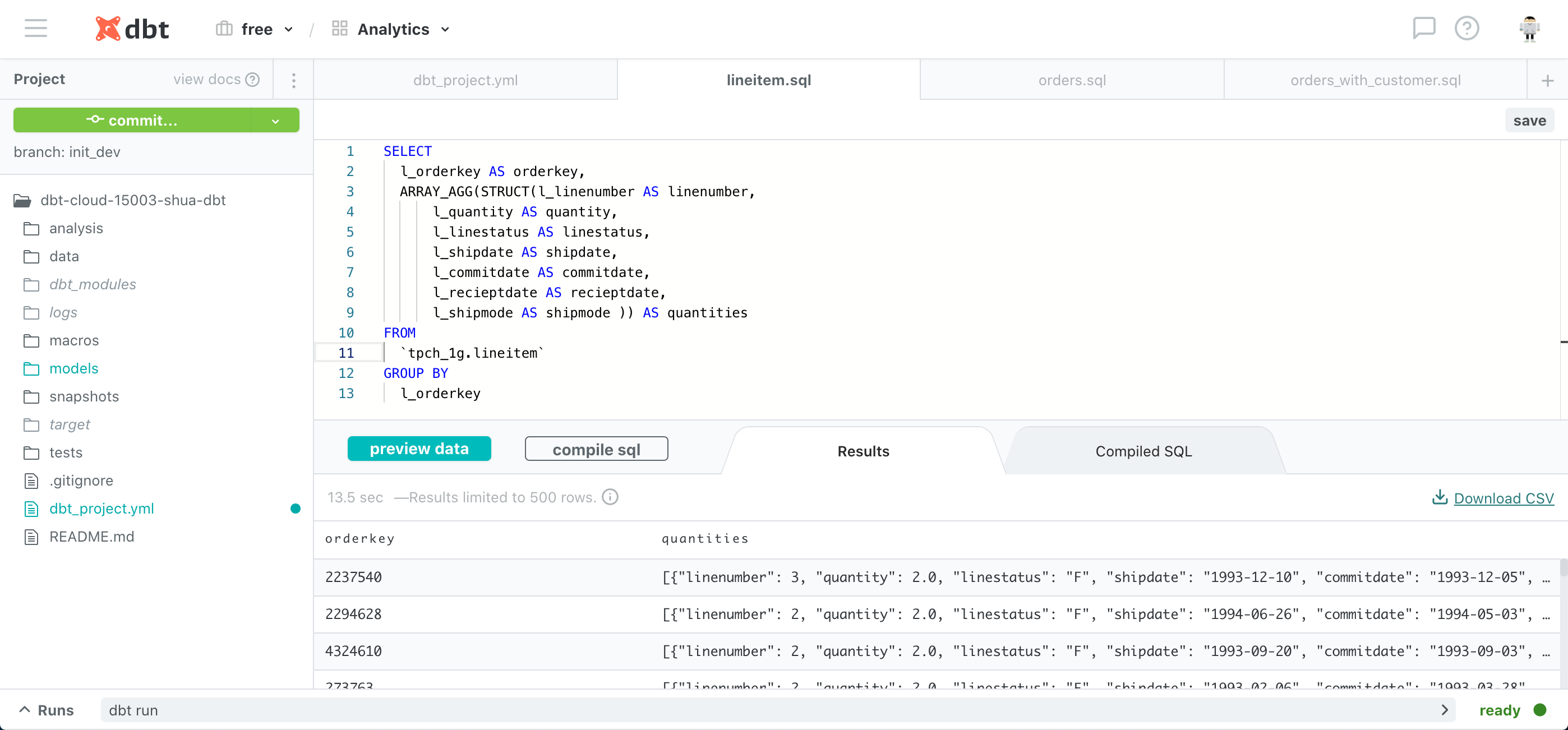
dbtでは、SQLを記述したファイルを作成し、それを関連づけることでパイプラインを構築します。SQLは次のようなファイルに本当に単にBigQueryの画面で書くSQLそのものをファイルにします。
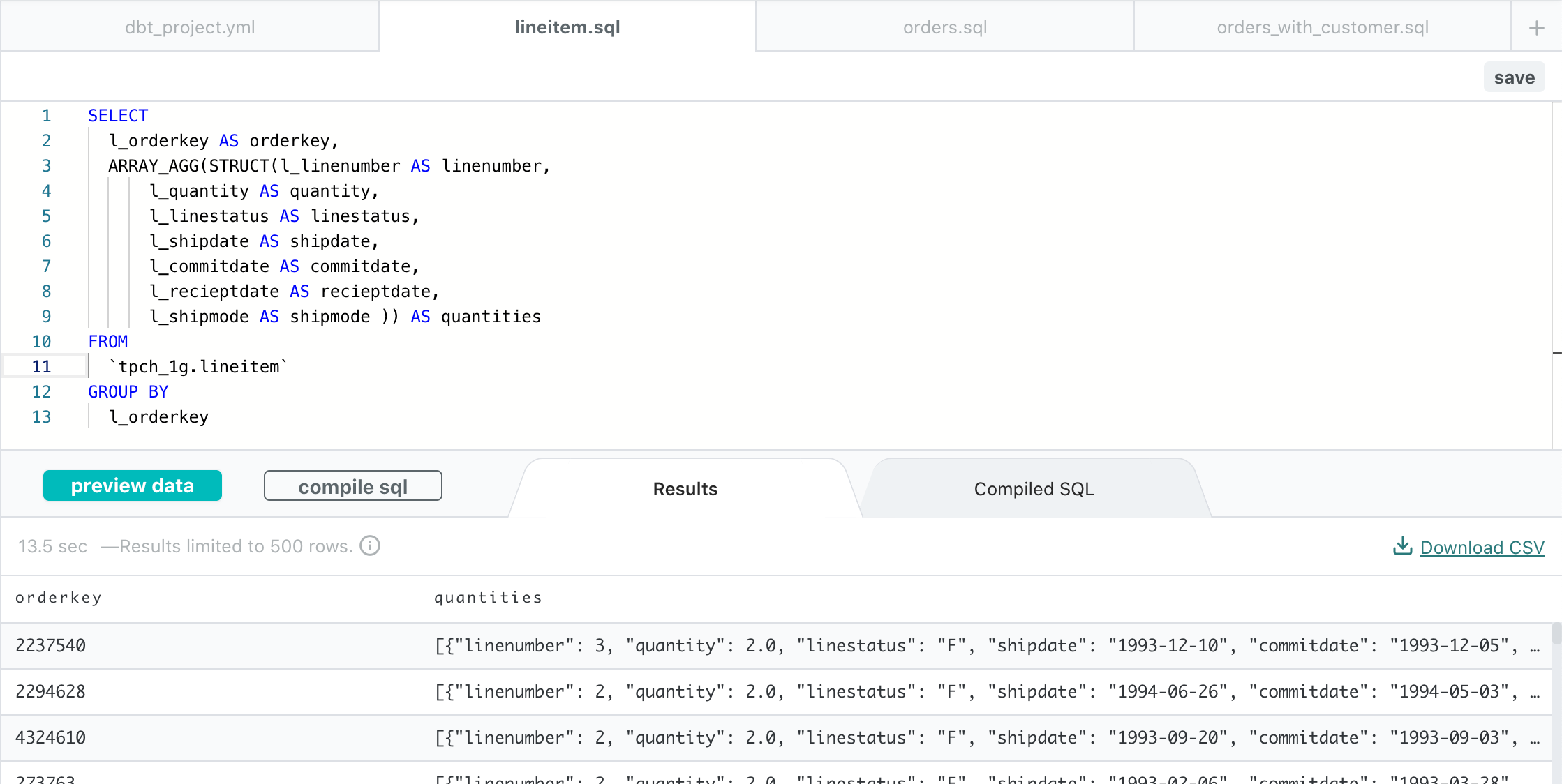
preview data をクリックすると実際にクエリがBigQueryに発行され、下部に結果が表示されます。(ここBigQueryの費用が発生するので大きなテーブルの場合など注意ですね。)
で、この結果をどういう形で出力するかを指定することができます。ビューとかテーブルとして実体化するなどを選択します。それは、別の設定ファイル dbt_project.yml に書くか、先のSQLファイルに書きます。SQLに書いた場合、当然そのSQL処理で生成される出力のみに対して指定は有効になります。一方、dbt_project.yml には、フォルダのレベルでより広く出力の設定を適用することができます。
SQLファイルに書く場合
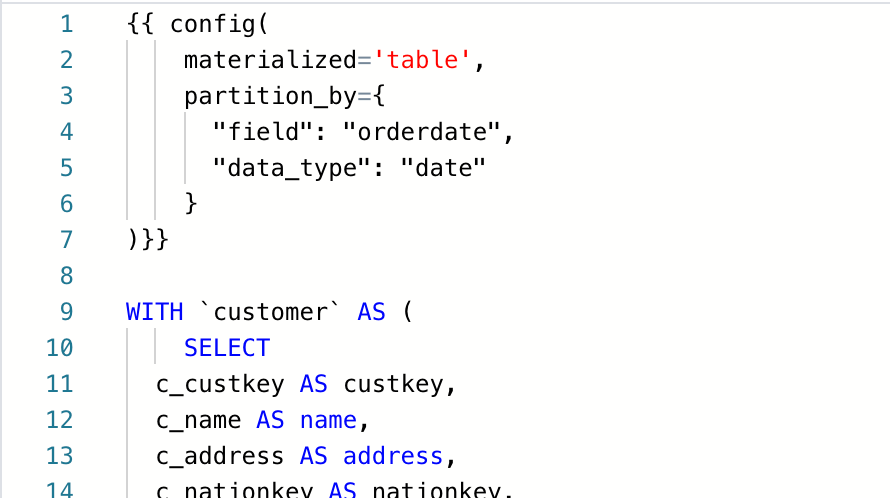
次のようにSQLファイルの冒頭などに書きます。BigQueryの場合、テーブルとして実体化する際のパーティションの指定などができます。
dbt_project.yml に書く場合
dbt_project.yml に書く場合は、次のようにyaml形式で、モデルの下のフォルダなどを指定して、そのフォルダに存在するファイル全てに適用させる形で指定します。
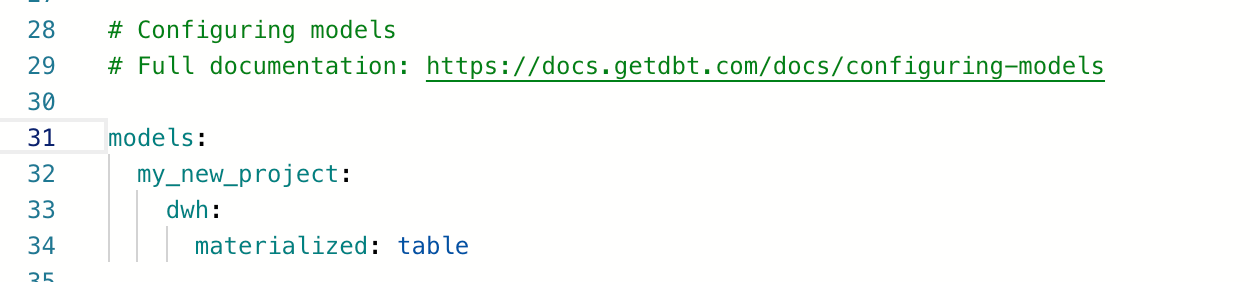
ファイルとフォルダ
dbtは、デフォルトで次のようなファイルやフォルダが生成されます。変換処理を定義するSQLファイルは models に記載します。models 配下に階層的にフォルダを作成することもできます。ここでは、dwh層のデータをつくるという想定で dwh フォルダを models の下に作り、そこに変換処理のクエリが書かれたSQLファイルを格納しています。
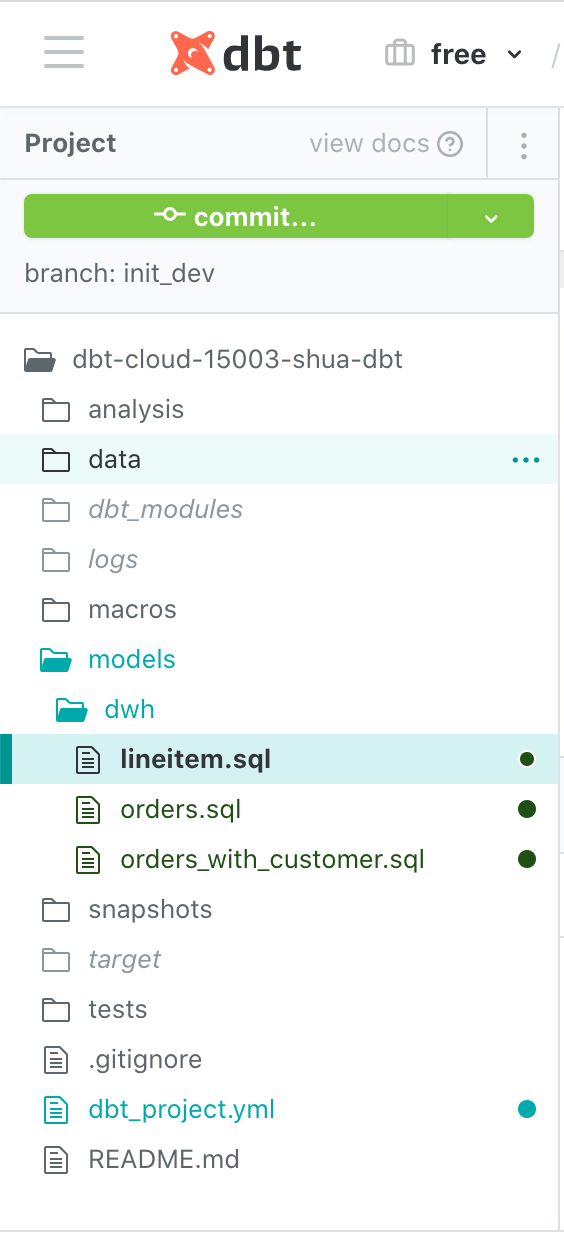
また、これらのファイルやフォルダは、Githubと連携します。これすごい良いところですね。開発フローが運用できるし、ファイルの管理も楽になります。
クエリの出力を別のクエリで参照する
例えば、2つのテーブルを結合する処理をする場合に、可読性やパフォーマンス向上のために複雑なクエリをファイルに分割したり、分割したクエリそれぞれで結果をテーブルに出力したりすることがあると思います。その場合、SQLファイルの中で次のようにして別のクエリ結果を引用することができます。 {{ ref('lineitem') }} や {{ ref('orders_with_customer') }} の部分がそれにあたります。こうすることで別ファイルでクエリを記述している処理を参照できます。

これにより、パイプラインとしては、lineitem と orders_with_customer の処理が終了した後に、上のSQLの処理が実行されるフローとなります。このようにして、処理の依存関係を定義していきます。
実行とEnvironment
開発環境での実行
処理の記述が終わったら、まずは開発環境で実行して想定通りの処理か確認することができます。dbtには、Development と Production それぞれの環境を用意できます。
画面左下の dbt run をクリックしてEnterすると処理が実行されます。処理が終わると次のように結果が表示されます。
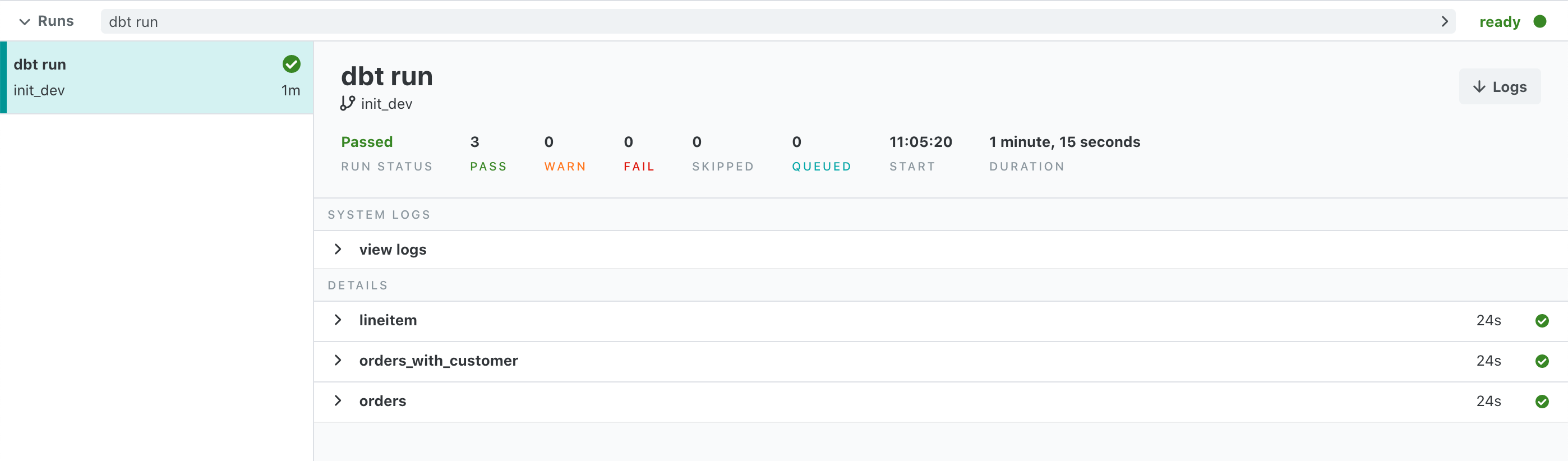
実際に、BiqQueryのコンソール画面上でテーブルができている様子が確認できます。

本番へのデプロイと実行
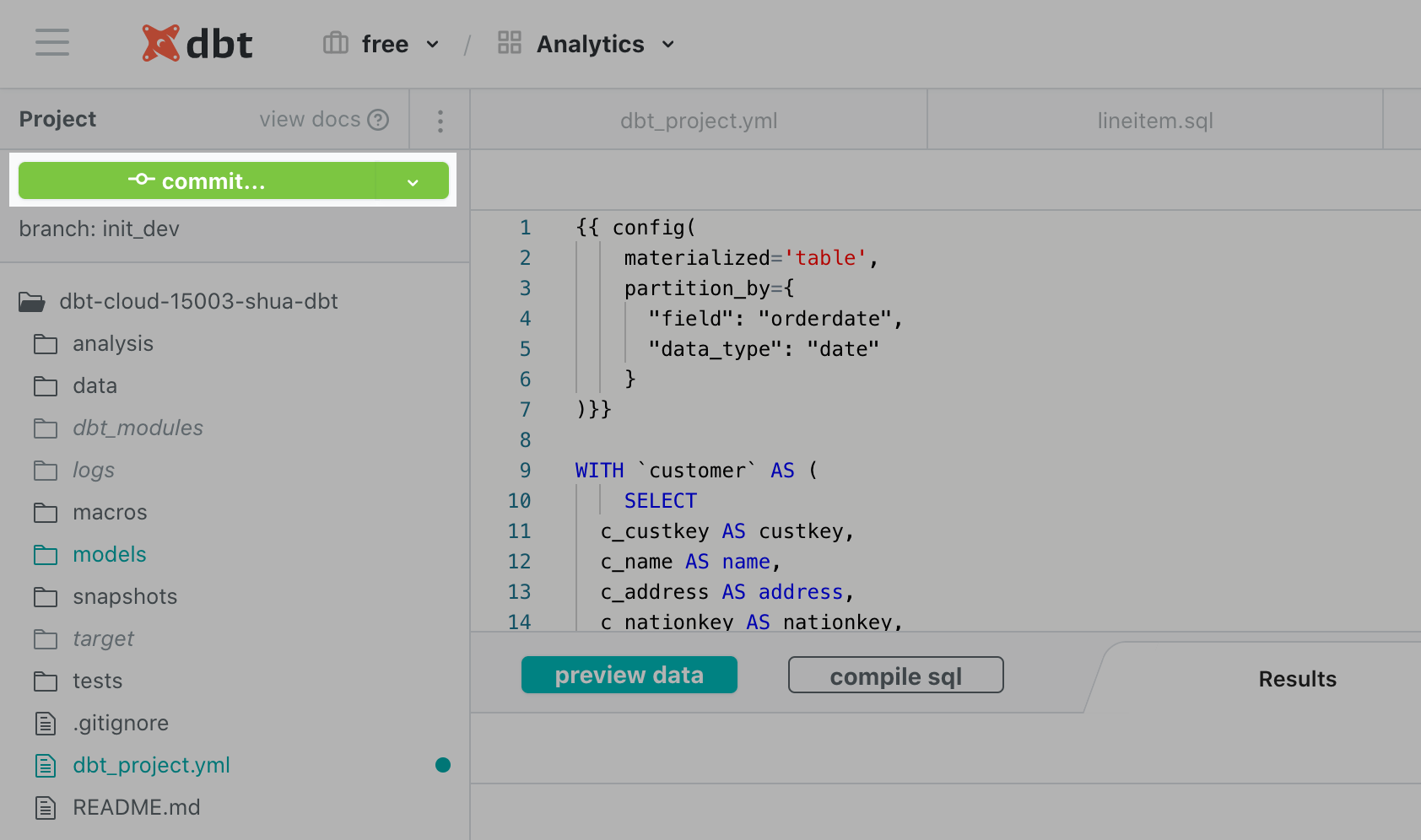
開発で正常に動くことが確認できたら本番へ反映します。画面の左上に Commit ボタンがあると思いますが、これをクリックしてコミットメッセージを入れます。今度は、同じボタンが merge to master となるのでこれを続けて押します。ちなみに、開発する際に初めにmasterとは別のブランチを作っています。
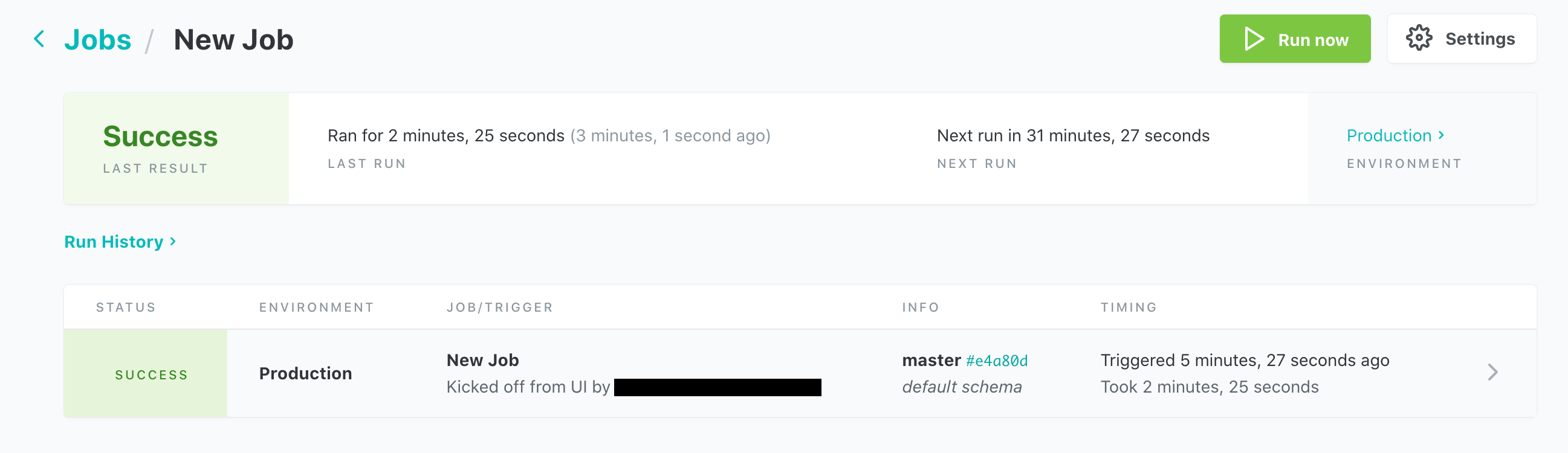
次にメニューから Jobs を選び、続けて New Job をクリックします。ジョブ名や定期実行の感覚などを設定し、Save をクリックします。これで指定した感覚でジョブが定期実行されるようになり、BigQuery上にある元テーブルのデータが更新を反映することができます。Run now をクリックして即時実行することもできます。ジョブが実行されると次のようにジョブの実行結果がリストされます。