- プログラミング歴45日の素人が書いています。ご注意ください。
注意
スクレイピングは利用方法によってはスクレイピング先のサーバに異常な負荷がかかります。
場合によってはグレー、違法となる可能性がありますのでご注意ください。
はじめに
【想定】WEBメディア運営の一貫として、あるキーワードに対してどんな記事が人気があるのかを調べます。
-
「goodkeyword」(https://goodkeyword.net) を使うと、あるキーワードに関連する検索ワードが100件出てきます。
-
100件の検索キーワードについて、Googleで検索した時のhit上位3件を自動で取得して、CSVにまとめます。
環境
-
MacBookAir-mid2014
-
macOS-Mojave
-
Python 3.7.4
Googleキーワードで人気のありそうな関連キーワードを調べる
「goodkeyword」(https://goodkeyword.net) を使うと、あるキーワードに関連する検索ワードが100件出てきます。
コピーしてCSVにまとめます。
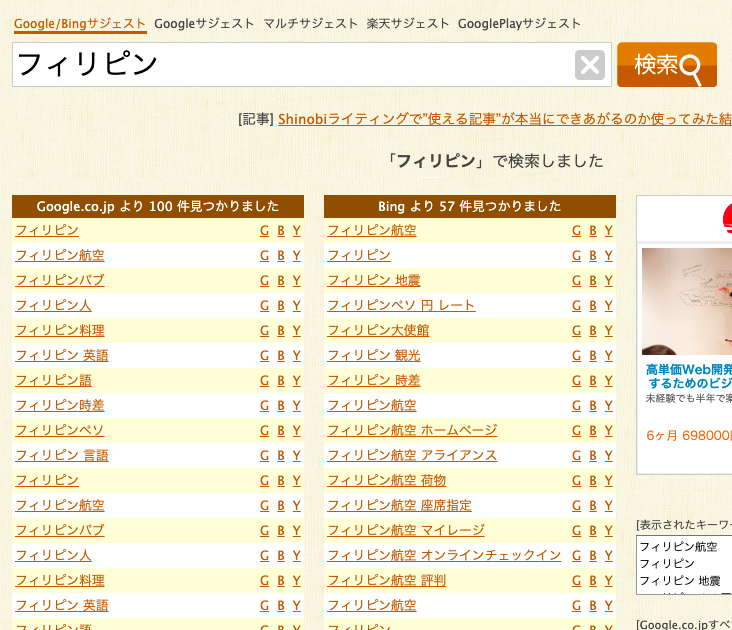
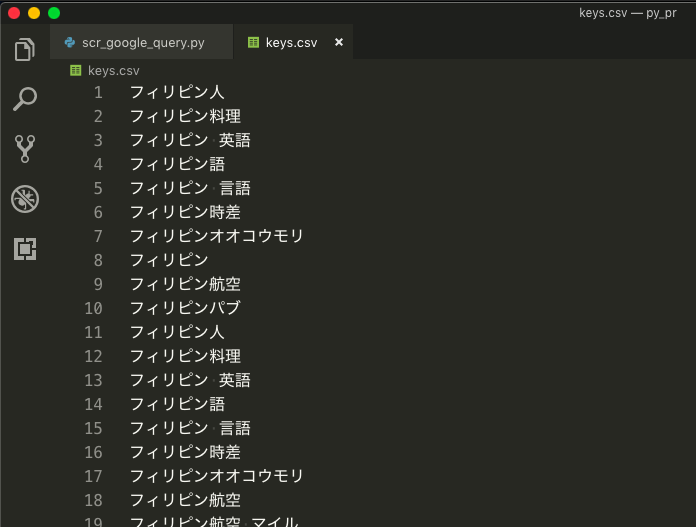
CSVにコピペする。
Pythonでスクレイピングする
import requests
from bs4 import BeautifulSoup
with open('keys.csv', encoding='shift_jis') as csv_file:
with open('result.csv','w') as f:
for keys in csv_file:
result = requests.get('https://www.google.com/search?q={}/'.format(keys))
soup = BeautifulSoup(result.text, 'html.parser')
list = soup.findAll(True, {'class' : 'BNeawe vvjwJb AP7Wnd'})
for i in range(3):
a = str(list[i]).strip('<div class="BNeawe vvjwJb AP7Wnd">')
result_title = a.strip('</')
keyword = keys.rstrip("\n")
f.write('{0},{1}\n'.format(keyword, result_title))
---
# target divs example
# <div class="BNeawe vvjwJb AP7Wnd">フィリピン人女性5つの特徴
# <div class="BNeawe vvjwJb AP7Wnd">フィリピン人 - Wikipedia
コードが汚いのは素人なのでかんべんしてください。
ライブラリのimport
import requests
from bs4 import BeautifulSoup
「requests」と「BeautifulSoup」をインポートします。
CSVファイルの準備
with open('keys.csv', encoding='shift_jis') as csv_file:
with open('result.csv','w') as f:
-
keys.csvには、検索キーワードが1行づつ入っています。 -
result.csvは、ディレクトリに存在しなければ自動で作成されます。
HTMLデータの取得
for keys in csv_file:
result = requests.get('https://www.google.com/search?q={}/'.format(keys))
soup = BeautifulSoup(result.text, 'html.parser')
list = soup.findAll(True, {'class' : 'BNeawe vvjwJb AP7Wnd'})
-
CSVファイルの中身を1行づつ取り出して、変数
keysに格納します。(これが検索キーワード) -
GoogleのURL末尾に検索キーワードを代入して、getリクエストを送ります。
-
取得したデータをBeautifulSoupがHTMLとして扱えるようにしてくれます。
-
さらにそこから、ターゲットとなるクラスをもつdivとクラスを指定して抜き出します。
複数のクラスを指定してfindAllする
複数のクラスを指定してfindAllするためには、
soup.findAll(True, {'class' : 'BNeawe vvjwJb AP7Wnd'})
のように書きます。
True指定して、第二引数にリストを渡すと、&&指定になります。
クラスが変わる?
同じURLでアクセスしているにも関わらず、ブラウザに表示されるHTMLと、requestsで取得するHTMLが違っていました。
↓ブラウザでは、<h3 class="LC20lb">が検索結果のタイトルになっている
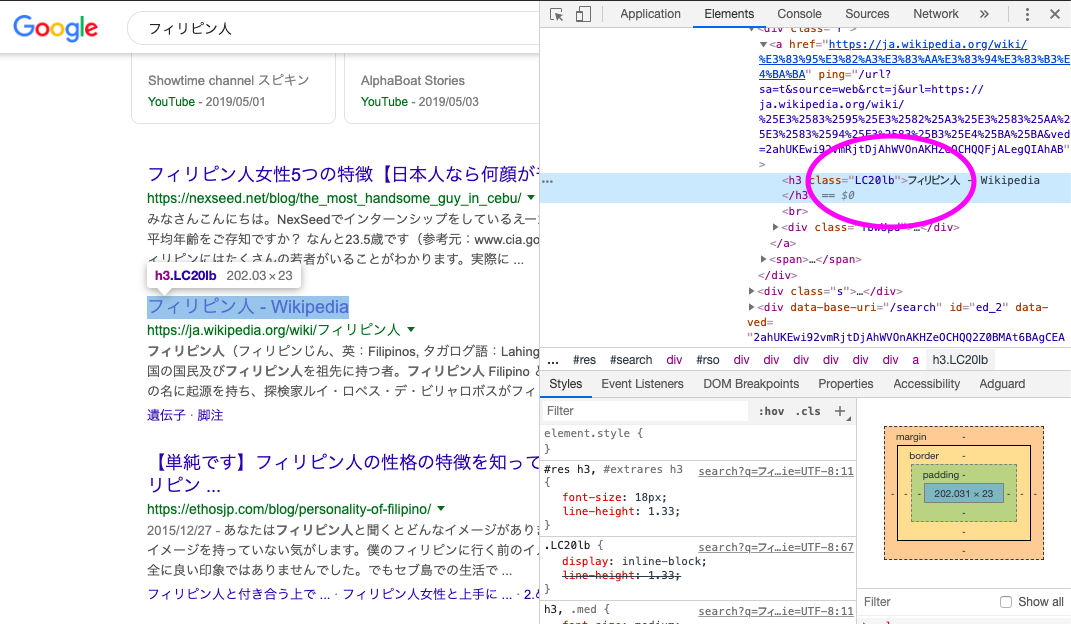
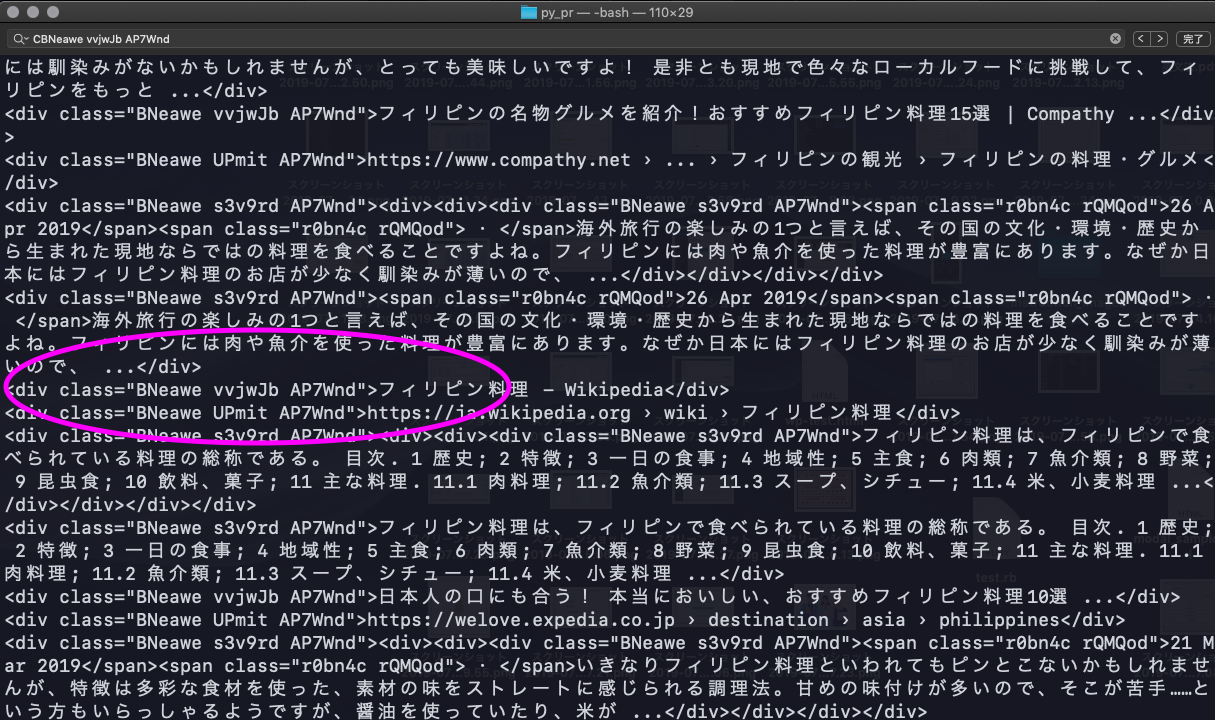
ターミナルで確認すると、<div class="BNeawe vvjwJb AP7Wnd">に変わっている
(わかるかた教えていただきたいです)
加工してCSVに書き込む
for i in range(3):
a = str(list[i]).strip('<div class="BNeawe vvjwJb AP7Wnd">')
result_title = a.strip('</')
keyword = keys.rstrip("\n")
f.write('{0},{1}\n'.format(keyword, result_title))
- 今回は上位3件だけを抽出するので、
range(3)で設定して各キーワードについて3回づつループを回してCSVに出力します。

-
find_allメソッドで抜き出したデータにはdivタグが含まれていますので、これをstripメソッドで取り除きます。 -
keys.csvにもともと入っている検索キーワードには、不要な改行\nが含まれているので、これもrstripメソッドで取り除きます。rstripメソッドは文字列を右から削除するメソッドです。 -
writeメソッドでresult.csvに書き込んで終了です。
エクセルなどで確認する
以下のように出力されています。
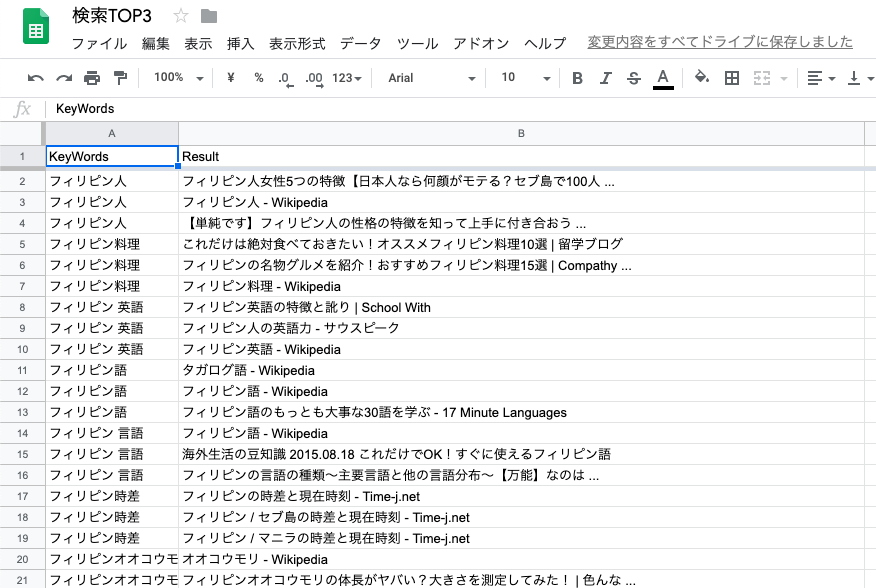
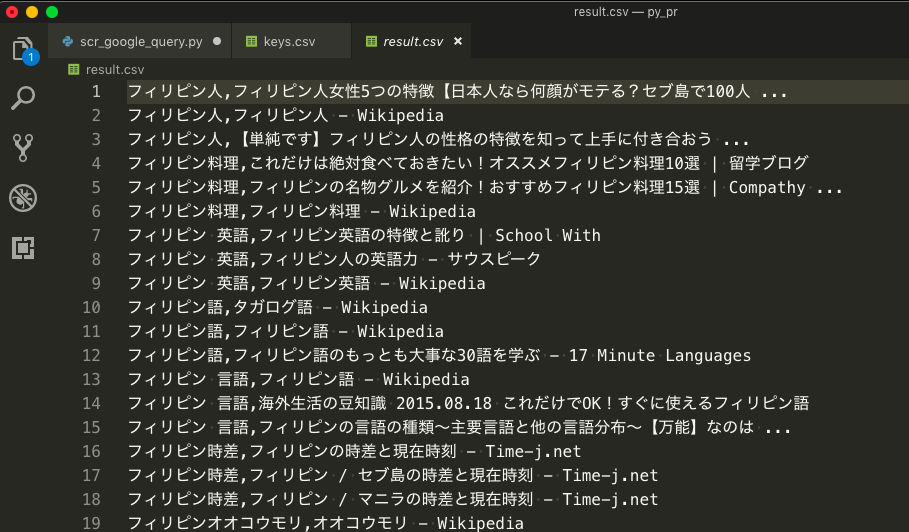
テキストエディタでみると、1行につき、コンマで区切られた状態になっています。
まとめ
- CSVファイルに入っている検索キーワード100件で検索し、各検索結果のTOP3を新しいCSVファイルにまとめました。
* 複数のクラスを指定してfindAllすることもできます。
- CSVファイルは1行ごとに改行が入る(当たり前だけど)ので、
rstripで取り除く。