その1↑の続きです。
今回は構成で言うと下記の部分を実装します。
数字だと1~3の部分です。

- PCからS3に手動で動画をアップロード
- S3への動画ファイルのアップロードをトリガーにLambdaを実行
- Lambdaで動画ファイルを音声ファイルに変換してS3の別のバケットに保存
- S3への音声ファイルのアップロードをトリガーにTranscribeを実行
- Transcribeで音声ファイルをテキストファイルに変換してS3の別のバケットに保存
- S3へのテキストファイルのアップロードをトリガーに別のAIツールを用いてテキストファイルを要約する(予定)
ffmpegのファイルを準備する
今回動画ファイルからの音声抽出にはffmpegという動画編集アプリを使います。
こちらをLambda関数に実装していきます。
https://ffmpeg.org/
実装には↓を参考にさせていただきました。
ファイルの作成方法
下記URLにアクセスして.tar.xzファイルをローカルにダウンロードします。
https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-amd64-static.tar.xz
ローカルでffmpegが含まれたZIPファイルを作成します。
下記が参考のコマンドとなります。
$ tar xvf ffmpeg-release-amd64-static.tar.xz
$ mkdir -p ffmpeg/bin
$ cp ffmpeg-6.0-amd64-static/ffmpeg ffmpeg/bin/
$ cd ffmpeg
$ zip -r ../ffmpeg.zip .
"ffmpeg-6.0-amd64-static"についてはバージョンによって異なるためダウンロードした時のバージョンに変更してください。
これにてffmpeg.zipファイルが出来たはずなのでこの後作成するS3バケットに保存しましょう。
S3の設定
やることは下記のです。
ただイベント通知についてはLambda関数で設定するのでそちらで行います。
- バケットを作る
- ffmpeg.zipを保存する
- イベント通知を設定する(Lambda関数の設定時に行う)
バケットを作る
下記の3つバケットを作りましょう。
- 動画ファイルを保存するバケット
- 音声ファイルを保存するバケット
- Lambdaレイヤーが参照する用のバケット
動画ファイルと音声ファイルを保存するバケットについては説明は不要だと思いますのでLambdaレイヤーが参照する用のバケットについて説明します。
今回ffmpegという動画ファイル変換ソフトを使うのですがこちらをLambda関数に実装するためにはLambdaレイヤーを使う必要があります。
ffmpegのファイルが約30MBあるため、直接LambdaレイヤーにアップロードするのではなくS3から参照する方法が望ましいのでffmpegのファイルの保存先のバケットとなります。
それぞれのバケット名は下記のように設定したとして話を進めます。
バケット名だけ決めてあとは全てデフォルト設定で問題ありません。
video-20230402
audio-20230402
lambda-layer-20230402
ffmpeg.zipを保存する
先ほど作成したffmpeg.zipをlambda-layer-20230402にアップロードしましょう。
Lambda関数の設定
やることは下記です。(順番に特にこだわりはありません。)
- Lambdaレイヤーの設定
- Lamda関数のためのIAMポリシーの作成
- Lambda関数の作成
- トリガーの設定
- その他の設定
- コードの記述
Lambdaレイヤーの設定
Lambdaのページに移動してレイヤーを作成しましょう。
- python3.9にて実装
- S3のリンクURLはffmpegのオブジェクトURLをコピーしましょう。
- アーキテクチャとランタイムはLambda関数と合わせましょう。(オプション)

作成をクリックしたらレイヤーが作成されたことを確認しましょう。
Lamda関数のためのIAMロールの作成
S3への操作が必要なため必要な権限をアタッチしたIAMポリシーを作成しましょう。
下記のJSONを含めたIAMポリシーを作成しましょう。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::video-20230402",
"arn:aws:s3:::video-20230402/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::audio-20230402/*"
]
},
{
"Effect": "Allow",
"Action": "lambda:InvokeFunction",
"Resource": "<Lambda関数のARNを入れましょう>"
}
]
}
Lambda関数の作成
Lamda関数を作成しましょう。
- ランタイム、アーキテクチャはLambdaレイヤーで設定したものと合わせましょう
- "実行ロールは基本的なLambdaアクセス権限で新しいロールを作成"を選択

lambda関数の作成が終わったら実行ロールに移動して先ほど作成したポリシーをアタッチしましょう。

トリガーの設定
[設定]→[トリガー]よりS3に動画ファイルがアップロードされたら実行されるトリガーを追加しましょう。

その他の設定
Lambdaレイヤーの追加
作成したLambda関数にLambdaレイヤーを追加しましょう。

一般設定
[設定]→[一般設定]よりメモリやタイムアウト時間を変更しましょう。
動画ファイルの処理となるためメモリ2048MB、タイムアウト5分で設定してます。

環境変数の編集
コード内にて環境変数を使用しているため[設定]→[環境変数]より環境変数を追加しましょう。

コードの記述
コードは試行錯誤の結果下記のようになりました。
import boto3
import json
import os
import subprocess
from tempfile import TemporaryDirectory
from io import BytesIO
from urllib.parse import unquote_plus
print("Contents of /opt/bin directory:")
print(os.listdir('/opt/bin'))
def lambda_handler(event, context):
print("Received event:", json.dumps(event, indent=2))
# Add /opt to PATH
os.environ['PATH'] = f"{os.environ['PATH']}:/opt"
s3 = boto3.client('s3')
# Input and output bucket names
input_bucket = os.environ['INPUT_BUCKET']
output_bucket = os.environ['OUTPUT_BUCKET']
# Get the input video file from S3
encoded_key = event['Records'][0]['s3']['object']['key']
key = unquote_plus(encoded_key)
print(f"Attempting to get S3 object with key: {key}")
with TemporaryDirectory() as tempdir:
output_file = os.path.join(tempdir, 'output_audio.mp3')
# Download the video file from S3 as streaming bytes
response = s3.get_object(Bucket=input_bucket, Key=key)
input_stream = response['Body']
# Extract audio from video using FFmpeg
# Extract audio from video using FFmpeg
command = f'/opt/bin/ffmpeg -i pipe:0 -vn -acodec mp3 -f mp3 pipe:1'
process = subprocess.Popen(command, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True)
output_data, stderr_data = process.communicate(input=input_stream.read())
# If an error occurs during the FFmpeg execution, log the error message
if process.returncode != 0:
print(f"FFmpeg error: {stderr_data.decode('utf-8')}")
else:
print(f"FFmpeg output: {stderr_data.decode('utf-8')}")
# Upload the extracted audio to S3
output_key = f'{os.path.splitext(key)[0]}.mp3'
s3.put_object(Bucket=output_bucket, Key=output_key, Body=BytesIO(output_data))
return {
'statusCode': 200,
'body': 'Audio extracted and uploaded to S3'
}
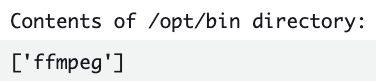
print文はトラブルシュート用です。
print("Contents of /opt/bin directory:")
print(os.listdir('/opt/bin'))
上記二つはffmpeg.zipのファイルが問題なく読み込めているかの確認
print("Received event:", json.dumps(event, indent=2))
上記はアップロードのイベントが読み込めているかの確認
print(f"Attempting to get S3 object with key: {key}")
上記はアップロードした動画ファイルが問題なく読み込めているかの確認
print(f"FFmpeg error: {stderr_data.decode('utf-8')}")
print(f"FFmpeg output: {stderr_data.decode('utf-8')}")
上記はffmpegの処理がうまくいったかどうかの確認
環境変数を導入しているため上記で環境変数を追加していない場合には追加しましょう。
結果
成功した場合に上記のprint文でどのように表示されるのかを添付します。


課題
https://ffmpeg.org/general.html
上記によると様々な動画ファイルのフォーマットに対応していることがわかる。
上記のLambda関数ではmp4, avi, movについては実施済み。
movについては上記Documentationを見る限り対応してそうだがLamda関数上ではエラーとなる。
直接音声に変換するのではなく一旦mp4などに変換してから音声に変換する方法があるかも。
次回
↑その3
次回は4~5を実装予定
最後までご覧いただきありがとうございました。

- PCからS3に手動で動画をアップロード
- S3への動画ファイルのアップロードをトリガーにLambdaを実行
- Lambdaで動画ファイルを音声ファイルに変換してS3の別のバケットに保存
- S3への音声ファイルのアップロードをトリガーにTranscribeを実行
- Transcribeで音声ファイルをテキストファイルに変換してS3の別のバケットに保存
- S3へのテキストファイルのアップロードをトリガーに別のAIツールを用いてテキストファイルを要約する(予定)