今回も Google Cloud Data Engineering の記事を書いていきます。
本記事では、BigQuery について記載していきます。

BigQuery
BigQuery はDWHであり、OLAP向けのデータベースです。
BigQueryは非常に多くの機能が存在するため、まずは全体概要から説明します。
Resource Model

データセット
プロジェクトに紐づく、データのロケーション(リージョン、マルチリージョン)を定義します。
また、データセットレベルでアクセス制御を許可出来ます。
テーブル
データセット内に展開され、行列のデータがマネージドのストレージに保存される領域です。指定された値の列を持つスキーマによって定義されます。テーブルレベルと列レベルのアクセス制御を許可します。
ビュー
SQLクエリによって定義される仮想テーブルです。
ビューレベルのアクセス制御を許可します。
ジョブ
ETLや、データコピー、クエリの実行をBigQueryが行うものです。
ジョブは非同期で実行されます。
Authorized View
データセットにアクセス権を設定する場合、BigQuery では承認済みビューを作成します。
承認済みビューを使用すると、元のテーブルへのアクセス権がないユーザーでも、クエリの結果を特定のユーザーやグループと共有できます。
詳細は以下に記載があります。
Storage
BigQuery が提供する機能は BigQueryStorageService と BigQueryQueryService の二つに分かれます。

これらのサービスは Google の内部のネットワークにより接続されます。
ここでは BigQuery Storage Service についての説明をします。
- 保存形式
BigQueryは、OLAPのユースケースであり、各列毎に別々のファイルブロックに保存されます。列毎の保存方式により、データの追加、既存の値を更新または削除ができます。

実際にはCapacitorという独自のカラム型でデータが保存されます。テーブルの各列は別々のファイルブロックに保存され、すべての列は 1 つのCapacitorファイルに保存されます。
BigQuery はクエリのアクセスパターンを使用して、物理シャードの最適な数とデータのエンコード方法を決定します。

- 保存場所
永続的なストレージとして Colossus と呼ばれるファイルシステムによりデータの圧縮、暗号化、複製、分散が内部的に行われます。

BigQuery へデータセットを取り込む際に使用するケースとして Cloud Storage がありますが、BigQuery の費用を最適化する際のベストプラクティスは、データを BigQuery に保持することです。古いデータをCloud Storageにエクスポートするのではなく、BigQuery の長期保存の料金を活用します。
これにより、古いデータの削除や、データのアーカイブ プロセスの設計を行う必要がなくなります。また、データが BigQuery に保持されるため、同じインターフェースを使用して、同じ費用レベル、同じパフォーマンス特性で古いデータをクエリすることもできます。
参考として90 日間連続して編集されていないテーブルやパーティションは長期保存とみなされ、そのテーブルに対するストレージ料金は自動的に約 50% 値引きされ、Cloud Storage Nearline と同じ費用になります。割引は、テーブル単位、パーティション単位で適用され、テーブルのデータを変更すると、90 日のカウンタはリセットされます。
BigQuery Slot and Execution Query
BigQuery スロットはクエリで使用される仮想CPUの事です。
スロットの利用は、オンデマンド料金モデルおよびフラットレート料金モデルのいずれかを選択できます。
オンデマンド料金モデルでは、クエリのサイズと複雑さに応じて、必要なスロットの数が自動的に計算されます。
フラットレート料金モデルとは、予約するスロットの数を明示的に選択し、クエリはその容量内で実行されます。
Big Query のクエリ実行は、メモリで実行されます。
クエリエンジンとして、データの再分配を行うシャッフルを再考した Bigquery shuffleにより、1 行のデータを転送したり、ペタバイト単位のデータをクエリします。
BigQuery shuffleによって定義された、プロデューサーが再パーティション化されるデータを作成し、コンシューマーが再パーティション化されたデータを受け取り、コントローラープロセスがシャッフルを管理する 3 つのエンティティで構成されます。
アーキテクチャはこちらに詳細が細かく記載されています。
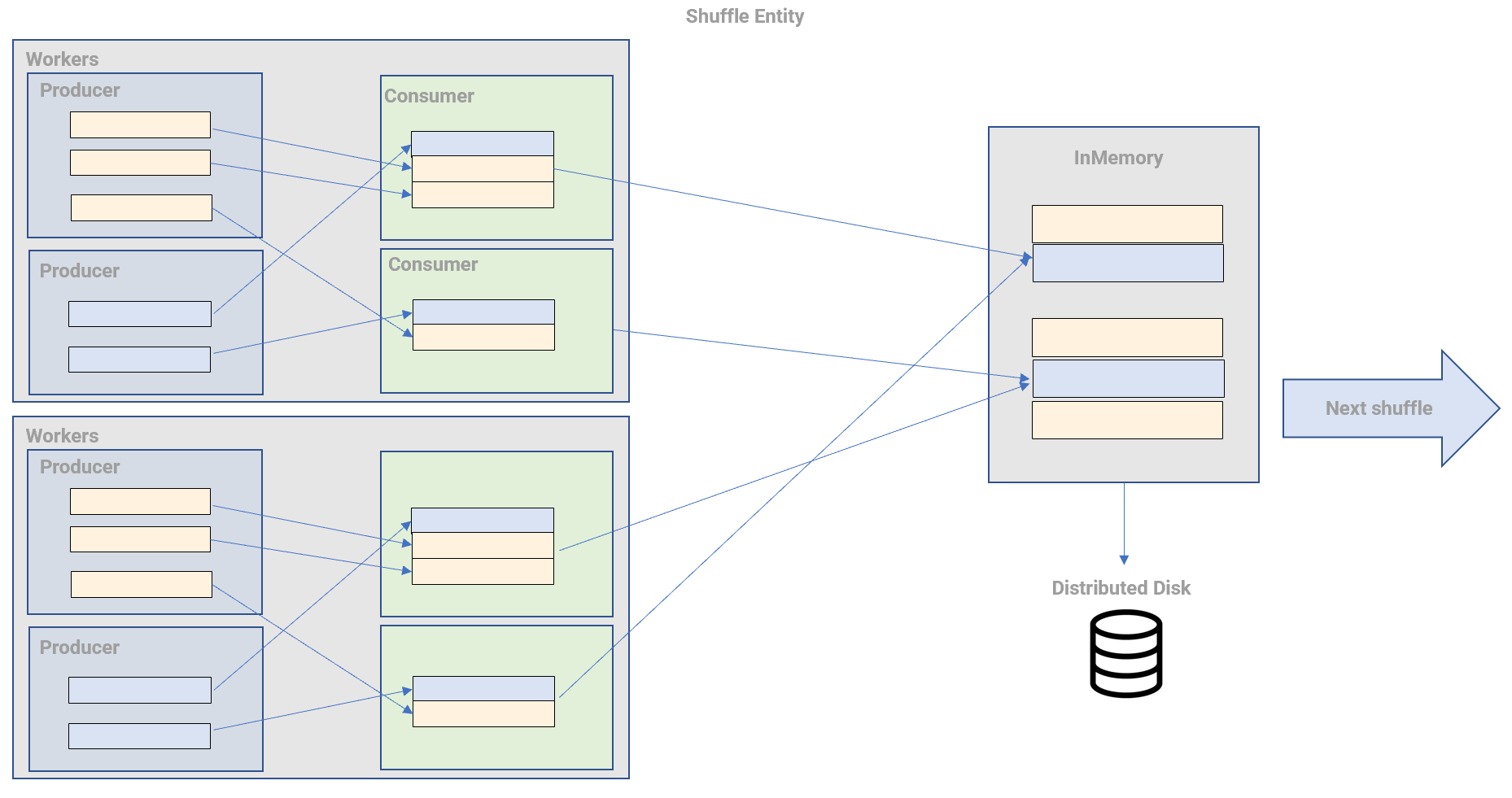
なお、shuffle処理を含んだクエリの処理プロセスは以下となります。
第 1 ステージとして、ワーカーがDistributed Disk にアクセスし、テーブルの読み込みして、フィルタリングや計算を行います。こののち、ワーカーからシャッフルに送信されます。
第 2 ステージでは、シャッフルのレコードを入力として読み込み、それを合計します。その出力ファイルを 1 つのファイルに書き出します。このファイルが、クエリの結果としてアクセスできるファイルになります。

これらのステージの個々の作業単位において、BigQuery スロットが使用されます。
スロットは、同時実行が可能なため、利用可能なスロット数の上限に達した場合でも、実行中のクエリに対してスロットの再割当が行われます。
これは、同時に実行されるクエリが多くなれば、その分、1クエリあたりのスロットが少なくなる事を示します。つまり、スロット数に依存して1クエリあたりの処理時間が遅れるという事になります。
なお、Bigquery では、通常の EXPLAIN (実行計画)を使用出来ません。
クエリプランとタイムラインを参考にクエリ実行の詳細を確認する必要があります。
Execution type
クエリを用途種別に分けてみます。
-
アドホッククエリ
GoogleCloud Console上、または、Cloud Shell、Google CloudのAPI、ODBC ドライバと JDBC ドライバの利用してアプリケーションと統合してBigquery のテーブルに対してクエリを実行できます。
-
GIS機能
地理的な分析を行う際に使用出来る機能です。
BigQuery ML
bqml と呼ばれ、Bigquery に機械学習モデルを作成して実行できます。
(こちらは別の章で記載します。)
-
BigQuery BI Engine
Bigquery に保存されたデータを Looker、Tableau、Power BI などのBIツールと統合して、分析を行えます。
データソースの種別は以下となります。
-
ネイティブデータ
BigQuery ストレージに保存されているデータを示します。クエリ結果をテーブルに書き込むことでデータを生成できます。
-
外部データ、フェデレーションデータ
Google Cloud のストレージサービスをソースとしたデータです。
以下の記事で Cloud SQL とのフェデレーテッドクエリを紹介しました。
-
マルチクラウド データ
AWS や Azure などの複数のクラウド サービスに保存されるデータをソースとする事を示します。
以下の記事にAWSのS3に Data Transfer Service を使用してBigQueryにデータロードする方法を紹介しました。
-
一般公開データセット
マーケットプレイスで入手可能なデータセットを示します。
クエリの種別です。
データを呼び込みしたのち、以下の2つのクエリを実行します。
- Interactive Query
- Batch Query
デフォルトは、BigQuery はインタラクティブクエリ(即時)を実行します。
バッチクエリは、BigQuery REST APIの jobs.queryメソッドまたはクエリ形式の jobs.insertメソッドを呼び出して実行します。
POST https://bigquery.googleapis.com/bigquery/v2/projects/{projectId}/queries
POST https://bigquery.googleapis.com/upload/bigquery/v2/projects/{projectId}/jobs
クエリジョブとAPI
データの呼び出しには以下の方法があります。
- BigQuery REST API の
tabledata.list メソッド/jobs.getQueryResultを利用しデータ取り出しを行うパターン。これらは web UIやCloud SDK などから利用されるもので SQLの結果をHTTPで取得するものです。
GET https://bigquery.googleapis.com/bigquery/v2/projects/{projectId}/datasets/{datasetId}/tables/{tableId}/data
GET https://bigquery.googleapis.com/bigquery/v2/projects/{projectId}/queries/{jobId}
{
"kind": string,
"etag": string,
"totalRows": string,
"pageToken": string,
"rows": [
{
object
}
]
}
-
BigQuery export ジョブを使用して、BigQuery上のデータに対してCSV、JSON、AVRO、Parquetの形式でCloud storageへ、バルク出力(エクスポート)してデータの確認が出来ます。
# from google.cloud import bigquery
# client = bigquery.Client()
# bucket_name = 'my-bucket'
project = "x"
dataset_id = "x"
table_id = "x"
destination_uri = "gs://{}/{}".format(bucket_name, "x.csv")
dataset_ref = bigquery.DatasetReference(project, dataset_id)
table_ref = dataset_ref.table(table_id)
extract_job = client.extract_table(
table_ref,
destination_uri,
# Location must match that of the source table.
location="x",
) # API request
extract_job.result() # Waits for job to complete.
print(
"Exported {}:{}.{} to {}".format(project, dataset_id, table_id, destination_uri)
)
-
BigQuery Storage APIは、 BigQuery Storage Serive へRemote Procedure Callベース(クライアントから関数の呼び出し)を使用してクエリを実行するものです。
大量データ処理を高速で取得するため、リアルタイムストリーミング処理に向いています。
BigQuery Storage API は、以下の4点の機能を保持します。
Multiple Streams
同一セッション内で複数のストリームを保持する事が可能で、読み取るテーブルの行を重複させない事を保証しています。これにより、分散処理フレームワーク上の複数の読み込みにおいて読み込みの高速性を保持します。
Dynamic Sharding
Stream を複数作成する際に、各Streamに対するデータの割り当てをBigQuery側が自動的に行なってくれます。読み取りする複数のクライアントがあった場合には、処理の遅いクライアントのStreamへの読み取りは自動的に減らす事が可能です。
Column Projection
データを取得する時に必要なカラムだけを取得できます。
それによって、テーブル全体を取得する場合と比較して高速にデータの読み取りを行うことができます。
Column Filtering
SQLのWHERE句等をデータ取り出しのタイミングでフィルタリングできます。
Snapshot Consistency
セッションを作った時点でのテーブルのスナップショットが保持されるため、セッションを通したスナップショットが有効となります。また、以前のスナップショットからデータを読み取ることができます。
以下は、bqstorage_client 引数を指定して to_dataframe メソッドを呼び出し、BigQuery Storage API を使用して行をダウンロードします。
from google.cloud import bigquery
bqclient = bigquery.Client()
# Download a table.
table = bigquery.TableReference.from_string(
"bigquery-public-data.utility_us.country_code_iso"
)
rows = bqclient.list_rows(
table,
selected_fields=[
bigquery.SchemaField("country_name", "STRING"),
bigquery.SchemaField("fips_code", "STRING"),
],
)
dataframe = rows.to_dataframe(
# Optionally, explicitly request to use the BigQuery Storage API. As of
# google-cloud-bigquery version 1.26.0 and above, the BigQuery Storage
# API is used by default.
create_bqstorage_client=True,
)
print(dataframe.head())
次回は引き続き Bigquery について、スキーマ設計、SQLの高度なオプションの説明、クラスタリング、パーティショニング、GIS等を説明したいと思います。