AIチャットボットやAI検索機能など、いわゆる AI-Powered App を実装しようとすると、必ず直面する課題がある。それは「アプリケーション固有のデータを、AIにどのように参照させるか」という点である。
AIが外部データを参照する代表的な方法として、まず挙げられるのが RAG(Retrieval-Augmented Generation) である。RAGは、LLMに独自の知識を付与する手法として広く知られており、十分なユースケースと実績を持つ。AIエージェントにとって、独自データを参照させる仕組みとしては、非常に有力な選択肢だと言える。
一方で、RAGは万能ではない。特に、アプリケーションの中核となる業務データを扱う場合、いくつかの実務的な課題が浮かび上がる。
RAGの限界と、構造化データの問題
RAGを採用する場合、既存のデータベースとは別に、埋め込みベクトル用のデータストアを用意することになる。これはすなわち、データの二重管理 を意味する。さらに、ベクトル検索は本質的に曖昧性を含むため、常に「正確な値」を返せるとは限らない。
例えば、次のような問いを考えてみる。
「この四半期でもっとも営業成績の良かった従業員は誰か」
営業成績は日次で更新されるデータであり、正確性が求められる。RAGで対応しようとすると、埋め込みデータの頻繁な更新が必要になるうえ、検索結果の妥当性を事前に検証することは難しい。Graph RAG のような reignite な手法で改善は可能だが、構成は複雑になる。
一方で、営業成績がRDBに正規化された形で保存されており、
- 四半期の定義
- 成績指標の算出方法
- 並び替え条件
が明確であれば、それを表現するSQLは検証可能であり、結果も説明可能である。
ここで登場するのが Text-to-SQL(NL2SQL) というアプローチである。
Text-to-SQLとは何か
Text-to-SQLとは、自然言語で書かれたクエリをSQLに変換し、データベースから構造化データを取得する という考え方である。検索対象はテキストではなく、あくまで構造化データであり、BIダッシュボードのAI拡張に近い発想だと言える。
この関係を整理すると、次のようになる。
- 従来のクエリ
- 構造化クエリ → 構造化データ
- 例:SUUMOで家賃、駅徒歩分数、間取りを指定する検索
- Text-to-SQL
- 非構造クエリ → 構造化データ
- SQLによる検索のため、結果は安定し、曖昧性が小さい
- RAG
- 非構造クエリ → 非構造データ
- 文書検索やナレッジ探索に向く
「正確な数値」「集計結果」「期間指定」といった要件が強い領域では、Text-to-SQLは非常に相性が良い。
Text-to-SQLの研究動向
Text-to-SQLは、従来のアプリケーション設計を変え得るポテンシャルを持つ分野として、研究も活発に進められている。体系的な整理としては、以下のリポジトリが参考になる。
- NL2SQL Survey & Tutorial
https://github.com/HKUSTDial/NL2SQL_Handbook?tab=readme-ov-file#-text-to-sql-survey--tutorial
Text-to-SQLの基本アーキテクチャ
Text-to-SQLの典型的な構成は、次のような流れになる。
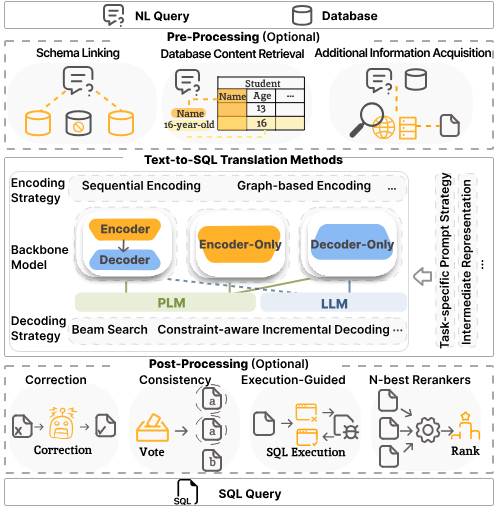
- ユーザの自然言語クエリを受け取る
- データベースのスキーマ情報を取得する
- LLMがSQLを生成する
- 生成されたSQLを検証する
- SQLを実行し、結果を取得する
- 結果を自然言語で整形して返す
重要なのは、SQLをそのまま実行しない ことである。検証や再生成のステップを挟むことで、安全性と信頼性を確保する。
実装案1:LangChain
Text-to-SQLを比較的容易に実装する方法として、LangChainのSQLエージェントがある。公式ドキュメントを参照すれば、標準的なフローが示されている。
実装イメージは次の通りである。
- 利用可能なテーブル一覧を取得
- クエリに関連するテーブルをLLMが判断
- スキーマ情報を取得
- SQLを生成
- SQLをチェック(LLMベース)
- SQLを実行
- エラー時は修正して再試行
- 結果を解釈して回答生成
LLMが生成したSQLを必ず検証する点が、実運用では重要になる。
実装案2:LlamaIndex
LlamaIndexも、Text-to-SQL向けのエージェント構成を提供している。
特徴的なのは、人間がSQLを書くときの思考プロセスを再現している点 である。
- Query-Time Table Retrieval
クエリに関連するテーブルだけを動的に取得し、不要な情報を排除する - Query-Time Sample Row Retrieval
サンプル行を取得し、データ型や値の傾向をLLMに理解させる
Claude CodeにLlamaIndexでの実装を指示した場合、次のようなフローになることが多い。
- クエリ受付
- 区分値・サンプル行の取得
- スキーマ確認
- SQL生成
- SQL実行
- エラー時の再試行
- 回答生成
自然言語と実データの乖離(表記揺れ、単位差、区分値不一致)は頻繁に起きるため、実データを見せたうえで判断させる設計は合理的である。
まとめ
Text-to-SQLは、AIエージェントの能力を測るタスクとしても、実務的な価値という点でも興味深い領域である。LangChainやLlamaIndexには、すでに実装例やツールが用意されており、導入のハードルは下がってきている。
BIツールやSaaSにおいて、ユーザが複雑な選択操作を求められている場面があるなら、自然言語検索に置き換えた場合のユーザ体験を検討する価値は高い。結果として、アプリケーションの価値向上に直結するケースも多い。
また、Text-to-SQLでは実行されるSQLが明示されるため、RAGと比べて挙動を把握しやすく、運用面での取り回しが良い。加えて、ユーザが自然言語で入力した検索要件そのものがログとして残る点も、開発側にとっては大きな利点である。
従来の検索UIでは拾えなかった「本当は何を知りたかったのか」を可視化できることこそ、Text-to-SQLがもたらす本質的な価値だと言える。