はじめに
本ページは以下の内容を翻訳・まとめたものになります。
https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues
何があったのか
- 8月から9月上旬にかけて、Claudeの応答品質を低下させる事象が発生。現在ではすべて解決している
- 原因はインフラ関連の不具合が3つあった
経緯
- 8月上旬、複数のユーザーからClaudeの応答品質が下がっているという報告が寄せられていた。しかし通常のユーザーフィードバックとは区別がつきにくかった
- 8月下旬、報告件数の増加と事象が持続していることから調査を開始した
原因
- コンテキストウィンドウのルーティングエラー
- 出力データの破損
- TPUコンパイラの潜在バグ誘発
下記の画像は以下の上記三つの減少の発生時期を示したもの。※出典より引用
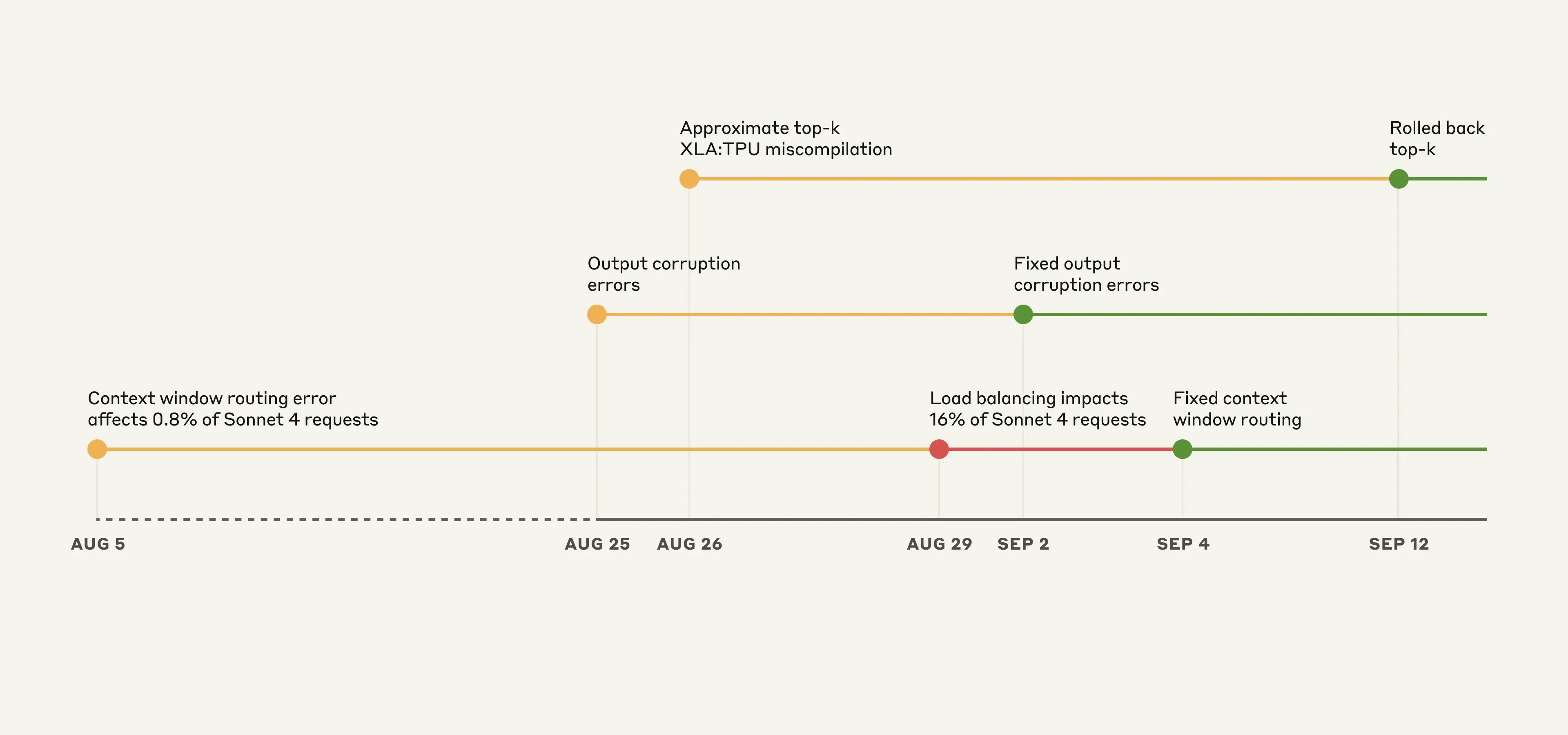
コンテキストウィンドウのルーティングエラー
事象
- Sonnet4リクエストの一部が、導入予定だった100万トークンコンテキストウィンドウ対応サーバーに誤って振り分けられた。
- スティッキーなルーティング方式を採用していたため、一部のユーザーは一度誤ったサーバーに割り振られると同じサーバーで処理された
影響範囲
- Sonnet 4リクエストの16%が影響を受けた。
- この期間中にClaude Codeを利用したユーザーの約30%で品質低下が発生
- サードパーティープラットフォーム(Bedrock, Vertex AI)でも軽微ではあるが発生
対応内容
- 要求されたコンテキストの長さに応じて適切なサーバープールに振り分けられるようルーティングロジックを修正を実装し各プラットフォームへ展開。
出力データの破損
事象
- Claude APIのTPUサーバーに設定ミスによる誤動作によって、トークン生成時にエラーが発生する問題が発生. これにより文脈上ほとんど発生しないはずのトークンに高い確率が割り当てられることがあった。具体的な例は以下。
- 英語のプロンプトに対して異なる言語(タイ語, 中国)が出力
- コード内に明らかな構文エラーがある状態で出力
影響範囲
- Opus 4.1、Opus 4、Sonnet 4へのリクエストにて発生。
- サードパーティプラットフォームは影響なし。
対応内容
- 該当の変更をロールバック。
- 再発防止策として、デプロイプロセスに予期しない文字出力を検出するためのテストを追加
TPUコンパイラの潜在バグ誘発
事象
- トークン選択方法を改善する実装内容をデプロイしていたことにより、XLA:TPUコンパイラに潜在していたバグが誘発された。これによりごくまれに不正確なトークン選択が発生し応答品質が低下。
影響範囲
- Claude Haiku 3.5へのリクエスト。Claude APIのSonnet 4 およびOpus 3の一部バージョンにも影響を及ぼした可能性。
- サードパーティプラットフォームは影響なし。
対応内容
- Haiku, Sonnet 4 , Opus 3の三つでロールバックした。Sonnet 4 では再現が見られなかったが念のため実施した。
- 根本対応としてXLA: TPUチーム連携してコンパイラのバグ修正に着手。精度向上したExact top-k方式を導入。
XLAコンパイラのバグに関して
前提
-
XLAとは
- (おそらく)機械学習向けのオープンソースコンパイラで、低レベルでの計算グラフの最適化により機械学習モデルの性能を向上させるように設計されている。大規模計算・高性能な機械学習モデルをを利用するときに利用する。
- Claudeテキスト生成アルゴリズムと分散環境における課題
- Claudeのテキスト生成時には際には各単語の出現確率を計算し、確率分布からランダムに選択する。このときtop-kサンプリング(累積確率が一定の閾値異常に達する単語のみを考慮する)という手法によって意味のない出力を防いでいる。
- しかしTPU環境ではモデルが複数のチップに分散して動作しているため、各チップで行われている確率値の計算・ソートを適切に行うためには、チップ間でデータを同期させる必要がある。
- 本事象とは別件で、TPU実装においてtempertureが0の場合に最も確率の高いトークンが時折消失する問題が発生していた。これはモデルとTPUの計算精度が不一致であったために発生しており、一時的な回避策を実装していた。
- 具体的にはモデルが16bit浮動小数点だったが、TPUコンパイラ側は最適化のためにfp32で計算を行っている&デフォルトでは有効に設定されていた。
詳細
- 上述した問題の根本的な精度計算を解決する修正を行い、回避策を削除した。これによりXLAコンパイラの潜在バグである近似top-k演算のバグが発覚した。
- 最終的な解決策として、性能最適化機能であった**「近似top-k」の使用を停止。計算の正確性が担保される「厳密なtop-k(Exact top-k)」**に切り替えることで問題を恒久的に解決.
なぜ検出が遅れたか
以下三点であると記述されている
- 従来の評価システムの限界
- 複数の要因による複雑化
- プライバシー保護とのジレンマ
-
従来の評価システムの限界
- 評価テストの不十分さ: 従来の評価テストでは、ユーザーが報告していた微妙な応答品質の低下を正確に捉えることができなかった。
- モデルの「回復力」: Claudeには個別のエラーから迅速に回復する特性があったため、評価テストをすり抜けてしまう一因となった。
- ノイズの多い評価への過度な依存: ユーザーからの否定的な報告は認識していたものの、その報告と直近のデプロイとの明確な関連付けができなかった。
-
複数の要因による複雑化
- 症状の多様性: 3つのバグが異なるプラットフォームで、異なる頻度で、異なる症状を引き起こしたため、報告内容が混乱し、原因が単一ではないことが判明するまで時間を要した。「ランダムで一貫性のない性能低下」に見えたため、エンジニアが単一の根本原因を特定することが非常に困難だった。
-
プライバシー保護とのジレンマ
- 調査の制約: Anthropic社の厳格なプライバシーおよびセキュリティ管理方針により、エンジニアがユーザーの対話ログにアクセスすることが厳しく制限されている。これはユーザーのプライバシー保護には不可欠だが、バグの特定や再現に必要な証拠へのアクセスを妨げ、問題解決の遅延につながった。
バグ検出・評価の変更
今後の改善のために以下三点を実行したと記述
- より精度の高い評価手法の導入: 特定の問題の根本原因を特定するため、正常に動作している実装と不具合のある実装をより確実に区別できる評価手法を開発した。
- 品質評価の強化: Anthropic社ではシステムの定期的な評価を実施しているが、今後は本番環境と同様の環境で継続的に評価を行い、コンテキストウィンドウの負荷分散エラーのような問題を早期に検出できるようする。
- 迅速なデバッグ環境の整備: ユーザーのプライバシーを損なうことなく、コミュニティから寄せられるフィードバックをより効果的に分析・デバッグするためのインフラストラクチャとツールを開発する。さらに、ここで開発した専用ツールを活用することで、同様の問題が発生した場合の対応時間を短縮できるようにする。
ユーザーに求めること
- ユーザーからの継続的なフィードバックが不可欠である。
- 具体的な変更点の報告、予期しない動作の事例、および異なる使用ケースにおけるパターンの分析が、問題の特定に寄与した。
- 不具合の報告は以下の方法で行うことができる
- Claude Code:
/bugコマンドを実行 - Claudeアプリでは「よくないね」ボタンを押下
- Claude Code:
感想
- 大規模AIサービスならではの課題が明確になったように見える。特にプライバシーを保護しつつデバックする方法は基盤モデルプラットフォーマーが開発してくれたら、結構いろんなユーザーに価値がありそうな気がする。
- 時系列で何が起こったのかがありわかりやすかった。
- XLAコンパイラの不具合は、当初露見していたバグに対する回避策が潜在的なバグの蓋をしていたという内容で、技術的な教訓として非常に価値があると思う
- 本当は近似top-kのバグであったが、当初はtop-pの精度不一致を議論していた可能性?
- 一部ソースコードを公開しており誠実さを感じる。(一般的には機密情報だと思うので)