S3バッチオペレーションについて使い方や使う場合がわからなかったので調べました。
自分の気になった点のみ記載しているので詳しく知りたい方は公式ドキュメント及び記事内のURLを参照。
[目次]
・できること
・設定方法
・料金
・その他
・個人的Q&A
[用語]
・ジョブ
S3バッチの基本単位。どのオブジェクトをバッチ処理するか、処理の方法などの設定が含まれている。
・オペレーション
処理の方法。Lambdaを呼び出すのかタグを置き換えるのか、削除するのか等。
できること
オブジェクトやタグの処理を一括して処理したい時に使う。大量のオブジェクトも素早く処理。
具体的には
- Lambda関数の呼び出し
- 全てのオブジェクトタグを置換する
- 全てのオブジェクトタグを削除する
- ACLを置換する
- オブジェクトの復元
- オブジェクトロックの保持
- オブジェクトロックのリーガルホールド
それぞれのオペレーションには個別のIAMロールやアクセス許可が必要となります。具体的にはLambdaを呼び出す場合にはLambdaに"s3:GetObject"等が必要で、オブジェクトのタグを置換する場合にはアクセス権限として[PutObjectTagging]が必要となる。
気になりポイント
1. Lambda関数の呼び出し
オブジェクトをまとめて別のサービスで処理したい場合に使う。下記はS3に保存した動画ファイルをMediaConvertで様々な形式に変換して再度S3に保存するというケース。
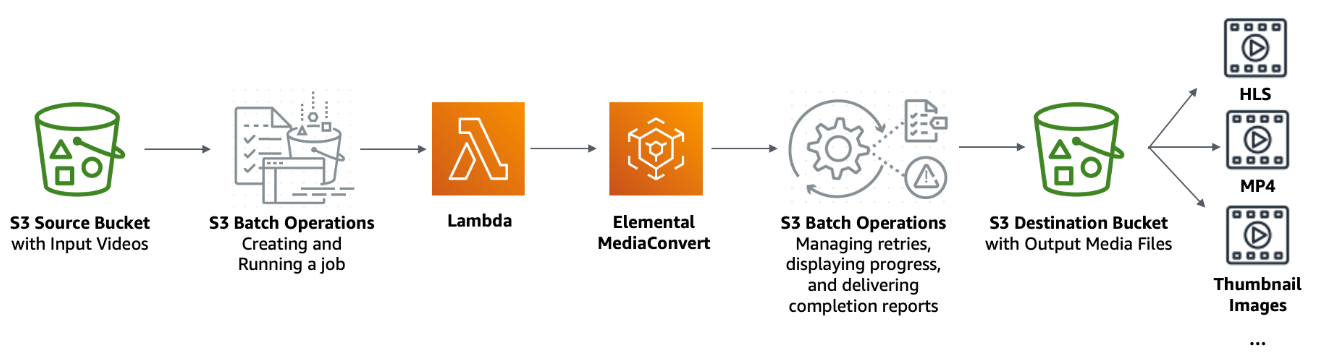
2. 全てのオブジェクトタグを置換する
3. 全てのオブジェクトタグを削除する
特になし
4. ACLを置換する
・該当するオブジェクトを操作する人物やその人物が実行できるアクションを一括で変えたい場合に使う。
・S3へのパブリックアクセスのブロックについてはバッチ処理ではなくコンソールで行う。
・ACLを無効(バケット所有者の強制設定)にしている場合は他のAWSアカウントやグループへの許可はできない。
5. オブジェクトの復元
Glacier Flexible Retrieval, Glicier Deep Archive及びIntelligent-TieringのDeep Archive層のオブジェクトを高頻度のストレージ層に戻す。アーカイブの取り出し方法(迅速、Standard, 大容量)を指定可能。
・ExpirationInDays
復元が完了したオブジェクトの一時的なコピーを保持する期間。Intelligent-Tieringでの復元を行う場合に指定すると復元リクエストが失敗する。
6. オブジェクトロックの保持
7. オブジェクトロックのリーガルホールド
特になし
設定の流れ
大まかな流れ
・マニフェストの準備(S3インベントリレポートもしくは自前のCSVファイル)
・アクセス許可の付与(必要なIAMロール、IAMポリシーの作成)
・マニフェストの指定
・オペレーションの選択
マニフェストとは対象となるオブジェクトのリストです。S3インベントリポートで作成した場合はjson形式となります。CSVファイルとして用意することも可能です。
S3インベントリレポートについて
最初のレポートが配信されるまでに最大で48時間かかることがあるので事前にインベントリ設定を行うこと。
S3インベントリレポートを指定してマニフェストからジョブを作成する場合は、S3のインベントリ設定から設定可能。
{S3 >> バケットクリック >> 管理 >> インベントリ設定 >> マニフェストからジョブの作成}
料金
・ジョブあたり 0.25USD
・実行された100万オブジェクトオペレーションあたり 1.00USD
・その他データ転送、リクエストなどはS3の料金を参照
その他
・ジョブの優先度の設定可能
・CLIを使ってジョブのリストや詳細の取得が可能
・ジョブの完了レポートをリクエストすることができジョブのステータスや失敗の追跡が可能
・ジョブにタグ付け可能
S3 バッチ操作ジョブの管理
ジョブステータスと完了レポートの追跡
タグを使用したアクセスのコントロールとジョブのラベル付け
個人的Q&A
Q. ジョブの自動化方法は?
そもそも複数回処理を行うための機能ではないのでは? AWS BatchならEventBridgeと統合して自動化が可能。