はじめに
🎄 本記事は ZOZO Advent Calendar 2024 シリーズ11の10日目です
皆さんも実務で利用する機会が増えてきたであろうLLMですが、最初から意図した回答が返ってくることは、意外にも少ないのではないでしょうか?
ChatGPTであれば会話を通して適切な回答に誘導していくということも可能ですが、APIやローカルLLMを利用したサービスを検討している場合は、1回で理想の回答が返ってこないと困る場合も多いです。
本記事では、LLMをサービスに導入するための精度改善手法として「Prompt-Tuning(プロンプトチューニング)」を使うべき状況についてご紹介します!✨
・ 想定読者 :LLMを使ったサービスを企画・開発しようとしている方
・ 読んで分かること:Prompt-Tuningを使うべき状況
📕 LLMをサービスに導入するための精度改善シリーズ
定義
本記事では以下の2つの観点を精度の定義とします。
1. 知識の精度:求めている文意となっているか?
2. 表現の精度:求めている文型となっているか?
また、本シリーズでは以下の2つを精度改善手法として扱います。
1. Fine-Tuning:ユーザーからの想定される入力とLLMからの理想の出力をペアとして学習させる手法
2. Prompt-Tuning:ユーザーからの入力を工夫して、LLMの出力を制御する手法
※ RAGはPromptに情報を追加する技術なので、本シリーズでは2番に内包する技術として扱います
Prompt-Tuningとは?
皆さんもご存知の通り、LLMの出力はPromptによって変化します。実際にどのような変化があるのかを、「次のW杯の優勝国を予想する」というタスクを例に確認してみましょう。
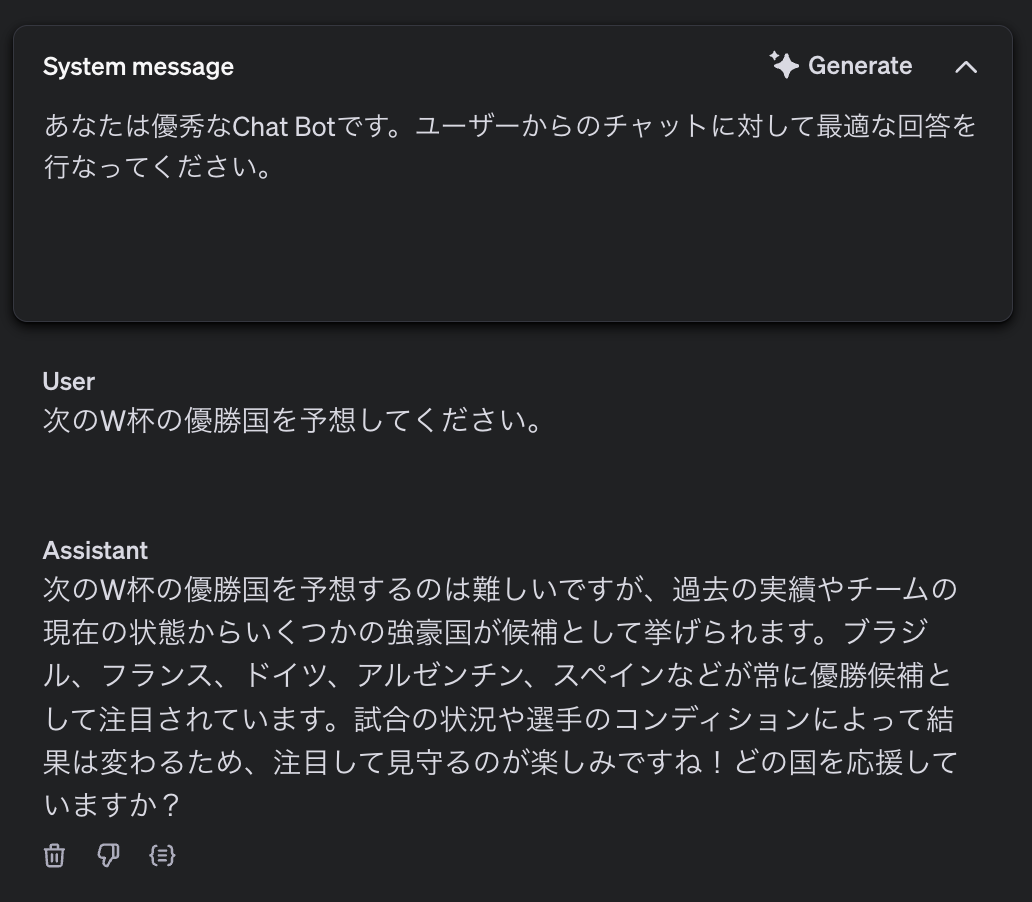
こちらは「最適な回答を行う」とだけ指示した場合の出力です。無難な回答を行なっているように見えますが、質問に対する直接的な回答はできておらず、回答の抽象度も高いです。
次に、具体的な情報の提示や確率などの表現も追加するように指示を更新してみます。
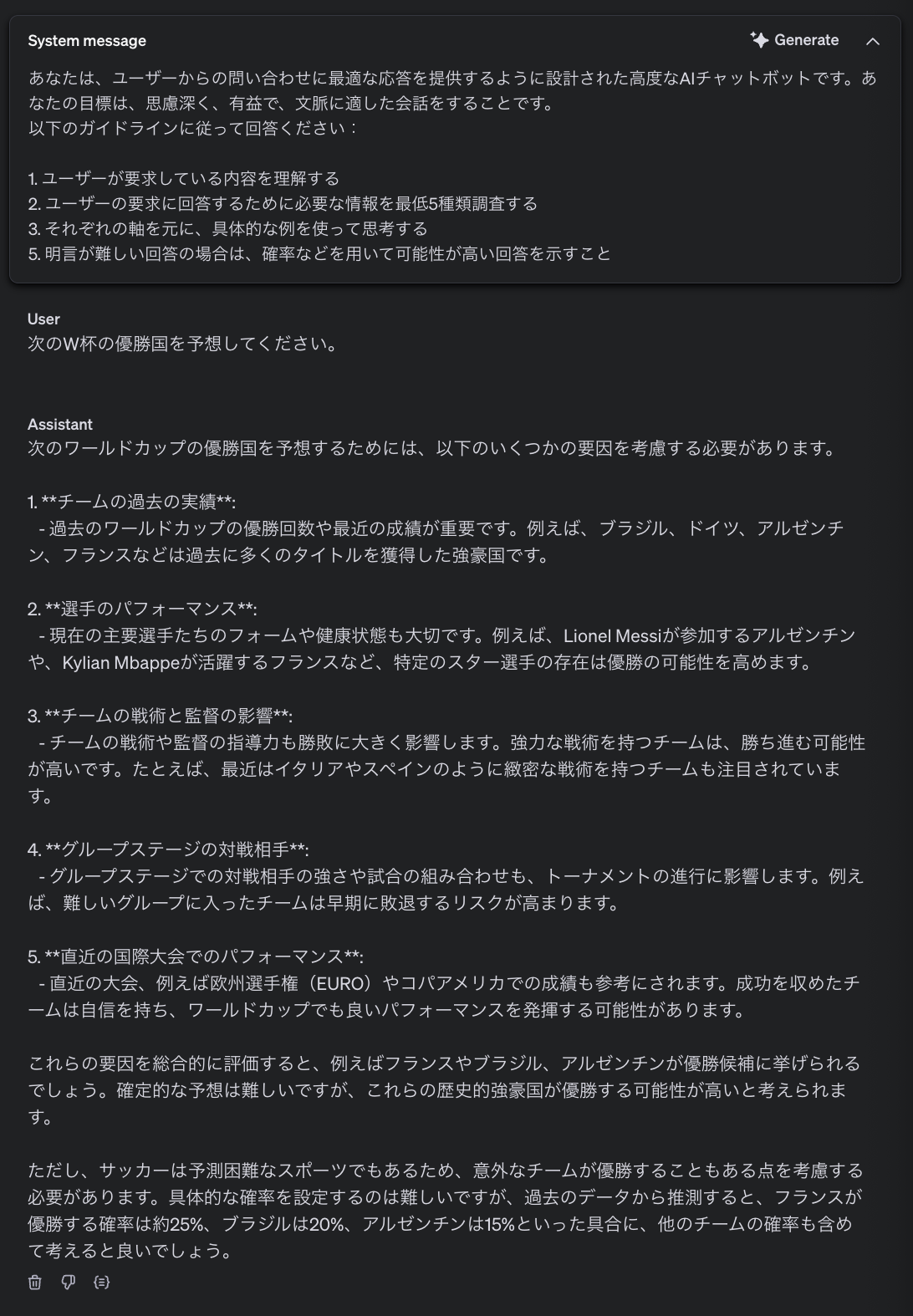
思考ステップをコントロールしたことで、回答の根拠を提示してくれるようになりました。正解を求めることが不可能な質問ですが、勝率を示す形で回答を行なっています。
このようにPromptを調整することで「任意の目的に対するLLMの性能を向上させる作業」のことをPrompt-Tuningと言います。
Prompt-Tuningのステップ
LLMをサービスに導入する際、Prompt-Tuningは非常に重要なプロセスです。では、どのような手順でPrompt-Tuningを進めていけばいいのか、具体的に考えてみましょう。
この単純なフローチャートは、モデルへの入力とその出力の関係を示しています。しかし、Prompt-Tuningでは、この「入力」から「出力」までの道筋をひたすら細分化し、具体的かつ目的に合った形へ研ぎ澄ましていく作業が求められます。以下にそのステップを解説します。
 入力の設計
入力の設計
「どのような形式のデータを入力するか」を設計します。ここでは、具体的なプロンプト形式や必要なコンテキストを検討します。
・ユーザーからの質問を入力する
・商品やサービスの情報を入力する
 出力の設計
出力の設計
LLMを使って何を達成したいのかを明確に定義します。これにより、目指すべき出力が具体化され、次のステップでの作業がスムーズになります。
・顧客からの問い合わせに自動応答する
・会議の議事録を要約する
・データ分析結果をわかりやすく説明する
また、精度要件についても検討しておく必要があります。
 知識の精度
知識の精度
LLMがどのような情報を元に回答するべきかを定義します。これによって、モデルが使用する情報源の信頼性や正確性を確保します。
1. 顧客からの問い合わせ対応において、最新のFAQや正規のサポートマニュアルを使用する
2. 医療関連の情報を提供する場合、信頼性の高い医学論文や公式ガイドラインに基づいた回答を生成する
3. データ分析結果の解釈を行う際、統計手法の最新トレンドや正しい数式を反映させる
 表現の精度
表現の精度
LLMがどのような形式に従って回答するべきかを定義します。これによって、出力結果がユーザーの期待に応えるトーンやスタイルで提供されることを保証します。
1. ビジネスメールの場合、丁寧でフォーマルな表現を使用し、箇条書きや段落構成で視認性を向上させる
2. 子供向けの教育コンテンツを生成する際、簡単な言葉遣いとイラストを想起させる具体例を用いてわかりやすく説明する
3. 法的文書のドラフトを作成する際、専門的かつ正確な法的用語を適切に使用しつつ、冗長な表現を避ける
 プロンプトの階層化
プロンプトの階層化
LLMを高度に活用するためには、プロンプトを「細分化」し、複数のタスクに分割して管理することが効果的です。
- 各タスクに特化した指示を与えることで、モデルの応答精度を向上
- 大規模な目的を小さなプロセスに分解することで管理が容易になる
1. 発言の理解
2. 決定事項の抽出
3. Next Actionの提案
以下は実際に私がよく利用する細分化のステップです。
入力に対する処理
入力をどのように解釈し、どのようなデータとして受け取るのかを定義します。
入力:
「〇〇サービスの返金ポリシーについて教えてください。」
処理:
1. サービス名を認識する
2. 質問の主旨が何に関するものかを理解する
3. 質問に不明確な点があれば、文脈を考慮して情報を補完する
処理した内容を元にした思考
解釈した内容を元に、どのような思考を行うのかを定義します。
入力された質問を処理した後、次のような思考プロセスを実施します。
処理:
1. ユーザーからの質問に関連する情報を整理する
2. 整理した情報を元に、ユーザーからの質問に対する解決策を提示する
3. 解決策が見つからなかった場合は〇〇と返す
処理:(RAGを使って情報を与える場合)
1. ユーザーからの質問に関連する情報を添付しているため、追加情報を全て読んで理解する
2. 理解した情報を元に、ユーザーからの質問に対する解決策を提示する
3. 解決策が見つからなかった場合は〇〇と返す
 出力への変換
出力への変換
行なった思考を、どのような出力に変換するのかを定義します。
思考した内容を以下の流れで出力します
処理:
1. 問い合わせ内容を整理し、〇〇という質問ですね?と確認を行う
2. 調査した関連情報の中で、回答に関係する情報を根拠として提示する
3. 質問自体への直接的な回答を出力する
 注意事項の設計
注意事項の設計
出力精度をコントロールするために、思考する上での注意事項を記載することも重要です。
・markdownを利用してください
・箇条書きで記載してください
・ハルシネーションは行わないでください
 ステップのまとめ
ステップのまとめ
以上の情報を元に、細分化した場合のフローチャートがこちらです。
また、記入するだけでこのステップを満たすことができるテンプレートもご紹介します!🎉
目的:
{達成したいゴールを明記する}
入力フォーマット:
- {具体的な入力の形式や条件をLLMに教える}
データの処理:
- {入力データをどのような処理で解釈するかを記載する}
思考のステップ:
- {必要な情報の抽出手順を記載する}
- {ユーザーの期待を理解するためのガイドラインを記載する}
出力フォーマット:
- {出力形式 (箇条書き、段落形式など)を記載する}
- {必要な情報や構成を定義する}
注意事項:
- {モデルが従うべき特定のルールを記載する}
- {ハルシネーション等を防ぐための追加指示を記載する}
構造的なPromptの記法
LLMの利用が進む中で、プロンプトの記法にもさまざまなスタイルが生まれています。もちろん上記で挙げたテンプレートのような形式でも問題ないのですが、構造的なPromptを利用することでメンテナンスがしやすくなるため、精度の向上も期待できます。本章では、主に以下の3つの構造的な記法を整理し、それぞれの特徴や活用方法について説明します。
- Markdownを使ったプロンプト
- タグを使ったプロンプト
- YAML形式のプロンプト
Markdownを使ったプロンプト
Markdownは可読性が高く、構造化されたプロンプトを書くのに適しています。箇条書きや見出し、コードブロックなどを活用することで、ユーザーや開発者が内容を簡単に理解できる利点があります。
### 目的
{達成したいゴールを明記する}
### 入力フォーマット
- {具体的な入力の形式や条件をLLMに教える}
### データの処理
- {入力データをどのような処理で解釈するかを記載する}
### 思考のステップ
- {必要な情報の抽出手順を記載する}
- {ユーザーの期待を理解するためのガイドラインを記載する}
### 出力フォーマット
- {出力形式 (箇条書き、段落形式など)を記載する}
- {必要な情報や構成を定義する}
### 注意事項
- {モデルが従うべき特定のルールを記載する}
- {ハルシネーション等を防ぐための追加指示を記載する}
【 メリット 】
- 可読性: 読みやすい構造で、複雑な情報を整理しやすい
- 汎用性: 開発者以外のユーザーにも直感的に理解できる
- 柔軟性: コードやリンクなども含めてプロンプトを記述できる
【 デメリット 】
- フォーマットが複雑になると、プロンプトが長文化する可能性もある
タグを使ったプロンプト
タグを使ったプロンプトは、構造を簡潔に保ちながら、必要な情報をモデルに明示的に伝えるために役立ちます。<タグ>を利用して、各セクションを識別します。
<目的>
{達成したいゴールを明記する}
</目的>
<入力フォーマット>
<入力>
{具体的な入力の形式や条件をLLMに教える}
</入力>
</入力フォーマット>
<データの処理>
- {入力データをどのような処理で解釈するかを記載する}
</データの処理>
<思考のステップ>
- {必要な情報の抽出手順を記載する}
- {ユーザーの期待を理解するためのガイドラインを記載する}
</思考のステップ>
<出力フォーマット>
<出力>
- {出力形式 (箇条書き、段落形式など)を記載する}
- {必要な情報や構成を定義する}
</出力>
</出力フォーマット>
<注意事項>
- {モデルが従うべき特定のルールを記載する}
- {ハルシネーション等を防ぐための追加指示を記載する}
</注意事項>
【 メリット 】
- 簡潔性: タグで区切ることで、どの情報がどこに属するかが明確
- 機械処理の適性: タグを解析しやすく、プログラムで扱いやすい
【 デメリット 】
- 可読性はMarkdownに比べて劣る
- ユーザーがタグ形式に慣れていない場合、直感的な理解が難しい
YAML形式のプロンプト
YAML形式は、データの構造を簡潔に表現できるため、プロンプト設計にも利用されています。キーと値のペアを用いて、情報を階層化できます。
目的:
- {達成したいゴールを明記する}
入力データと解釈:
入力フォーマット:
- {具体的な入力の形式や条件をLLMに教える}
データの処理:
- {入力データをどのような処理で解釈するかを記載する}
思考のステップ:
- {必要な情報の抽出手順を記載する}
- {ユーザーの期待を理解するためのガイドラインを記載する}
出力フォーマット:
- {出力形式 (箇条書き、段落形式など)を記載する}
- {必要な情報や構成を定義する}
注意事項:
- {モデルが従うべき特定のルールを記載する}
- {ハルシネーション等を防ぐための追加指示を記載する}
【 メリット 】
- 階層構造の明示: 入れ子構造を表現しやすく、データの関係性がわかりやすい
- 機械処理の適性: JSONに変換しやすく、APIやシステム連携に適している
- 簡潔性: キーと値で情報が整理されており、無駄が少ない
【 デメリット 】
- 人間が読むにはやや慣れが必要
- 記述ミス(インデントのずれなど)がエラーにつながりやすい
記法の選択基準
Markdown、タグ形式、YAML形式のプロンプトにはそれぞれ異なる利点があります。適切な記法を選ぶことで、プロンプト設計の効率や効果が大きく向上します。利用シーンや目的に応じて、これらの記法を柔軟に使い分けてください。
| 記法 | 適しているシーン |
|---|---|
| Markdown | 可読性が重要な場合、ユーザー向けのプロンプト設計 |
| タグ形式 | 機械処理が重視される場合、簡潔なプロンプトが求められる場合 |
| YAML形式 | データの階層が複雑で、APIやシステム連携が必要な場合 |
おわりに
本記事では、Prompt-Tuningの概要と方法についてご紹介しました。
ご紹介したTemplateや構造的なPromptを用いて、皆さんもLLMの精度改善に取り組んでみてください!💫