AIエージェントによるコーディングが一般化しつつある現在、「AIでTDD(テスト駆動開発)は実現できるのか」という問いは、単なる興味ではなく実務上の重要な論点になりつつある。
仮に、AI駆動開発がTDDを十分に理解し、適切に実行できるとすれば、誰がそれに異を唱えるだろうか。ソースコードを書く速度に関して言えば、人間がキーボードを叩くよりも、AIエージェントの方が速いのは自明である。問題になるのは常に「品質」だ。
実際、いくつかの研究や現場報告では、AIエージェントの導入によって実装スピードは向上する一方、バグ修正の件数も増加していると指摘されている1。
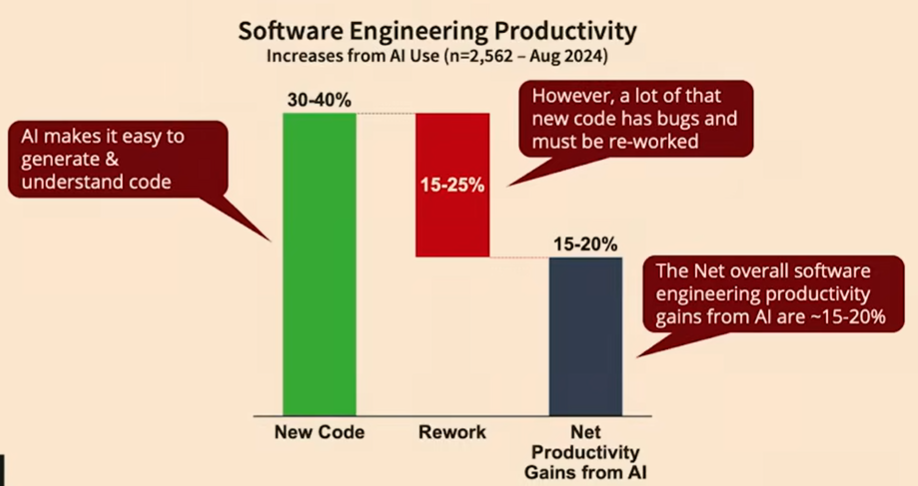
つまり、前進はしているが、同時に後退もしている状態である。そこには「TDDが成立していない」という構造的な問題が横たわっている。
AIエージェントにおけるTDDの典型的な破綻パターン
AIエージェントを用いた開発で、TDDがうまく機能しない場面には、いくつか共通した失敗例が見られる。
- すでに実装されたコードを前提に、後付けでテストケースを生成している
- テストが失敗した際、実装コードを場当たり的に修正して通過させる
- テストが失敗したまま完了扱いにする、あるいはテストケース自体を削除してしまう
これらはいずれも、TDDにおいて本来守られるべき基本的なルールから逸脱している。しかし、AIエージェントはそれを「破っている」という自覚を持たないまま作業を進めてしまう。
背景には、現在のLLMがTDDを「概念として知っている」段階にとどまり、「思想として運用する」水準に達していないという問題がある。「TDDに沿って実装せよ」と指示しても、それを時系列のプロセスとして一貫して遂行することは難しい。
この理由としては、少なくとも次の二点が考えられる。
- テスト戦略やテスト設計はプロジェクトごとの差異が大きい
- LLMの学習データには、開発フローを時系列で追える情報が少ない
その結果、「TDDを実現する」と謳うワークフローやツールであっても、実態としてはTDDになっていないケースが多い。
React / Next.jsにおけるテスト設計という前提問題
この問題は、AIコーディング以前の段階にも起因している。たとえばReactやNext.jsを用いたWebプロダクトにおいて、「どのようなテストを書くべきか」が体系的に整理されたドキュメントはどれほど存在しているだろうか。
多くの開発者が合意できる標準的なテスト方針が確立されているとは言い難い。仮に、1日に1回のリリースを目指すプロダクトであれば、どのレベルまでテストすべきなのか。その問いに即答できるチームは多くないはずだ。
つまり、「何をテストすべきか」という共通認識自体が曖昧である。この曖昧さが、LLMにおけるTDD理解の浅さにもつながっていると考えられる。
その結果、AIが生成したテストコードは信用しきれず、人間が一つひとつ内容を確認する必要が生じる。もしくは、「テストは通るが実際には動かないプロダクト」がデプロイされ、すぐに修正が必要になるという二次作業が発生する。
Reactのテストが難しい理由
ReactをはじめとするWebアプリケーションにおけるテストが難しい理由は、大きく二つある。
- テスト実行のコストが高い
- 一つのユーザー操作に対して、状態管理からDB更新までと、実装とテストの対象範囲が広い
E2Eテストは、画面遷移やAPI通信を伴うため、1ケースあたりの実行時間が長くなりがちである。すべてのエッジケースをE2Eで網羅するのは現実的ではない。一方で、品質を担保しようとするとテストケースは増え、実行時間が開発効率を圧迫する。
このトレードオフの中で、「どこまでテストするか」を判断するには、プロジェクト固有の思想が不可欠である。これはエージェントに自律的に委ねられる判断ではない。
テスト思想を自然言語で与えるという発想
AIエージェントにTDDを実行させるための鍵は、「どのように指示を与えるか」にある。
アセンブリ言語が高級言語に置き換えられたように、高級言語が自然言語によるプログラミングへと置き換わりつつあるのであれば、開発者自身のテスト思想を自然言語として明示することによってAIエージェントをコントロール可能になるだろう。
ライブラリやツールに期待するのではなく、自分たちの基準や判断軸を言語化し、それをエージェントに渡す。この前提がなければ、AIによるTDDは成立しない。
テストピラミッドと現実的な運用
JavaScript / React の文脈では、従来の「テストピラミッド」をそのまま適用するのは難しいとされてきた。E2E テストは実行時間と不安定性の問題を抱えやすく、数を増やせば品質は上がるが、開発速度を著しく損なう。一方で、単体テストだけでは UI を中心とした Web アプリケーションの品質を担保できない。
この現実を踏まえ、フロントエンド領域では E2E を最小限に抑え、その分 Integration Test(結合テスト)を厚くするという設計が広く受け入れられている。いわゆる「トロフィー型」のテスト分布である。
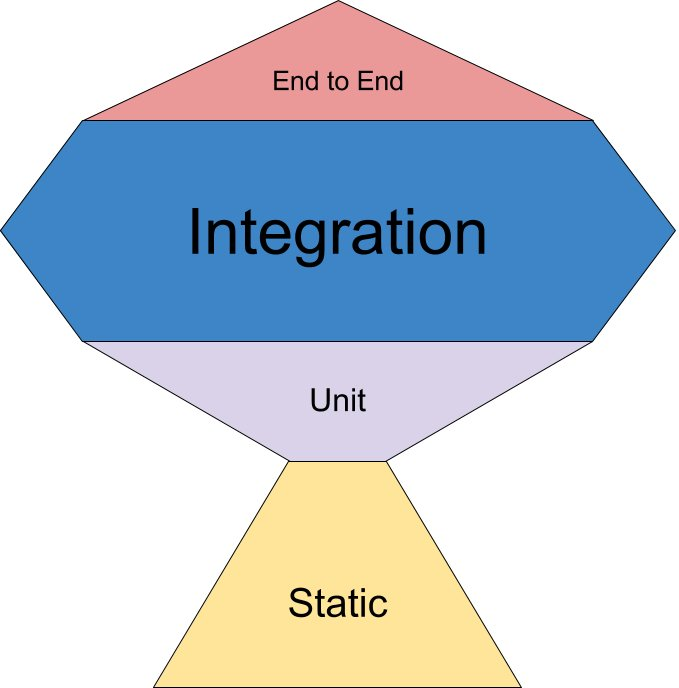
ただし、この方針はあくまで方向性を示すものであり、「どこを結合とみなすか」「何を信頼境界とするか」はプロジェクトごとに異なる。特に Next.js では、アーキテクチャの違いがそのままテスト設計の違いに直結する。
Next.js における代表的なアーキテクチャのバリエーション
Next.js と一口に言っても、実際の構成は多岐にわたる。
バックエンド分離型(BFF / API 分離)
- バックエンドは OpenAPI を備えた別サービス(FastAPI / NestJS など)
- Next.js は純粋なフロントエンド
- 結合テストは「API を信頼する前提」で UI 振る舞い中心
- MSW による API モックが一般的
Next.js API Routes / Route Handlers 利用型
- フロントとバックエンドが同一リポジトリ
- DB 直結(Prisma / Sequelize / Drizzle)
- API を直接テストするか、UI 経由で叩くかの線引きが必要
App Router + Server Actions 中心構成
- API Routes を使わず、Server Actions に副作用を集約
- Server Component 主導のデータフェッチ
- 結合テストは UI 側に寄りやすく、E2E 比重が上がる傾向
状態管理の違い
- Redux / RTK:Reducer や Selector を単体テスト可能
- Zustand / Jotai:UI と一体でのテストが増えやすい
- TanStack Query / SWR:Server State の再取得・キャッシュ挙動が論点
テスト基盤
- Unit / Integration:Jest / Vitest + Testing Library
- API:supertest / Contract Test
- E2E:Playwright
このように、Next.js における「結合テスト」は、アーキテクチャ・状態管理・副作用の配置によって成立条件が大きく異なる。
そのため、「結合テストを厚くする」といった一般論を、そのまま AI エージェントに適用することはできない。
React におけるテスト思想:React Testing Library が与える基準
こうした多様性の中で、React におけるテスト設計の思想的な基準として有効なのが、先程のトロフィーモデルを提唱しているKent C.Doddsが作成したReact Testing Library(RTL)が示す考え方である。
RTL の公式ドキュメントでは、React コンポーネントのテストにおいて避けるべきものとして implementation details が挙げられている。内部 state やコンポーネント構造に依存したテストは、リファクタリングに弱く、保守性を損なう。
その代わりに RTL が強調する中心原則は次の一点に集約される。
テストは、実際の利用に近ければ近いほど、高い信頼性をもたらす
この思想は API 設計にも反映されている。RTL はコンポーネントインスタンスを直接扱わず、DOM を通じてテストを書くことを強制する。要素の取得も、ユーザーが認識できる情報(ラベル、ロール、表示テキスト)を優先し、data-testid は最後の手段として位置付けられている。
重要なのは、この思想がアーキテクチャ非依存であるという点である。
バックエンド分離型であっても、Server Actions 中心構成であっても、「ユーザーの振る舞いとして何を検証するか」という基準は変わらない。
AI に TDD をさせるための前提条件
しかし、React Testing Library の思想は、あくまで「何を良いテストとみなすか」という基準を与えるものであり、TDD のプロセスそのものを自動的に成立させるものではない。
AI エージェントにテストを書かせる場合、
- 実装詳細をテストしない
- ユーザーの振る舞いを中心に検証する
- どこまでを結合とみなすか
といった判断軸を、プロジェクト固有のルールとして明文化して渡す必要がある。
これを与えずに「TDD で実装しろ」と指示すれば、エージェントは実装コードを起点にテストを書くという最も避けたい行動に流れる。
テストピラミッドや RTL の思想は、AI にとっての「暗黙知」ではない。
人間が設計思想を言語化し、前提条件として固定して初めて、AI 駆動開発における TDD は意味を持ち始める。
AIテストツールの現在地
テスト工程を支援するAIツールも登場し始めており、大きく二系統に分けられる。
一つは、テストを独立した領域として扱い、自動修復まで含めて吸収しようとするアプローチである。
QodoのBlogで整理されたものがわかりやすい。
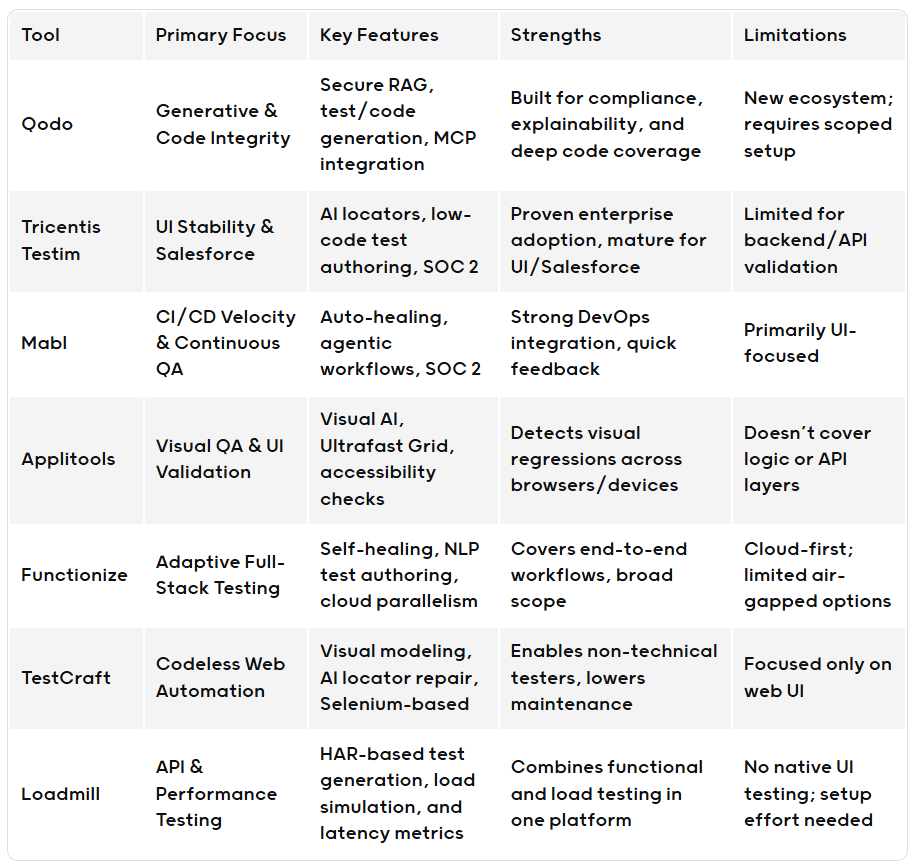
AIによるlocatorの自動検出やローコード・自然言語によるケース作成、実装が変わってもテストが追従するようなSelf-healingを謳うものが多い。
これらのツールは耳障りは良いが、Hypeが多いように思う。
もう一つは、既存のテストツールにAIを組み合わせ、生成や操作を補助する方向性だ。
PlaywrightのMCPなどのように、Claude Codeが呼び出して使うスタイルである。
後者の場合、テスト設計の主導権は依然として開発者側にあり、適切にコントロールしなければ、形だけのTDDに陥る危険がある。
まとめ
Claude CodeをはじめとするAIエージェントでTDDを実行すること自体は、不可能ではない。しかし、それはツールやフレームワークによって自動的に達成されるものではない。
- E2Eテストは最小限に抑え、実行可能性を重視する
- 結合テストは前提条件と思想を明文化し、エージェントに与える
- LLMがTDDを深く理解している前提を置かない
これらを踏まえ、自分たちなりのテスト思想を自然言語として明示し続けることが求められる。そうでなければ、エージェントは実装コードを起点にテストを書くという、本来避けるべき振る舞いに容易に流れてしまう。
現時点では、「Claude CodeでTDDは可能か」という問いに対する答えは、「条件付きで可能」である。その条件をどこまで明確にできるかが、開発者側に突きつけられている課題だと言える。