概要
AWS上に構築されているサーバーレスなAPIをAzure上に移行する機会があったので
移行についてのメモや注意点などのまとめました。
既存AWS環境で使用しているサービスは以下の通り。
- API環境:Lambda + API Gateway
- NoSQLDB:DynamoDB
- ストレージ:S3
移行先のAzure想定環境として使用予定のサービスは以下の通り。
- API環境:Azure Functions
- NoSQLDB:Azure Table Storage
- ストレージ:Azure Storage(BLOB)
前提条件(環境など)
開発環境
- Windows 10 Pro 64bit 1703
- node.js 6.11.3 64bit
- Visual Studio Code 64bit 1.16.1
- Azure Functions Tools 0.3.1
- ESLint 1.3.2
Azure Functionsをローカルで開発するためのVisual Studio Code環境は以下のblog記事を参考にしました。
かずきのBlog@hatena:Azure Functions を始めてみました(node.js + VSCode)
その他
- Azureのアカウントを作成済み
- Azure Portal で初めての関数を作成するを参照し関数を作っていること。
- Lambdaの開発言語はNode.js、Azure Functionsも同様にNode.jsを使用する。
※今回は移行元がNode.jsのためNode.jsで開発しましたが、新規の場合はC#の方がいいかもしれません。Web上の情報の多さが違います。
LambdaからAzure Functionsにソースを移行するに際して気を付ける点
- 開発言語を変更しない場合、SDKを使用している箇所以外のソースをそのまま使用可能。
- AWS SDKを使用している箇所については、Lambdaには無いバインドを使用して変更する箇所と、Lambdaと同様にAzure SDKを使用して変更する箇所があります。
- DynamoDBではキー項目については自由な項目名に出来るが、Azure Table StorageではRowKeyという項目名固定になるため、その部分は変更する必要があります。
- context.doneメソッドを呼ぶことで関数が完了したと判断される。呼び出していない場合、タイムアウトとなります。
※context.doneメソッドを呼び出した箇所以降に処理が記述されている場合、記述された処理は実行されます。
そのためエラー処理などで処理を終了する場合はreturnメソッドを呼び出す必要があります。
メイン処理完了後に非同期で処理を行いたい場合はあえてreturnメソッドを記述しないことも出来ます。
実際に移行してみる
DynamoDBからデータの取得・追加・更新・削除を行うコードを
Azure Table Storageからデータの取得・追加・更新・削除を行うコードに移行します。
データの取得
LambdaではDynamoDBからデータの取得を行う場合、AWS SDKを使用します。
サンプルコード(usersテーブルから指定したuserIdのデータを取得)
const AWS = require('aws-sdk');
const docClient = new AWS.DynamoDB.DocumentClient();
exports.handler = (event, context, callback) => {
let userId = event.userId;
const params = {
TableName: 'users',
FilterExpression : "userId = :val",
ExpressionAttributeValues : {":val" : userId}
};
// 該当するuserIdのデータを取得
docClient.scan(params, function(err, data) {
var user = data.Items[0];
callback(null, user);
})
};
Azure Functionsでは事前に定義したバインドを元にデータの取得が行えます。
バインド定義は以下の手順で設定します。
関数の一覧から統合を選択
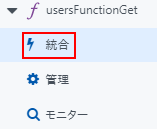
新しい入力を選択

Azure Table Storageを選択し、選択ボタンをクリック
Azure Table Storageの入力バインドの設定画面が表示される。
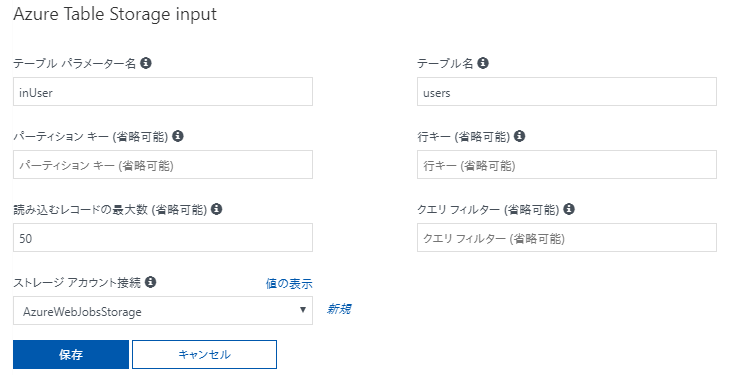
設定値の内容は以下の通り。
- テーブルパラメーター名:プログラムから使用する名称
- テーブル名:取得するテーブルの名称
- パーティションキー:レコードのパーティションキー。
- 行キー:レコードの行キー。
パーティションキーと行キーの組み合わせでレコードを一意にすることが出来る。 - 読み込むレコードの最大数:このバインドを使用してデータを読み込んだ場合に一度に読み込める最大レコード数
- クエリフィルター:パーティションキー、行キーの組み合わせ以外でデータをフィルタリングしたい場合にクエリを設定
- ストレージアカウント接続:Azure Storageへの接続情報を指定。
Azure Functions作成時に指定したストレージアカウントを使用する場合はデフォルトで表示されている接続情報どれでもいいです。
パーティションキー、行キー、クエリフィルターは"{}"を使用することで、トリガーパラメータを代入することが出来ます。
HTTPトリガーの場合は、クエリパラメーター、リクエストのBODY内に指定した値のみ使用可能です。
プログラムソース中で代入する値を変更することは出来ません。
またバインドで指定した代入する値がクエリパラメーター、リクエストのBODY内に指定した値に存在しない場合、HTTP500のエラーとなります。
パーティションキー、行キーの設定例
パーティションキー:User
行キー:{userId}
を設定した場合、パーティションキーが"User"、行キーがuserIdというパラメータの値のレコードを1行取得します。
存在しない場合はnullとなります。
クエリパラメーターの設定例
クエリパラメーター:userName eq {paraName}
を設定した場合、userNameというカラムの値がparaNameというパラメータの値と等しいレコードを読み込むレコードの最大数まで配列で取得します。
存在しない場合は0件の配列となります。
パーティションキー、行キー、クエリパラメーターいずれも設定しない場合、指定テーブルのデータを読み込むレコードの最大数まで配列で取得します。
設定したバインド定義については実体はfunction.jsonというファイルに保存されており、画面内の詳細エディタをクリックすることと参照・修正することが出来ます。
入力バインド定義のみを抜粋
{
"type": "table",
"name": "inUser",
"tableName": "users",
"take": 50,
"connection": "AzureWebJobsStorage",
"direction": "in",
"partitionKey": "User",
"rowKey": "{userId}"
}
バインド定義を使用してデータを取得するサンプルコードは以下の通りになります。
機能としては本項の最初のサンプルコードと同一です。
module.exports = function (context, req) {
var user = context.bindings.inUser;
context.res = {
body = user;
}
context.done();
};
var user = context.bindings.inUser;
バインド定義で設定したデータは引数のcontextのbindingsから参照することが出来ます。
データの追加
LambdaではDynamoDBへデータの追加を行う場合、AWS SDKを使用します。
サンプルコード(usersテーブルに値を追加)
const AWS = require('aws-sdk');
const docClient = new AWS.DynamoDB.DocumentClient()
exports.handler = (event, context, callback) => {
// Userテーブルに保存するデータ
const params = {
TableName: "users",
Item: {
"userId": "User001",
"createdAt": "2017/10/05 16:52:19",
"updatedAt": "2017/10/05 16:52:19",
"userName": "ユーザー001"
}
};
//データの保存処理
docClient.put(params, function(err, data) {
callback(null, "OK");
})
};
Azure Functionsでは事前に定義したバインドを元にデータの追加が行えます。
バインド定義は以下の手順で設定します。
新しい出力を選択

Azure Table Storageを選択し、選択ボタンをクリック
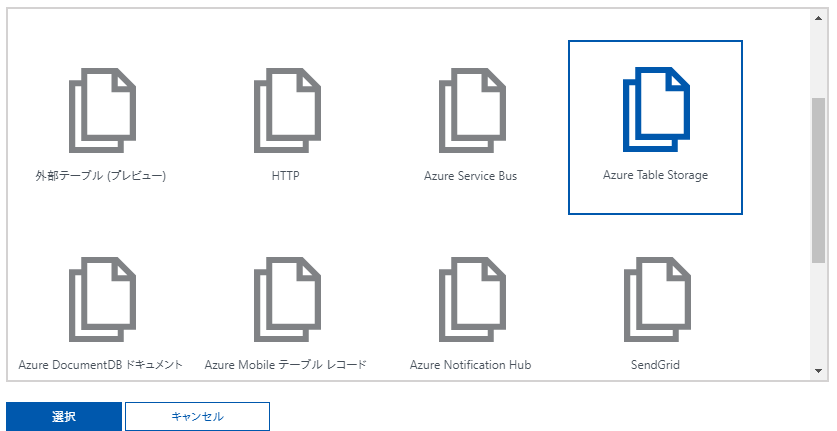
Azure Table Storageの出力バインドの設定画面が表示される。
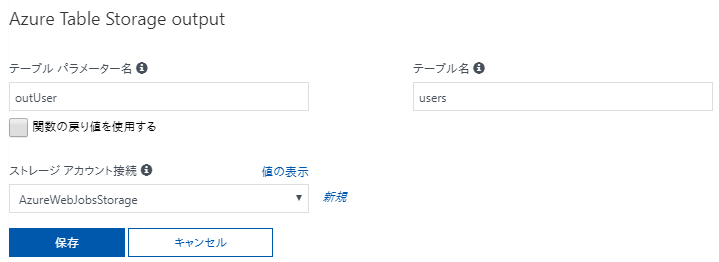
設定値の内容は以下の通り。
- テーブルパラメーター名:プログラムから使用する名称
- テーブル名:データを追加するテーブル名
※存在しないテーブル名を設定した場合、新たにテーブルが作られます。 - ストレージアカウント接続:取得と同様、Azure Storageへの接続情報を指定。
出力バインド定義のみ抜粋
{
"type": "table",
"name": "outUser",
"tableName": "users",
"connection": "AzureWebJobsStorage",
"direction": "out"
}
バインド定義を使用してデータを追加するサンプルコードは以下の通りになります。
機能としては本項の最初のサンプルコードと同一です。
module.exports = function (context, req) {
context.bindings.users = JSON.stringify({
PartitionKey: "User",
RowKey: "User001",
createdAt: "2017/10/05 16:52:19",
updatedAt: "2017/10/05 16:52:19",
userName: "ユーザー001"
});
context.done();
};
context.bindings.outUsers = JSON.stringify({
PartitionKey: "User",
RowKey: "User001",
createdAt: "2017/10/05 16:52:19",
updatedAt: "2017/10/05 16:52:19",
userName: "ユーザー001"
});
バインド定義で設定した項目に追加したい値を設定することにより追加することが出来ます。
context.done();
実際にDBに更新されるタイミングはcontext.doneメソッドを呼び出したタイミングです。
データの更新
LambdaではDynamoDBへデータの更新を行う場合、AWS SDKを使用します。
サンプルコード(usersテーブルの値を更新)
const AWS = require('aws-sdk');
const docClient = new AWS.DynamoDB.DocumentClient();
exports.handler = (event, context, callback) => {
const params = {
TableName: 'users',
Item: {
"userId": "User001",
"createdAt": "2017/10/05 16:52:19",
"updatedAt": "2017/10/05 16:52:19",
"userName": "ユーザー001"
}
};
docClient.put(params, function(err, data) {
callback(null, "OK");
})
};
Azure Functionsでは事前に定義したバインドを元にデータの更新が出来そうなのですが、現状出来ないのでAzure FunctionsもSDKを使用してデータの更新をします。
※更新対象がDocumentDBの場合はバインドを使用してデータの更新が出来るので、今後バージョンアップによりAzure Table Storageでもバインドを使用した更新が出来るようになるかもしれません。
SDKを使用してデータを更新するサンプルコードは以下の通りになります。
機能としては本項の最初のサンプルコードと同一です。
let azure = require('azure-storage');
let connectionString = process.env.AzureWebJobsStorage;
let tableService = azure.createTableService(connectionString);
module.exports = function (context, event) {
let outUsers = {
PartitionKey: "User",
RowKey: "User001",
createdAt: "2017/10/05 16:52:19",
updatedAt: "2017/10/06 09:14:27",
userName: "ユーザー001修正"
};
tableService.replaceEntity('users', outUsers, (error, response) => {
context.res = {
body: { updatedAt: formatDate }
};
context.done();
});
};
let azure = require('azure-storage');
外部ライブラリとしてazure-storageを使用しています。
let connectionString = process.env.AzureWebJobsStorage;
Azure Storageへの接続情報を指定しています。
**process.env.<アプリケーション設定名>**を使用することによりアプリケーション設定の値を取得出来ます。
let tableService = azure.createTableService(connectionString);
取得したAzure Storageへの接続情報を元にTableServiceオブジェクトを作成します。
tableService.replaceEntity('users', outUsers, (error, response) => {
context.res = {
body: { updatedAt: formatDate }
};
context.done();
});
TableServiceオブジェクトのreplaceEntityメソッドを使用してデータの更新を行います。
データの削除
LambdaではDynamoDBへデータの更新を行う場合、AWS SDKを使用します。
サンプルコード(usersテーブルの値を削除)
const AWS = require('aws-sdk');
const docClient = new AWS.DynamoDB.DocumentClient();
exports.handler = (event, context, callback) => {
const params = {
TableName: 'users',
Key:{
"userId": userId
}
};
// ユーザー情報の削除
docClient.delete(params, function(err, data) {
callback(null, {});
});
};
Azure Functionsではバインドを使用した削除は出来ません。
Azure FunctionsもSDKを使用してデータの更新をします。
SDKを使用してデータを更新するサンプルコードは以下の通りになります。
機能としては本項の最初のサンプルコードと同一です。
let azure = require('azure-storage');
let connectionString = process.env.AzureWebJobsStorage;
let tableService = azure.createTableService(connectionString);
module.exports = function (context, req) {
let outUser = {
PartitionKey: "User",
RowKey: "User001"
}
tableService.deleteEntity('users', outUser, (error, response) => {
context.done();
});
};
let azure = require('azure-storage');
let connectionString = process.env.AzureWebJobsStorage;
let tableService = azure.createTableService(connectionString);
ライブラリ読み込み、接続情報取得、TableServiceオブジェクト取得については更新と同様です。
tableService.deleteEntity('users', outUser, (error, response) => {
context.done();
});
TableServiceオブジェクトのdeleteEntityメソッドを使用してデータの削除を行います。
まとめ
LambdaからAzure Functionsへの移行は比較的容易に出来ました。
しかしバインド機能が使える処理使えない処理があるので、早く実装されるといいなと思います。